






在ChatGPT发布后的三个季度,人们对LLM的态度也从追捧到狂热再到冷静。随着开源社区不断的推陈出新,以及各个厂商各类Chat-LLM的不断发布,大家的目光也逐渐朝着LLM的实用性转移。LLM的训练是一个非常耗费资源的事项,不管是出于降本增效还是环保的考虑,包括LLM高效预训练、高效参数微调、无损量化等等方向都广受关注。但是这次我们来看一个似乎没那么热门但又很水到渠成的话题——LLM lifelong learning。
Continual lifelong learning
Lifelong learning的概念其实很好理解,人工智能是为了构造拟人化的智能体,那么很自然地会想要让模型能够像人一样不断接受新的事物并学习,而非进行模型训练后仅能在一个或多个task使用,而无法持续更新的方法。和其他的学习范式一样,实际上在学术界Lifelong learning(Continual learning, CL)也算是个自成一脉的子领域,但是本身又和很多领域有很大程度的交叉,这里援引20年一篇survey[1]来简要介绍下Lifelong learning的概念。
持续学习的目标是在模型持续输入学习新数据的同时避免旧知识的遗忘,这里摘出几个性质及其定义:
| 性质 | 定义 |
|---|---|
| 知识记忆(knowledge retention) | 模型不易产生遗忘灾难 |
| 前向迁移(forward transfer) | 利用旧知识学习新任务 |
| 后向迁移(backward transfer) | 新任务学习后提升旧任务 |
| 在线学习(online learning) | 连续数据流学习 |
| 无任务边界(No task boudaries) | 不需要明确的任务或数据定义 |
| 固定模型容量(Fixed model capacity) | 模型大小不随任务和数据变化 |
Survey里还列举了各学习范式具备的性质和常见的一些持续学习方法,由于是2020年的论文,这里就不再赘述,只使用同样的形式来看看LLM所具备的性质。
| 性质 | 说明 | |
|---|---|---|
| 知识记忆(knowledge retention) | √ | LLM预训练后,具备世界知识,小规模finetune不易对LLM造成遗忘灾难。但大规模数据续训会造成。 |
| 前向迁移(forward transfer) | √ | 基于世界知识的Zero shot、few shot、finetune。 |
| 后向迁移(backward transfer) | - | Finetune后会可能会造成部分任务的性能下降。二次finetune会损失首次finetune性能。 |
| 在线学习(online learning) | × | 离线预训练、微调。 |
| 无任务边界(No task boudaries) | √ | Unsupervised预训练、微调,不区分任务。 |
| 固定模型容量(Fixed model capacity) | √ | LLM预训练后大小不变。 |
从上表可以看出,LLM实际上已经满足了大部分持续学习的性质,百亿千亿级别的大模型经过充足的预训练后,具备大量世界知识以及涌现能力,基于此进行终身学习成为可能。
那么LLM的终身学习应该使用什么方法呢?常见的持续学习方法,包括Rehearsal(排练), Regularization(正则), Architectural(结构改造)等方式在LLM的参数量和训练模式下其实都不太适用。而LLM本身为了增大参数量和减少推理成本的混合专家方法(Mixture of Experts, MoE) 似乎成了LLM终身学习的新途径。
MoE的前世今生
