







在MindSpore的数据集加载接口中,可以启动多进程模式加快数据处理速度,具体有2个API支持:
mindspore.dataset.GeneratorDataset
mindspore.dataset.GeneratorDataset(source, column_names=None, column_types=None, schema=None, num_samples=None, num_parallel_workers=1, shuffle=None, sampler=None, num_shards=None, shard_id=None, python_multiprocessing=True, max_rowsize=6)map(operations, input_columns=None, output_columns=None, column_order=None, num_parallel_workers=None, python_multiprocessing=False, cache=None, callbacks=None, max_rowsize=16, offload=None)这两个API中,与多进程启动相关的参数是python_multiprocessing和max_rowsize。
python_multiprocessing决定是否启用多进程模式加快数据处理速度,而max_rowsize用于配置多进程模式下共享内存的大小,属于高级用法。
一般来说,只需要将python_multiprocessing设置为True在大多数情况下就可以适用。
△ 如果打开了多进程模式,可能会碰到以下的错误,这里总结了一些常见的错误和解决办法。
错误1:
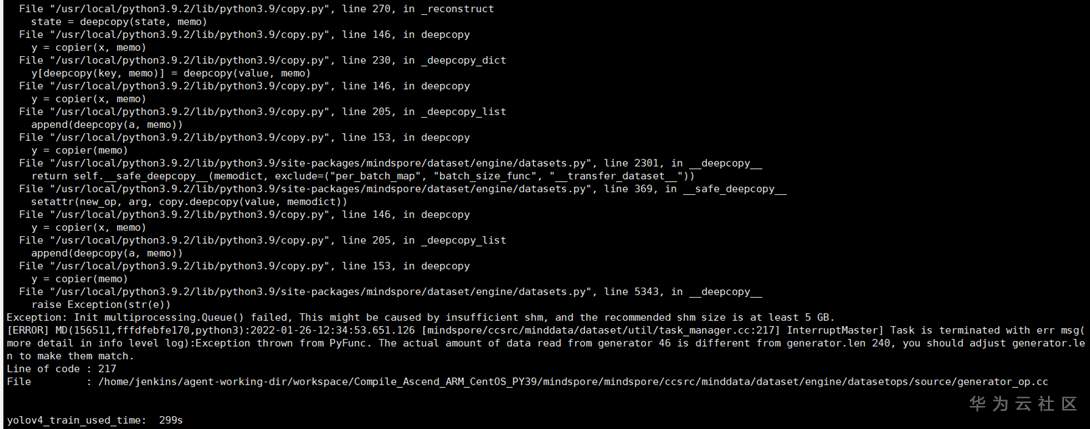
核心报错信息是 This might be caused by insufficient shm, and the recommended shm size is at least 5 GB.
原因:
系统可用的共享内存太小,可以通过 df -h 查看共享内存的大小,如下示例有500G的共享内存,妥妥的够用啦。
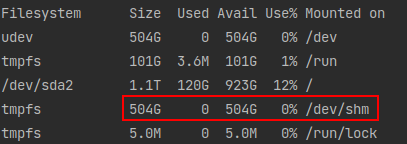
解决办法:
如果发现自身系统的 /dev/shm 不足5G,那确实会导致这个错误,有2个解决办法
- 关闭多进程模式,即设置python_multiprocessing=False。这样就会采用多线程模式进行加速,同样也会有一定的加速效果,也可以调节num_parallel_workers增加线程/进程数,以提高整体的数据处理效率。
