








本文从三个关键维度:评价什么、在哪里评价和如何评价,对这些 LLMs 评价方法进行了全面回顾。
- 首先,我们从评价任务的角度进行了概述,包括一般自然语言处理任务、推理、医学应用、伦理学、教育、自然科学和社会科学、代理应用以及其他领域。
- 其次,我们通过深入研究评估方法和基准来回答 "在哪里"和 "如何做"的问题,这些方法和基准是评估 LLM 性能的重要组成部分。
- 然后,我们总结了 LLM 在不同任务中的成功和失败案例。
- 最后,我们阐明了 LLMs 评估未来面临的几项挑战。我们的目标是为 LLMs 评估领域的研究人员提供宝贵的见解,从而帮助开发更完善的 LLMs。
我们的核心观点是对 LLMs 的评估应成为一门重要学科,以更好地帮助 LLMs 的发展。我们一直在维护相关的开源材料,网址是: GitHub - MLGroupJLU/LLM-eval-survey: The official GitHub page for the survey paper "A Survey on Evaluation of Large Language Models".
1. INTRODUCTION
理解智能的本质以及确定机器是否体现了智能,是科学家们面临的一个迫切问题。人们普遍认为,真正的智能具备推理能力,使我们能够检验假设,并为未来的可能情况做好准备[92]。人工智能(AI)研究人员尤其关注机器智能的发展,而不是生物智能的发展[136]。适当的测量有助于理解智力。例如,对人类个体一般智力的测量通常围绕 IQ 进行测试[12]。
在人工智能领域,图灵测试[193]是一项广受认可的测试,它通过辨别反应是源于人类还是机器来评估智能。研究人员普遍认为,成功通过图灵测试的计算机可以被认为是智能的。因此,从更广阔的视角来看,人工智能的编年史可以被描述为智能模型和算法的创建与评估时间表。每出现一种新的人工智能模型或算法,研究人员都会通过使用特定的、具有挑战性的任务进行评估,仔细研究其在现实世界场景中的能力。例如,20 世纪 50 年代被誉为人工通用智能(AGI)方法的感知器算法[49],后来因无法解决 XOR 问题而被揭露其不足之处。随后,支持向量机(SVM)[28] 和深度学习[104] 的兴起和应用标志着人工智能领域的进步和挫折。从之前的尝试中得出的一个重要启示是,人工智能评估至关重要,它是识别当前系统局限性和设计更强大模型的重要工具。
最近,大型语言模型(LLMs)在学术和工业领域都引起了极大的兴趣[11, 219, 255]。正如现有工作[15]所证明的那样,LLMs 的卓越性能让人们相信它们可以成为这个时代的 AGI。LLMs 具备解决各种任务的能力,这与之前局限于解决特定任务的模型形成了鲜明对比。由于 LLMs 在处理一般自然语言任务和特定领域任务等不同应用方面表现出色,越来越多的人开始使用 LLMs 来满足学生或病人等对信息的重要需求。
