









https://arxiv.org/pdf/1711.00937v2.pdf(论文下载链接)
之所以将VQ-VAE(Vector Quantised Variational AutoEncoder)论文,主要是为讲解后面两篇论文做准备,VQ-VAE不管是视频还是博客,都有人在讲解,但是这里也做一个总结,以衔接后面的两篇论文讲解,关于VAE(Variational AutoEncoder)相关的论文比较多,并且其中涉及的数学原理以及推导也比较多,导致我们在阅读VAE方法的时候可能存在较多的困惑,自己在看的过程中也遇到了较多的困惑,但是还是准备做一个总结。
目录

一.提出目的和方法
1.提出目的
传统的VAE(变分自编码器)在隐空间中使用连续分布,导致生成的隐变量难以进行有效的离散化表示(如用于序列建模或强化学习)。
2.提出方法
VQ-VAE提出了一种离散隐变量的自编码方法,通过向量量化(Vector Quantization, VQ) 实现隐空间的离散化,从而提升表征的可解释性和生成质量。具体方法:编码器网络输出离散而非连续代码;且先验分布是动态学习而非静态预设。为学习离散潜在表征,融入了向量量化(VQ)的核心思想。采用VQ方法使模型能够规避VAE框架中常见的"后验坍塌"问题(即当潜在变量与强大的自回归解码器结合时被忽略)
二.VQ-VAE贡献点
- 提出VQ-VAE模型:该模型结构简单,采用离散潜在变量,既不会出现"后验坍塌"问题,也不存在方差异常;
与本研究最相关的工作当属变分自编码器(VAEs)。VAE包含以下核心组件:
1)编码器网络:用于参数化离散潜在随机变量z的后验分布q(z|x),其中x为输入数据;
2)先验分布p(z);
