









论文链接
0. Abstract
尽管基于学习的方法在单视图深度估计和视觉里程计方面显示出有希望的结果,但大多数现有方法以监督方式处理任务。最近的单视图深度估计方法探索了通过最小化光度误差在没有完全监督的情况下学习的可能性
探索使用立体序列来学习深度和视觉里程计,框架能够从单目序列估计单视图深度和双视图里程计
- 单视图深度和视觉里程计的联合训练可以改善深度预测,因为对深度施加了额外的约束,并实现了视觉里程计的有竞争力的结果
- 基于深度特征的扭曲损失改进了单视图深度估计和视觉里程计的简单光度扭曲损失
1. Intro
-
提出了一个框架,使用立体视频序列(如图 1 所示)联合学习单视图深度估计器和单目里程估计器进行训练。该方法可以理解为深度估计的无监督学习和立体对之间已知的姿势的半监督学习
-
提出了一种额外的深度特征重建损失,它考虑了上下文信息,而不是单独考虑每个像素的颜色匹配
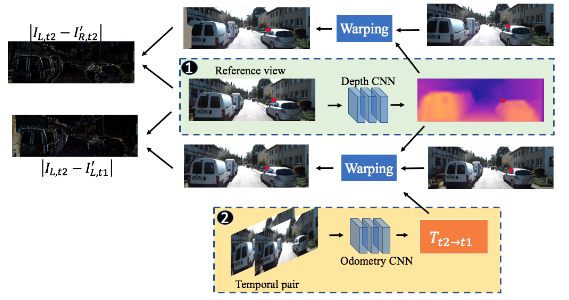
Fig. 1 训练实例示例。立体相机 T L → R T_{L→R} TL→R 之间的已知相机运动限制了深度 CNN 和里程计 CNN,以实际比例预测深度和相对相机姿势
本文贡献
- 一个用于联合学习深度估计器和视觉里程估计器的无监督框架,该框架不会受到尺度模糊的影响
- 利用可从空间和时间图像对获得的全套约束来改进单视图深度估计的现有技术
- 产生最先进的帧到帧里程测量结果,该结果显着改进并且与几何方法相当
- 除了基于颜色强度的图像重建损失之外,还使用一种新颖的特征重建损失,显着提高了深度和里程估计精度
2. Related Work
2.1 监督学习方法
- 使用 ConvNet 估计深度,使用多尺度深度网络和尺度不变损失来进行深度估计
- 将深度估计表述为连续条件随机场学习问题
- 使用全卷积架构的残差网络来对单目图像和深度图之间的映射进行建模
- 使用端到端学习框架来预测立体对的差异
2.2 无监督或半监督方法
使用光度扭曲损失来替换基于地面实况深度的损失,可以从立体图像对中实现无监督深度学习管道
- 使用双目立体对(相机间变换是已知的)并训练一个网络来预测深度,以最小化真实右图像与通过将左图像扭曲到右视点而合成的图像之间的光度差异,使用预测的深度
- 通过引入对称左右一致性标准和更好的立体损失函数对深度估计进行了改进
- 使用提出了一种半监督学习框架,使用稀疏深度图进行监督学习,使用密集光度误差进行无监督学习
所有无监督深度估计方法都依赖于照片一致性假设,而这在实践中经常被违反。故在本文的工作中,比较了多种特征
3. Method
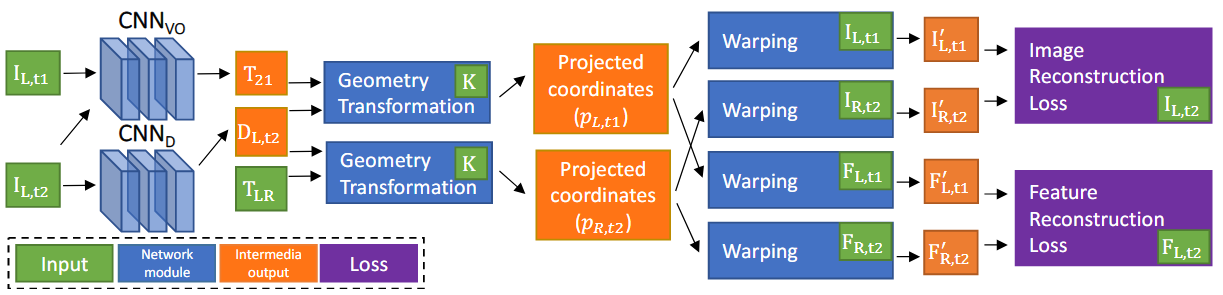
Fig. 2 在训练阶段提出的框架的图示。 C N N V O CNN_{VO} CNNVO 和 C N N D CNN_D CNND 在测试阶段可以独立使用
3.1 图像重建作为监督
