






PyTorch深度学习实战(46)——深度Q学习
0. 前言
我们已经学习了如何构建一个 Q 表,通过在多个 episode 中重复进行游戏获取与给定状态-动作组合相对应的值。然而,当状态空间是连续时,可能的状态空间数会变得非常巨大。在本节中,我们将学习如何使用神经网络在没有 Q 表的情况下估计状态-动作组合的 Q 值,因此称为深度 Q 学习 (deep Q-learning)。
1. 深度 Q 学习
与 Q 表相比,深度 Q 学习利用神经网络将任意给定的状态-动作(其中状态可以是连续或离散的)组合映射到相应 Q 值。
在本节中,将使用 Gym 中的 CartPole 环境,智能体的任务是尽可能长时间地平衡 CartPole,CartPole 环境如下图所示:

当小车向右移动时,杆向左移动,反之亦然,CartPole 环境中的每个状态都由四个观测值定义,其名称及其最小值和最大值如下:
| 状态 | 最小值 | 最大值 |
|---|---|---|
| Cart position | -2.4 | 2.4 |
| Cart velocity | -inf | inf |
| Pole angle | -41.8° | 41.8° |
| Pole velocity at the tip | -inf | inf |
需要注意的是,表示状态的所有观测值都具有连续值,用于 CartPole 平衡游戏的深度 Q 学习的工作原理如下:
- 获取输入值(游戏图像/游戏元数据)
- 通过网络传递输入值,网络的输出与可能的动作数相同
- 输出层预测在给定状态下采取某个动作对应的 Q 值
2. 网络架构
网络架构使用状态(四个观测值)作为输入,在当前状态下采取左/右动作的 Q 值作为输出。神经网络训练策略如下:
- 在探索阶段,执行输出层中具有最高值的随机动作
- 将动作、下一个状态、奖励和指示游戏是否完成的标志存储在内存中
- 如果游戏没有完成,计算在给定状态下采取行动的 Q 值,即奖励 + 折扣因子 x 下一个状态中所有动作的最大可能 Q 值
- 修改采取动作的Q值,而其他状态-动作组合的 Q 值保持不变
- 多次执行步骤
1到4并存储经验 - 拟合模型,将状态作为输入,动作值作为预期输出(来自内存和回放经验),并最小化
MSE损失 - 在降低探索率的同时在多个
episode上重复上述步骤
3. 实现深度 Q 学习模型进行 CartPole 游戏
根据以上策略,使用 PyTorch 编写深度 Q 学习模型,进行 CartPole 游戏。
(1) 导入相关库:
import gym
import numpy as np
import cv2
from collections import deque
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import random
from collections import namedtuple, deque
import torch
import torch.nn.functional as F
import torch.optim as optim
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
(2) 定义环境:
env = gym.make('CartPole-v1')
(3) 定义网络架构:
class DQNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(DQNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_size)
def forward(self, state):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
该架构在两个隐藏层中仅包含 24 个单元,输出层包含与可能动作数相同的单元。
(4) 定义 Agent 类。
定义 __init__ 方法,其中包含各种参数、网络的定义:
class Agent():
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.seed = random.seed(0)
## hyperparameters
self.buffer_size = 2000
self.batch_size = 64
self.gamma = 0.99
self.lr = 0.0025
self.update_every = 4
# Q-Network
self.local = DQNetwork(state_size, action_size).to(device)
self.optimizer = optim.Adam(self.local.parameters(), lr=self.lr)
# Replay memory
self.memory = deque(maxlen=self.buffer_size)
self.experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])
self.t_step = 0
定义 step 函数,该函数从内存中获取数据并通过调用 learn 函数将其拟合到模型中:
def step(self, state, action, reward, next_state, done):
# Save experience in replay memory
self.memory.append(self.experience(state, action, reward, next_state, done))
