







文章链接:EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
1.基础背景
大型语言模型(LLMs),如GPTs和LLaMa,由于其在广泛的机器学习任务中的卓越能力,引领了机器智能的革命。LLM从数据中心向边缘设备的下沉转移慢慢成为一种趋势:
- 高通在智能手机上部署了一个文本图像生成的LLM模型,该模型包含超过10亿个参数。
- 华为在智能手机中嵌入了一个多模式的LLM,以促进基于自然语言的准确内容搜索
这种转移趋势带来了一系列机遇和挑战。一方面这种转变可以增强隐私性和可用性,另一方面是模型庞大的参数量和不可承受的运行成本的挑战。
混合专家模型(MoE)是一种稀疏门控制的深度学习模型。它由一组专家模型和一个门控模型组成。MoE的基本理念是将输入分割成多个区域,并对每个区域分配一个或多个专家模型。每个专家模型可以专注于处理输入的一部分,从而提高模型的整体性能。
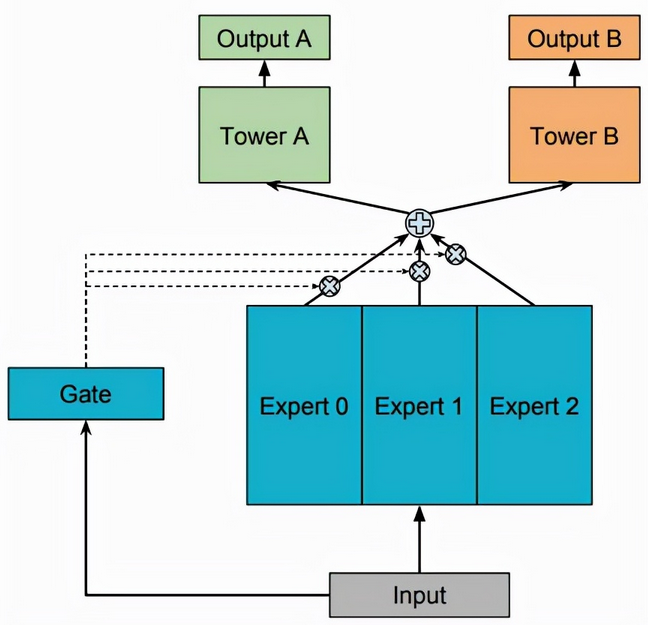
由于稀疏性的设计,MoE LLMs(结构如下图所示)能够在几乎恒定的计算复杂度下扩展其参数大小和能力,使其很好地适合于存储成本比计算容量更低、可扩展的边缘设备。但是 MoE LLMs太大了,无法装入设备内存。例如,Switch transformer(每层有32个专家)需要54GB的内存来进行推理,这在大多数边缘设备上都是负担不起的。简单地缩小专家数量会显著降低性能容量;或者,由于LLM的自回归特性,频繁地在内存和存储之间交换权重会导致巨大I/O的开销。
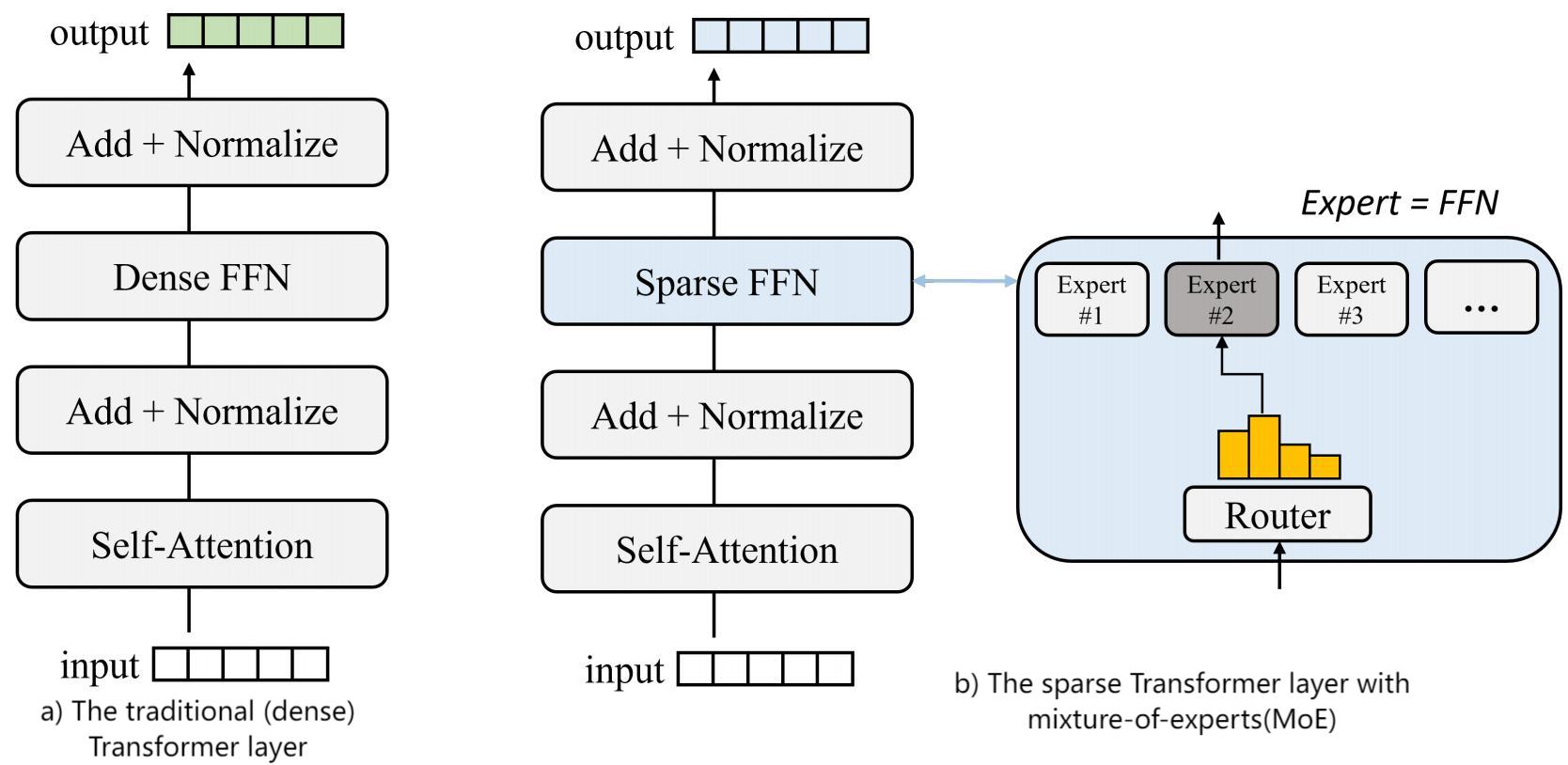
