








论文链接
Towards End-to-End Lane Detection: an Instance Segmentation Approach
0. Abstract
- 在本文中,将车道检测问题转化为实例分割问题——其中每个车道形成自己的实例——可以进行端到端训练
- 为了在拟合车道之前对分段车道实例进行参数化,应用基于图像的学习透视变换,而不是固定的“鸟瞰图”变换
- 提出了一种快速车道检测算法,以 50 fps 运行,可以处理可变数量的车道并应对车道变化
1. Intro
传统方法很容易出现鲁棒性问题,因为道路场景变化无法通过基于模型的系统轻松建模
车道分割分支有两个输出类:背景或车道,而车道嵌入分支进一步将分割的车道像素分解为不同的车道实例
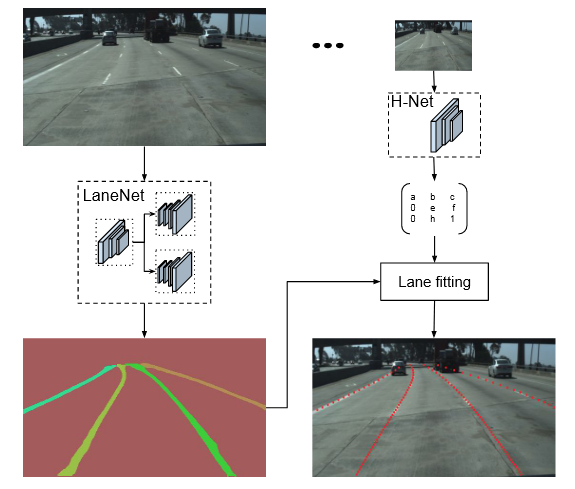
Fig. 1 系统总览。给定输入图像,LaneNet 通过用车道 ID 标记每个车道像素来输出车道实例图。接下来,使用 H-Net 输出的变换矩阵对车道像素进行变换,H-Net 学习以输入图像为条件的透视变换。对于每个车道,拟合三阶多项式并将车道重新投影到图像上
本文贡献
- 一个分支的多任务架构,将车道检测问题转化为实例分割任务,处理车道变化并允许推断任意数量的车道。特别是,车道分割分支输出密集的每像素车道段,而车道嵌入分支进一步将分割的车道像素分解为不同的车道实例
- 给定输入图像的网络估计透视变换的参数,该变换允许车道拟合对道路平面变化具有鲁棒性,例如,上/下坡
2. Method
端到端地训练神经网络进行车道检测,以解决上述车道切换问题以及车道数量限制。这是通过将车道检测视为实例分割问题来实现的。该网络我们将称为 LaneNet(参见图 2)。它将二元车道分割的优点与专为一次性实例分割设计的聚类损失函数相结合
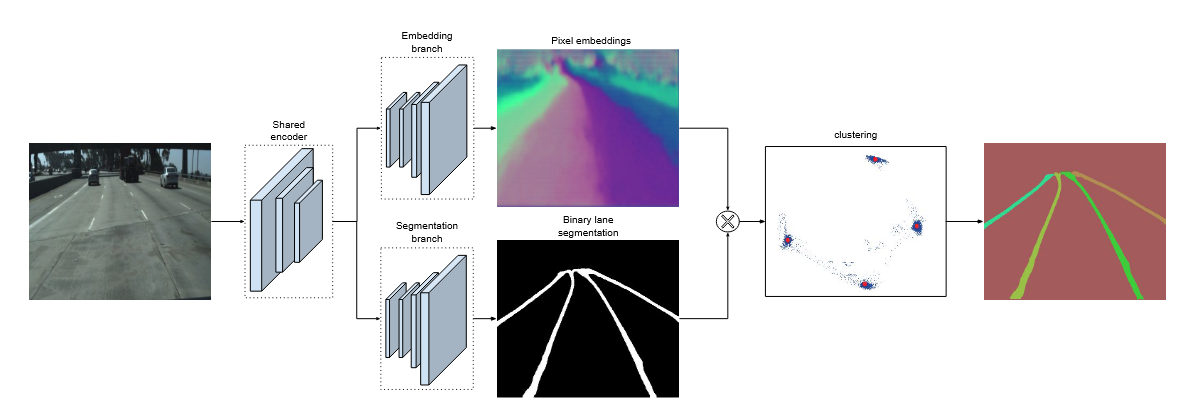
Fig. 2 LaneNet 架构。它由两个分支组成。分割分支(底部)经过训练以生成二进制通道掩码。嵌入分支(顶部)为每个通道像素生成一个 N 维嵌入,以便来自同一通道的嵌入靠近,而来自不同通道的嵌入在流形中远离。为了简单起见,我们展示了每个像素的二维嵌入,它既可视化为彩色图(所有像素),也可视化为 xy 网格中的点(仅车道像素)。使用分割分支中的二进制分割图屏蔽背景像素后,车道嵌入(蓝点)聚集在一起并分配给它们的聚类中心(红点)
由于 LaneNet 输出每个车道的像素集合,因此我们仍然需要通过这些像素拟合一条曲线来获得车道参数化。通常,首先使用固定的变换矩阵将车道像素投影为“鸟瞰图”表示形式。然而,由于所有图像的变换参数都是固定的,因此当遇到非平坦的地平面时会引发问题。在斜坡上。为了缓解这个问题,我们训练了一个称为 H-Net 的网络,该网络以输入图像为条件来估计“理想”透视变换的参数
2.1 LaneNet
LaneNet 通过将车道检测视为实例分割问题来进行车道检测的端到端训练。这样,网络就不受其可以检测到的车道数量的限制,并且能够应对车道变化
实例分割任务由两部分组成,分割部分和聚类部分。为了提高速度和准确性方面的性能,这两部分在多任务网络中联合训练
二元分割
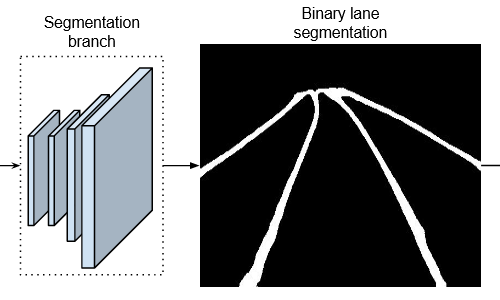
Fig. 2-1 二元分割分支
经过训练可输出二进制分割图,指示哪些像素属于车道,哪些像素不属于车道