评估对 LLMs 的成功至关重要,原因有以下几点。首先,评估 LLM 有助于我们更好地了解 LLM 的优缺点。例如,PromptBench [262] 基准表明,当前的 LLM 对对抗性提示很敏感,因此,要想获得更好的性能,就必须对提示进行精心设计。其次,更好的评估可以为人类与 LLMs 的交互提供更好的指导,从而为未来的交互设计和实施提供灵感。第三,LLMs 的广泛适用性强调了确保其安全性和可靠性的极端重要性,尤其是在安全敏感领域,例如金融机构和医疗机构。最后,随着 LLM 的规模越来越大,具备更多新兴能力,现有的评估协议可能不足以评估其能力和潜在风险。因此,我们希望通过回顾当前的评估协议,提高社区对 LLMs 评估重要性的认识,最重要的是,为设计新的 LLMs 评估协议的未来研究提供启示。
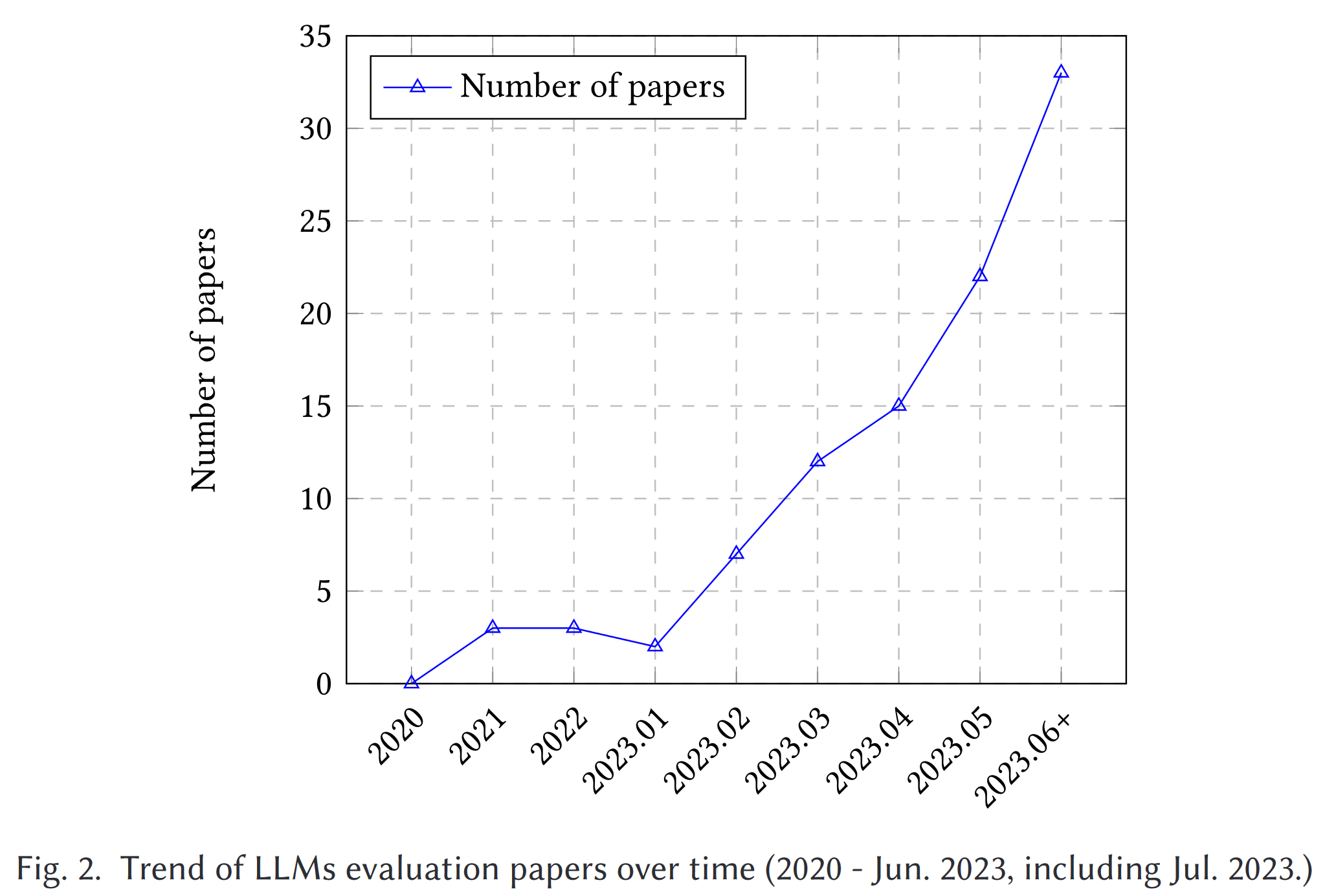
随着 ChatGPT [145] 和 GPT-4 [146]的问世,许多研究工作都旨在从不同方面评估 ChatGPT 和其他 LLM(图 2),包括 natural language tasks, reasoning, robustness, trustworthiness, medical applications, and ethical considerations 等一系列因素。尽管做出了这些努力,但目前仍缺乏一个全面的概述来捕捉整个评估范围。此外,LLM 的不断发展也为评估带来了新的方面,从而对现有的评估协议提出了挑战,并加强了对全面、多方面评估技术的需求。虽然 Bubeck 等人[15]现有的研究声称 GPT-4 可被视为 AGI 的火花,但也有人对这一说法提出质疑,因为其评估方法具有人为设计的性质。
本文是对大型语言模型评估的首次全面调查。如图 1 所示。

我们从三个方面探讨了现有工作:1) 评估什么;2) 在哪里评估;3) 如何评估。具体来说,"评估什么 "概括了现有的 LLM 评估任务,"在哪里评估 "涉及选择合适的数据集和基准进行评估,而 "如何评估 "则涉及对任务和数据集的评估过程。这三个方面是 LLM 评估不可或缺的部分。随后,我们将讨论 LLMs 评估领域未来可能面临的挑战。
本文的贡献如下:
(1) 我们从 "评价什么"、"在哪里评价 "和 "如何评价 "三个方面对 LLMs 的评估进行了全面概述。我们的分类具有普遍性,涵盖了 LLMs 评估的整个生命周期。
(2)关于 "评价什么",我们总结了各个领域的现有任务,并就 LLMs 的成功和失败案例得出了深刻的结论(第 6 节),为今后的研究提供了经验。