鉴于MoE 模型在 推理过程中需要占用庞大的内存,为了降低MoE在推理过程中的内存消耗,目前学界有以下几个方法:
- 模型压缩 :通过对MoE模型进行压缩,可以减少模型参数量,从而降低内存消耗常用的压缩方法包括剪枝、量化和蒸馏等
- 分布式推理 :将MoE模型分布式部署在多个设备上进行推理,可以将内存消耗分摊到多个设备上,从而降低单个设备的内存消耗
- 优化推理算法 :通过优化MoE模型的推理算法,可以减少模型计算量和内存消耗常用的优化方法包括缓存、并行计算和异步计算等
2.EdgeMoE:边缘设备部署的推理引擎
内容简介:
EdgeMoE : Fast On-Device Inference of MoE-based Large Language Models(下面简称EM)提出了一种为混合专家(MoE)大型语言模型(LLM)设计的设备上推理引擎。EM在存储层次结构中战略性地划分模型,将非专家权重存储在设备内存中,而将专家权重存储在外存中,以解决LLM模型从数据中心向边缘设备迁移时,模型参数过大的问题。EM结合了两种创新技术: 专家位宽自适应和 专家管理,以减少与专家I/O交换相关的开销。
- 专家位宽自适应:这种方法在可接受的精度损失水平上降低了专家权值的大小
- 专家管理:提前预测将被激活的专家,并将其预加载到 I/O流水线中
实验表明,EM不但节省了大量的内存资源,而且提升了模型的精度。
试点实验与分析:
作者通过观察Switch Transformer模型inference running process发现MoE模型有以下特征:
- 在提高模型精度的同时,专家的权重会随着模型数量的增加而迅速膨胀。
