







题目:UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
1 引言
幻觉问题是当前大语言模型领域实际应用落地需要克服的主要障碍之一。幻觉问题是指生成的内容与用户输入、模型自己的输出上下文或事实信息不一致等。尤其是在医学、法律、金融和新闻等专业领域,其对内容的及时性、准确性和逻辑一致性标准要求更为严格,幻觉问题表现得更为突出。
UHGEval数据集中部分真实的幻觉示例如图1所示。

图1 UHGEval的幻觉示例
为了有效控制幻觉,设计新的训练方法和模型架构固然重要,但是在那之前制定一个全面、统一的基准来评估语言生成中的幻觉也是至关重要的。缺少这样的基准,该领域的工作则难以横向对比,良性发展。目前已经有一些比较知名的评测幻觉的基准,比如,TruthfulQA,HADES,HalluQA,ChineseFactEval等。然而这些基准大多存在这样一些问题:
-
大多采用约束式生成范式,定向生成可预测类型的幻觉。这种生成方法与现实世界中的场景不一致,在现实世界中,幻觉可能会在不受限制的、自发生成的内容中出现。
-
现有基准往往在标注数据时,只标注到句子级别的幻觉,其粒度少有在关键词级别的。然而从不同粒度上考验大模型的分辨能力不仅更有挑战,也能为解决幻觉问题提供启发。
-
大多数基准都集中在对英语幻觉的评估上,而忽略了对汉语幻觉现象的评估。据论文所述,唯二的两项中文领域的工作,复旦大学的HalluQA和上海交通大学的ChineseFactEval分别只有450条,和125条数据项,数据量较小。
为了解决上述挑战,中国人民大学,上海算法创新研究院,与新华社媒体融合生产技术与系统国家重点实验室联合引入了一种新的幻觉评估基准UHGEval,一个全面的中文专业生成领域的幻觉评测基准。该基准包括一个具有5000多个数据项基于新闻内容生成的幻觉数据集;一个数据安全,扩展便捷,实验方便的评测框架,以及一份在11个当下流行的大语言模型上的实验报告。
2 UHGEVAL基准数据集
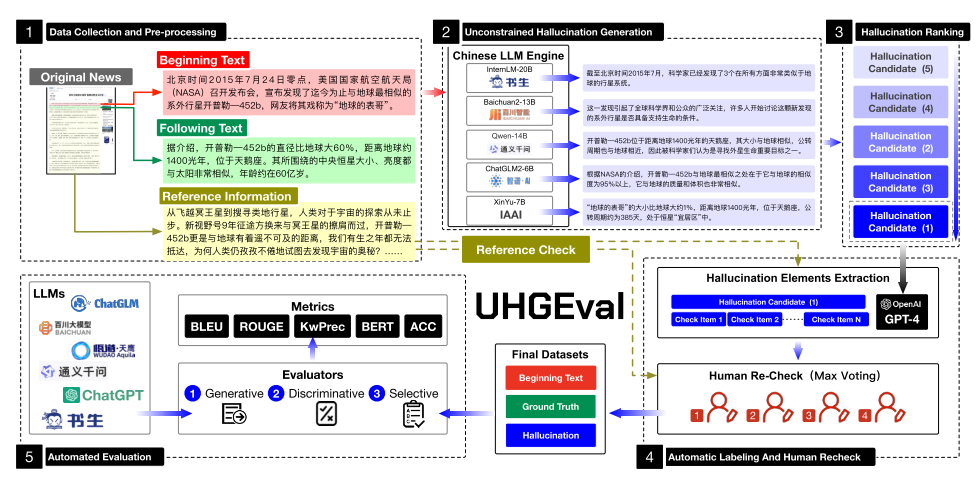
图2 UHGEval制作流程
2.1 数据收集和预处理
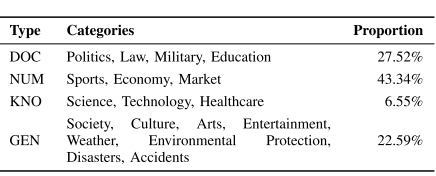
该阶段使用涵盖2015年1月至2017年1月数万条来自中文权威新闻网站的原始新闻作为数据集来源,并将其划分为开头部分,续文部分以及参考信息。开头部分被用作待续写的文本,续文部分是续写的正样例,参考信息被用来视作后续标注和评估的参考。该阶段同时还包括新闻类别的细分方案和数据筛选过程。数据集中的新闻示例分为四大类型:文档密集型、数字密集型、知识密集型和一般新闻,如表1所示。
2.2 无约束幻觉生成
生成内容与其他同类工作不同,UHGEval一方面使用5个LLM同时生成多个候选幻觉续写,以提高幻觉的多样性,避免单模型造成的评测偏见;另一方面,在具体生成文本时,不约束生成内容一定包含幻觉,也不指定生成幻觉类型,而是让模型自由生成,在后续标注阶段再确定是否真正有幻觉。具体来说,生成内容时,模型提示词减少指令以至于不适用指令,而直接将待续写的开头部分输给大模型,以得到最后的候选续写。如此一来,这两方面共同构成了模型和提示无约束的候选幻觉生成。
