







理解SVM
支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
线性分类器:给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。如果用x表示数据点,用y表示类别(y可以取1或者-1,分别代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为( wT中的T代表转置):
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0
这个超平面可以用分类函数:
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b
表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:

函数间隔与几何间隔
在超平面wx+b=0确定的情况下,|wx+b|能够表示点x到距离超平面的远近,而通过观察wx+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用(y(wx+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔**(functional margin)的概念。
函数间隔公式:
γ
=
y
(
w
T
x
+
b
)
=
y
f
(
x
)
\gamma=y(w^Tx+b)=yf(x)
γ=y(wTx+b)=yf(x)
函数间隔与几何间隔
在超平面wx+b=0确定的情况下,|wx+b|能够表示点x到距离超平面的远近,而通过观察wx+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用(y(wx+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔**(functional margin)的概念。
函数间隔公式:
γ
=
m
i
n
γ
i
(
i
=
1
,
.
.
.
n
)
\gamma=min\gamma i(i=1,...n)
γ=minγi(i=1,...n)
但这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(虽然此时超平面没有改变),所以只有函数间隔还远远不够。
几何间隔
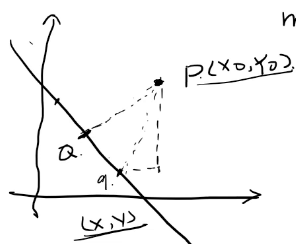
事实上,我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离–几何间隔(geometrical margin)的概念。假定对于一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直于超平面的一个向量, 𝛾 为样本x到超平面的距离,如下图所示:
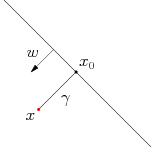
几何间隔:
γ
′
=
γ
∣
∣
w
∣
∣
\gamma'=\frac{\gamma}{||w||}
γ′=∣∣w∣∣γ
从上述函数间隔和几何间隔的定义可以看出:几何间隔就是函数间隔除以||w||,而且函数间隔y(wx+b) = yf(x)实际上就是|f(x)|,只是人为定义的一个间隔度量,而几何间隔|f(x)|/||w||才是直观上的点到超平面的距离。
最大间隔分类器的定义
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。

通过由前面的分析可知:函数间隔不适合用来最大化间隔值,因为在超平面固定以后,可以等比例地缩放w的长度和b的值,这样可以使得:
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b
的值任意大,亦即函数间隔可以在超平面保持不变的情况下被取得任意大。但几何间隔因为除上了,使得在缩放w和b的时候几何间隔的值是不会改变的,它只随着超平面的变动而变动,因此,这是更加合适的一个间隔。换言之,这里要找的最大间隔分类超平面中的“间隔”指的是几何间隔。
如下图所示,中间的实线便是寻找到的最优超平面(Optimal Hyper Plane),其到两条虚线边界的距离相等,这个距离便是几何间隔,两条虚线间隔边界之间的距离等于2倍几何间隔,而虚线间隔边界上的点则是支持向量。由于这些支持向量刚好在虚线间隔边界上,所以它们满足:
y
(
w
T
x
+
b
)
=
1
y(w^Tx+b)=1
y(wTx+b)=1
对于所有不是支持向量的点,则显然有:
y
(
w
T
x
+
b
)
>
1
y(w^Tx+b)>1
y(wTx+b)>1