本文框架中的基本监督信号来自图像重建任务。对于两个附近的视图,假设参考视图的深度和两个视图之间的相对相机姿态已知,就能够从实时视图重建参考视图
由于深度和相对相机位姿可以通过 ConvNet 来估计,因此真实视图和重建视图之间的不一致允许 ConvNet 的训练
但没有额外约束的单目框架会遇到缩放模糊问题,因此提出了一个立体框架,在给定已知立体基线设置的额外约束的情况下,将场景深度和相对相机运动限制在共同的真实世界尺度中
对于每个训练实例,有一个时间对
(
I
L
,
t
1
,
I
L
,
t
2
)
(I_{L,t1},I_{L,t2})
(IL,t1,IL,t2) 和一个立体对
(
I
L
,
t
2
,
I
R
,
t
2
)
(I_{L,t2},I_{R,t2})
(IL,t2,IR,t2) ,其中
I
L
,
t
2
I_{L,t2}
IL,t2 是参考视图,而
I
L
,
t
1
I_{L,t1}
IL,t1 和
I
R
,
t
2
I_{R,t2}
IR,t2 是实时视图。可以分别从
I
L
,
t
1
I_{L,t1}
IL,t1 和
I
R
,
t
2
I_{R,t2}
IR,t2 合成两个参考视图
I
L
,
t
1
′
I^\prime_{L,t1}
IL,t1′ 和
I
R
,
t
2
′
I^\prime_{R,t2}
IR,t2′
I
L
,
t
1
′
=
f
(
I
L
,
t
1
,
K
,
T
t
2
→
t
1
,
D
L
,
t
2
)
(1)
I^\prime_{L,t1} = f(I_{L,t1},K,T_{t2→t1}, D_{L,t2})\tag{1}
IL,t1′=f(IL,t1,K,Tt2→t1,DL,t2)(1)
I R , t 2 ′ = f ( I R , t 2 , K , T L → R , D L , t 2 ) (2) I^\prime_{R,t2} = f (I_{R,t2}, K, T_{L→R}, D_{L,t2})\tag{2} IR,t2′=f(IR,t2,K,TL→R,DL,t2)(2)
D L , t 2 D_{L,t2} DL,t2 表示参考视图的深度图; T L → R T_{L→R} TL→R 和 T t 2 → t 1 T_{t2→t1} Tt2→t1 是参考视图和实时视图之间的相对相机位姿变换; K K K 表示已知的相机本征矩阵。 D L , t 2 D_{L,t2} DL,t2 通过 C N N D \mathrm{CNN}_D CNND 从 I L , t 2 I_{L,t2} IL,t2 映射,而 T t 2 → t 1 T_{t2→t1} Tt2→t1 通过 C N N V O \mathrm{CNN}_{VO} CNNVO 从 [ I L , t 1 , I L , t 2 ] [I_{L,t1}, I_{L,t2}] [IL,t1,IL,t2] 映射
