







这里是从头开始搭建一个人脸检测和识别功能的工程。
官方教程我只看懂了所下载的路径下insightface-master/examples里的demo_analysis.py文件(可以参考https://blog.csdn.net/qq_40035462/article/details/131968872),运行了一下但是感觉不太全,所以我来写一个完整好懂的:
0、首先下载insightface库和onnxruntime库:
pip install insightface
pip install onnxruntime #如果有gpu就把onnxruntime替换为onnxruntime-gpu
其中第一个库是用来人脸识别的功能库,第二个是用来推理的(因为insghtface里的是onnx格式的模型)。
我这里因为自带的环境比较全,所以只安了这2个。
1、onnx格式的人脸检测模型下载:
如果你网比较好,代码会自动帮你下(因为在https://github.com/deepinsight/insightface/tree/master/python-package里面有说明),这一步你就不用管了可以直接跳过。
但是我的办公网比较垃圾,只能手动先下好模型包buffalo_l.zip(在https://drive.google.com/file/d/1qXsQJ8ZT42_xSmWIYy85IcidpiZudOCB/view?usp=sharing),然后解压到对应位置。具体操作就2步:
(1)先创建文件夹:
mkdir /home/jovyan/.insightface/models/buffalo_l
(2)然后解压你下载的模型包(最重要的是这个.insightface/models/buffalo_l路径,你看终端报错提示里downloading到的就是这个位置):
unzip /home/jovyan/conda_env/buffalo_l.zip -d /home/jovyan/.insightface/models/buffalo_l
你可以使用ls命令,查看里面是不是有5个.onnx后缀的模型文件如下图,分别是用来2D关键点检测、3D关键点检测、det_10g (人脸检测)、genderage (性别年龄预测)、w600k_r50 (人脸识别),一共5个功能。

2、直接运行下列代码就可以:
在终端输入:
python 绝对路径/你的测试文件名.py
比如我的是:
python /home/jovyan/insightface/myTest.py
其中我的myTest.py代码内容是:
import cv2
import numpy as np
import insightface
from insightface.app import FaceAnalysis ##这个文件在conda_env/insightface-master/python-package/insightface/app/
from insightface.data import get_image as ins_get_image #这个文件在conda_env/insightface-master/python-package/insightface/data/image.py