为了构建真实的分割图,我们将所有真实的车道点连接在一起,形成每条车道的连接线。请注意,这里甚至可以通过遮挡汽车等物体,或者在没有明确的视觉车道段(如虚线或褪色车道)的情况下绘制这些真实车道。即使车道被遮挡或处于不利情况下,网络也将学会预测车道位置。分割网络使用标准交叉熵损失函数进行训练。由于两个类(车道/背景)高度不平衡,我们应用有界逆类权重
实例分割
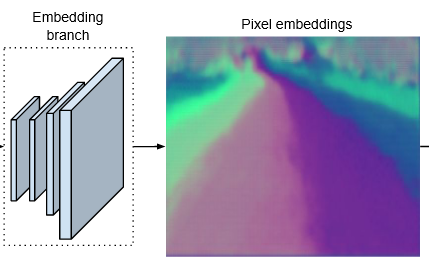
Fig. 2-2 实例嵌入分支
为了解开分割分支识别的车道像素,训练 LaneNet 的第二个分支用于车道实例嵌入。用 De Brabandere 等人提出的基于距离度量学习的一次性方法。可以轻松地与标准前馈网络集成,并且专为实时应用而设计
通过使用它们的聚类损失函数,训练实例嵌入分支来输出每个车道像素的嵌入,使得属于同一车道的像素嵌入之间的距离很小,而属于不同车道的像素嵌入之间的距离最大化。这是通过引入两项来实现的:方差项 ( L v a r ) (L_{var}) (Lvar),它对每个嵌入施加拉力,以达到车道的平均嵌入;距离项 ( L d i s t ) (L_{dist}) (Ldist),将聚类中心推离彼此。这两项是相互关联的:
-
只有当嵌入距离其聚类中心超过 δ v δ_v δv 时,拉力才会起作用,而中心之间的推力只有在它们彼此之间的距离比 δ d δ_d δd 更近时才会起作用
-
其中 C C C 表示簇(车道)的数量, N c N_c Nc 表示簇 c c c 中的元素数量, x i x_i xi 表示像素嵌入, μ c μ_c μc 表示簇 c c c 的平均嵌入, ‖ ⋅ ‖ ‖·‖ ‖⋅‖ 表示 L2 距离, [ x ] + = max ( 0 , x ) [x]_+ = \max(0, x) [x]+=max(0,x) 铰链,总损耗 L L L 等于 L v a r + L d i s t L_{var} + L_{dist} Lvar+Ldist
{ L v a r = 1 C ∑ c = 1 C 1 N c Σ i = 1 N c [ ‖ μ c − x i ‖ − δ v ] + 2 L d i s t = 1 C ( C − 1 ) ∑ c A = 1 C ∑ c B = 1 , c A ≠ c B C [ δ d − ‖ µ c A − µ c B ‖ ] + 2 (1) \begin{cases} L_{var} = \frac{1}{C} \sum^C_{c=1} \frac{1}{N_c} Σ^{N_c}_{i=1}[‖μ_c − x_i‖ − δ_v]^2_+ \\ L_{dist} = \frac{1}{C(C −1)} ∑^C_{c_A =1} ∑^C_{c_B =1,c_A\neq c_B} [δ_d − ‖µ_{c_A} − µ_{c_B}‖]^2_+ \tag{1} \end{cases} {Lvar=C1∑c=1CNc1Σi=1Nc[‖μc−xi‖−δv]+2Ldist=C(C−1)1∑cA=1C∑cB=1,cA=cBC[δd−‖µcA−µcB‖]+2(1)
一旦网络收敛,车道像素的嵌入将聚集在一起(见图 2),因此每个簇之间的距离将大于 δ d δ_d δd,并且每个簇的半径小于 δ v δ_v δv
聚类
聚类是通过迭代过程完成的。通过在上述损失中设置 δ d > 6 δ v δ_d > 6δ_v δd>6δv,可以采用随机车道嵌入和其周围半径为 2 δ v 2δ_v 2δv 的阈值来选择属于同一车道的所有嵌入。重复此操作,直到所有车道嵌入都分配给相应的车道
网络架构
