







1. Tittle

2017
2. 标签
- model-free
3. 总结
针对的问题:
-
reward function的设计是很复杂的,不仅需要反映任务的本质 而且还有精心设计才能够使策略最优化。
-
稀疏奖励或者二进制奖励很难训练。
-
提高reward是稀疏的或者是1/0的这种形式时的sample-efficiency,从而避免复杂的reward设计。
解决方法:
- 提出了一个新的技术叫做Hindsight Experience Replay。 能够针对所有的off-policy RL算法进行使用。
- 算法的核心思想:输入是
当前状态+目标状态。在每个episode进行replay时,使用不同的agent想要达到的目标,而不是仅仅只使用一个目标。
paper中提到的一个例子:当打冰球的时候,如果偏向右侧了,那么想要得到的结论是:如果这个网再往右移一点(不同的目标),这一些列动作(episode)就能够成功了。
3. 原理
Background
- DQN
- DDPG
- UVFA:Universal Value Function Approximators
- 是DQN对于多目标的拓展。希望能够达到不止一个目标。Q-function扩展成为状态status、行为action、目标goal 对。在每个时间步,agent得到动作与状态status和目标goal相关。不同的目标有不同的奖励函数。
HER原理
例子: n维度的0/1转换。
-
状态空间KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲S \it = \{0,1\}…
-
动作空间KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲A = \it \{0,1..… ,代表反转哪一个维度的状态。每个动作只转换一个维度。
每一个episode,统一采样初始化状态和目标状态。只要状态和目标状态不相同,就会得到-1的reward
对于这个问题,标准的RL算法当n>40时,就会失败。
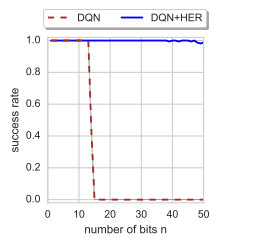
问题不在于缺少状态的多样性,而是去探索这么大的状态空间(如n=40,状态空间是 2 40 2^{40} 240)是不现实的。标准的解决办法是使用含有更多信息的shaped reward function去引导agent走向走向目标。例如 r g ( s , a ) = − ∣ ∣ s − g ∣ ∣ 2 r_g(s,a) = - ||s-g||^2 rg(s,a)=−∣∣s−g∣∣2
r g r_g rg是针对目标g的奖励。
核心思想就是在replay时使用不同的目标,例如除了使用最终的target,还可以使用最后的状态 s T s_T sT作为目标。这样做就可以得到更多的信息了。
下面表格为DDPG和DDPG-HER的对比:
| DDPG | DDPG-HER | |
|---|---|---|
| Actor Net:Input | State | state||goal |
| Actor Net : Output | actions | actions |
| Critic Net:Input | state||actions | state||goal||actions |
| Critic Net:Output | Q | Q |
显然,HER把goal也作为一个产生动作和评价价值的一个指标。
多目标RL
- multi-goal RL比单一任务更容易训练
- goal可以是state的全部后者部分属性
构造replay buffer
HER的关键在于构造replay的数据。以论文中的机械臂FetchReach-V1为例:
环境ENV返回的observations中包含了:(在gym中,observation就是我们公式讨论时的state)
-
observation:当前的状态
-
achieved_goal: 当前已经达到的目标(是个三维度的坐标)
-
desired_goal: 最终目标(一旦设定后,在单次模拟中不会改变)
我们需要记录一系列的轨迹,如设定env走50步为一个完整的序列,称之为rollout,将这50步存储起来。之所以要取连续的,是因为我们需要知道achieved_goal与observation的先后关系。因为我们一会要用achieved_goal替换掉部分的desired_goal
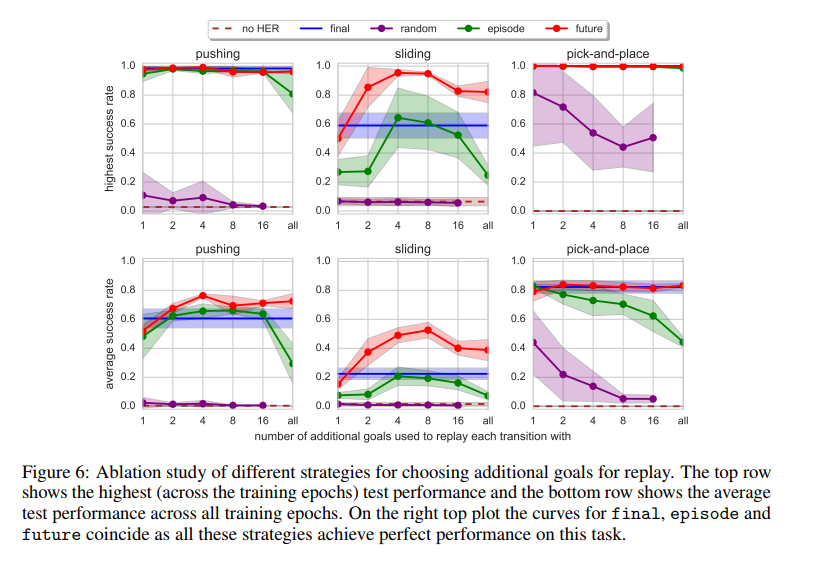
然后我们就可以开始构造HER版本的replay数据了,在每次sample replay的数据时,我们都有以下几种方式进行构造:
- final:只使用episode的最后一个状态
- future:从该episode中,选取k个state,然后用k个state之后达到的achieved_goal去替换他们当前的desired_goal(效果最好)
- episode:从该episode中随机选择k个状态
- random:从所有的训练数据中随机选择k个转台
future 例图(图中没有画reward):

