







 这篇CVPR2017论文介绍了如何从视频中无监督学习深度和相机位姿。通过视图合成和光度误差最小化,论文提出使用深度网络和位姿网络分别估计单帧深度和相机位姿。尽管深度预测的精度稍逊于Godard的工作,但它在pose估计上表现出色,尤其是在静态图像为主的场景中。未来的研究方向包括处理物体移动和遮挡,以及无需先验内参的估计。
这篇CVPR2017论文介绍了如何从视频中无监督学习深度和相机位姿。通过视图合成和光度误差最小化,论文提出使用深度网络和位姿网络分别估计单帧深度和相机位姿。尽管深度预测的精度稍逊于Godard的工作,但它在pose估计上表现出色,尤其是在静态图像为主的场景中。未来的研究方向包括处理物体移动和遮挡,以及无需先验内参的估计。
CVPR2017_Unsupervised Learning of Depth and Ego-Motion from Video
这是一篇从一段视频中恢复场景深度和相机pose的论文。
他可能是第一篇用深度学习的方法从一段视频中恢复camera的pose的方法,它用两个网络(严格意义上是3个网络,下文赘述)分别/独自无监督地估计单帧的深度,和视频序列中的camera的pose变化。最终得到的深度达到state of art,pose的精度也与ORB-SLAM2的localization模式(即没有丢失后的重定位以及以关键帧的全局BA为核心力量的回环检测)效果相当。

Q1:pose估计是怎么找到的?
A1:在已知当前帧depth,以及当前帧poses转换到将一个图像序列(视频)中其他帧的情况下,我们知道,可以将当前帧的每一个像素映射到其他帧上,然后最小化当前帧和其他帧映射位对应位置的光度误差来求出这些pose.
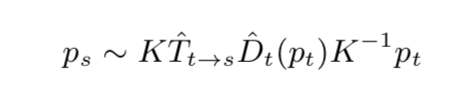
Q2:那么先验深度预测怎么求出?
A2:本文的框架为联合训练depth和pose,因此我猜测是在分别给定depth和p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2413
2413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









