







前言
本文是针对这两篇博文代码的理解
基于BERT里的[CLS] Token在Pytorch里是如何实现的,引出对Torch的视图View和扩展视图expand的理解-CSDN博客
CV攻城狮入门VIT(vision transformer)之旅——VIT原理详解篇-CSDN博客
里面有下列代码
self.cls_token = nn.Parameter(torch.randn(1, 1,embedding_size))
expand_cls_token = self.cls_token.expand(x.size(0), -1,-1)
# 将cls_token的第一维度batch_size的大小“扩充”为和x一样的batch_size(x_batch_size,1,embedding_size),-1 means not changing the size of that dimension
x = torch.cat((expand_cls_token, x), dim=1)
# cls_token与x拼接,cls_token放置在Sequence序列的首位,所以dim=1
原文对于view和expand已经描述的比较详细了,这里我重点讲一下我的理解
CLS的理解
因为我们的目标是进行分类,按照CNN的思想,每张图片都要有一个判别概率,在传统CNN中,我们是利用softmax取最大值,但是在这里,我们使用class token来进行"代表",即这一个多出来的部分就是这张图片的预测结果
从实际应用角度出发,cls加了一共全局的信息,可以在反向传播中接收来自模型反馈的梯度值(因为我们最开始初始化为全0,相当于给我们ViT展平后的向量增加一点空间用于接收反向传播的信息),所以也就有代码中的:
- nn.Parameters,将这向量初始化为模型可训练的参数
- torch.cat,表示直接将向量进行连接而不是进行加和,因为这部分的向量值初始化后无意义,作用就是让模型通过反向传播给它赋值,成为有意义的值
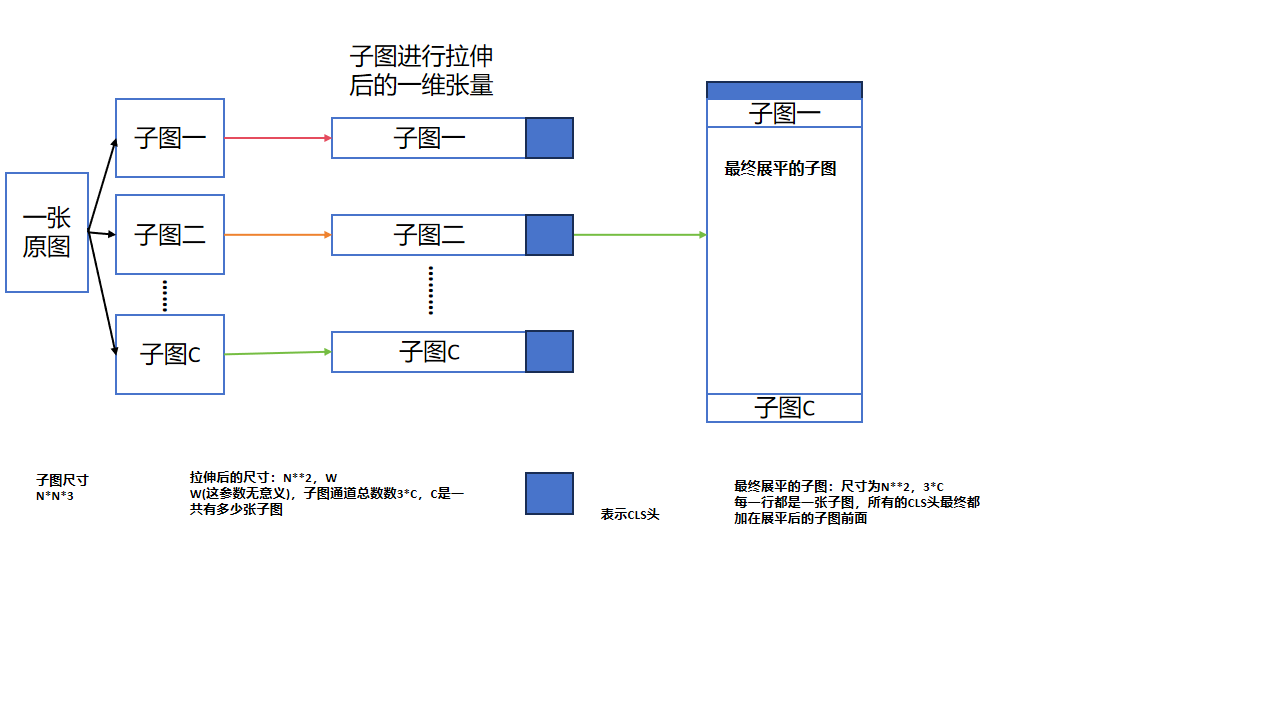
下面这张图可以比较明了表示我的理解,为了方便理解,我假设了一个中间过程,每个子图加上个cls头,但是实际应该没有这个过程,从博文的代码中可以知道,实际是在展平后的子图上直接加上蓝色长方形的部分

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