Vanilla MoE
MoE是一个已经有30多年历史,且十分实用的技术。最早的MoE更多地类似于ensemble的概念,即:使用多个模型来共同提高任务性能。在实际的数据分布中,存在着很多天然的子集,如不同的domain、topic,不同的语言、不同的模态等等,在使用单个模型进行学习,且模型capacity较小的情况下,不同子集会起到噪声的作用,干扰模型的拟合,导致模型训练慢、泛化困难。MoE的思想就是构造多个模型(每个模型称为专家Expert),将不同子集的数据分发到不同模型进行训练,减少不同类型样本间的干扰。下图是经典的MoE[2]示意图:
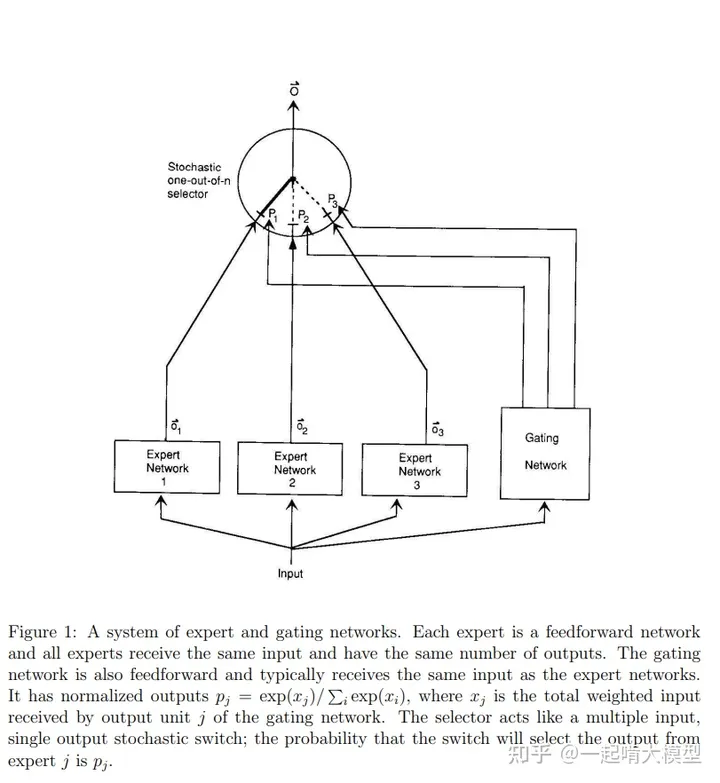

彼时的MoE思路简单但有效,启发了后续诸多MoE相关工作。Expert的竞争或合作,以及Gating Network的分发方式,也成为了MoE演进过程中不断更迭演进的方向。时间很快到了2017年,当下MoE系统的雏形初现了。
Sparse MoE
在前Transformer时代,使用RNN构造的神经网络很难做到很大很深,且硬件利用率也不高。Google Brain的Shazeer, Noam, 等人[3]提出使用稀疏的MoE结构来将模型容量做大的方法,即:训练时使用海量Expert,推理时激活少数Expert。
前文讲到的Vanilla MoE本身要达成的效果便是单样本单Expert处理,因此训练完成后的模型在推理时只会用到很少的Expert,这样在推理阶段实际上能够节省大量的算力资源。因此稀疏的MoE无疑是一种很经济的模型训练策略。下图是Sparse MoE的示例:
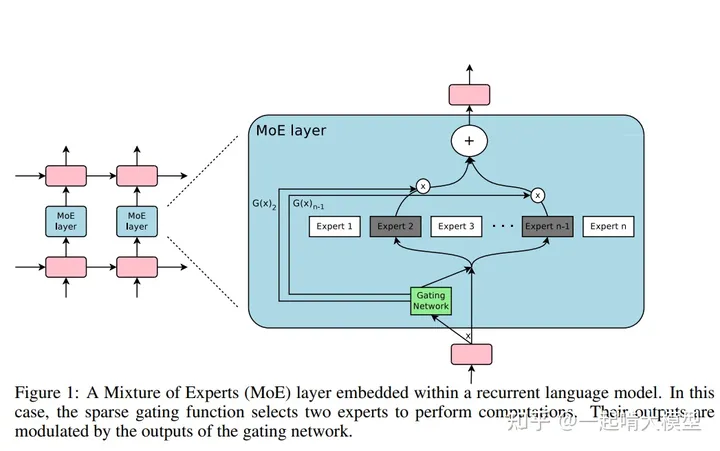
如图所示,模型共有n个Expert,Gating Network选择少数Expert进行计算。此外,该工作还发现了后续影响MoE研究的一大现象——赢者通吃:在训练过程中前期编号的expert会更容易被gating network选择,导致只有少数几个expert有用,这被称为Expert Balancing问题。这时的Sparse MoE目标方向是将模型做大,以及经济高效地进行训练推理。同年,能够并行训练的Transformer的出现将所有人的目光都汇聚了过去,大模型时代的序幕逐渐升起。
Transformer MoE
Transformer在NLP领域大杀四方,不论是Encoder结构BERT的刷榜,还是Decoder-only GPT在zero shot的大放异彩,大家不停地改进着Transformer模型的结构和效果,也逐渐提升着模型的参数量,直到再次触碰到硬件资源的瓶颈。
当模型参数量到了千亿这个级别以后,再想向上扩展变得愈发困难,经济实用的MoE又被重启。还是Google,提出了GShard[4],首个将MoE思想拓展到Transformer的工作,而后Siwtch Transformer[5]、GLaM[6]等工作持续改进着Transformer MoE的结构,也将LLM的参数量从千亿推向了万亿级别。
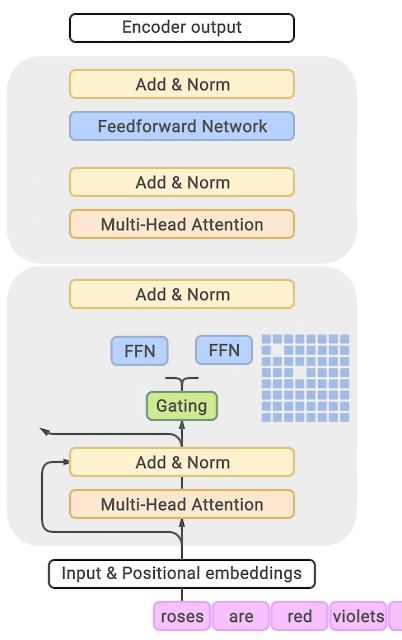
这里我们放一个GLaM的示意图,在Transformer的encoder和decoder中,间隔一个(every other)FFN层,替换成position-wise 的 MoE层。Gating network使用的Top-2路由,选择概率最高的两个expert。
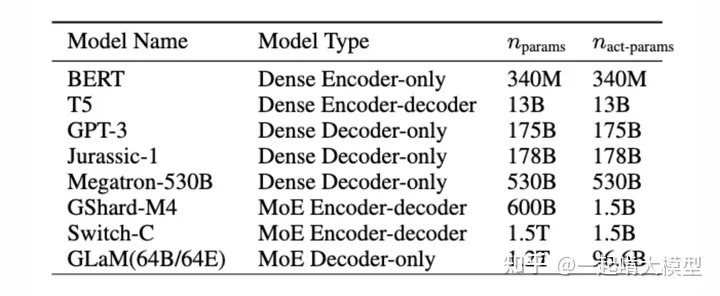