通过支持向量的定义可知:
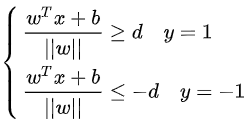
备注:左边代表几何间隔,d代表支持向量和分割平面的距离;y=1代表正样本(左上角),y=-1代表负样本(右上角)。
稍作转化:
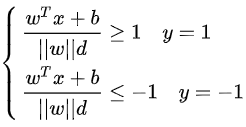
暂令||w||d为1,因为它对目标函数的优化没有影响:
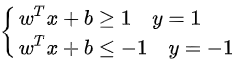
合并公式:
y
(
w
T
x
+
b
)
≥
1
y(w^Tx+b)\ge1
y(wTx+b)≥1
我们要优化的目标函数,仅仅只针对支持向量,所以
y
(
w
T
x
+
b
)
=
1
y(w^Tx+b)=1
y(wTx+b)=1,对其他点肯定就是大于1,不过SVM只关注支持向量决策下来的那个平面:
m
a
x
2
∗
y
(
w
T
x
+
b
)
∣
∣
w
∣
∣
max 2*\frac{y(w^Tx+b)}{||w||}
max2∗∣∣w∣∣y(wTx+b)
这里乘上 2 倍也是为了后面推导,对目标函数没有影响。刚我们得到支持向量的函数间隔为1。
目标函数转化为:
m
a
x
2
∣
∣
w
∣
∣
max\frac{2}{||w||}
max∣∣w∣∣2
继续转化:
m
i
n
1
2
∣
∣
w
∣
∣
2
min\frac{1}{2}||w||^2
min21∣∣w∣∣2
添加优化限制:
m
i
n
1
2
∣
∣
w
∣
∣
2
min\frac{1}{2}||w||^2
min21∣∣w∣∣2 s.t.
y
(
w
T
x
+
b
)
≥
1
y(w^Tx+b)\ge1
y(wTx+b)≥1
备注:损失函数只考虑支持向量,但是约束条件需要考虑全部的样本点,保证选到的样本一定是支持向量的那个样本,所以有这么一个约束,就是说其他点都没有我离这个分割平面最近,其他点的函数间隔都要大于等于1。
如何求解这样的有限制最优化问题?
最优化问题的形式:
无约束优化问题,可写作:
min f(x);
有等式约束的优化问题,可写作:
min f(x),
s.t.
h
i
(
x
)
=
0
;
i
=
1
,
.
.
.
,
n
h_i(x) = 0; i =1, ..., n
hi(x)=0;i=1,...,n
有不等式约束的优化问题,可以写为:
min f(x),
s.t.
g
i
(
x
)
<
=
0
;
i
=
1
,
.
.
.
,
n
g_i(x) <= 0; i =1, ..., n
gi(x)<=0;i=1,...,n
h
j
(
x
)
=
0
;
j
=
1
,
.
.
.
,
m
h_j(x) = 0; j =1, ..., m
hj(x)=0;j=1,...,m
一般数学上的求解方式:【记住方法就可以,不需要记住推导】
1>使用求取f(x)的导数,然后令其为零,可以求得候选最优值;
2>常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束
h
i
(
x
)
h_i(x)
hi(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值;
3>常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件;
拉格朗日乘子法(Lagrange Multiplier)
核心思想:
约束条件和目标函数归纳到同一个函数当中(拉格朗日函数)
对于等式约束,我们可以通过一个拉格朗日系数a 把等式约束和目标函数组合成为一个式子
L
(
a
,
x
)
=
f
(
x
)
+
a
∗
h
(
x
)
L(a, x) = f(x) + a*h(x)
L(a,x)=f(x)+a∗h(x)
优化方式:
然后求取最优值,可以通过对L(a,x)对各个参数求导取零,联立等式进行求取
KKT条件
核心思想相似 同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子
L
(
a
,
b
,
x
)
=
f
(
x
)
+
a
g
(
x
)
+
b
h
(
x
)
L(a, b, x)= f(x) + ag(x)+bh(x)
L(a,b,x)=f(x)+ag(x)+bh(x)
但必须满足以下条件:
L
(
a
,
b
,
x
)
L(a, b, x)
L(a,b,x)对x求导为零;
h
(
x
)
=
0
h(x) =0
h(x)=0;
a
∗
g
(
x
)
=
0
a*g(x) = 0
a∗g(x)=0;
其实点到直线的距离公式就有一种求解方式是拉格朗日乘子法:

不需要深入了解核函数,只需要了解:
svm解决线性不可分问题中,可以使用核函数对这个问题进行转换。
优化问题的转化过程:
1.经过拉格朗日乘子法转化前:
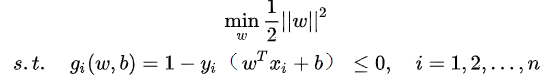
2.构造拉格朗日函数:
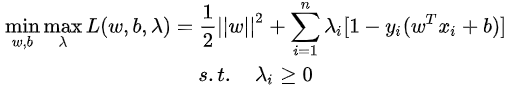
svm损失函数怎么优化?
把以上1有约束情况的极小化这个问题,通过强对偶性转化为一个拉格朗日损失函数2,然后再去优化这个拉格朗日损失函数即可,不需要记住公式,了解到这步即可。
3.求导:
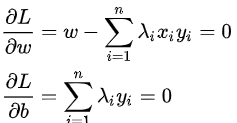
得到:
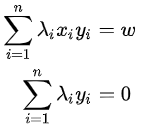
带回原优化函数:

得到:
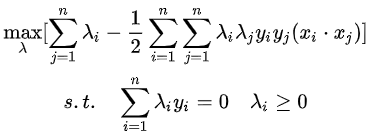
这是一个二次规划问题,问题规模正比于训练样本数,我们常用 SMO(Sequential Minimal Optimization) 算法求解。
SMO(Sequential Minimal Optimization),序列最小优化算法,其核心思想非常简单:每次只优化一个参数,其他参数先固定住,仅求当前这个优化参数的极值。
hinge loss合页损失函数
【只需要记住这句】线性支持向量机学习等价于最小化二阶范数正则化的合页函数。
拉格朗日乘子法转换后的损失函数:
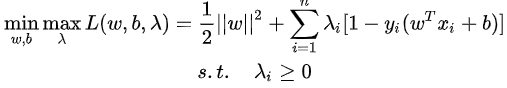
合页损失函数的特性:

线性不可分问题
通过松弛变量使某些样本不满足这个约束也可以容忍得了,来解决线性不可分问题,了解即可。还一种方式是使用核函数对问题进行转换,了解即可。
总结
SVM它本质上即是一个分类方法,用 w T x + b w^Tx+b wTx+b 定义分类函数,于是求w、b,为寻最大间隔,引出1/2||w||^2,继而引入拉格朗日因子,化为对拉格朗日乘子a的求解(求解过程中会涉及到一系列最优化或凸二次规划等问题),如此,求w.b与求a等价,而a的求解可以用一种快速学习算法SMO,至于核函数,是为处理非线性情况,若直接映射到高维计算恐维度爆炸,故在低维计算,等效高维表现。
感知机的损失函数:它是误分点到这个平面的函数间隔。
只跟误分点有关系,跟其他点完全没有关系。
svn的损失函数:合页函数,更深的表示:
在一个有约束条件下最小化我们的支持向量到平面的几何间隔。
约束是要求我们的支持向量一定要是跟平面最近的向量,所以就有了一系列约束。
一系列约束表示有样本个,有n个样本就有n个约束。
约束的内容是所有其他点到这个平面的距离一定比这个支持向量的大。
有了这个约束项,在求支持向量自己到这个平面的几何间隔最大的这个损失函数。
这个损失函数的原始形式要优化的目标只跟支持向量有关系,所以就有了支持向量机这个名字。
如何一步一步优化这个过程?首先通过拉格朗日乘子法把我们有约束的优化问题转换为直接把约束部分直接把约束部分写进优化函数里面的拉格朗日函数这样的一种形式,最后通过求导得到结果。
同时它里面还用到了SMO算法,SMO算法是为了解决在进行拉格朗日乘子法的转发之后我们一步一步的对它进行梯度优化的这个过程。
支持向量机记住点:
1)函数间隔和几何间隔公式手写;
2)了解名词:
- 拉格朗日乘子法做了什么?
- SMO算法解决什么问题?
- 强对偶转化将一个最小最大问题(先求某些参数下函数最大,再求某些参数下函数极小)转换为一个最小最大问题
3)svm损失函数怎么写?
首先通过原始几何间隔,令支持向量函数间隔为1这个条件后,将其转换为最终有约束的优化问题,所有公式只用记住这部分,后面口述:将有约束的优化问题通过拉格朗日乘子法转换为一个极大极小问题,然后通过这个极大极小的对偶问题(也就是对应的极小极大问题),最后来求解这个问题,即先对w和b进行求导,使得w和b取值使拉格朗日函数最小的这个w和b,再将求得的值带回去,最后通过SMO算法解出最终的
λ
\lambda
λ,然后就得到了整个函数。
4)svm的合页损失函数,就是一个加了L2范式的svm合页损失函数。
SVM的一些问题
是否存在一组参数使SVM训练误差为0?
答:意思就是线性可分,肯定存在
训练误差为0的SVM分类器一定存在吗?
答:一定存在
加入松弛变量的SVM的训练误差可以为0吗?
答:使用SMO算法训练的线性分类器并不一定能得到训练误差为0的模型。这是由 于我们的优化目标改变了,并不再是使训练误差最小。
带核的SVM为什么能分类非线性问题?
答:核函数的本质是两个函数的內积,通过核函数将其隐射到高维空间,在高维空间非线性问题转化为线性问题, SVM得到超平面是高维空间的线性分类平面。其分类结果也视为低维空间的非线性分类结果, 因而带核的SVM就能分类非线性问题。简单回答就是可以投射到另外一个空间,所以可分。
如何选择核函数?
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
【面试常问】 LR和SVM的联系与区别
相同点:
- 都是线性分类器。本质上都是求一个最佳分类超平面。
- 都是监督学习算法。
- 都是判别模型。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。常见的判别模型有:KNN、SVM、LR,常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。
不同点:
- LR是参数模型,svm是非参数模型,linear和rbf则是针对数据线性可分和不可分的区别;
- 从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
- 逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
- logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
线性分类器与非线性分类器的区别以及优劣:
线性和非线性是针对模型参数和输入特征来讲的;比如输入x,模型y=ax+ax^2 那么就是非线性模型,如果输入是x和X^2则模型是线性的。
- 线性分类器可解释性好,计算复杂度较低,不足之处是模型的拟合效果相对弱些。
LR,贝叶斯分类,单层感知机、线性回归 - 非线性分类器效果拟合能力较强,不足之处是数据量不足容易过拟合、计算复杂度高、可解释性不好。
决策树、RF、GBDT、多层感知机 - SVM两种都有(看线性核还是高斯核)
svm的优缺点
1.优点
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”
2.缺点
- 训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为O(n*n) ,其中 N 为训练样本的数量;
- 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为O(n*n) ;
- 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高
- 无法处理缺失数据
- 只适用于二分类问题,使用多个二分类器组合组合才可以进行多分类
为什么svm走下了神坛?
1.模型稳定性低,输入的微小变化会使得模型难以收敛;
2. 在数据量大的情况下运算复杂度高,不适合处理过大的数据;
3.分类能力被其他分类器超越;














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









