







一图读懂“模型动态混淆”
01 技术背景
人工智能技术拉开了“第四次工业革命”的序幕,AI技术逐渐应用到了我们生活的方方面面,对应的就是各种各样的AI模型部署到了很多电子设备上,比如手机、平板、汽车以及一些大型的云服务机器。这些模型需要AI厂商投入大量的人力、物力才能训练出来。
如果AI模型在部署环境中被敌手窃取了,会造成多方面的恶劣影响。一方面敌手拿到模型后,可以解析模型的结构,将模型部署到自己的硬件设备上进行重训练或者微调,甚至直接拿去使用。这样就相当于侵犯了原模型厂商的知识产权,削弱了原模型厂商的技术竞争力。另一方面,敌手在了解了模型的真实结构之后,可以发动白盒攻击,使得模型发生误判或失效,从而制造AI应用的负面舆论。
02 现有技术
意识到模型被窃取带来的风险后,AI算法专家开始探索有效的模型保护方法。一种主流方案是采用传统的加解密算法对模型进行保护,比如苹果的CoreML框架采用的方案。这类方案是模型在部署到使用环境之前,先使用AES等加密算法对模型文件进行全量加密,然后把加密后的模型存放在磁盘空间中;当APP启动了一个AI推理进程之后,AI模型就会被传到运行内存中解密。
这个方案可以保证模型在静态存储时的安全性。但是它有两个问题,一个是加密模型在内存中的解密时延是明文模型导入框架的时延的数十倍,影响了端侧的推理性能和用户体验;另一个是模型在运行过程中是明文形式的,尽管它在内存中存在的时间比较短暂,但是有研究测试表明,超过半数的模型可以从运行内存中dump出来。
另一种是基于安全多方计算、同态加密等技术的密态计算方案,这类方案可以使得模型在密文形式下进行推理。但他们的缺陷也很明显,就是计算开销或者通信开销很大,会导致模型推理时延是普通模型推理时延的上千倍。
还有一类是基于可信执行硬件(TEE)的方案,TEE是硬件环境中一块隔离的内存空间,提供运算和存储功能,并且提供安全性保护。把模型部署到TEE中进行推理,可以防止被窃取。但是基于TEE的保护方案通用性不强,一方面体现在对于不同的TEE架构,需要设计不同的保护方案;另一方面,有些业务场景不具备TEE或者不信任第三方TEE;其次,当前业界的TEE算力有限,会导致模型推理性能下降,不适用大模型场景。而且为了执行模型文件需要将整个AI软件栈移植到TEE中,可能会增大TEE自身的攻击面,导致整个系统的安全性降低。
03 模型动态混淆
基于上述背景,昇思MindSpore安全可信团队自研了一种新的模型机密性保护方案,叫做“模型动态混淆”,这种模型保护方案可以兼顾模型安全(静态存储安全和动态推理安全)和推理性能,还能防逆向、防盗用。
3.1 算法原理
一句话概括:基于AI模型的原始FuncGraph[1](昇思MindSpore计算图的表达格式),使用伪分支算法和扁平化算法在原始计算图中插入伪分支,混淆原模型的真实结构;同时使用权重混淆算法对原模型的算子权重进行混淆保护。敌手窃取到混淆模型之后一,也很难理解原模型的真实结构信息和权重信息。
接下来详细介绍伪分支算法、扁平化算法以及权重混淆算法。
3.1.1 伪分支混淆算法
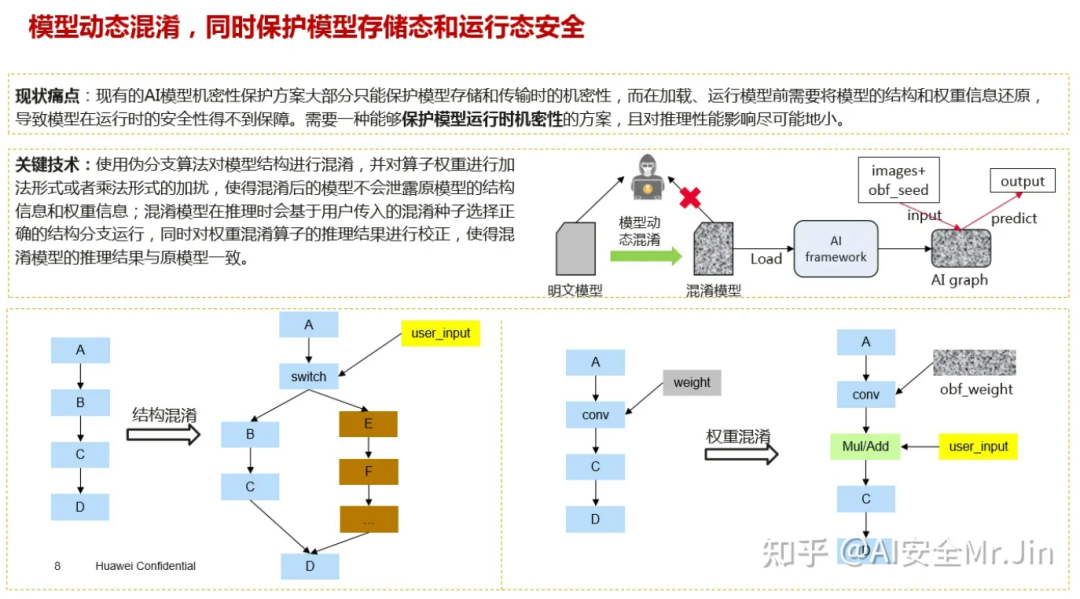
众所周知,AI模型是由众多算子连接而成的图结构,如下图左边所示,这是一个由A、B、C三部分(每部分可能包含一个算子或多个算子)组成的模型,如果我们现在想保护子图B,那么就可以创建一个伪分支D,把D和B作为并排的分支,组成一个switch结构,并且由condition决定模型走哪个分支。这样的话,攻击者即使拿到了模型,也不知道B是原始模型的分支还是D是原始模型的分支。需要注意的是,condition的结果是不能被攻击者得知的,只有模型运行的时候才能知道其结果,所以我们还要设计合适的控制条件,详情见3.1.4节。
伪分支算法图示