2.3 幻觉排名
对于生成的5个候选幻觉文本,UHGEval从文本流畅性和幻觉发生可能性两个维度进行排名。之所以要进行排名是因为目标候选幻觉文本应当满足”看起来很像真的(流畅性高)而实则存在幻觉(幻觉发生可能性高)“的特征。UHGEval使用自研的奖励模型(reward model)来评价续写的流畅性,使用提出的kwPrec指标来评价续写发生幻觉的可能性。通过排名,最终会筛选出一个较为流畅,同时较为可能发生幻觉的目标候选续写文本。
kwPrec指标。这种方法最初使用LLM从延续中提取关键字,并确定这些关键字在引用信息中是否匹配。然后计算所有匹配项与总关键字的比率。由于LLM通常更有效地提取适当的关键词,因此kwPrec更关注事实相关性,而不是表达相关性。
2.4 自动标注和人工复检
有了高达上万条的候选续写文本,为了筛选出真正存在幻觉的文本,UHGEval提出了基于关键词的标注方案。在该阶段由GPT4进行关键词粒度的标注(关键词是否存在幻觉,若存在原因是什么),由人工判断GPT4标注的是否准确,最终只保留人工认为GPT4标注准确且存在幻觉关键词的续写文本,以构成最终数据集。这样的标注方案实现了成本和标注准确性上的平衡。
3 实验
3.1 实验模型
使用了3个来自GPT系列的模型,GPT3.5-Turbo,GPT4-0613和GPT4-1106;以及8个中文大语言模型,ChatGLM2-6B,Xinyu-7B,Xinyu2-70B,InternLM-20B,Baichuan2-13B,Baichuan2-53B,Qwen14B,Aquila2-34B。
3.2 实验方法
文章对评测首先进行了三个层级的解构,认为评测包括形式,指标和粒度。形式是指模型如何与数据集交互,包括人类评测、判别式评测(Discriminative Evaluation)、选择式评测(Selective Evaluation)和生成式评测(Generative Evaluation);指标是具体计算量化表现的方法,如准确率,ROUGE,kwPrec,BERTScore等;粒度指幻觉标注的粒度,如句子粒度,关键词粒度等。
判别式评测(Discriminative Evaluation)。判别式评测使LLM能够以“是”或“否”的二进制答案进行响应。具体来说,这种评测模式包括在仔细审查的LLM中呈现一个初始文本,然后是一个可能包括幻觉也可能不包括幻觉的延续。LLM的任务是对幻觉的存在做出裁决。由于few-shot prompting的有效性,这种评测模式对LLM来说相对简单,因为它有助于引发必要的反应。然而,这种方法仅取决于LLM利用其参数内编码的知识的能力,这就需要同时应用知识和推理,因此需要强大的基础模型能力。
选择式评测(Selective Evaluation)。与歧视性评测类似,选择性评测允许LLM通过在选项A或B之间进行选择。具体来说,在选择性评估中,评估中的LLM有一个初始文本,后面是两个连续部分:一个包含幻觉,另一个不包含幻觉。LLM的目的是确定两者中哪一个产生了幻觉。这种评估方法为LLM提供了比判别式评估更多的上下文信息,从而减轻了事实核查的负担,并减少了从其参数中检索事实的依赖性。