LaneNet 的架构基于编码器-解码器网络 ENet,因此被修改为两分支网络。虽然原始 ENet 的编码器由三个阶段组成(阶段 1、2、3),但 LaneNet 仅在两个分支之间共享前两个阶段(1 和 2),留下 ENet 编码器的阶段 3 和完整的 ENet 解码器作为每个单独分支的骨干。分割分支的最后一层输出单通道图像(二值分割),而嵌入分支的最后一层输出 N 通道图像,其中 N 为嵌入维度
2.2 使用 H-NET 进行曲线拟合
LaneNet 的输出是每个通道的像素集合。通过原始图像空间中的这些像素拟合多项式并不理想,因为必须求助于更高阶多项式才能应对弯曲车道。解决此问题的常用解决方案是将图像投影为“鸟瞰图”表示,其中车道彼此平行,因此,弯曲车道可以用二阶到三阶多项式拟合。然而,在这些情况下,变换矩阵 H 只计算一次,并且对于所有图像保持固定。通常,这会导致地平面变化时产生误差,其中投影到无穷远的消失点向上或向下移动
为了解决这个问题,我们训练一个具有自定义损失函数的神经网络 H-Net:该网络经过端到端优化以预测透视变换 H 的参数,其中变换后的车道点可以与第二个或三阶多项式。预测以输入图像为条件,允许网络在地平面变化下调整投影参数,以便车道拟合仍然正确
H
=
[
a
b
c
0
d
e
0
f
1
]
H= \begin{bmatrix} a &b &c \\ 0 &d &e \\ 0 &f &1 \end{bmatrix}
H=
a00bdfce1
放置零点是为了强制约束水平线在变换下保持水平
曲线拟合
在通过车道像素 P \mathbf{P} P 拟合曲线之前,使用 H-Net 输出的变换矩阵对后者进行变换。给定车道像素 p i = [ x i , y i , 1 ] T ∈ P p_i = [x_i, y_i, 1]^T ∈ \mathbf{P} pi=[xi,yi,1]T∈P,变换后的像素 p i ′ = [ x i ′ , y i ′ , 1 ] T ∈ P ′ p^′_i = [x^′_i, y^′_i, 1]^T ∈ \mathbf{P}^′ pi′=[xi′,yi′,1]T∈P′ 等于 H p i H_{p_i} Hpi。接下来,使用最小二乘算法通过变换后的像素 P ′ \mathbf{P}^\prime P′ 拟合 n 次多项式 f ( y ′ ) f (y^\prime) f(y′)
为了获得给定 y y y 位置 y i y_i yi 处车道的 x x x 位置 x i ∗ x^*_i xi∗,点 p i = [ − , y i , 1 ] T p_i = [−, y_i, 1]^T pi=[−,yi,1]T 转换为 p i ′ = H p i = [ − , y i ′ , 1 ] T p^′_i = H_{p_i} = [−, y^′_i, 1 ]^T pi′=Hpi=[−,yi′,1]T 并计算为: x i ′ ∗ = f ( y i ′ ) x^{′*}_i = f (y^′_ i) xi′∗=f(yi′)
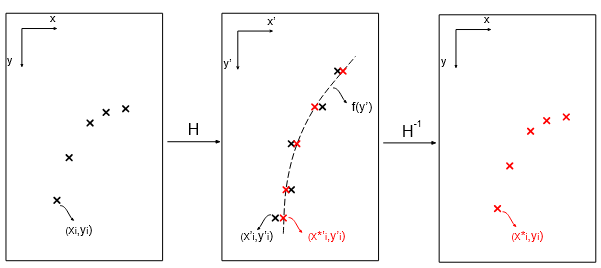
Fig. 3 曲线拟合。左:使用 H-Net 生成的矩阵 H 变换车道点。中:通过变换点拟合一条线,并在不同高度(红点)评估曲线。右:评估的点被变换回原始图像空间

Fig. 4 用于车道拟合的固定单应性和条件单应性(使用 H-Net)之间的比较。由于地平面的变化,绿点无法使用固定单应性正确拟合,这可以通过使用 H-Net 的条件单应性来解决(最后一行)
损失函数
为了训练 H-Net 输出最适合通过车道像素拟合多项式的变换矩阵,我们构建了以下损失函数。给定 N 个真实车道点
p
i
=
[
x
i
,
y