3.1.2 伪分支构建算法
上一小节阐述了伪分支的算法思想,下面具体介绍如何构建伪分支。
方案一:逐算子替换。假设真分支是由op1->op2->op3组成的,那么我们需要设计一个条件映射函数:op_fake = MapFun(op_true),对每一类算子选择对应的伪节点,比如卷积算子对应卷积算子(的组合)、激活算子对应激活算子;那么根据这个映射函数,我们就可以得到op_fake1、op_fake2、op_fake3组成的伪分支。
好处:便于让伪分支处理后的输出shape和原节点处理后的shape保持一致;
坏处:对于不同类型的算子要专门写映射函数,通用性差;混淆结构单一,混淆效果差。
方案二:端到端整体替换。由于构建伪分支的关键是控制它输出的shape,而不是它计算的值,所以我们只关注真分支的输入形状input_shape以及输出形状output_shape,只要我们构造的伪分支能满足输出的shape和原始分支的输出shape相同即可,伪分支包含的算子个数随机化(以原分支算子个数为基准浮动)。于是可以设计这样一个伪分支构建函数:make_fake_branch(input_shape, output_shape)。
假设input_shape= (C1, W1, H1),output_shape= (C2, W2, H2),那么fake_branch只需要使用合适的算子把(C1, W1, H1)调整成(C2, W2, H2),就达到了目标。这个调整可以分两步做:先使用可以调整C,再调整W、H,这就需要先分析昇思MindSpore的常用算子,根据他们对C、W、H的改变作效果归类,然后在构建伪分支的时候随机选择。
这里有个需要注意的点,就是如果input_shape有维度缺失,比如,input_shape= (W1, H1),那么我们可以在伪分支中使用expand_dims算子把它的维度扩充为(1, W1, H1),然后继续处理;如果output_shape有维度缺失,比如,output_shape= (C2,),那么我们可以把它当作(C2, 1, 1)传进make_fake_branch(),然后在最后加一个reduce_dims算子。
在统一input_shape和output_shape的维度后,我们根据维度分为2维,3维,4维,5维的情况。根据不同的维度,可以选择不同的算子来达成改变shape的目的。
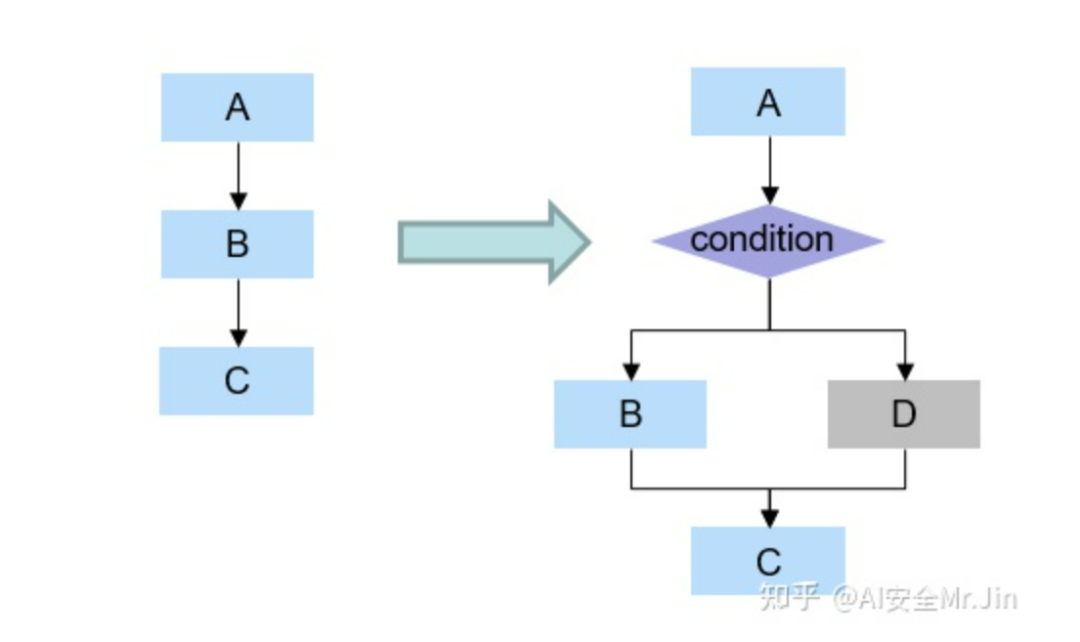
3.1.3 扁平化算法
扁平化算法是伪分支算法的一种扩展形式。如下图所示,原模型由A、B、C、D、E五部分组成,现在我们想保护B、C、D三部分。于是我们可以构建一个switch结构,其中三个分支是原模型的B、C、D,其它分支是伪分支。为了保证B、C、D三部分都能执行一遍,这个switch结构就需要执行多次,所以下图中的'P_loop'到switch节点有一个回转(假设P_loop=True时进行回转,P_loop=False时走到E)。此外,为了保证每次执行switch结构体的时候,都能选择正确的分支,我们还要维护一个指示变量next。如下图所示,最开始的时候,next=P0,我们让P0=3,于是switch就会选择走第3个分支,也就是子图B;然后运行完子图B之后,next的值更新为P3,我们让P3=5,于是switch会选择走第5个分支,也就是子图C;再接着让switch走第1个分支,同时把P_loop的值更新为False。这样就可以按原模型的节点顺序执行,同时攻击者从这个switch结构体看不出来原来的真实节点和执行顺序。要注意的是,P0, P1, ..., P_loop的结果不能让攻击者知道,只有在模型运行时才能确定。
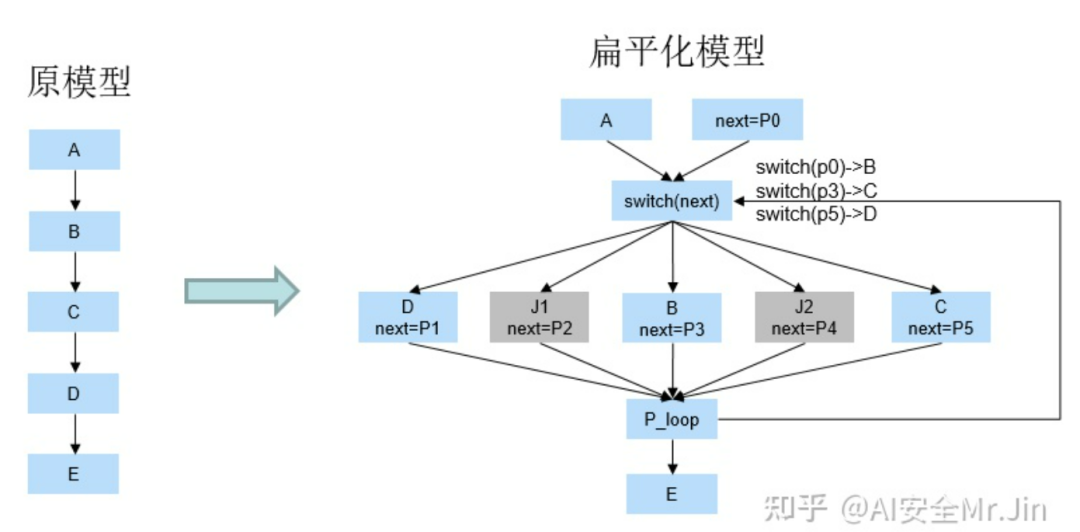
扁平化算法图示