HRE算法描述
在replay时,不仅仅使用原始的目标,还使用其他的目标。这些目标是受actions的影响。注意算法描述中G的来源。

4. 实验
没有标准的multi-goal RL算法,所以作者创建了自己的环境,是机械臂抓取的一个模拟。最后应用到了实际的机器手臂上。
- 实验证明有HER的加入,提升了multi-goal训练速度,对于某些任务能够提升准确性。
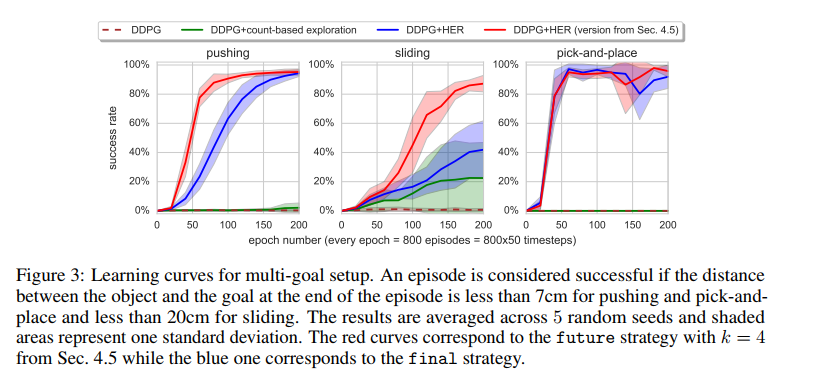
- 对于单一目标的应用
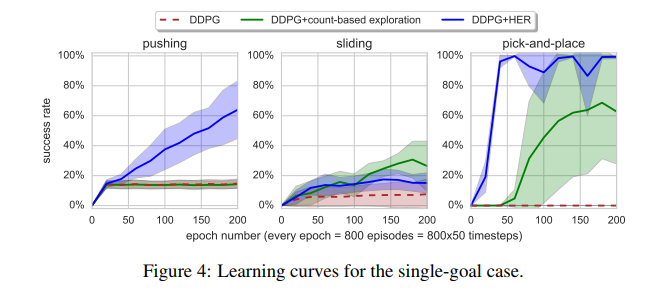
-
不同版本的HER,future效果最好
















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