3)解码器网络:建立输入数据条件分布p(x|z)。
传统VAE通常假设后验分布与先验分布均为对角协方差的正态分布,这种设定可利用高斯重参数化技巧。现有扩展方法包括:
本研究提出的VQ-VAE创新性地采用离散潜在变量,其训练方法受向量量化(VQ)启发。该模型中:
1)后验与先验分布均为类别分布;
2)从分布中采样的离散值作为嵌入表的索引;
3)检索到的嵌入向量将作为解码器网络的输入。
三.VQ-VAE具体方法
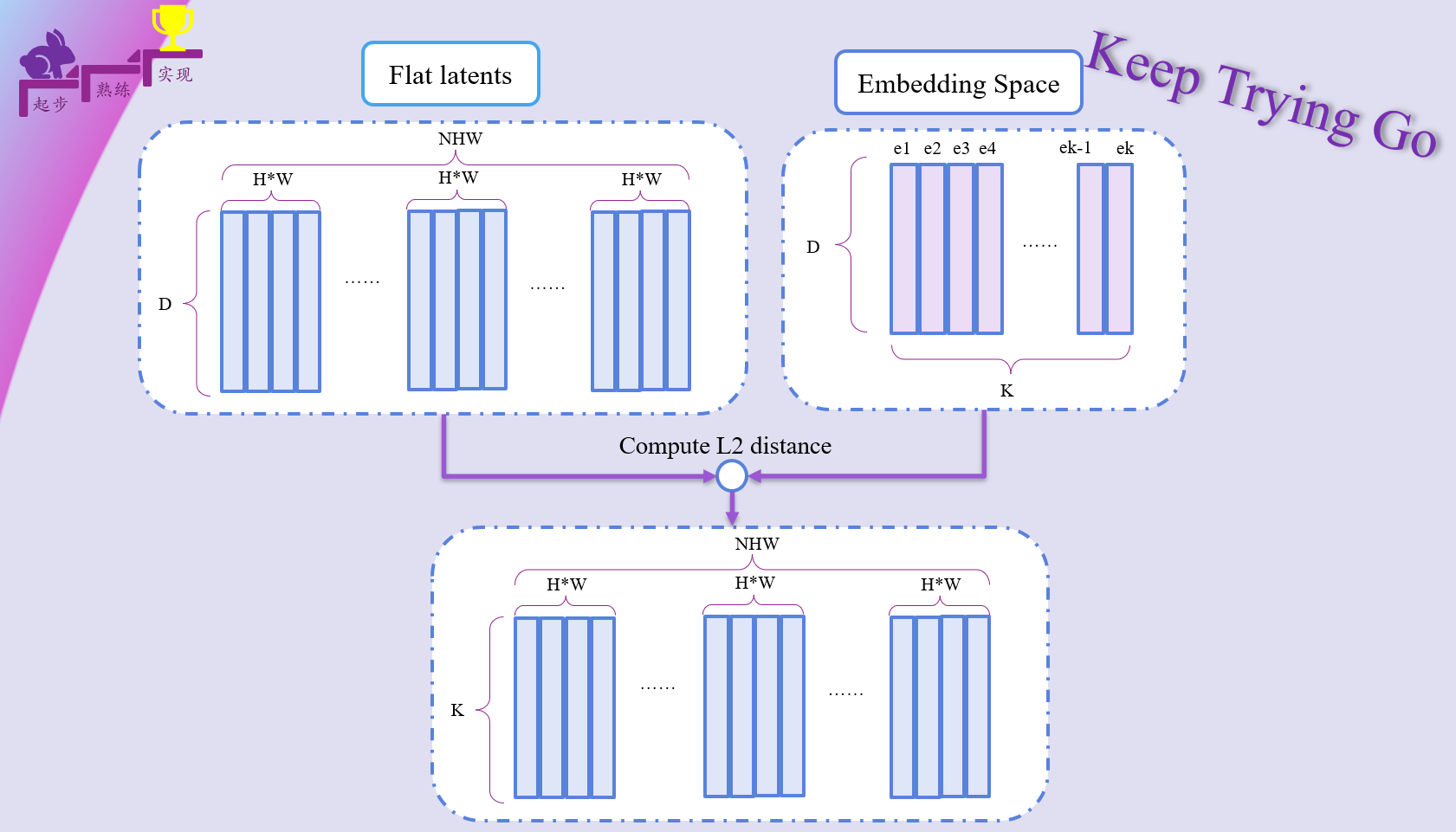
1.离散化隐藏向量

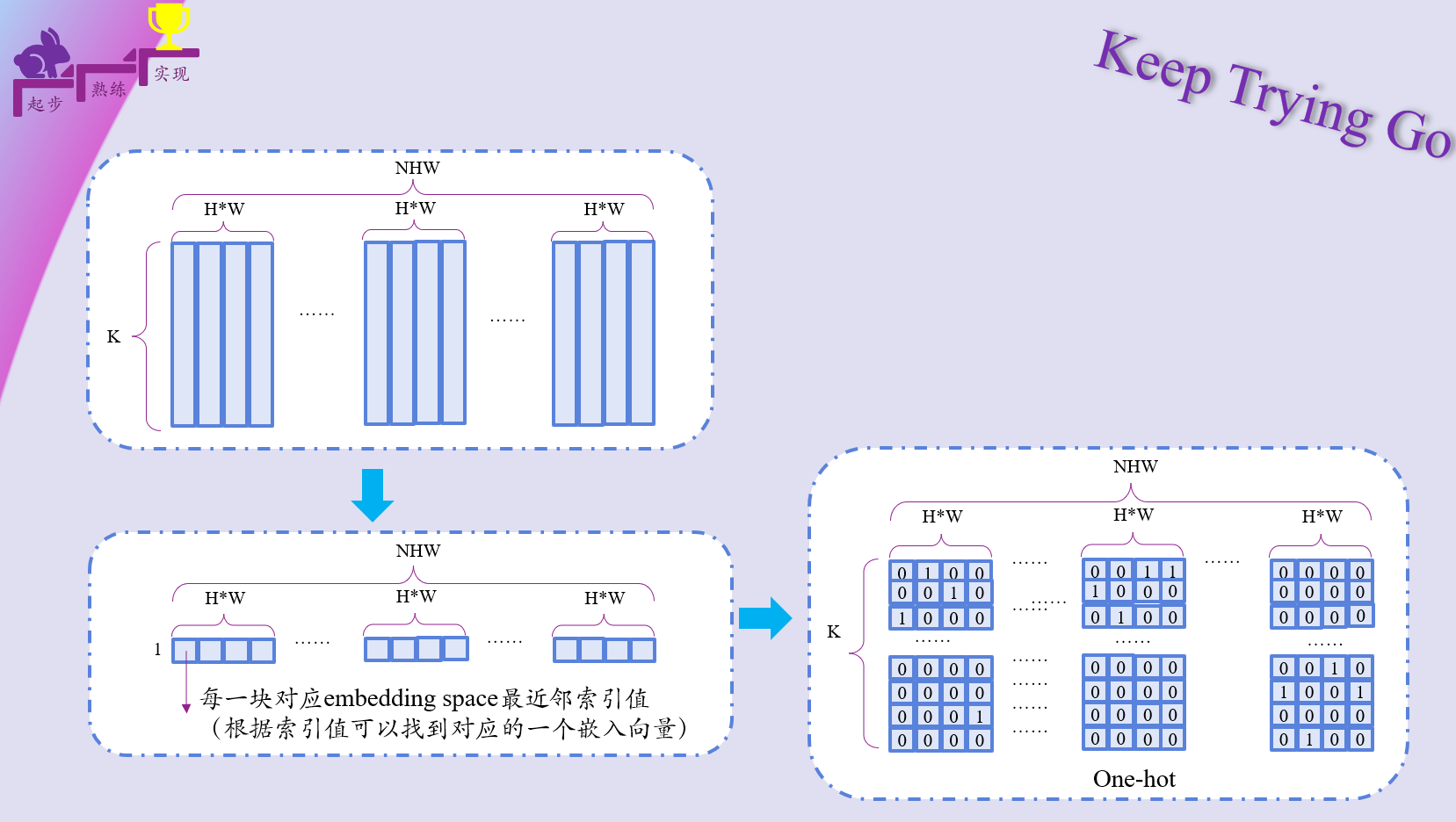
注:也就是这里计算嵌入空间和编码器输出向量Ze(x)之间的距离,找到最小距离的索引K,然后下面将其转换为one-hot编码格式。

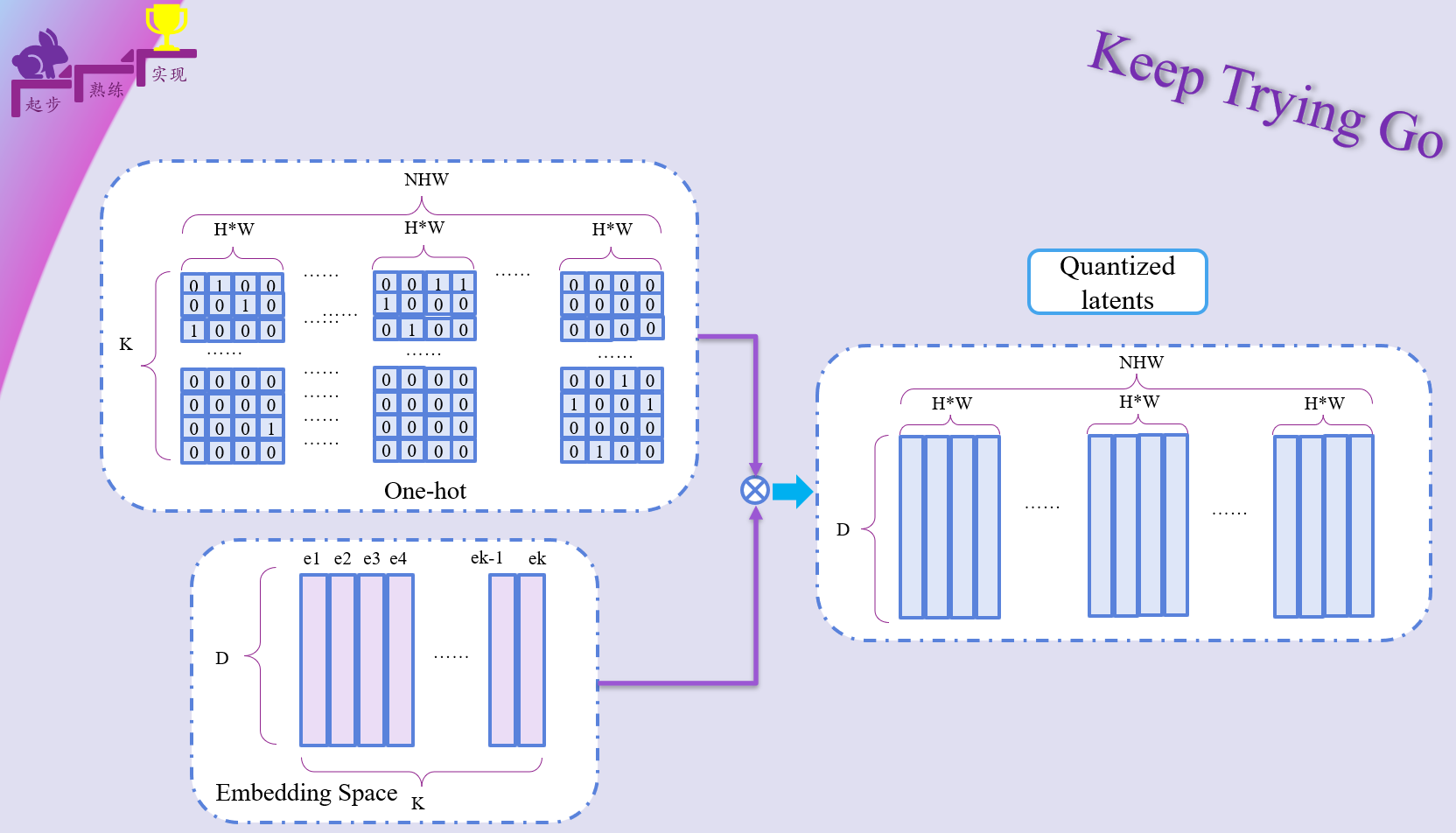
转换为one-hot编码格式之后。通过为1的位置获得对应的离散向量。 为了更好的理解这个过程,使用下面的图来给大家表示一下:(建议结合代码看)
四.VQ-VAE学习方式
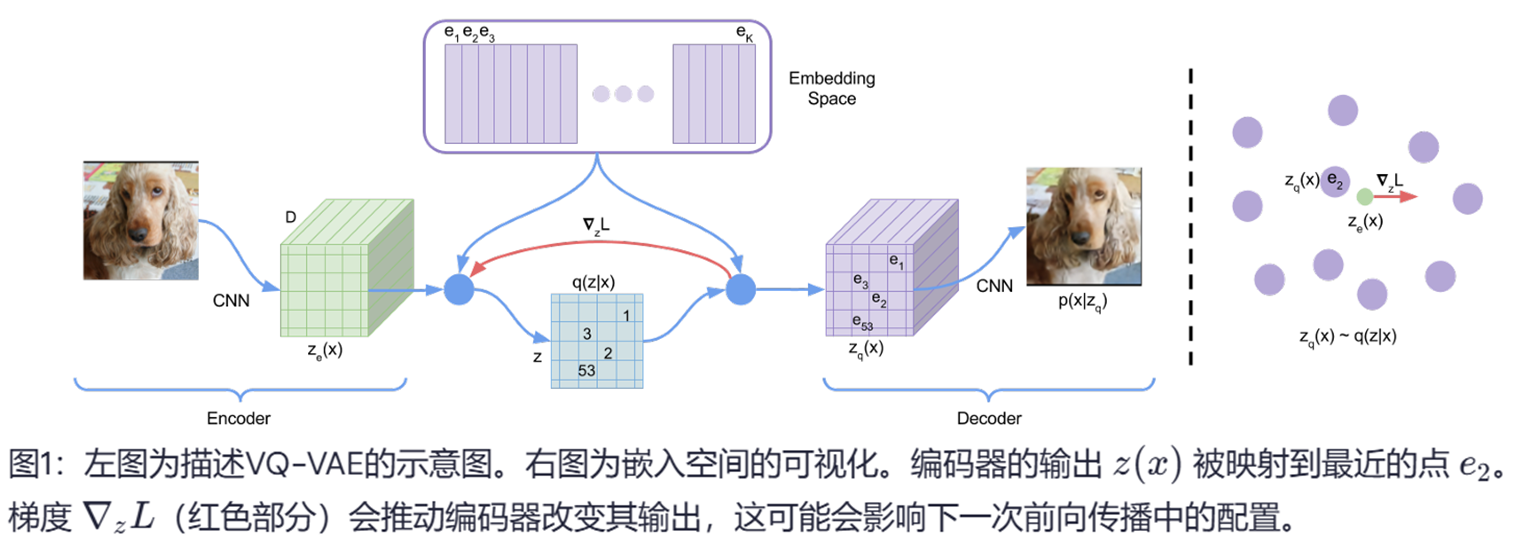
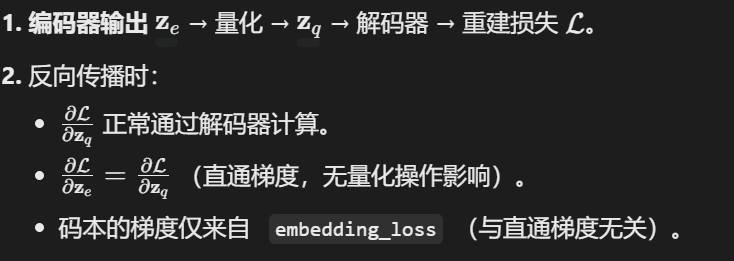
虽然方程2没有明确定义的梯度,但本文采用类似于直通估计器(straight-through estimator)的方法来近似梯度,即直接将解码器输入 zq(x) 的梯度复制到编码器输出 ze(x)。
# TODO gradient copy trick (Add the residue back to the latents)
quantized_latents = latents + (quantized_latents - latents).detach()