伪分支和扁平化的算法原理很简单,困难的是代码实现:如何在原有的FuncGraph中根据现有的语法规则插入新的节点,保证模型能正确执行,同时推理性能损失最小;模型执行的时候是按节点排列顺序执行的,如何在模型执行过程中,动态调整扁平化算子中next的值和P_loop的值。
3.1.4 混淆结构控制条件设计
上面几个小节提到了,模型子图或节点的保护是通过构造switch结构体来实现的,这一节说明如何设计switch结构的判定条件(针对伪分支算法的)。该判定条件需要满足两个条件:
1、在完成模型混淆后,敌手不能通过观察判定条件推断其结果;
2、对于任意的模型输入(推理时传入的样本),判定条件的返回值恒为True或者恒为False。举个例子,如果某个switch结构体中,真实节点被放在了True分支,伪节点放在了False分支,那么判定条件就需要保证在推理任意一个样本的时候,它返回的都是True,否则的话模型就会使用伪节点去推理,造成推理结果错误。
我们目前设计了基于外部输入的判定模式和用户自定义函数的模式,具体如下。
3.1.4.1基于外部输入的判定模式
在这种模式下,switch节点的结构为:
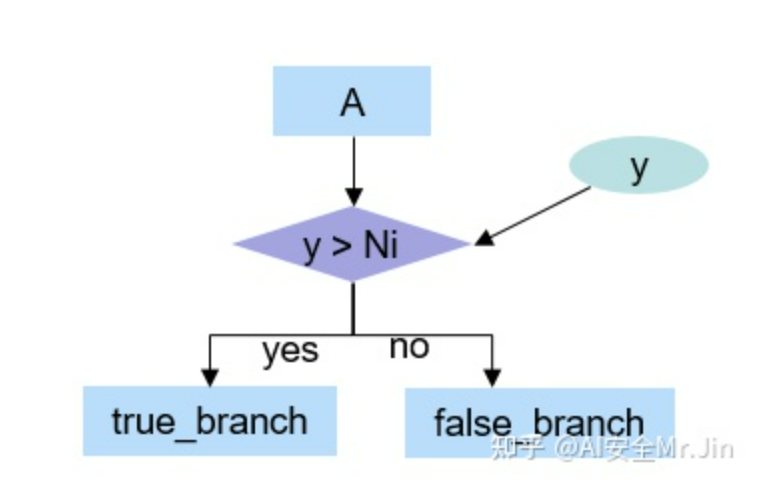
switch结构体-1
其中y是新增的一个模型输入,在推理时除了输入推理样本,还需要输入y值。我们如下确定Ni的值和真实节点放置的分支:
在混淆模型的时候,用户需要设置随机种子obf_random_seed,并基于函数f(x)生成一个整数branch_control_input,然后我们在构造第i个switch结构的时候,随机生成一个整数Ni,如果branch_control_input>Ni,那么我们把真实节点放在true_branch,否则把真实节点放在false_branch。
这样的话,混淆后的模型里面,判定条件是y>Ni,攻击者即使看到了这个表达式也不知道它的结果是什么。
在加载混淆模型推理的时候,用户只需要输入正确的混淆随机种子,模型就会选择正确的分支执行。
但这样有个问题,比如生成的branch_control_input=10086,而且他的模型只混淆了一个节点,N1=1234。那么其它用户在加载混淆模型推理的时候,生成的branch_control_input=2000,也同样可以使模型选择正确的分支执行。当然,如果混淆节点很多,这种概率是比较小的。
为了解决上述的问题,我们在构造第一个switch节点的时候,使用如下判定方式:
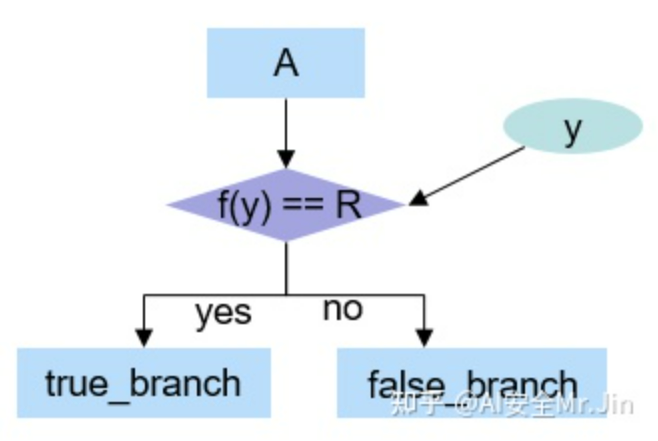
switch结构体-2
f(y)是变换函数(参考_get_branch_control_input()函数[2]),R=f(obf_random_seed),对于y1≠y2,f(y1)等于f(y2)的概率极小。
这样的话,如果其它用户拿到模型后,传入的y≠obf_random_seed的话,得到的结果几乎不可能正确。
上述方法存在一个安全问题,就是攻击者可以看到R=f(obf_random_seed),由于f(y)目前是公开在Python代码中的,所以攻击者可以通过穷举整数来寻找obf_random_seed。目前obf_random_seed的合法取值范围是0~int64_max(9223372036854775807),假设每秒可以穷举10000次,需要9223372036854775807/(10000x3600x24x365)≈3千万年,这样看来,代价还是很高的。
优化方案:引入权重混淆,也就是在模型算子的权重上面加扰,执行推理时动态解扰。扰动是以 obf_random_seed作为随机种子生成的,如果推理时传入的 obf_random_seed与模型混淆时设置的不同,权重解扰就会错误,从而导致推理结果不正确;从而可以去掉Equal的判断,不会泄露R。