- 推理期间的大多数计算驻留在一小部分权重(非专家“热权重”)中,而大多数权重(专家“冷权重”)贡献了一小部分计算。这是有一定解释依据的:专家权重虽然大量,但由于稀疏的激活模式,很少被访问。
- 专家权重计算与I/O不对称。即使每层只多load一个专家,也会显著降低MoE的执行性能。
- 计算/IO流水线是不可行的。可以进一步利用计算/IO并行性,将专家loading与权重计算重叠,类似于STI
- 专家激活路径遵循幂律分布。虽然单个专家的总体激活频率是很均衡的,但激活路径,即一个token的所有transformer层激活专家的向量,是高度倾斜的。
ME设计架构
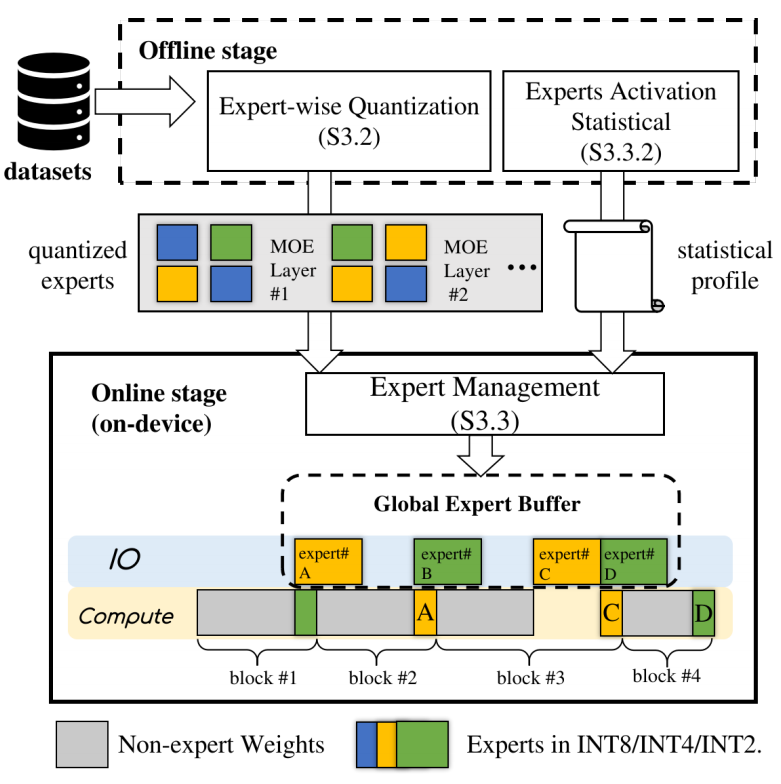
EM的架构大致可分为离线和在线两个系统。
- 离线系统预处理一个预先训练的模型:它描述专家的重要性,然后根据专家评估的重要性将专家量化到不同的位宽。
- 在线系统通过专家缓冲区动态管理设备内存和磁盘之间的专家。通过利用专家激活的统计配置文件,EM预先决定在路由器功能之前从磁盘中取出哪些专家,在缓冲区满时取出哪些专家。
关键技术
技术一:层次存储
基于上述推理过程种不平衡的对象访问,EM战略地在存储层次中划分模型来实现内存和计算效率。具体来说,非专家权重存储在设备的内存中,而专家权重存储在外存中,只有当它们被激活时才会进入内存,也就是专家缓冲区。
使用专家缓冲区设计,EM只要按需将激活的专家从存储器加载到内存。然而,与计算相比,这个I/O开销仍然是显著的(由于I/O开销,推理在Jetson TX2上有高达4.1倍的延迟)。为了进一步降低专家I/O交换的开销,作者提出了专家位宽自适应和专家管理两项技术。前者是通过量化专家模型参数,直接减少I/O数据;后者是将I/O与计算连接起来,以隐藏其延迟。