计算量化误差(zq − ze),但通过 .detach() 断开梯度回传,确保这部分不会影响编码器的梯度。- 前向传播时,等价于直接返回 zq(因为 ze+(zq−ze)=zq)。
- 反向传播时,由于右侧项被
detach(),梯度会直接通过左侧的latents(即 ze)回传,相当于将 zq 的梯度复制给了 ze。


核心代码实现
class VectorQuantizer(nn.Module):
"""
Reference:
[1] https://github.com/deepmind/sonnet/blob/v2/sonnet/src/nets/vqvae.py
"""
def __init__(self,
num_embeddings: int,
embedding_dim: int,
beta: float = 0.25):
super(VectorQuantizer, self).__init__()
self.K = num_embeddings
self.D = embedding_dim
self.beta = beta
#TODO 定义的嵌入向量e
self.embedding = nn.Embedding(self.K, self.D)
self.embedding.weight.data.uniform_(-1 / self.K, 1 / self.K)
def forward(self, latents: Tensor) -> Tensor:
#TODO 编码器输出的编码向量
latents = latents.permute(0, 2, 3, 1).contiguous() # [B x D x H x W] -> [B x H x W x D]
latents_shape = latents.shape
flat_latents = latents.view(-1, self.D) # [BHW x D]
# TODO 计算隐藏向量和嵌入向量权重之间的L2距离 Compute L2 distance between latents and embedding weights
dist = torch.sum(flat_latents ** 2, dim=1, keepdim=True) + \
torch.sum(self.embedding.weight ** 2, dim=1) - \
2 * torch.matmul(flat_latents, self.embedding.weight.t()) # [BHW x K]
# TODO 获得最小距离对应的索引 Get the encoding that has the min distance
encoding_inds = torch.argmin(dist, dim=1).unsqueeze(1) # [BHW, 1]
# TODO 将其索引转换为对应的one-hot编码 Convert to one-hot encodings
device = latents.device
encoding_one_hot = torch.zeros(encoding_inds.size(0), self.K, device=device)
encoding_one_hot.scatter_(1, encoding_inds, 1) # [BHW x K]
#TODO 获得离散化隐藏向量空间 Quantize the latents
quantized_latents = torch.matmul(encoding_one_hot, self.embedding.weight) # [BHW, D]
quantized_latents = quantized_latents.view(latents_shape) # [B x H x W x D]
# TODO Compute the VQ Losses
commitment_loss = F.mse_loss(quantized_latents.detach(), latents)
embedding_loss = F.mse_loss(quantized_latents, latents.detach())
vq_loss = commitment_loss * self.beta + embedding_loss
# Add the residue back to the latents
quantized_latents = latents + (quantized_latents - latents).detach()
return quantized_latents.permute(0, 3, 1, 2).contiguous(), vq_loss # [B x D x H x W]五.实验比较





悄悄举手:若觉得文章有用,不妨留下一个小赞?(´▽`ʃƪ)


















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