# Learn every update_every time steps.
self.t_step = (self.t_step + 1) % self.update_every
if self.t_step == 0:
# If enough samples are available in memory, get random subset and learn
if len(self.memory) > self.batch_size:
experiences = self.sample_experiences()
self.learn(experiences, self.gamma)
定义 act 函数,该函数在给定状态的情况下预测动作:
def act(self, state, eps=0.):
# Epsilon-greedy action selection
if random.random() > eps:
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
self.local.eval()
with torch.no_grad():
action_values = self.local(state)
self.local.train()
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
在以上代码中,我们在确定要采取的行动时使用探索-利用策略。
定义 learn 函数用于拟合模型,使其在给定状态时预测动作值:
def learn(self, experiences, gamma):
states, actions, rewards, next_states, dones = experiences
# Get expected Q values from local model
Q_expected = self.local(states).gather(1, actions)
# Get max predicted Q values (for next states) from local model
Q_targets_next = self.local(next_states).detach().max(1)[0].unsqueeze(1)
# Compute Q targets for current states
Q_targets = rewards + (gamma * Q_targets_next * (1 - dones))
# Compute loss
loss = F.mse_loss(Q_expected, Q_targets)
# Minimize the loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
在以上代码中,获取采样经验并预测我们执行的动作的 Q 值。此外,由于我们已经知道下一个状态,可以预测下一个状态下动作的最佳 Q 值。因此,我们可以得到与在给定状态下采取的动作相对应的目标值。最后,计算在当前状态下采取的动作的 Q 值的期望值 (Q_targets) 和预测值 (Q_expected) 之间的误差。
定义 sample_experiences 函数以便从内存中采样经验:
def sample_experiences(self):
experiences = random.sample(self.memory, k=self.batch_size)
states = torch.from_numpy(np.vstack([e.state for e in experiences if e is not None])).float().to(device)
actions = torch.from_numpy(np.vstack([e.action for e in experiences if e is not None])).long().to(device)
rewards = torch.from_numpy(np.vstack([e.reward for e in experiences if e is not None])).float().to(device)
next_states = torch.from_numpy(np.vstack([e.next_state for e in experiences if e is not None])).float().to(device)
dones = torch.from_numpy(np.vstack([e.done for e in experiences if e is not None]).astype(np.uint8)).float().to(device)
return (states, actions, rewards, next_states, dones)
(5) 定义智能体对象:
agent = Agent(env.observation_space.shape[0], env.action_space.n)
(6) 训练模型。
初始化列表:
scores = [] # list containing scores from each episode
scores_window = deque(maxlen=100) # last 100 scores
n_episodes=5000
max_t=5000
eps_start=1.0
eps_end=0.001
eps_decay=0.9995
eps = eps_start
在每个 episode 中重置环境并获取状态的形状,此外,整形状态维度形状,以便可以将其传递给网络:
for i_episode in range(1, n_episodes+1):
state = env.reset()
state_size = env.observation_space.shape[0]
state = np.reshape(state, [1, state_size])
score = 0
循环通过 max_t 个时间步,确定要执行的动作,并使用 step 方法执行,使用 np.reshape 整形状态张量,并将整形后的状态传递给神经网络:
for i in range(max_t):
action = agent.act(state, eps)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
通过指定 agent.step 在当前状态之上拟合模型,并将状态重置为下一个状态,以便在下一次迭代中使用。
如果前 10 步的得分平均值大于 450,则存储相关数据并停止训练:
reward = reward if not done or score == 499 else -10
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
eps = max(eps_end, eps_decay*eps) # decrease epsilon
print('\rEpisode {}\tReward {} \tAverage Score: {:.2f} \tEpsilon: {}'.format(i_episode,score,np.mean(scores_window), eps), end="")
if i_episode % 100 == 0:
print('\rEpisode {}\tAverage Score: {:.2f} \tEpsilon: {}'.format(i_episode, np.mean(scores_window), eps))
if i_episode>10 and np.mean(scores[-10:])>450:
break
"""
Episode 100 Average Score: 12.65 ge Epsilon: 0.951217530242334.9512175302423344
...
