







Abstract
- 最近对深度神经网络的研究主要集中在提高准确性上。对于给定的准确度级别,通常可以识别达到该准确度级别的多个DNN架构。具有同等精度,较小的DNN架构至少具有三个优势:
- 在分布式培训期间,较小的DNN需要较少的服务器通信。
- 较小的DNN需要较少的带宽来将新模型从云导出到自动驾驶汽车。
- 较小的DNN更适合部署在FPGA和内存有限的其他硬件上。
- 为了提供所有这些优势,我们提出了一种名为SqueezeNet的小型DNN架构。SqueezeNet在ImageNet上实现了AlexNetlevel精度,参数减少了50倍。 此外,通过模型压缩技术,我们可以将SqueezeNet压缩到不到1MB。
Introduction
- 最近关于深度神经网络的许多研究都集中在提高计算机视觉数据集的准确性上。对于给定的准确度级别,通常存在多个达到该准确度级别的DNN架构。给定等效精度,具有较少参数的DNN架构具有以下几个优点:
- 更有效的分布式培训。服务器之间的通信是分布式DNN培训可扩展性的限制因素。 对于分布式数据并行训练,通信开销与模型中的参数数量成正比。 简而言之,由于需要较少的通信,小型模型训练更快。
- 将新模型导出到客户端时的开销较小。对于自动驾驶,特斯拉等公司会定期将新型号从其服务器复制到客户的汽车上。 使用AlexNet,这需要从服务器到汽车的240MB通信。 较小的模型需要较少的通信,使频繁的更新更加可行。
- 可行的FPGA和嵌入式部署。FPGA通常具有不到10MB1的片上存储器,并且没有片外存储器或存储器。 对于推理,一个足够小的模型可以直接存储在FPGA上,而视频帧可以实时流经FPGA。
- 如您所见,DNN架构较小有几个优点。 考虑到这一点,我们直接关注识别DNN架构的问题,该架构具有较少的参数,但与众所周知的模型相比具有相同的精度。 我们发现了这样一种架构,我们称之为SqueezeNet。
SqueezeNet:preserving accuracy with few parameters
- 在本节中,我们首先概述我们的DNN架构设计策略,参数很少。 然后,我们介绍Fire模块,我们的构建块用于构建DNN体系结构。 最后,我们使用我们的设计策略来构建SqueezeNet,它主要由Fire模块组成。
- 我们在本文中的首要目标是确定DNN架构,这些架构在保持竞争准确性的同时具有很少的参数。 为实现这一目标,我们在设计DNN架构时努力实现三个主要策略。
- 策略1.用1x1过滤器替换3x3过滤器。考虑到一定数量的卷积滤波器的预算,我们将选择使这些滤波器的大部分为1x1,因为1x1滤波器的参数比3x3滤波器少9倍。
- 策略2.将输入通道的数量减少到3x3过滤器。考虑一个完全由3x3滤波器组成的卷积层。 该层中参数的总量是(输入通道数)*(滤波器数)*(3 * 3)。因此,为了在DNN中保持少量参数,重要的是不仅要减少3x3滤波器的数量(参见上面的策略1),还要减少3x3滤波器的输入通道数量。我们使用挤压模块将输入通道的数量减少到3x3滤波器,我们将在下一节中介绍。
- 策略3.在网络后期进行下采样,以便卷积层具有大的激活映射。在卷积网络中,每个卷积层产生一个输出激活图,其空间分辨率至少为1x1,通常远大于1x1。这些激活图的高度和宽度由以下内容控制:(1)输入数据的大小(例如256×256图像)和(2)在DNN体系结构中下采样的层的选择。最常见的是,通过在某些卷积或池化层中设置(stride> 1),将下采样设计到DNN体系结构中。如果网络中的早期图层具有较大的步幅,则大多数图层将具有较小的激活图。相反,如果网络中的大多数层具有1的步幅,并且大于1的步幅集中在网络的末端,则网络中的许多层将具有大的激活图。我们的直觉是,由于延迟下采样导致的大型激活图可以导致更高的分类精度,而其他所有都保持相同。实际上,K.He和H.Sun将延迟下采样应用于四种不同的DNN架构,并且在每种情况下延迟下采样都导致更高的分类精度。
- 策略1和2是在努力保持准确性的同时明智地减少DNN中的参数数量。 策略3是关于在有限的参数预算上最大化准确性。 接下来,我们将介绍Fire模块,它是我们构建策略1,2和3的DNN架构的构建块。