3.1.4.2基于用户自定义函数的判定模式
在这种模式下,switch选择分支的逻辑由用户自己定义。如下图所示,customized_func()是用户自定义的函数,p和q取自节点A输出的Tensor矩阵中的两个元素。customized_func()要满足这个条件:对于任意的输入p和q,customized_func的返回结果恒为True或者恒为False。为什么要满足这个条件?因为对于不同的推理样本,p和q很可能是不同的,为了保证模型能一直选择正确的分支执行,customized_func的结果就必须是恒定的。
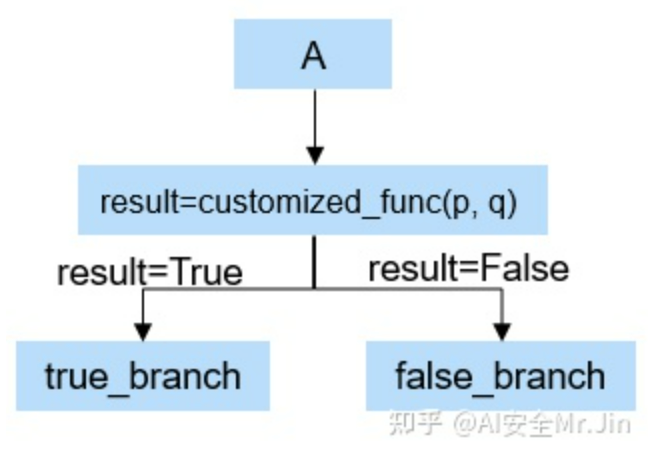
switch结构体-3
需要注意的是,模型文件(比如MindSpore IR格式)中只能保存算子名,并不会保存算子的计算逻辑,所以我们在修改模型结构的时候,只能在模型图里面插入算子名'customized_func',并不会记录函数的主体逻辑(也就是即使攻击者拿到了模型文件,也不知道自定义函数的计算逻辑)。于是在混淆模型的时候,我们调用用户在Python层定义的customized_func来决定把真实节点放在true_branch还是false_branch。加载混淆模型推理的时候,用户同样需要在Python层定义好这个函数,然后框架在推理过程中会调用这个函数的返回结果。
如果仅仅按上面的逻辑设计判定方式,那么攻击者可以这样简单地攻破:定义 attack_func(p, q): return True 或者 attack_func(p, q): return False,然后把attack_func作为 customized_func,一定有一种情形的结果和设置正确的 customized_func得到的推理结果相同。造成这种情形的原因就是每个switch节点在选择分支时,调用 customized_func返回的结果都相同,而不像obf_random_seed模式中,每个switch节点的判定条件都使用了不同的Ni。
所以我们在代码实现的时候,采用了下面这种方式提升安全性:
首先获取用户设置的自定义函数名func_name,并且把函数名的每个字母转成数字保存在func_name_code_中:
func_name_code_.clear();
std::transform(func_name.begin(), func_name.end(), std::back_inserter(func_name_code_),
[](const char &item) { return static_cast<int>(item); });然后第i次调用customized_func的时候,这样确定result的值:
int even_num = 2;
if (func_name_code_[i % func_name_code_.size()] % even_num == 0) {
i += 1;
return customized_func(p, q);
}
i += 1;
return !customized_func(p, q);举个例子:
假如用户在混淆模型的时候,设置的func_name是'my_func',包含7个字符,我们把它转成数字列表:[109, 121, 95, 102, 117, 110, 99]。
在创建第1个switch节点的时候,i=0,func_name_code_[i % func_name_code_.size()=109,109为奇数,所以result=!customized_func(p, q);
在创建第2个switch节点的时候,121为奇数,所以result=!customized_func(p, q);
...