app = FaceAnalysis(allowed_modules=['detection'],providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640)) #缩放到640x640像素再输入到模型进行处理
img = ins_get_image('t1') #不用带后缀,图片放到./insightface/python-package/insightface/data/images
faces = app.get(img) #进行检测
print("faces::::", faces) #这里我把每张脸的bbox、kps、score三个信息打印出来了
rimg = app.draw_on(img, faces) #绘制检测框
# cv2.imwrite("./ldh_output.jpg", rimg)
cv2.imwrite("/home/jovyan/conda_env/insightface-master/python-package/insightface/data/images/xx_output.jpg", rimg)
注意,这里的图片路径是在类似于/opt/conda/envs/yolo/lib/python3.9/site-packages/insightface/app中,里面自带了t1.jpg等。
如果你想测试自己的图片,有两种方式:
方式一:
把自定义图片给直接复制到那里面去,比如使用cp命令:
cp /home/jovyan/conda_env/insightface/zhe1.jpeg /opt/conda/envs/yolo/lib/python3.9/site-packages/insightface/data/images/
然后把图片文件名换成你自己的(不带后缀)就可以啦。这样比较直接快速。
方式二:
你也可以跑去那个image.py文件(在类似于/opt/conda/envs/yolo/lib/python3.9/site-packages/insightface/data路径下,你可以用ls命令来确认它是不是在里面)里面去修改它读取图片路径的逻辑代码。这里我就不详细阐述了,懒得改。
Anyway,这一步的输出结果应该是:
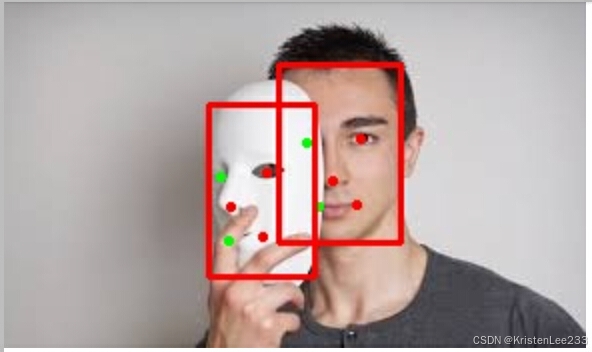
如果能import啥的不报错,就说明安装成功了。如果检测到类似图中的bbox和5个关键点,就说明检测成功了。其他错误看不懂直接问gpt解决
从结果图里可以看出2个问题(个人理解,不知道对不对):
1、这里就算嘴被遮挡,模型也会强行拟合出对应位置的关键点,难怪会需要研发遮挡检测算法。。。
此外我还测了其他的非深度学习方法如dlib,那个更辣鸡,更不容易检测出人脸(安装教程很简单,直接一句conda install就可以。用conda最简单方便),并且一样是强行拟合出68或者81个关键点,不管是否遮挡,很无语
2、面具也会被看作人脸而检测到,所以这部分属于anti spoof又称作live detection的内容,即活体检测。避免把逼真面具或者图片来误识别成真人。
3、多个人脸的注册+识别