(3) 关于 "在哪里评估",我们总结了评估指标、数据集和基准,对当前的 LLMs 评估有了深刻的了解。在如何评价方面,我们探讨了当前的协议,并总结了新颖的评价方法。
(4) 我们进一步讨论了 LLMs 评估的未来挑战。我们将 LLMs 评估的相关资料开源并维护在 GitHub - MLGroupJLU/LLM-eval-survey: The official GitHub page for the survey paper "A Survey on Evaluation of Large Language Models". 网站上,以培养一个合作社区,从而更好地进行评估。
本文的结构如下。第 2 节,我们介绍了 LLM 和人工智能模型评估的基本信息。然后,第 3 节从 "评估什么 "的角度回顾了现有工作。之后,第 4 节是 "在哪里评估 "部分,总结了现有的数据集和基准。第 5 节讨论如何进行评估。第 6 节总结了本文的主要发现。第 7 节讨论了未来的重大挑战,第 8 节是本文的结尾。
2. BACKGROUND
2.1. Large Language Models
语言模型(LM)[36, 51, 96] 是一种能够理解和生成人类语言的计算模型。语言模型具有转换能力,可预测词序列的可能性或根据给定输入生成新文本。N-gram 模型[13]是最常见的 LM 类型,它根据前面的上下文来估计单词的可能性。然而,LM 也面临着一些挑战,如罕见词或未见词问题、过拟合问题以及难以捕捉复杂语言现象的问题。研究人员正在不断改进 LM 架构和训练方法,以应对这些挑战。
大型语言模型(LLMs)[19, 91, 255]是一种先进的语言模型,具有庞大的参数规模和卓越的学习能力。许多 LLM(如 GPT-3 [43]、InstructGPT [149] 和 GPT-4 [146])背后的核心模块是 Transformer [197] 中的自我注意模块。自注意力模块是语言建模任务的基本构件。Transformers 能够高效处理序列数据,实现并行化,并捕捉文本中的长距离依赖关系,从而在 NLP 领域掀起了一场革命。LLM 的一个主要特点是上下文学习 [14],即根据给定的上下文或提示来训练模型生成文本。这使得 LLMs 能够生成更加连贯和与上下文相关的回复,从而使其适用于交互式和对话式应用。从人类反馈中强化学习(RLHF)[25, 266] 是 LLMs 的另一个重要方面。这项技术包括利用人类生成的回复作为奖励对模型进行微调,使模型能够从错误中吸取教训,并随着时间的推移不断改进其性能。
在自回归语言模型(如 GPT-3 和 PaLM [24])中,给定上下文序列 X 时,LM 任务的目的是预测下一个标记 y。模型的训练方法是最大化给定标记序列在上下文条件下的概率,即 P(y|X ) = P(y|x1, x2,...,xt-1) ,其中 x1, x2,...,xt-1 是上下文序列中的标记,t 是当前位置。利用链式规则,条件概率可以分解为每个位置的概率乘积:
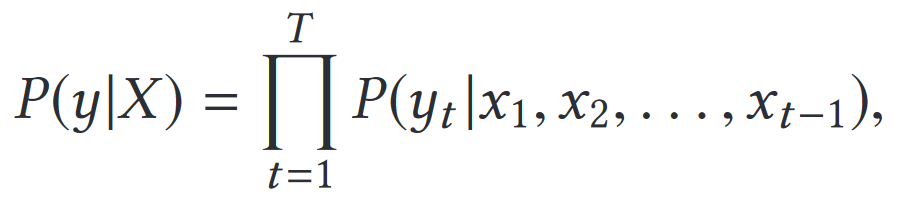
其中 T 为序列长度。这样,该模型就能以自回归的方式预测每个位置上的每个标记,从而生成一个完整的文本序列。
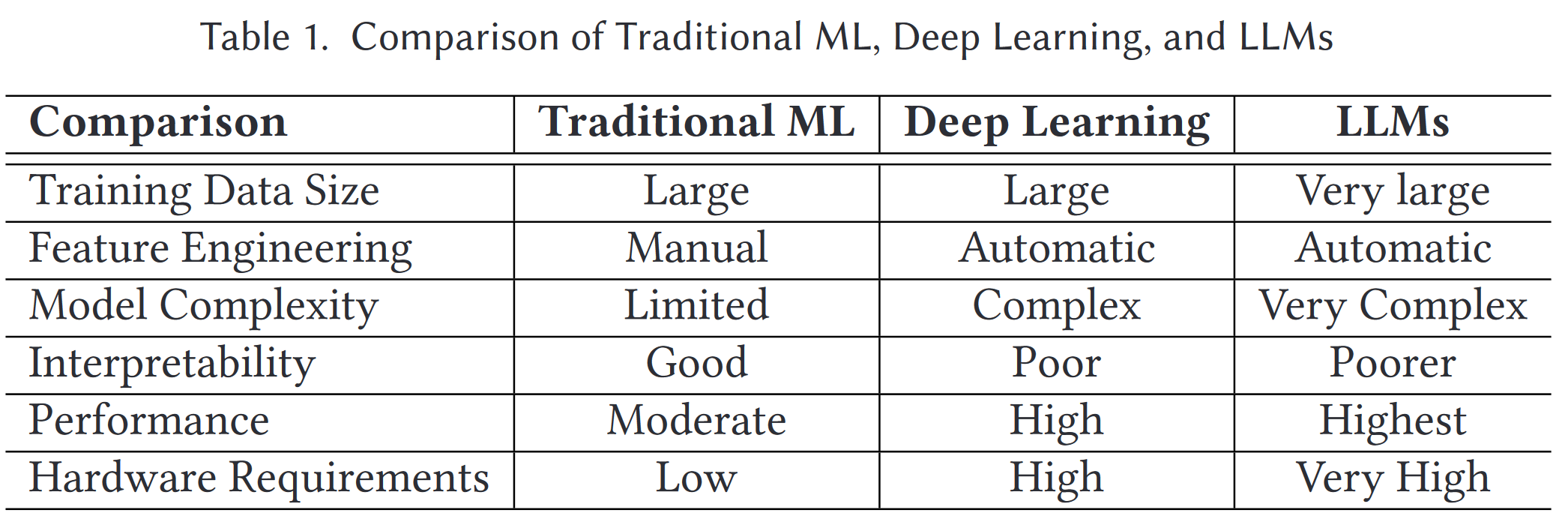
与 LLMs 交互的一种常见方法是提示工程(prompt engineering)[26, 221, 261],即用户设计并提供特定的提示文本,引导 LLMs 生成所需的回复或完成特定任务。这种方法在现有的评估工作中被广泛采用。人们还可以参与问答互动[83],即向模型提出问题并得到答案,或者参与对话互动,与 LLM 进行自然语言对话。总之,LLM 凭借其 Transformer 架构、上下文学习和 RLHF 能力,已经彻底改变了 NLP,并在各种应用中大有可为。表 1 简单比较了传统 ML、深度学习和 LLM。
2.2. AI Model Evaluation
人工智能模型评估是评估模型性能的重要步骤。目前有一些标准的模型评估方案,包括 k-fold cross-validation、holdout validation、leave one out cross-validation (LOOCV)、bootstrap 和 reduced set [8,95]。例如,K-fold cross-validation 将数据集分为 k 部分,其中一部分作为测试集,其余部分作为训练集,这样可以减少训练数据的损失,获得相对更准确的模型性能评价[48];Holdout validation 将数据集分为训练集和测试集,计算量较小,但可能存在较大偏差;LOOCV 是一种独特的 k 倍交叉验证方法,只用一个数据点作为测试集[222];Reduced set 用一个数据集训练模型,用剩余数据进行测试,计算简单,但适用性有限。应根据具体问题和数据特征选择合适的评价方法,以获得更可靠的性能指标。
图 3 展示了人工智能模型(包括 LLM)的评估过程。由于深度学习模型需要大量的训练,某些评估协议可能无法对其进行评估。因此,长期以来,在静态验证集上进行评估一直是深度学习模型的标准选择。例如,计算机视觉模型利用 ImageNet [33] 和 MS COCO [120] 等静态测试集进行评估。LLM 也使用 GLUE [200] 或 SuperGLUE [199] 作为常用测试集。

随着 LLM 的流行,可解释性却越来越差,现有的评估协议可能不足以全面评估 LLM 的真正能力。我们将在第 5 节介绍最近对 LLM 的评估。
3. WHAT TO EVALUATE