在创建第6个switch节点的时候,110为偶数,所以result=customized_func(p, q);
在创建第7个switch节点的时候,99为奇数,所以result=!customized_func(p, q);
在创建第8个switch节点的时候,109为奇数,所以result=!customized_func(p, q);
在创建第9个switch节点的时候,121为奇数,所以result=!customized_func(p, q);
...
也就是说,result的值不仅和customized_func()的值有关,还和函数名以及调用次序i有关(所以在加载混淆模型进行推理的时候,i要复位为0)。这样的话,除非攻击者知道原来的自定义函数名,否则是不能得到正确结果的。
需要注意的是,由于result的值和调用customized_func()的次序有关,所以在模型混淆的处理过程中和加载混淆后模型进行推理时,被保护节点的处理顺序和推理执行先后顺序要一致,否则会导致错误。举个例子,假如在混淆的时候,先后对A、B、C三个节点进行了保护,也就是构造了3个switch结构、调用了三次customized_func(),假设这3次调用得到的result值分别是True、False、True,那么A、B、C分别会被放在switch的true_branch、false_branch、true_branch中。完成混淆后,加载混淆模型进行推理,由于要执行3个switch结构体,所以也要调用3次 customized_func,对应结果同样是True、False、True,如果在这个过程中,A、B、C的执行顺序是B、A、C,那么在执行含有B的switch结构体的时候,会选择true_branch中的节点,但实际上在混淆的时候,B是放false_branch中的,所以会导致推理结果错误。
为了避免上述错误,我们在遍历图的节点做混淆的时候,会先调用sorted_nodes = TopoSort(node)接口,把获取到的节点的顺序排列成模型推理时的节点执行顺序。
3.1.5 全图混淆遍历算法(仅对于3.1.2中的方案一)
以上只是讲述了对于一个节点或者一部分子图进行混淆的方式,那么对于一个完整的AI模型,我们如何去选取混淆的部分?进行什么方式的混淆呢?这节将给出答案。
首先,对于目前已经支持混淆的算子,我们内置了一份算子白名单。先使用sorted_nodes.reverse()逆向遍历模型的所有算子节点(也就是从模型的最下层往上遍历),当遇到一个可混淆算子时,我们把该算子和算子名称分别存储在字典node_dict_和列表node_names_中,并且向上查找他的父节点,如果父节点也为可混淆算子,则存储该父节点并持续向上查找,直到父节点为不可混淆算子,我们将这个不可混淆的父节点的名称存储在另一个列表parent_names中,该节点即为我们添加switch算子和伪分支的地方。这样操作会让我们对任意输入模型生成一个混淆目标算子名称列表,一个父节点名称列表和一个节点字典,如下图所示:
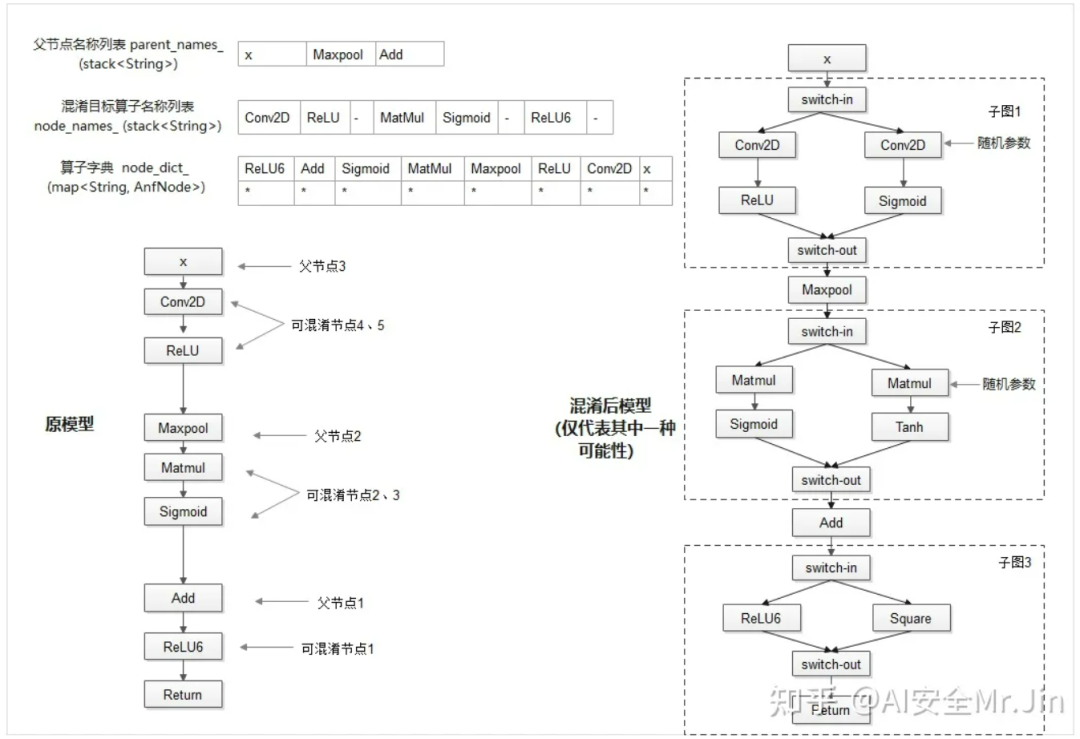
遍历算法图示
这样的储存可以大大提升后续查找算子的效率。后续在做子图伪分支混淆时,可直接使用混淆目标列表中的节点生成伪分支中的算子节点,并将switch算子、原始分支和伪分支添加到对应的父节点位置上。在存储可混淆节点时,我们添加了随机性,即有一定概率不混淆该算子,保证了即使模型相同,每次混淆后的结果也不一样,提高了安全性。