前面的myTest.py文件 只是单纯地检测一张图里的人脸信息(模型会输出检测到的人脸的特征向量embedding),找出它的框+关键点。但是它只开启了一个功能模型(即初始化的时候我们设置了allowed_modules=['detection']),并且没利用上检测到的人脸embedding特征向量。
思考一下:
a. 其实我们可以把每张脸的特征向量进行比对,计算相似度,这样就可以知道是不是同一张脸(即下面代码里的feature_compare函数)。
b. 此外,我们还可以把各种人脸做成一个列表,保存在一个数据库里。一旦外面来了一张新图,就可以拿它和建立的数据库进行比对。
我们把这些实现到一个类里去,那么新代码的工作流程分为如下两步:
(1)用户注册:
即把每个人的证件照放在数据库里。
具体代码实现:对输入照片进行特征提取,并另存照片在数据库中。
比如我选择了先注册热巴和娜扎两位美女姐姐的照片信息:
python your_script.py --picture path_to_your_image --register True
例如:
python /home/jovyan/insightface-master/examples/my_test3.py --picture /home/jovyan/conda_env/insightface-master/python-package/insightface/data/images/dlrb/dlrb0.jpeg --register True
python /home/jovyan/insightface-master/examples/my_test3.py --picture /home/jovyan/conda_env/insightface-master/python-package/insightface/data/images/glnz/glnz.jpeg --register True


返回结果:
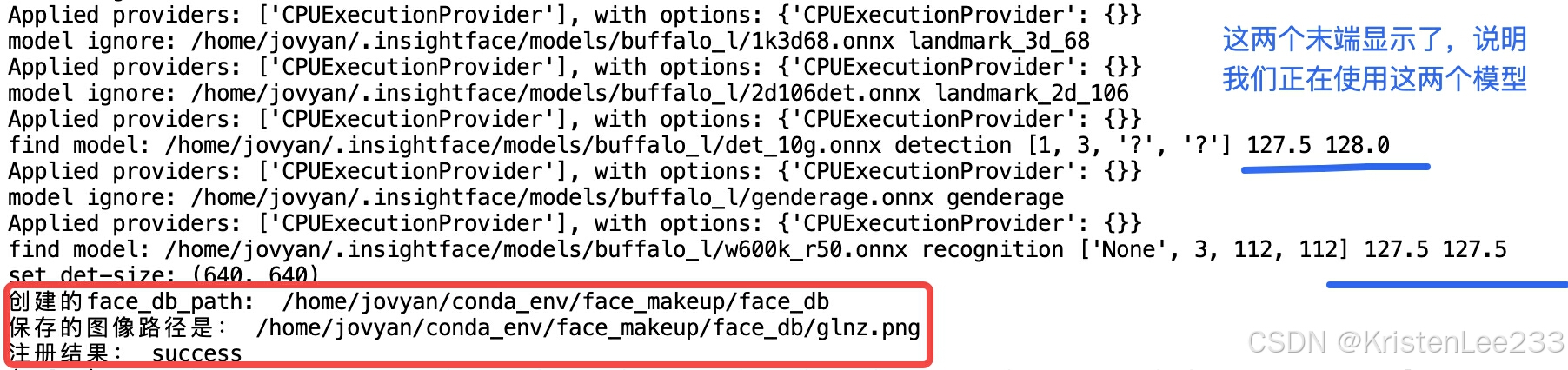
娜扎的身份注册成功。
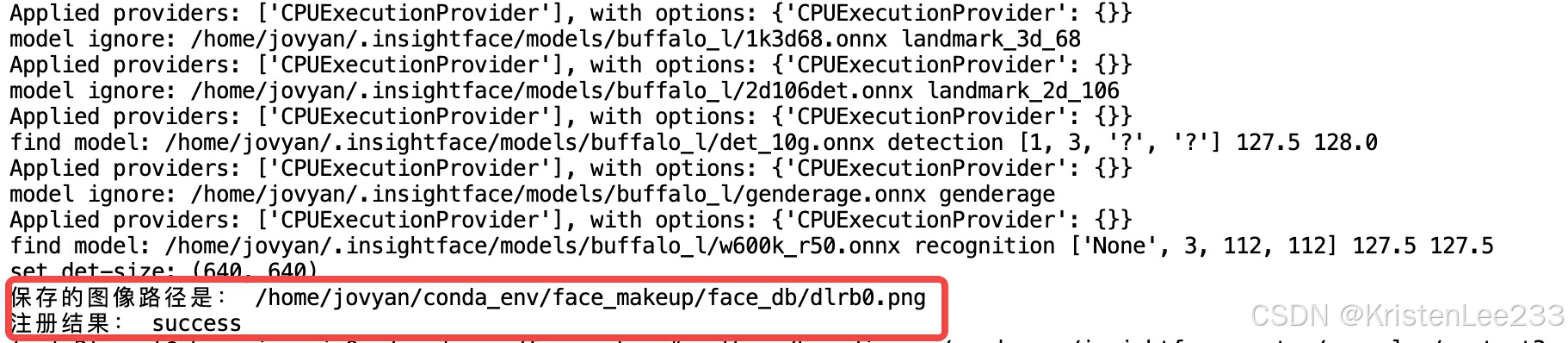
热巴的也注册成功了。
如果你再次执行同一张图的注册语句,则会提醒你 “注册结果: 该用户已存在”。即不需要再重复注册啦~
(2)人脸识别:
这里我拿另一张热巴的照片测试:
python /home/jovyan/conda_env/insightface-master/examples/my_test3.py --picture /home/jovyan/conda_env/insightface-master/python-package/insightface/data/images/dlrb/dlrb3.jpeg --recognition True

识别结果如下,成功检测出是热巴:
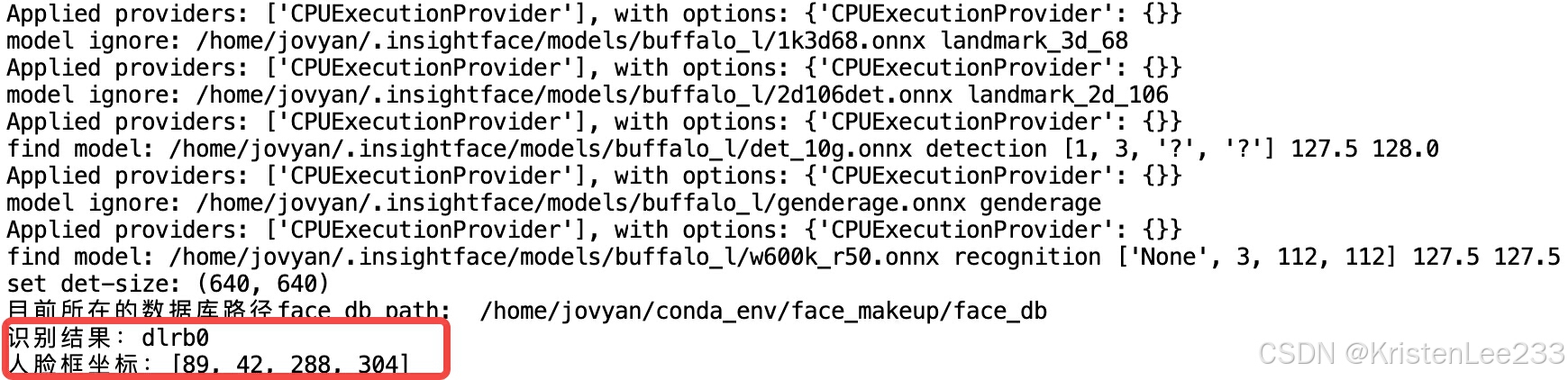
同理,拿另一张娜扎的图也能正确识别出是娜扎的身份。
如果这时拿一位没注册过的新用户来识别,比如下图的颖宝:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