Episode 2700 Average Score: 116.56 e Epsilon: 0.259152752655221145915275265522114
Episode 2712 Reward 500.0 Average Score: 159.01 Epsilon: 0.2576021050410192
"""
(7) 绘制随着 episode 的增加的分数变化情况如下:
import matplotlib.pyplot as plt
plt.plot(scores)
plt.title('Scores over increasing episodes')
plt.show()
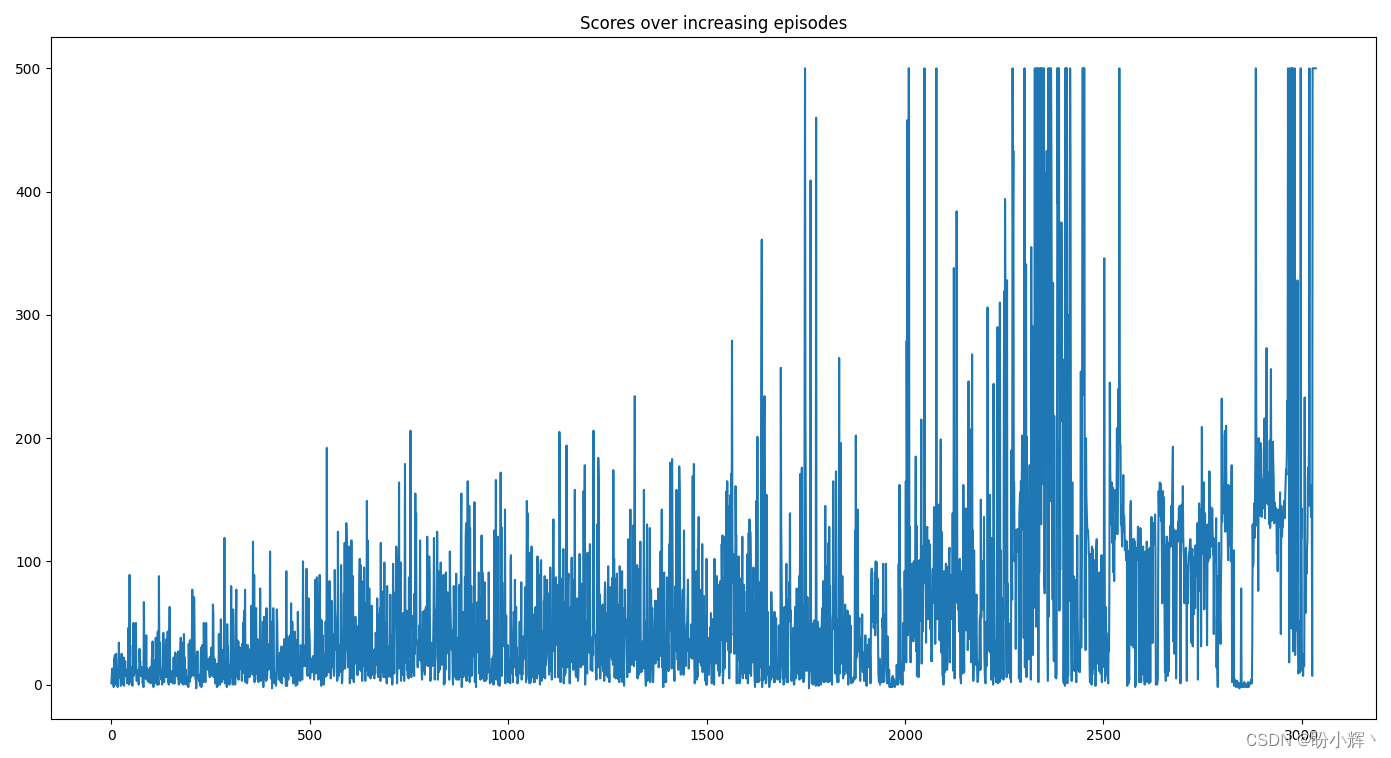
从上图中可以看出,在第 2000 个 episode 之后,该模型在进行 CartPole 游戏时能够获得较高分。
小结
深度 Q 学习是一种结合了深度学习和强化学习的方法,通过深度神经网络逼近 Q 值函数,在解决大规模、连续状态空间问题方面具有优势,并在多个领域展示了强大的学习和决策能力。在本节中,介绍了深度 Q 学习的基本概念,并学习了如何使用 PyTorch 实现深度 Q 学习进行 CartPole 游戏。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(24)——使用U-Net架构进行图像分割
PyTorch深度学习实战(25)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)——多对象实例分割
PyTorch深度学习实战(27)——自编码器(Autoencoder)
PyTorch深度学习实战(28)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(31)——神经风格迁移
PyTorch深度学习实战(32)——Deepfakes
PyTorch深度学习实战(33)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)——DCGAN详解与实现
PyTorch深度学习实战(35)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)——Pix2Pix详解与实现
PyTorch深度学习实战(37)——CycleGAN详解与实现
PyTorch深度学习实战(38)——StyleGAN详解与实现
PyTorch深度学习实战(39)——小样本学习(Few-shot Learning)
PyTorch深度学习实战(40)——零样本学习(Zero-Shot Learning)
PyTorch深度学习实战(41)——循环神经网络与长短期记忆网络
PyTorch深度学习实战(42)——图像字幕生成
PyTorch深度学习实战(43)——手写文本识别
PyTorch深度学习实战(44)——基于 DETR 实现目标检测
PyTorch深度学习实战(45)——强化学习
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