3.1.6 权重混淆算法
3.1.4.1节提到了使用权重混淆可以提升结构混淆的安全性。另外,使用权重混淆也可以保护模型的权重信息。
权重混淆的思路也很简单。参考论文[3]中的乘法加扰的方式,在混淆模型时,把线性算子(卷积算子、全连接算子等)的权重乘以一个系数μ(基于混淆随机种子生成),同时在该算子后面插入一个乘法算子,乘法算子的一个输入是原线性算子的输出,另一个输入来自模型推理时的额外输入。以卷积算子为例,混淆后的计算图如下所示:
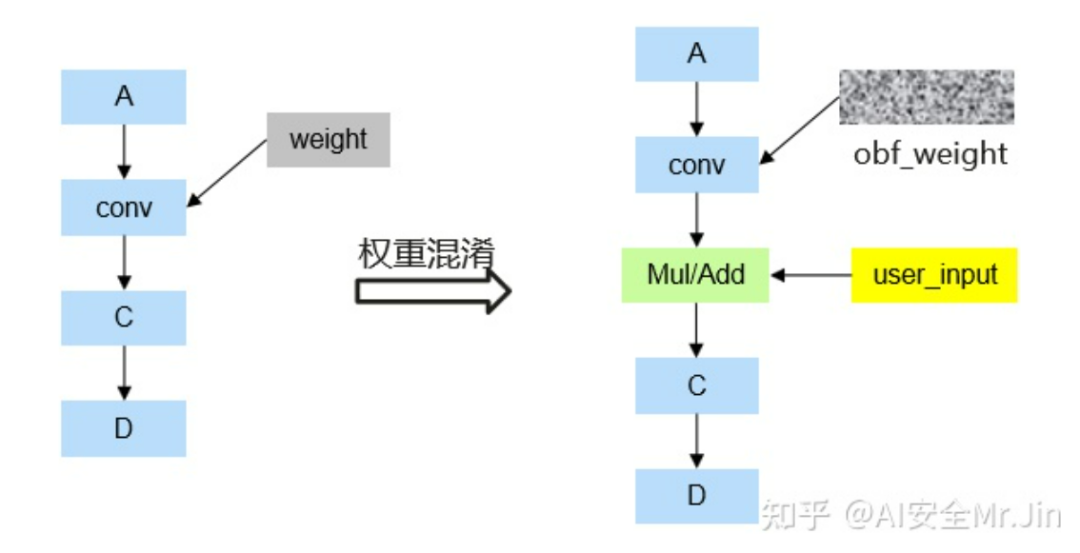
权重混淆图示
3.2 代码实现设计
3.2.1 流程概览
模型动态混淆目前已基于昇思MindSpore进行了实现[4],实现流程图如下所示:
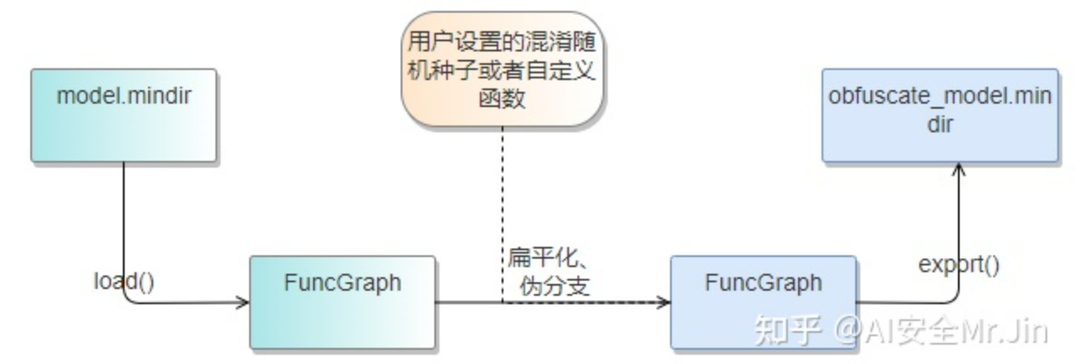
模型混淆代码流程
上图为动态混淆过程,对于一个待混淆的MindSpore IR格式的模型,先使用load函数将其转为FuncGraph格式,然后基于动态混淆算法(伪分支、扁平化、权重混淆)对ANF图进行修改,在修改过程中,要使用控制流算子Switch创建混淆分支,且在插入控制流算子时,使用用户设置的控制流函数或者混淆种子作为分支选择依据。混淆结束后,会输出一个混淆之后的MindSpore IR模型,敌手此时若窃取到了混淆后的模型,也很难知道原模型的真实结构,并且在不知道混淆种子或者用户的自定义函数的情况下,不能使用模型进行正确的推理。
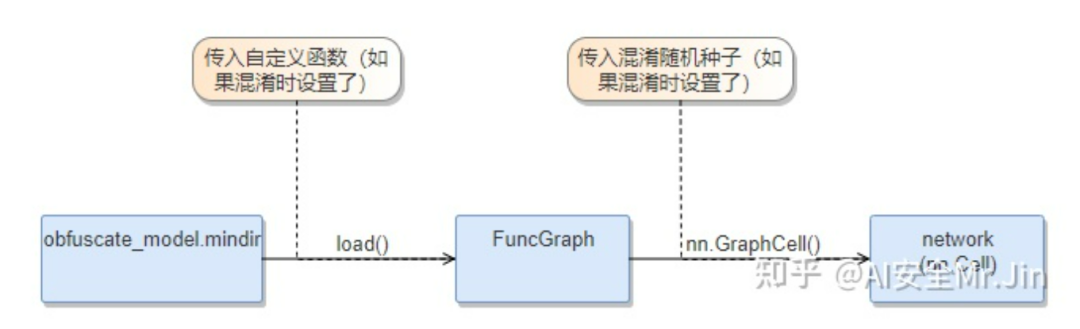
混淆模型推理流程
上图为使用混淆模型的过程。和正常MindSpore IR模型的导入、推理过程(network=nn.GraphCell(load(model.mindir)))相比,导入混淆模型主要有以下不同:
1、若用户在混淆模型阶段设置了自定义函数,则在导入混淆模型的时候,需要在load()接口中传入之前定义的函数(Python函数);
2、若用户在混淆模型阶段设置了混淆种子,则在导入混淆模型的时候,需要在nn.GraphCell()函数中传入混淆种子。
3.2.2 实现细节
模型动态混淆提供了export()、obfuscate_model()、load()等Python接口供用户调用,内部实现则是基于C++接口做的。具体新增和改动的接口、文件如下
1 mindspore/python/mindspore/train/serialization.py里增加了obfuscate_model()函数,作为对外接口;
2 mindspore/ccsrc/pipeline/jit/http://pipeline.cc增加了动态混淆主函数DynamicObfuscateMindIR();
3 mindspore/ccsrc/utils/下面加了dynamic_obfuscation目录,放置动态混淆相关的文件,其中包括动态混淆核心逻辑代码http://dynamic_obfuscation.cc和用户自定义函数注册文件http://registry_opaque_predicate.cc;
4 mindspore/core/ops/目录下增加了http://opaquePredicate.cc,作为用户自定义函数算子的后端原语,做混淆的时候需要在原模型的FuncGraph中插入该算子;