i
,
1
]
T
∈
P
p_i = [x_i, y_i, 1]^T ∈ \mathbf{P}
pi=[xi,yi,1]T∈P,我们首先使用 H-Net 的输出来变换这些点
P
′
=
H
P
\mathbf{P}^\prime=\mathrm{H}\mathbf{P}
P′=HP
使用最小二乘封闭式解拟合多项式
f
(
y
′
)
=
α
y
′
2
+
β
y
′
+
γ
f (y^′) = αy^{′2} + βy^′ + γ
f(y′)=αy′2+βy′+γ
w
=
(
Y
T
Y
)
−
1
Y
T
x
′
\mathbf{w} = (\mathbf{Y}^T \mathbf{Y})^{−1}\mathbf{Y}^T\mathbf{x}^′
w=(YTY)−1YTx′
其中
w
=
[
α
,
β
,
γ
]
T
\mathbf{w} = [α, β, γ]^T
w=[α,β,γ]T ,
x
′
=
[
x
1
′
,
x
2
′
,
.
.
.
,
x
N
′
]
T
\mathbf{x}^′ = [x^′_1, x^′_2, ..., x^′_N ]^T
x′=[x1′,x2′,...,xN′]T 且
Y
=
[
y
1
′
2
y
1
′
1
⋮
⋮
⋮
y
N
′
2
y
N
′
1
]
\mathbf{Y}= \begin{bmatrix} y^{\prime 2}_1 &y^\prime_1 &1\\ \vdots &\vdots &\vdots \\ y^{\prime 2}_N &y^\prime_N &1 \end{bmatrix}
Y=
y1′2⋮yN′2y1′⋮yN′1⋮1
在每个
y
i
′
y^\prime_i
yi′ 位置评估拟合多项式,给出
x
i
′
∗
x^{′*}_i
xi′∗ 预测
这些预测被投影回来:
p
i
∗
=
H
−
1
p
i
′
∗
p^*_i = \mathrm{H}^{−1}p^{′*}_i
pi∗=H−1pi′∗ 其中
p
i
∗
=
[
x
i
∗
,
y
i
,
1
]
T
p^*_i = [x^*_i , y_i, 1]^T
pi∗=[xi∗,yi,1]T 和
p
i
′
∗
=
[
x
i
′
∗
,
y
i
′
,
1
]
T
p^{\prime *}_i = [x^{\prime *}_i , y^\prime_i, 1]^T
pi′∗=[xi′∗,yi′,1]T 。损失是
L
o
s
s
=
1
N
∑
i
=
1
,
N
(
x
i
∗
−
x
i
)
2
Loss = \frac{1}{N} \sum\limits_{i=1,N} (x^∗_i − x_i)^2
Loss=N1i=1,N∑(xi∗−xi)2
由于车道拟合是通过使用最小二乘算法的封闭式解来完成的,因此损失是可微的。我们使用自动微分来计算梯度
网络架构
H-Net 的网络架构有意保持较小,并由连续的 3x3 卷积块、batchnorm 和 ReLU 构成。使用最大池化层减少维度,最后添加 2 个全连接层
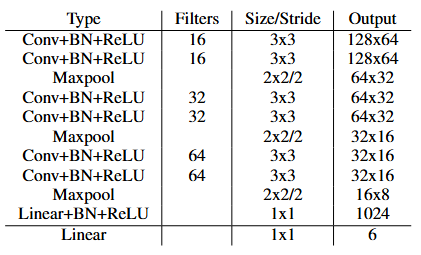
Tab. 1 H-Net 网络架构
3. Results
3.1 数据集
tuSimple 车道数据集是用于在车道检测任务上测试深度学习方法的大规模数据集。它由 3626 张训练图像和 2782 张测试图像组成。它们是在不同白天的 2 车道/3 车道/4 车道或更多车道的高速公路上记录的
准确度计算为每幅图像的平均正确点数:
a
c
c
=
∑
i
m
C
i
m
S
i
m