凭借着MoE的稀疏激活能力,GLaM训练了1.2T(1.2万亿)参数,但在推理时仅需要96B(960亿)参数,比起GPT3大约节省了一半的资源,推理速度也大幅提升。后续的大量万亿级参数量的LLM均选择了MoE的方式,甚至近两个月在网络上盛传GPT4也是一个MoE结构。MoE也逐渐成为了LLM的一个重要发展方向。
MoE和Lifelong learning
讲了这么久的MoE,和Lifelong learning又有什么关系呢?这里我们再回顾一下Lifelong learning的目标:模型不断学习持续的信息流来获得在各种任务上都能适用的能力。而当下的LLM通常的做法是什么呢?Finetune或续训。虽然LLM在学习了大量世界知识后,不会因为finetune而产生明显的遗忘灾难问题,但是续训和二次finetune都会降低甚至损伤模型的backward transfer能力。
让我们回过头看一下持续学习的几个性质,LLM本身唯一不具备的便是backward transfer能力。再来看MoE的特点:
- 多个Expert分别处理不同分布(domain/topic)的数据。
- 推理仅需要部分Expert。
那么是否可以在LLM持续训练的过程中,通过不断地增添和删减Expert,来实现新知识的学习补充,同时还能保留旧知识训练得到的模型,来达到持续学习的目的,最终实现LLM的终身学习。答案是肯定的。
如果想要实现LLM的终身学习,要满足以下几点:
- 世界知识底座持续学习。实际上当前Transformer结构的MoE都是Vanilla Transformer的侵入式改造,不论是间隔进行FFN的替换还是Dense+Sparse的连接结构,都是为了保留一部分原始Transformer结构,来保证底层语义可以尽可能进行保持。
- Expert可插拔。这一点很好理解,老的Expert不需要的时候要移除,新的Expert要增加。
- Gating Network可增删。由于Gating Network本身影响输入的路由分发,实际上在去除Expert时也需要Gating Network进行相应的改变,否则会产生随机路由导致输出结果完全错误的问题。
有了这几点目标后,我们选择两个思路完全不同但又都达成了LLM终身学习的两个工作进行深入解析。
Lifelong-MoE
没错,还是谷歌。MoE和Transformer的持续演进和结合都源于谷歌,Lifelong learning自然也是谷歌打头。Lifelong-MoE[7]是今年5月份的工作,其思路是将旧expert冻结,训练新expert。下图是其模型主要结构。
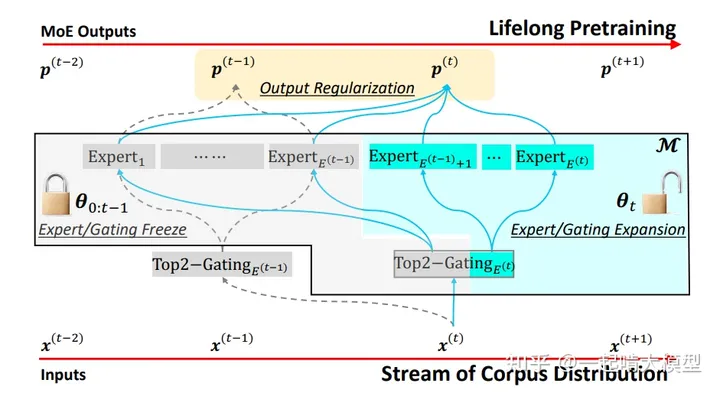
模型的Lifelong learning策略包含以下步骤:
- 扩增Expert数量及对应的Gating维度。
- 冻结旧Expert和对应的Gating维度,只训练新Expert。
- 使用Output Regularization方法来保证新Expert继承过去学习到的知识。
该方法能够实现LLM终身学习的几个目标,但是由于Gating Network本身也是个可学习的神经网络层,不得不增加了Regularization来解决遗忘灾难问题。但是该工作还是为LLM的Lifelong learning打下了一个很好的基础。
接下来介绍的是稍早一些且思路更加简单粗暴的工作——既然Gating Network可学习难以满足Expert增删的需要,那么手动Gating就好。
PanGu-Sigma
Pangu-sigma[8]是今年3月华为诺亚方舟实验室基于Pangu-alpha模型进行MoE扩充实现的Lifelong-MoE模型。其提出了随机路由专家(RRE)方法,使得Gating Network也可以随着Expert进行裁剪。下图是PanGu-Sigma的示意图:
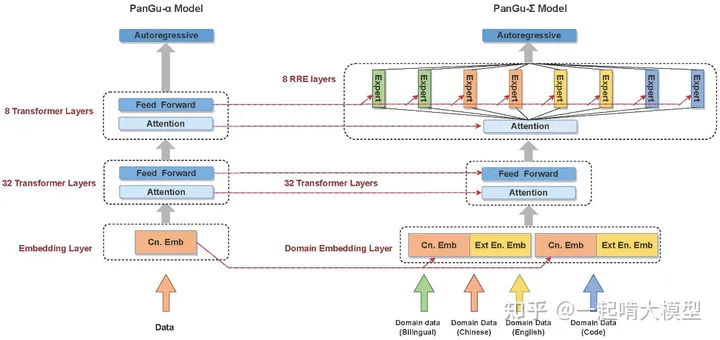