计算合成视图和真实视图之间的图像重建损失作为监督信号来训练
C
N
N
D
\mathrm{CNN}_D
CNND 和
C
N
N
V
O
\mathrm{CNN}_{VO}
CNNVO 。图像构造损失表示为
L
i
r
=
∑
p
(
∣
I
L
,
t
2
(
p
)
−
I
L
,
t
1
′
(
p
)
∣
+
∣
I
L
,
t
2
(
p
)
−
I
R
,
t
2
′
(
p
)
∣
)
(3)
L_{ir}=\sum\limits_p(\left|I_{L,t2}(p)-I^\prime_{L,t1}(p)\right|+\left|I_{L,t2}(p)-I^\prime_{R,t2}(p)\right|) \tag{3}
Lir=p∑(
IL,t2(p)−IL,t1′(p)
+
IL,t2(p)−IR,t2′(p)
)(3)
使用立体序列代替单目序列的效果是双重的
- 立体对之间已知的相对姿态 T L → R T_{L→R} TL→R 限制了 C N N D \mathrm{CNN}_D CNND 和 C N N V O \mathrm{CNN}_{VO} CNNVO 来估计现实世界尺度中时间对之间的深度和相对姿态
- 除了仅具有一个实时视图的立体对之外,时间对还为参考视图提供第二实时视图
3.2 可微分几何模块
如方程 1 - 2 所示,学习框架中的一个重要函数是综合函数 f ( ⋅ ) f (\cdot) f(⋅)。该函数由两个可微运算组成,允许梯度传播用于 ConvNet 的训练。这两个操作是极线几何变换和扭曲。前者定义两个视图中像素之间的对应关系,而后者通过扭曲实时视图来合成图像
令
p
L
,
t
2
p_{L,t2}
pL,t2 为参考视图中像素的齐次坐标。可以使用对极几何获得
p
L
,
t
2
p_{L,t2}
pL,t2 在实时视图上的投影坐标。投影坐标通过以下方式获得
p
R
,
t
2
=
K
T
L
→
R
D
L
,
t
2
(
p
L
,
t
2
)
K
−
1
p
L
,
t
2
(4)
p_{R,t2} = KT_{L→R}D_{L,t2}(p_{L,t2})K^{−1}p_{L,t2}\tag{4}
pR,t2=KTL→RDL,t2(pL,t2)K−1pL,t2(4)
p L , t 1 = K T t 2 → t 1 D L , t 2 ( p L , t 2 ) K − 1 p L , t 2 (5) p_{L,t1} = KT_{t2→t1}D_{L,t2}(p_{L,t2})K^{−1}p_{L,t2}\tag{5} pL,t1=KTt2→t1DL,t2(pL,t2)K−1pL,t2(5)