我们应该评估 LLMs 在哪些任务中的表现?在本节中,我们将现有任务分为以下几类:自然语言处理、鲁棒性、伦理、偏见和可信度、社会科学、自然科学和工程学、医学应用、agent 应用以及其他应用。
3.1. 自然语言处理任务
开发语言模型,特别是大型语言模型的最初目的是提高自然语言处理任务的性能,包括理解和生成两个方面。因此,大多数评估研究都主要集中在自然语言任务上。表 2 总结了现有研究的评估方面,我们将在下文中重点介绍其结论。

3.1.1. 自然语言理解(NLU)
自然语言理解是一个范围广泛的任务,其目的是更好地理解输入序列。我们从几个方面总结了最近在 LLM 评估方面所做的努力。
情感分析(Sentiment analysis)是一项分析和解释文本以确定情感倾向的任务。它通常是一个二元(正面和负面)或三元(正面、中性和负面)分类问题。评估情感分析任务是一个流行的方向。Liang 等人[114]和 Zeng 等人[242]的研究表明,该任务的模型性能通常很高。ChatGPT 的情感分析预测性能优于传统的情感分析方法 [129],并接近 GPT-3.5 [159]。在细粒度情感和情绪原因分析中,ChatGPT 也表现出了卓越的性能 [218]。在低资源学习环境中,LLM 与小语言模型相比具有显著优势 [249],但 ChatGPT 理解低资源语言的能力有限 [6]。总之,LLM 在情感分析任务中的表现值得称赞。未来的工作重点应放在提高 LLMs 理解低资源语言情感的能力上。
文本分类(Text classification)和情感分析是相关领域;文本分类不仅关注情感,还包括对所有文本和任务的处理。Liang 等人[114]的研究表明,GLM-130B 是表现最好的模型,在杂项文本分类中的总体准确率为 85.8%。Yang和Menczer[232]发现,ChatGPT可以为各种新闻媒体提供可信度评级,而且这些评级与人类专家的评级有适度的相关性。此外,ChatGPT 在二元分类情况下达到了可接受的准确度(AUC=0.89)。Peña 等人[154]讨论了公共事务文档的主题分类问题,并表明使用 LLM backbone 与 SVM 分类器相结合是在公共事务领域执行多标签主题分类任务的有效策略,准确率超过 85%。总体而言,LLM 在文本分类方面表现出色,甚至可以处理非常规问题环境中的文本分类任务。
自然语言推理(NLI)是判断给定的 "假设 "是否符合 "前提 "的逻辑。Qin 等人[159]的研究表明,ChatGPT 在自然语言推理任务方面的表现优于 GPT-3.5。他们还发现,ChatGPT 在处理事实输入方面表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