- 申请更多的共享内存,可以参考博客上教程调整共享内存,如 https://blog.csdn.net/Sunny_Future/article/details/100569637
错误2:
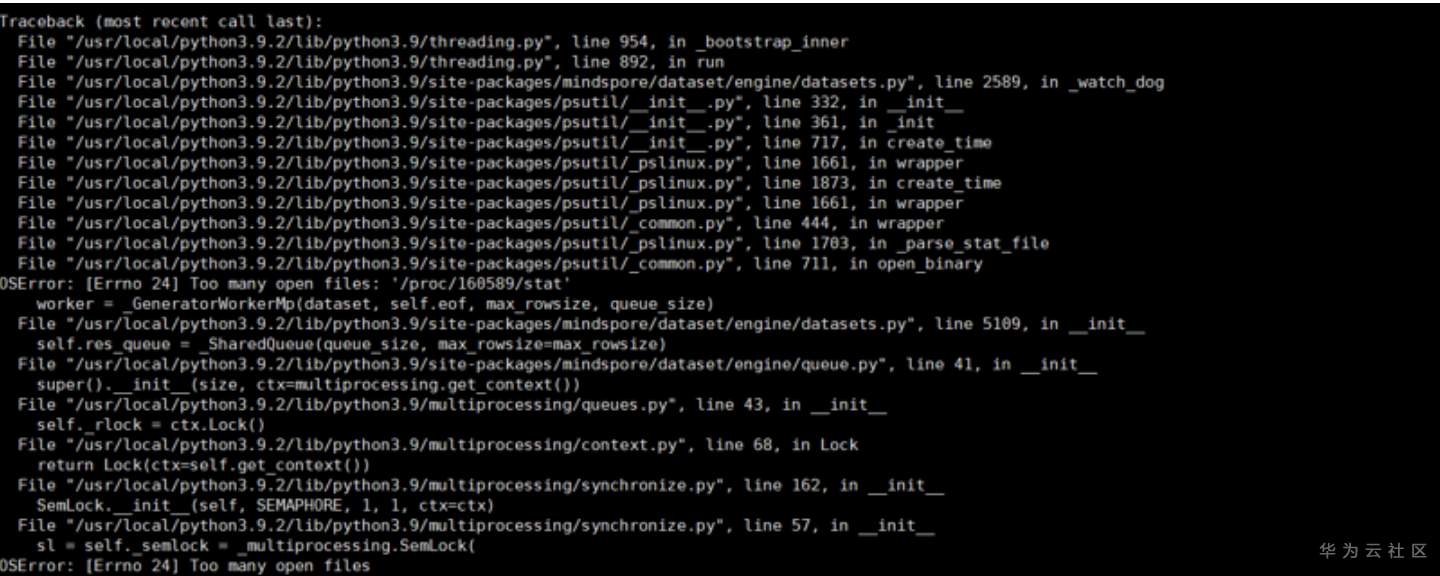
核心报错信息是 OSError: [Errno 24] Too many open files.
这个错误可能会在 非root用户 下使用 多进程模式 时触发
原因:
有几个可能的原因
- 如上一个错误所属,共享内存不足5G,导致无法使用。
- 如果发现/dev/shm超过5G,却还是这个错误,则可能是 非root用户可用资源的限制,可以通过 ulimit -a 查看非root用户可用资源
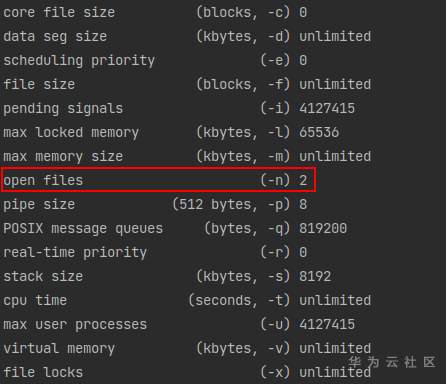
可以看到当前用户的可用 open files 数目只有2,这样很大程度就会抛出上述错误。
解决办法:
通过 ulimit -a 查看 open files 的数量,然后通过 ulimit -n 设置成较大的数值,如
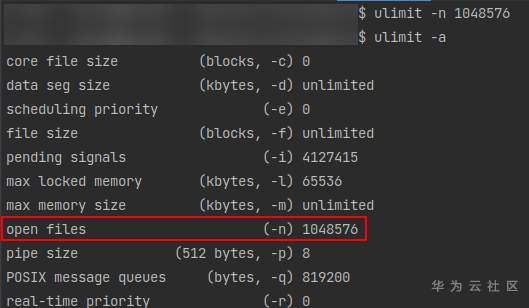
重新启动训练就可以啦。
错误3:
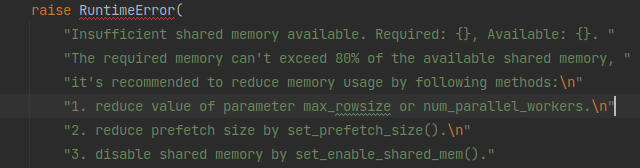
核心报错信息是 Insufficient shared memory available. Required: xxxxx, Available: xxxxx.
这个错误可能会在 共享内存不够/处理的数据块过大 时触发
原因:
- 可能有其他进程也在使用共享内存,使用 df -h 查看 /dev/shm 当前的可用大小
- 当前正在处理的数据非常大,导致其占用了过多的共享内存,使得共享内存不够用了
解决办法:
- 在允许的范围内,尽可能增大共享内存的大小,如 https://blog.csdn.net/Sunny_Future/article/details/100569637
- 检查数据处理时,是否正在处理过大的数据导致内存占用太多
- 通过 mindspore.dataset.config.set_prefetch_size() 减少数据管道中缓存的数据量
- 实在不行,通过 mindspore.dataset.config.set_enable_shared_mem(False) 关掉共享内存














 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