其中 p R , t 2 p_{R,t2} pR,t2 和 p L , t 1 p_{L,t1} pL,t1 分别是 I R , t 2 I_{R,t2} IR,t2 和 I L , t 1 I_{L,t1} IL,t1 上的投影坐标。注意 D L , t 2 ( p L , t 2 ) D_{L,t2}(p_{L,t2}) DL,t2(pL,t2) 是位置 p L , t 2 p_{L,t2} pL,t2 处的深度; T ∈ S E 3 T ∈ SE3 T∈SE3 是由 6 个参数定义的 4x4 变换矩阵,其中 3D 向量 u ∈ s o 3 \mathbf{u} ∈ so3 u∈so3 是轴角表示,3D 向量 v ∈ R 3 \mathbf{v} ∈ R3 v∈R3 表示平移
从方程 4 5 获得投影坐标后,可以使用中提出的可微双线性插值机制(扭曲)从实时帧合成新的参考帧
3.3 特征重构作为监督
为了提高框架的鲁棒性,我们提出了特征重建损失:我们探索使用密集特征作为额外的监督信号,而不是单独使用3通道颜色强度信息
令
F
L
,
t
2
F_{L,t2}
FL,t2、
F
L
,
t
1
F_{L,t1}
FL,t1 和
F
R
,
t
2
F_{R,t2}
FR,t2 分别为
I
L
,
t
2
I_{L,t2}
IL,t2、
I
L
,
t
1
I_{L,t1}
IL,t1 和
I
R
,
t
2
I_{R,t2}
IR,t2 对应的密集特征表示。与图像合成过程类似,可以分别从
F
L
,
t
1
F_{L,t1}
FL,t1 和
F
R
,
t
2
F_{R,t2}
FR,t2 合成两个参考视图
F
L
,
t
1
′
F'_{L,t1}
FL,t1′ 和
F
R
,
t
2
′
F'_{R,t2}
FR,t2′。合成过程可以表示为
F
L
,
t
1
′
=
f
(
F
L
,
t
1
,
K
,
T
t
2
→
t
1
,
D
L
,
t
2
)
(6)
F^′_{L,t1} = f (F_{L,t1}, K, T_{t2→t1}, D_{L,t2})\tag{6}
FL,t1′=f(FL,t1,K,Tt2→t1,DL,t2)(6)
F R , t 2 ′ = f ( F R , t 2 , K , T L → R , D L , t 2 ) (7) F^′_{R,t2} = f (F_{R,t2}, K, T_{L→R}, D_{L,t2})\tag{7} FR,t2′=f(FR,t2,K,TL→R,DL,t2)(7)
特征重建损失可以表示为
L
f
r
=
∑
p
∣
F
L
,
t
2
(
p
)
−
F
L
,
t
1
′
(
p
)
∣
+
∑
p
∣
F
L
,
t
2
(
p
)
−
F
R
,
t
2
′
(
p
)
∣
(8)
L_{fr}=\sum\limits_p \left| F_{L,t2}(p)-F^\prime_{L,t1}(p) \right|+\sum\limits_p \left| F_{L,t2}(p)-F^\prime_{R,t2}(p) \right|\tag{8}
Lfr=p∑
FL,t2(p)−FL,t1′(p)
+p∑
FL,t2(p)−FR,t2′(p)