这里着重讲一下RRE的设计。前面提到既然可学习的Gating Network很难裁剪,那么可以简单粗暴地使用手动Gating地方式。RRE就是这样地思路,只是为了缓解过于粗暴的领域区分(持续学习的性质之一就是无任务边界,手动Gating一定程度上违背了这一点),RRE做了双层的设计:
- 第一层,根据任务分配给不同的专家组(多个expert构成一个专家组,供一个task/domain使用)。
- 第二层,使用组内随机Gating,让专家组的expert可以负载均衡。
这样带来的好处是显而易见的,只要对专家组进行裁切,可以完全剥离出某个领域的子模型进行推理部署,同时也可以不断地更新迭代新的专家组,实现Lifelong-learning。下图是预训练好的MoE模型进行子模型抽取的示意图。
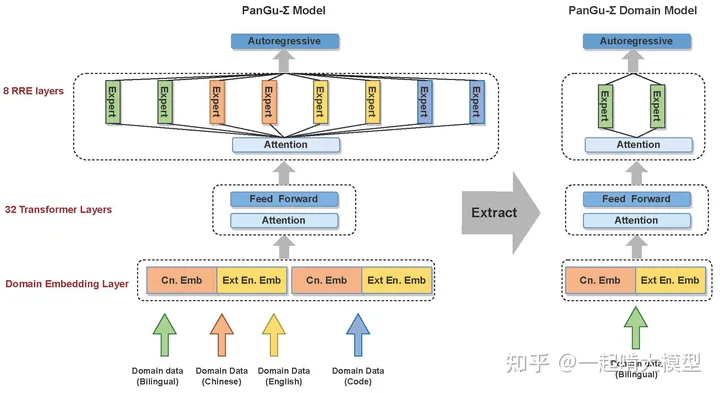
通过这样的设计,PanGu-Sigma能够根据实际需求和场景提取和部署子模型,子模型参数量在百亿量级,可以实现性能、效率、可用性和部署的均衡。
以上两个工作,是Lifelong-MoE的两个典型工作,也分别延续了两家公司LLM的能力。但值得额外一提的是,MoE LLM实际上从训练起点分为了两派,分别是from scratch和from pretrained,而GPT4据称是from scratch的8个Expert集合,某种意义上可能更像是回到了ensemble阶段,更多是为了业务效果而非LLM的持续演进。
MoE的问题
Lifelong-MoE看起来很好用,但是万事皆无完美,但MoE方法本身还是有一些问题,下面进行简单的介绍,也算是后续演进方向的探讨。很多人认为MoE难以训练,也跟这几个问题相关。
MoE结构复杂度
前文讲过,Transformer的MoE会对FFN层进行MoE扩展,但是Transformer结构本身还有Multihead Attention结构,这使得MoE扩展会变成Transformer结构的侵入式改造,而不管是训练前并行化的侵入式改造,还是训练完成后进行子模型的抽取,都会因为复杂的结构而需要投入大量人力(当然,这利好算法工程师)。同时由于结构的复杂,加上LLM的资源要求,可以预见学术界鲜有团队能够持续投入Lifelong-LLM的研究。
Expert balancing
然后回到MoE本身的缺陷,即Expert balancing问题。这个问题可以被归结为两个层面:
- 物理世界规律造成的不均衡。2-8定律在此,总会有一部分任务或领域占据所有数据的大部分,也一定会有长尾数据,使用等参数量、随机Gating的方式进行强制的均衡分配,实际上也是在伤害模型对现实世界的拟合。
- 神经网络特点决定的嬴者通吃。Gating Network可学习会很自然的朝着几个拟合较好的Expert进行数据分配,这一点仍需要大量的尝试和研究,也许可以缓解,也许可以解决。
分布式通信问题
最后是比较现实的系统问题,当下的LLM预训练必然是要使用分布式并行切分的,而MoE结构和普通的Dense模型的差异在于,其需要额外的AllToAll通信,来实现数据的路由(Gating)和结果的回收。而AllToAll通信会跨Node(服务器)、跨pod(路由),进而造成大量的通信阻塞问题。如何高效地实现AllToAll通信也成为了诸多框架的演进重点,当下包括Tutel、DeepSpeed-MoE、Fast-MoE、HetuMoE等框架都对其进行了额外的优化加速,如MindSpore等底层框架也加入了硬件耦合的AllToAll优化,但当下对于MoE结构需要的通信加速仍需要持续演进和发展。
展望