生成式评测(Generative Evaluation)。歧视性评测和选择性评测是基于这样一种假设:“LLM产生可靠文本的能力取决于他们对幻觉和非幻觉内容的辨别能力。”这些方法并不模拟对模型幻觉输出的评估。因此,生成性评测至关重要,因为它直接评估LLM生成的文本中是否存在幻觉。具体来说,为评估中的LLM提供初始文本,然后负责生成延续。随后,利用各种基于参考的技术来确定延续是否包括幻觉。然而,挑战来自这样一个事实,即自动准确地确定新生成的文本是否产生幻觉是不可行的;如果是的话,带注释的数据集将是多余的。在不受约束的文本生成场景中,这个问题变得越来越复杂。这种复杂性源于这样一个事实,即在没有限制的情况下生成的文本可能会引入参考材料中缺乏的大量实体和事实,从而使其准确性的验证变得复杂。尽管存在这些障碍,生成性评估仍然是自然语言生成(NLG)任务中的主要策略。
3.3 实验框架
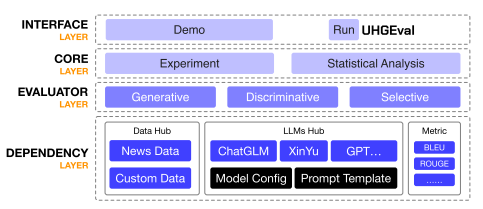
为了实现多种形式,多种模型下,大规模的评测,UHGEval提出了一个完整的实验数据安全,便于拓展,且易于使用的评测框架。框架包括依赖层,评估器层,核心层和界面层四层,如图3所示。
3.4 结果分析
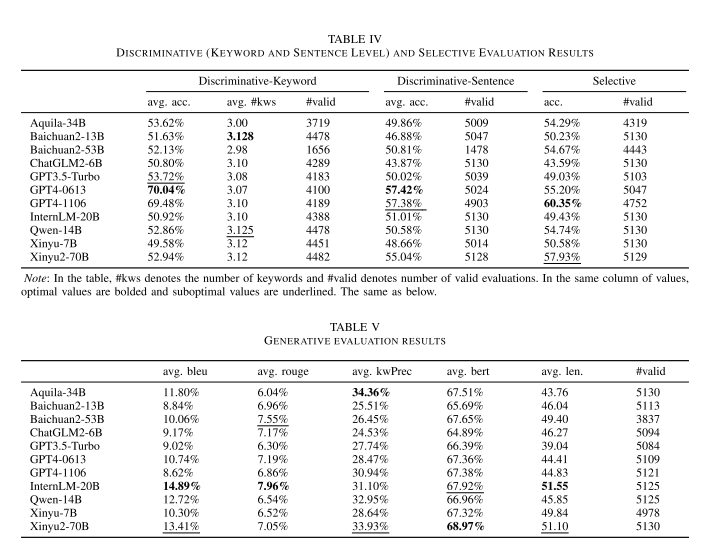
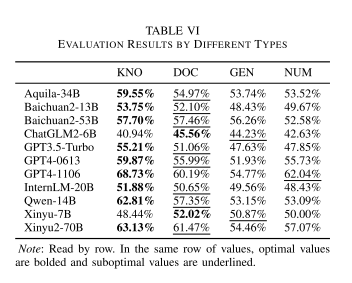
文章从三个不同的评测器,对11个大模型展开了详尽的实验分析,如表4和表5所示。同时也分析了不同新闻类型导致幻觉的差异性,如表6所示。文中提到的观点例如,“领域模型能够在特定场景胜过通用模型”,“GPT系列模型的确存在跷跷板效应”,“基于关键词的幻觉检测比基于句子的幻觉检测更可靠”等。此外,文章还讨论了各种评测器的难易度,优缺点,适用场景等。
4 相关工作及未来方向
4.1 相关工作
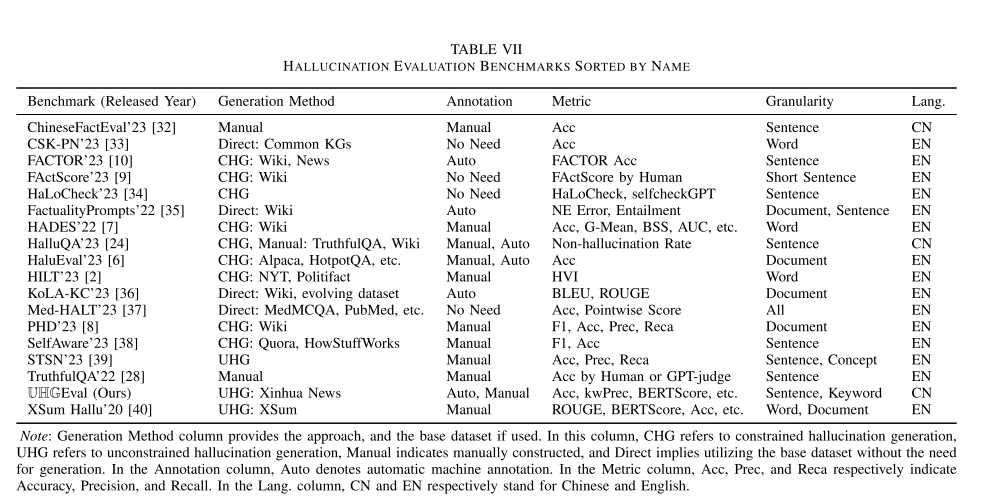
文章从大模型,幻觉,以及评测基准三个角度对相关工作进行了详细的评述。(1)在大模型方面,作者从模型权重的开放性和模型的训练深度(PLM或SFT等)两个维度回顾了目前流行的模型。(2)在大模型幻觉方面,作者回顾了幻觉的定义,表现以及成因。(3)在幻觉评测基准方面,作者全面地回顾了现有的幻觉评测基准,如表7所示。
4.2 未来方向
文章介绍了一个使用无约束幻觉生成的新的基准数据集,包括一个专门为幻觉新闻连续性策划的数据集,该数据集包括5000多个在关键字级别注释的实例。此外,文章提出了一个安全、可扩展和用户友好的评估框架,以促进全面评估。通过对11个知名的LLM的进行实验,作者发现了一系列富有启发性的发现。展望未来,作者的研究工作将坚持探索专业内容生成中幻觉现象的复杂性。与此同时,在基准测试方面,作者希望扩大数据集,以涵盖更多样的领域和语言,从而扩大基准测试的适用性和相关性。

















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