5 mindspore/ccsrc/plugin/device/cpu/kernel/增加http://opaque_predicate_kernel.cc,对应于http://opaquePredicate.cc的CPU后端实现。
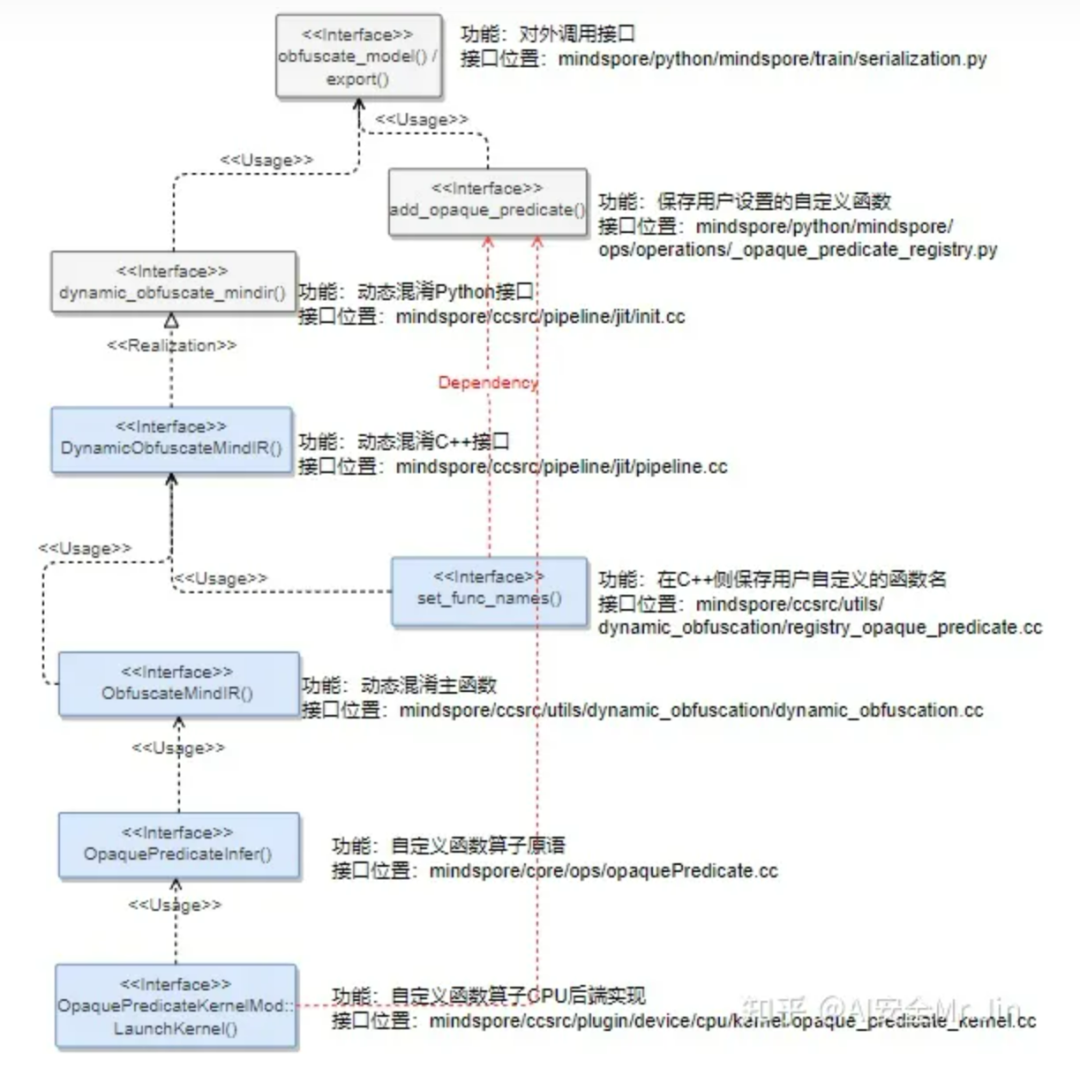
接口调用关系图
上图是内部接口依赖关系图,灰色模块代表Python接口,蓝色模块代表C++接口。
混淆逻辑的实现是在C++中做的,而提供给用户使用的接口是Python接口,他们之间通过mindspore/ccsrc/pipeline/jit/http://init.cc[6]中的接口定义连接:
(void)m.def("dynamic_obfuscate_mindir", &mindspore::pipeline::DynamicObfuscateMindIR, py::arg("file_name"),
py::arg("obf_ratio"), py::arg("branch_control_input") = py::int_(0), py::arg("dec_key") = nullptr,
py::arg("key_len") = py::int_(0), py::arg("dec_mode") = py::str("AES-GCM"),
"Obfuscate a mindir model by dynamic obfuscation.");在customized_func模式下,用户传入的Python函数先由add_opaque_predicate()保存,然后由http://registry_opaque_predicate.cc保存在C++环境中。在模型混淆要用到自定义函数逻辑的时候,通过OpaquePredicateInfer()和OpaquePredicateKernelMod::LaunchKernel()去间接调用。要注册自定义函数算子的原因是算子是模型的基本组成单位,要想在模型执行推理的时候调用用户自定义的函数逻辑,就需要把自定义函数的调用封装成算子的形式。
3.3 使用场景
模型动态混淆是基于MindSpore IR语法实现的(也就是对FuncGraph对象进行混淆处理),目前支持以下两种场景:
① 用户已经训练好了一个nn.Cell类的network,在使用export() 接口导出MindSpore IR模型时,可以传入动态混淆参数,得到一个混淆后的MindSpore IR模型;
② 用户有一个未混淆的MindSpore IR模型,想对其进行混淆,可以采用新增的Python接口obfuscate_model() 进行混淆。
使用样例(官网教程链接[7]):
该特性提供的基本功能包括混淆模型和导入混淆后的模型,通过Python接口供用户调用,示例:
混淆模型:
场景1,在export mindir时进行混淆:
from mindspore import export
obf_config = {'obf_ratio': 0.01, 'obf_random_seed': 1, 'customized_func':f1}
export(net, input, file_name="obf_net", file_format="MINDIR", obf_config=obf_config)上面代码的功能是把nn.Cell类的net导出成一个混淆后的mindir文件。
场景2,把一个已有的MindSpore IR模型进行混淆:
from mindspore import obfuscate_model