acc=\sum\limits_{im}\frac{C_{im}}{S_{im}}
acc=im∑SimCim
其中
C
i
m
C_{im}
Cim 为正确点的数量,
S
i
m
S_{im}
Sim 为真实点的数量。当真实点与预测点之间的差异小于某个阈值时,该点是正确的
除了准确性之外,它们还提供假阳性和假阴性分数
F
P
=
F
p
r
e
d
N
p
r
e
d
F
N
=
M
p
r
e
d
N
g
t
FP=\frac{F_{pred}}{N_{pred}} \\ FN=\frac{M_{pred}}{N_{gt}}
FP=NpredFpredFN=NgtMpred
其中
F
p
r
e
d
F_{pred}
Fpred 为错误预测车道的数量,
N
p
r
e
d
N_{pred}
Npred 为预测车道的数量,
M
p
r
e
d
M_{pred}
Mpred 为错过的地面实况车道的数量,
N
g
t
N_{gt}
Ngt 为所有地面实况车道的数量
3.2 设置
LaneNet
使用嵌入维度为 4、 δ v = 0.5 δ_v = 0.5 δv=0.5 和 δ d = 3 δ_d = 3 δd=3 进行训练。将图像重新缩放为 512x256,并使用 Adam 训练网络,批量大小为 8,学习率为 5e-4,直至收敛
H-Net
使用尺寸为 128x64 的输入图像的缩放版本进行三阶多项式拟合训练。使用 Adam 训练网络,批量大小为 10,学习率为 5e-5,直到收敛
Speed
给定 512x256 的输入分辨率、每像素 4 维嵌入并使用三阶多项式拟合,我们的车道检测算法可以每秒运行高达 50 帧
3.3 实验
插值法
在表III中,我们计算了基于HNet的无变换、固定变换和条件变换的车道拟合精度。我们还测量二阶或三阶多项式拟合之间的差异
当直接在原始图像空间中拟合曲线而不进行变换时,这会导致较差的结果;这是预料之中的,因为使用低阶多项式很难拟合弯曲的车道。使用 H-Net 生成的变换矩阵(针对车道拟合进行了优化),结果优于具有固定变换的车道拟合。我们不仅获得了更好的 MSE 分数,而且使用这种方法可以让我们拟合所有点,无论地平面的斜率是否发生变化
tuSimple结果
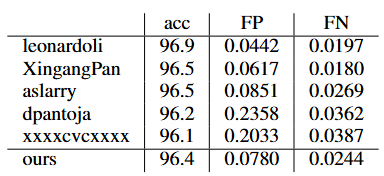
Tab. 2 tuSimple 测试集上的车道检测性能

Tab. 3 使用不同变换下的二阶和三阶多项式验证集上拟合车道点和 GT 点之间的 MSE(以像素为单位)。无法拟合的点不会添加到 MSE,但会被视为未命中并影响平均未命中/车道
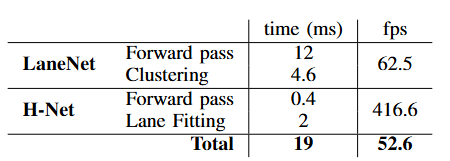
Tab. 4 在 NVIDIA 1080 TI 上测量的 512X256 图像大小的不同组件的速度。总的来说,车道检测可以以 52 FPS 的速度运行
4. Conclusion
- 提出了一种 50 fps 的端到端车道检测方法。受最近的实例分割技术的启发,与其他相关的深度学习方法相比,我们的方法可以检测可变数量的车道,并且可以应对车道变换操作。
- 为了使用低阶多项式对分段车道进行参数化,我们训练了一个网络来生成透视变换的参数,以图像为条件,其中车道拟合是最佳的
- 网络使用用于车道拟合的自定义损失函数进行训练。与流行的“鸟瞰图”方法不同,我们的方法通过相应地调整变换参数,对地平面的坡度变化具有鲁棒性。















 6211
6211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