- 我们定义Fire模块。 Fire模块包括:由1x1滤波器组成的挤压卷积模块,送入扩展模块,该模块由1x1和3x3卷积滤波器组成; 我们在图1中说明了这一点。

- 我们在Fire模块中公开了三个可调维度(超参数):
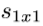 ,
,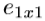 ,
, 。在Fire模块中,
。在Fire模块中,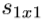 是挤压模块中的过滤器数量(全部为1x1),
是挤压模块中的过滤器数量(全部为1x1),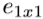 是扩展模块中1x1过滤器的数量,
是扩展模块中1x1过滤器的数量, 是扩展模块中3x3过滤器的数量。 当我们使用Fire模块时,我们将
是扩展模块中3x3过滤器的数量。 当我们使用Fire模块时,我们将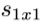 设置为小于
设置为小于 ,因此挤压模块有助于限制3x3滤波器的输入通道数量,从而实现了2.1节中的策略2。
,因此挤压模块有助于限制3x3滤波器的输入通道数量,从而实现了2.1节中的策略2。 - 我们现在描述SqueezeNet DNN架构。 我们在图2中说明了SqueezeNet从一个独立的卷积层(conv1)开始,接着是8个Fire模块(fire2-9),以最终的conv层(conv10)结束。我们逐渐增加从网络的开始到结束的每个模块的过滤器数量。 在conv 1,fire4,fire8和conv 10之后,SqueezeNet执行max-pooling,步幅为2; 这些相对较晚的汇集安排使我们能够从第2.1节实现战略3。
- 因此,1x1和3x3滤波器的输出激活具有相同的高度和宽度,我们在输入数据中添加1像素的零填充边框,以扩展模块的3x3滤波器。
- ReLU适用于挤压和扩展模块的激活。
- 在fire9层之后应用具有50%比率的DropOut。
- 注意SqueezeNet中缺少完全连接的层; 这种设计选择的灵感来自NiN架构。
- 在训练SqueezeNet时,我们使用多项式学习率,就像我们在Fire Caffe论文中描述的那样。
- Caffe框架本身不支持包含多个滤波器分辨率的卷积层(例如1x1和3x3)。 为了解决这个问题,我们使用两个独立的卷积层实现扩展模块:一个带有1x1过滤器的层和一个带有3x3过滤器的层。 然后,我们在通道维度中将这些层的输出连接在一起。 这在数值上等同于实现包含1x1和3x3滤波器的一个层。

Related Work
- 我们工作的首要目标是确定一个参数非常少但同时保持准确性的模型。为了解决这个问题,一个明智的方法是采用现有的DNN模型并以有损的方式压缩它。事实上,围绕模型压缩的主题出现了一个研究社区,并且已经报道了几种方法。Denton等人的一种相当简单的方法。 是将奇异值分解(SVD)应用于预训练的DNN模型[4]。Han等人开发网络修剪,以预训练模型开始,然后用零替换低于某个阈值的参数,形成解析矩阵,最后在稀疏DNN上执行一些训练迭代[9]。 最近,Han等人。 通过将网络修剪与量化(至8位或更少)和霍夫曼编码相结合来扩展其工作,以创建一种称为深度压缩的方法[8]。
Conclusions and Future Work
- 我们介绍了SqueezeNet,这是一种DNN架构,其参数比AlexNet少50倍,并在ImageNet上保持AlexNet级精度。 在本文中,我们将ImageNet作为目标数据集。然而,将ImageNet训练的DNN表示应用于各种应用已经成为惯例,例如细粒度物体识别,图像中的标识识别,以及生成关于图像的句子。ImageNet训练的DNN也已应用于许多与自动驾驶相关的应用,包括图像和视频中的行人和车辆检测,以及分割道路的形状。 我们认为SqueezeNet将成为适用于各种应用的良好候选DNN架构,尤其是那些小型号非常重要的应用。
- SqueezeNet是我们在广泛探索DNN架构设计空间时发现的几个新DNN之一。 我们希望SqueezeNet能够激发读者思考和探索DNN架构设计领域的广泛可能性。















 5941
5941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