技术二:专家位宽自适应
作者观察到不同层次甚至同一层次的专家在量化后对模型精度的影响是不同的。因此,EM采用了细粒度的、专家级的位宽自适应来充分利用模型冗余。
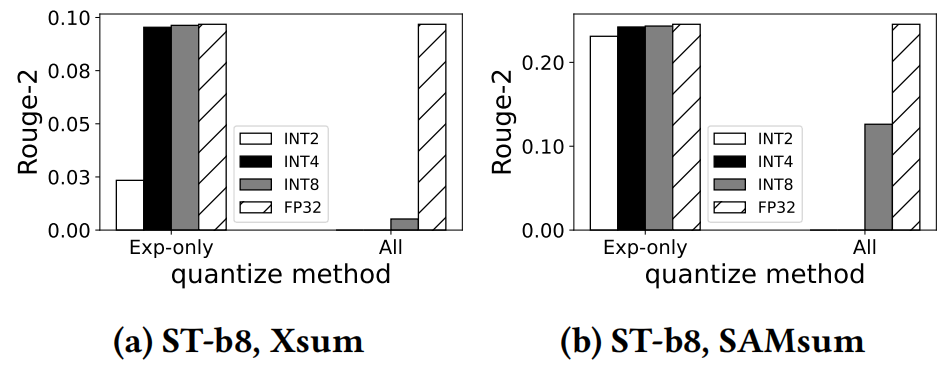
在离线状态下,EM逐步降低少数对量化最健壮的专家的位宽,直到准确度下降达到用户指定的可容忍阈值。在选择哪些专家进一步量化时,还共同考虑了比特宽度较低的量化能在多大程度上提高推理速度。最终,EM得到了一个混合精度模型,该模型以尽可能小的模型尺寸达到目标精度。
技术三:专家管理
作者观察道专家激活路径(即每个令牌的顺序激活专家集)在实践中是高度不平衡和倾斜的。这表明专家激活之间存在显著的相关性。
在离线阶段,EM根据前一层的激活情况,建立统计模型来估计当前层的专家激活概率。在在线推理中,EM查询这个模型,并在I/O-compute流水线激活之前预加载最有可能的专家。此外,EM为专家缓冲区设计了一种新颖的缓存逐出策略,利用激活频率和它们与当前执行的相对位置,决定驱逐的对象。
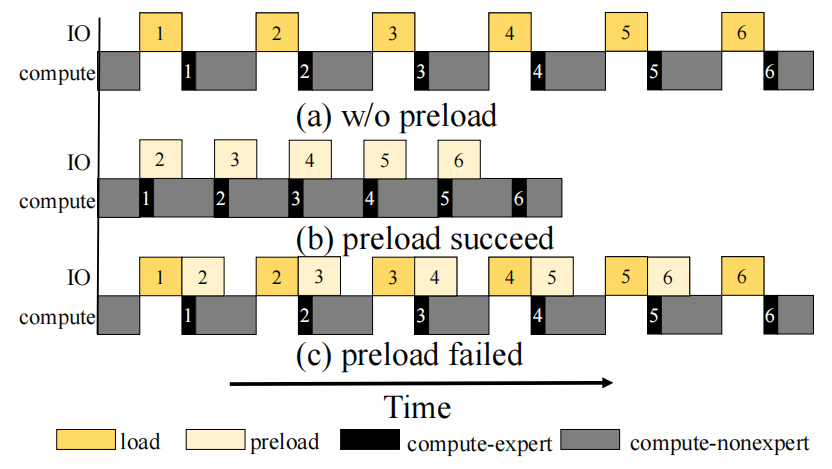
总的来说,无论是预测然后预加载技术还是驱逐技术都是为了在激活专家缓存时最大化专家缓存命中率。
3.总结
EM集成了两种创新技术:专家特定的位宽适应,在可接受的精度损失下减少专家尺寸,以及专家预加载,它可以预测激活的专家,并使用计算 I/O管道预加载他们。实验表明,EM能够在CPU和GPU平台上实现MoE LLM的实时推理,同时保持可容忍的精度损失。


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