不知不觉写成了个小survey,虽然并没有把工作列全,但还是将Lifelong-MoE这一概念进行了较为深入的剖析。从ChatGPT出现到现在,LLM仍旧火热,甚至被奉为第四次工业革命,相信不论是工业界还是学术界,都会持续对LLM进行创新和突破,而LLM的Lifelong learning,也一定会称为LLM推陈出新的动力源泉。
参考
- ^Biesialska M, Biesialska K, Costa-Jussa M R. Continual lifelong learning in natural language processing: A survey[J]. arXiv preprint arXiv:2012.09823, 2020.
- ^JACOBS R, JORDAN M, NOWLAN S, 等. Adaptive Mixture of Local Expert[J/OL]. Neural Computation, 1991, 3: 78-88. Adaptive Mixtures of Local Experts | Neural Computation | MIT Press
- ^SHAZEER N, MIRHOSEINI A, MAZIARZ K, 等. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer[M/OL]. arXiv, 2017[2023-08-15]. http://arxiv.org/abs/1701.06538
- ^LEPIKHIN D, LEE H, XU Y, 等. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding[M/OL]. arXiv, 2020[2023-08-15]. http://arxiv.org/abs/2006.16668
- ^FEDUS W, ZOPH B, SHAZEER N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity[J]. The Journal of Machine Learning Research, 2022, 23(1): 120:5232-120:5270.
- ^DU N, HUANG Y, DAI A M, 等. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts[C/OL]//Proceedings of the 39th International Conference on Machine Learning. PMLR, 2022: 5547-5569[2023-08-15]. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
- ^CHEN W, ZHOU Y, DU N, 等. Lifelong Language Pretraining with Distribution-Specialized Experts[M/OL]. arXiv, 2023[2023-08-15]. http://arxiv.org/abs/2305.12281
- ^REN X, ZHOU P, MENG X, 等. PanGu-{\Sigma}: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing[M/OL]. arXiv, 2023[2023-08-15]. http://arxiv.org/abs/2303.10845

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