obf_config = {'original_model_path': "xxx.mindir",
'save_model_path': "./obf_net", 'model_inputs': [input, ],
'obf_ratio': 0.01, 'obf_random_seed': 1, 'customized_func':f1}
obfuscate_model(obf_config)上面代码的功能是把MindSpore IR模型xxx.mindir进行混淆,输出成混淆后的MindSpore IR模型obf_net.mindir。
运行混淆后的模型:
1、如果用户在混淆模型的阶段设置了'customized_func',那么可以如下加载推理混淆后的模型:
from mindspore import load
import mindspore.nn as nn
custom_ops=f1
obf_graph = load("obf_net.mindir", obf_func=custom_ops)
obf_net = nn.GraphCell(obf_graph )
print(obf_net(input).asnumpy())2、如果用户在混淆模型的阶段设置了'obf_random_seed',那么可以如下加载推理混淆后的模型:
from mindspore import load
import mindspore.nn as nn
obf_graph = load("obf_net.mindir")
obf_net = nn.GraphCell(obf_graph, obf_random_seed=xx)
print(obf_net(input).asnumpy())04 加入我们一起讨论
如果您对模型动态混淆感兴趣,或者有新的想法,欢迎加入Trusted AI SIG[8],和我们一起探讨!(添加MindSpore小助手微信 'mindspore0328',发送“加入Trusted AI SIG”,就可以加入我们SIG微信群噢!)
扫码添加MindSpore小助手

参考链接
[1]https://zhuanlan.zhihu.com/p/591593493
[2]https://gitee.com/mindspore/mindspore/blob/r2.0/mindspore/python/mindspore/common/api.py
[3]https://www.usenix.org/system/files/atc22-shen.pdf
[4]https://gitee.com/mindspore/mindspore/tree/r2.0/mindspore/ccsrc/utils/dynamic_obfuscation
[5]http://findresultsonline.com/?dn=pipeline.cc&rg=2686291&_slsen=0&pid=9PO7FO5YW
[6]https://init.cc/
[7]https://mindspore.cn/mindarmour/docs/zh-CN/master/dynamic_obfuscation_protection.html
[8]https://mindspore.cn/community/SIG/detail/?name=Trusted%20AI%20SIG

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