(8)
3.4 训练损失
通过引入边缘感知平滑项来鼓励深度局部平滑。如果在同一区域显示图像连续性,则深度不连续性会受到惩罚。否则,对于中断深度的惩罚很小
L
d
s
=
∑
m
,
n
W
,
H
∣
∂
x
D
m
,
n
∣
e
−
∣
∂
x
I
m
,
n
∣
+
∣
∂
y
D
m
,
n
∣
e
−
∣
∂
y
I
m
,
n
∣
(9)
L_{ds}=\sum\limits_{m,n}^{W,H} \left| ∂_xD_{m,n} \right|e^{ -\left|∂_xI_{m,n} \right|}+\left| ∂_yD_{m,n} \right|e^{-\left| ∂_yI_{m,n}\right|}\tag{9}
Lds=m,n∑W,H∣∂xDm,n∣e−∣∂xIm,n∣+∣∂yDm,n∣e−∣∂yIm,n∣(9)
其中
∂
x
(
⋅
)
∂x(\cdot)
∂x(⋅) 和
∂
y
(
⋅
)
∂y(\cdot)
∂y(⋅) 分别是水平和垂直方向的梯度。请注意,上述正则化中的
D
m
,
n
D_{m,n}
Dm,n 是深度的倒数
最终的损失函数变为
L
=
λ
i
r
L
i
r
+
λ
f
r
L
f
r
+
λ
d
s
L
d
s
L=\lambda_{ir}L_{ir}+\lambda_{fr}L_{fr}+\lambda_{ds}L_{ds}
L=λirLir+λfrLfr+λdsLds
3.5 网络架构
深度估计
深度ConvNet由两部分组成,编码器和解码器。对于编码器,出于计算成本的考虑,采用带有半滤波器的 ResNet50 变体(ResNet50-1by2)中的卷积网络。对于解码器网络,解码器首先使用 1x1 内核将编码器输出(1024 通道特征图)转换为单通道特征图,然后使用具有跳跃连接的传统双线性上采样内核
在最后一个预测层之后使用 ReLU 激活来确保正预测来自深度 ConvNet。对于深度ConvNet的输出,框架来预测逆深度而不是深度。然而,ReLU 激活可能会导致零估计,从而导致无限深度。因此,我们将预测的逆深度转换为深度 D = 1 / ( D i n v + 1 0 − 4 ) D = 1/(D_{inv} + 10^{−4}) D=1/(Dinv+10−4)
视觉里程计
ConvNet 被设计为沿颜色通道采用两个串联视图作为输入,并输出 6D 向量 [ u , v ] ∈ s e 3 [\mathbf{u}, \mathbf{v}] \in se3 [u,v]∈se3,然后将其转换为 4x4 变换矩阵。该网络由 6 个 stride-2 卷积和后面的 3 个全连接层组成。最后一个全连接层给出了 6D 向量,它定义了从参考视图到实时视图的转换 T r e f → l i v e T_{ref→live} Tref→live
4. Experiments
