







1 数据处理
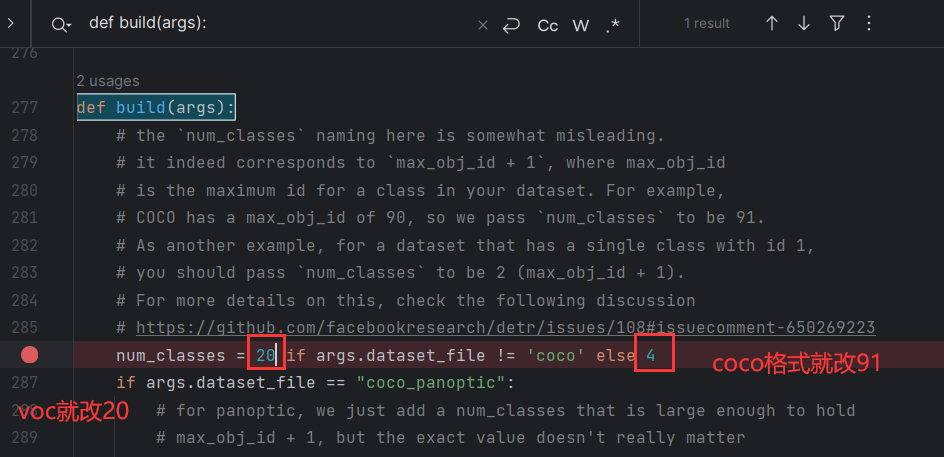
- 修改类别数:在
models/detector.py中定位到def build(args):,将num_classes进行修改,改为最大的类别id+1。我有4个类别,类别id是从0~3,因此max_id=3,这里的num_classes=max_id+1=4
- 修改数据集位置:
- 允许输入
voc、coco两种格式,在main.py的--dataset_file设置,默认的是使用coco - 在
main.py的--coco_path指明数据集根目录 - 我用的是
coco格式,yolo标签转为coco格式的代码可参考将YOLO数据集转成COCO格式,单个文件夹转为单个json文件,例如…/images/train转为instance_train.json,如果要用voc格式,可自行看看源码datasets/voc.py
- 允许输入
然后,因为我的数据集排布是:
F:/A_Publicdatasets/RDD2020-1202/train_valid/RDD2020_together
├─annotations
│ ├─instances_train.json
│ ├─instances_val.json
│ └─instances_test.json
├─images
│ ├─test
│ │ ├─xxx.jpg
│ │ ├─xxx.jpg
│ ├─train
│ └─val
因此,在datasets/coco.py中根据自己的数据集进行更改:
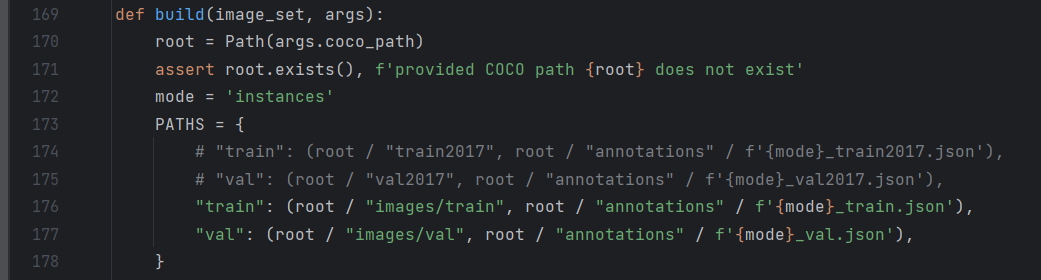
"train": (root / "images/train", root / "annotations" / f'{mode}_train.json'),
"val": (root / "images/val", root / "annotations" / f'{mode}_val.json'),
2 配置训练参数
官方给的训练YOLOS-S 300轮的命令:
python -m torch.distributed.launch \
--nproc_per_node=8 \
--use_env main.py \
--coco_path /path/to/coco
--batch_size 1 \
--lr 2.5e-5 \
--epochs 150 \
--backbone_name small \
--pre_trained /path/to/deit-small-300epoch.pth\
--eval_size 800 \
--init_pe_size 512 864 \
--mid_pe_size 512 864 \
--output_dir /output/path/box_model
参照着上面去修改即可,我喜欢将参数直接给修改在main.py里面,但我:
- 把
--init_pe_size和--mid_pe_size都设置成了default=(640, 640),这应该是跟图像尺寸相关的 - 没有使用
--pre_trained,因为不想使用预训练权重
题外话:
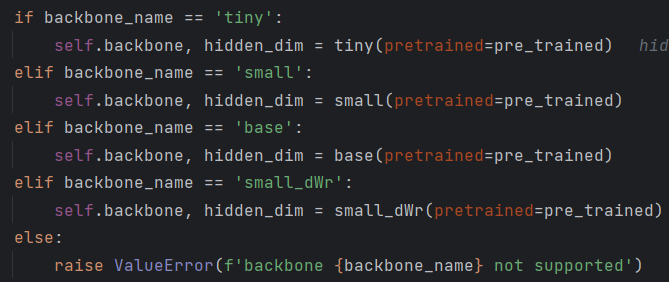
选择使用哪个?默认的是tiny,可以换成small,可对应models/backbone.py中进行查看,可以定位到tiny、small函数位置

对应的有这些选项:
3 可能会遇到的报错
可能会遇到这个报错:ImportError: cannot import name 'container_abcs' from 'torch._six' (F:\SoftWareInstall\Anaconda3\envs\torch1.10\lib\site-packages\torch\_six.py),然后参照这个篇博客【报错】cannot import name ‘container_abcs‘ from ‘torch._six‘
在models/layers/helper.py中将from torch._six import container_abcs改为如下代码即可:
import collections.abc as container_abcs
















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