使用 Caffe 框架训练所有的 CNN。我们使用 Adam 优化器和优化设置,其中 [ β 1 , β 2 , ϵ ] = [ 0.9 , 0.999 , 1 0 − 8 ] [β1, β2,\epsilon] = [0.9, 0.999, 10^{−8}] [β1,β2,ϵ]=[0.9,0.999,10−8]。所有经过训练的网络的初始学习率为 0.001,当训练损失收敛时我们手动降低该学习率。对于最终损失函数中的损失权重,我们凭经验发现组合 [ λ i r , λ f r , λ d s ] = [ 1 , 0.1 , 10 ] [λ_{ir}, λ_{fr}, λ_{ds}] = [1, 0.1, 10] [λir,λfr,λds]=[1,0.1,10] 会产生稳定的训练
系统主要在 KITTI 数据集中进行训练。该数据集包含 61 个视频序列,具有 42,382 个校正立体对,原始图像大小为 1242x375 像素,训练设置中使用 608x160 的图像大小
另一方面,为了评估我们的视觉里程计性能并与之前的方法进行比较,在官方 KITTI 里程计训练集上训练深度和姿势网络。
对于每个数据集分割,我们通过选择帧 I t I_t It 作为实时帧,同时选择帧 I t + 1 I_{t+1} It+1 作为参考帧(实时帧扭曲到该参考帧)来形成时间对
4.1 视觉里程计结果
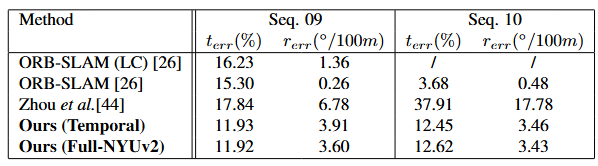
Tab. 1 视觉里程计结果在 KITTI 里程计数据集的序列 09、10 上进行评估。 t e r r t_{err} terr 是平均平移漂移误差。 r e r r r_{err} rerr 是平均旋转漂移误差
从表1中可以看出,即使没有任何进一步的后处理来修复平移尺度,我们的基于立体的里程计学习方法也大大优于单目学习方法
由于 ORB-SLAM 面临整个序列的单一深度平移尺度模糊性,通过遵循标准协议优化地图比例来将 ORB-SLAM 轨迹与地面实况对齐。只是将估计的帧到帧相机姿势整合到整个序列上,而不进行任何后处理
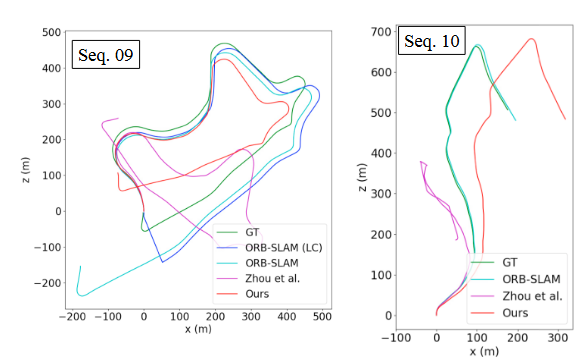
Fig. 3 视觉里程计的定性结果。绘制了测试序列 (09, 10) 的完整轨迹
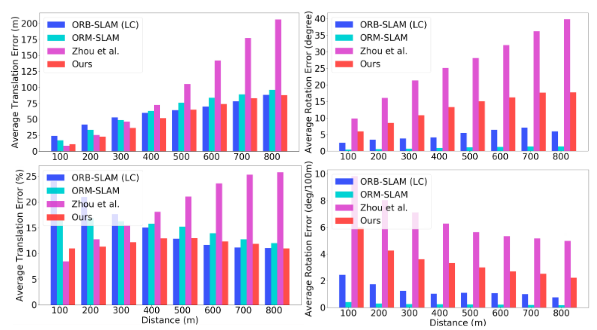
Fig. 4 里程计数据集序列 09 的 VO 误差与不同平移阈值的比较
可以清楚地看到,当平移幅度较小时,本文的方法优于ORBSLAM。随着平移幅度的增加,帧到帧 VO 的简单集成开始逐渐漂移,这表明基于地图的跟踪相对于没有捆绑调整的帧到帧 VO 具有明显的优势
4.2 深度估计结果
使用特征分割来评估我们的系统,并将结果与各种最先进的深度估计方法进行比较。
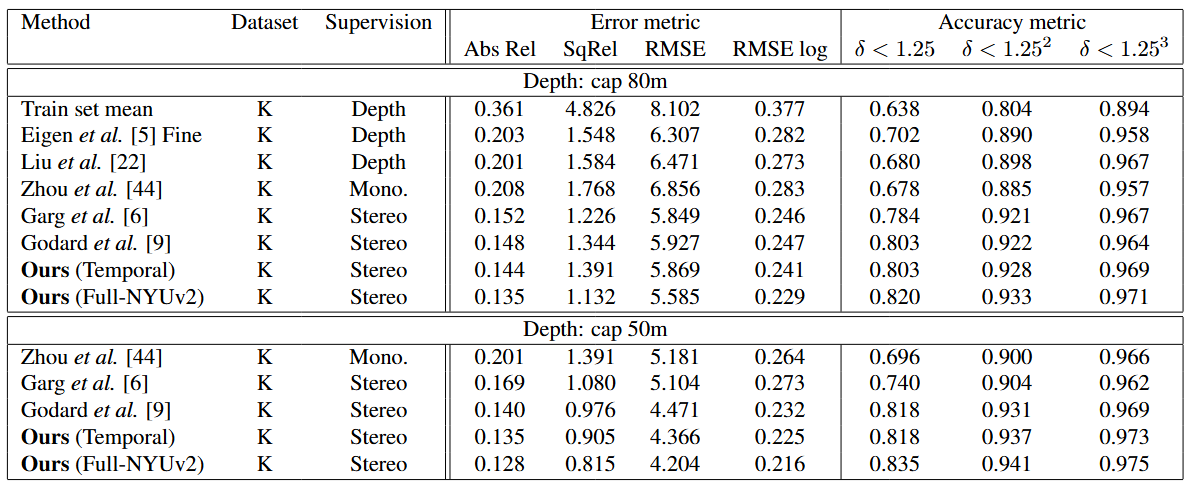
Tab. 2 单视图深度估计性能与现有方法的比较。对于训练,K 是 KITTI 数据集(Eigen Split)。为了公平比较,所有方法均在裁剪区域上进行评估。对于监督,“深度”是指方法中使用的真实深度; “单核细胞增多症。”表示训练中使用单目序列; “立体”是指训练中具有已知立体相机姿势的立体序列

Fig. 5 Eigen Split 中的单视图深度估计示例。为了可视化目的,对地面实况深度进行插值
采用 AlexNet-FCN 架构和 Horn 和 Schunck 损失的基于光度立体的训练已经比 KITTI 上最先进的监督方法给出了更准确的结果。受益于基于特征的重建损失和通过里程计网络的附加扭曲误差,本文的方法以合理的裕度更优。
4.3 消融实验
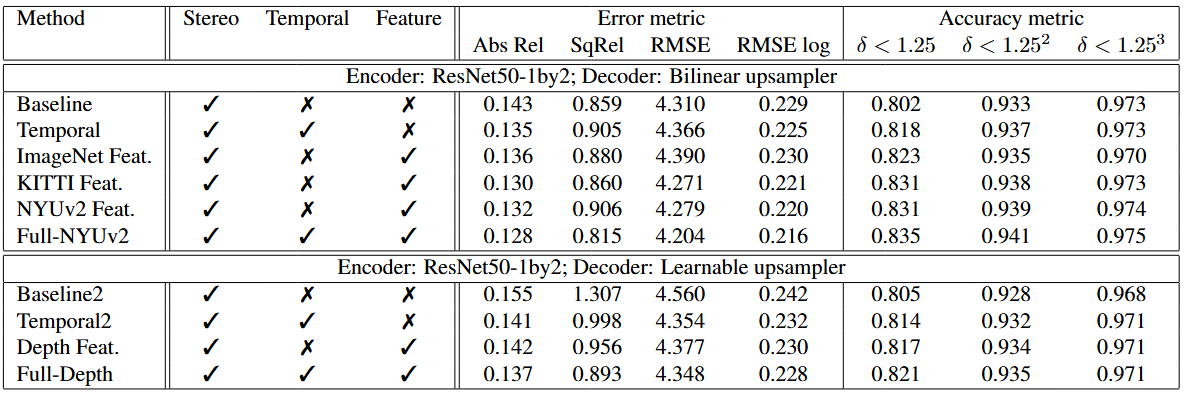
Tab. 3 单视图深度估计的消融研究。结果在 KITTI 2015 中使用 Eigen Split 测试集进行评估,遵循评估协议。结果以 50m 深度为上限。 Stereo:立体声对用于训练; Temporal:使用额外的时间对;特征:使用特征重建损失
- 与深度网络联合训练位姿网络时,深度估计精度略有提高。使用 ImageNet 特征中的特征(预训练的 ResNet50-1by-2 中的 conv1 特征)可以稍微提高深度估计的准确性
- 使用现成图像描述符的特征可以进一步提升效果
由于大多数其他无监督深度估计方法使用具有反卷积网络架构的卷积编码器来进行密集预测,我们还尝试了可学习的反卷积架构,其中 ResNet50-1by2 作为编码器,可学习的上采样器作为解码器设置。表底部的结果反映出该基线 2 的整体性能略逊于第一个基线。为了提高该基线的性能,我们探索使用从深度解码器本身提取的深度特征。最后,解码器输出一个 32 通道特征图,我们直接将其用于特征重建损失
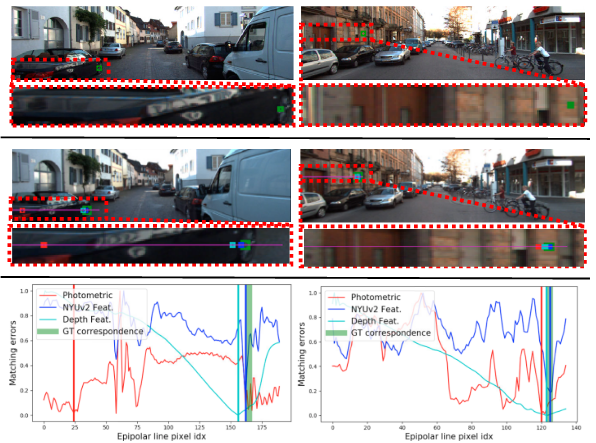
Fig. 6 立体匹配示例。行:(1) 左图; (2) 右像; (3)使用颜色强度和深度特征的匹配误差。与特征损失相比,光度损失并不稳健,尤其是在模糊区域
5. Conclusion
提出了一种使用立体数据进行训练的单视图深度估计和单目视觉里程计的无监督学习框架
- 已经证明,使用双目立体序列来联合学习这两个任务,只需给定 2 帧即可实现公制尺度的里程计预测
- 除了单视图深度的立体对对齐之外,我们还展示了使用时间图像对齐的优势预测
- 此外,我们提出了一种新颖的特征重建损失,以具有最先进的无监督单视图深度和帧到帧里程计,而没有尺度模糊性
仍有许多挑战需要解决
- 框架假设没有遮挡,并且场景假设是刚性的
- 在深度学习框架中显式地对场景动态和遮挡进行建模将为在真实场景中进行更实用和有用的导航提供一种自然的方法















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









