








文章目录
原文链接
源代码
Abstract
最近对深度卷积神经网络(cnn)的研究主要集中在提高准确性上。对于给定的精度水平,通常可以识别达到该精度水平的多个CNN架构。在同等精度的情况下,较小的CNN架构提供了至少三个优势:(1)较小的CNN在分布式训练期间需要更少的服务器间通信。(2)较小的cnn从云端导出新模型到自动驾驶汽车所需的带宽更少。(3)较小的cnn更适合部署在FP-GAs和其他内存有限的硬件上。为了提供所有这些优势,我们提出了一个名为SqueezeNet的小型CNN架构。SqueezeNet在ImageNet上实现alexnet级别的精度,参数减少了50倍。此外,通过模型压缩技术,我们能够将SqueezeNet压缩到小于0.5MB(比AlexNet小510倍)
介绍和动机
最近对深度卷积神经网络(cnn)的研究主要集中在提高计算机视觉数据集的准确性上。对于给定的精度水平,通常存在多个达到该精度水平的CNN架构。给定相同的精度,具有较少参数的CNN架构具有以下优点:
• 更高效的分布式训练 简而言之,小模型训练更快,因为需要更少的交流
• 在向客户导出新模型时减少开销 较小的模型需要较少的通信,使频繁更新更可行
• 可行的FPGA和嵌入式部署。fpga的片内存储器通常小于10MB1,没有片外存储器或存储器。对于推理,足够小的模型可以直接存储在FPGA上,而不会受到内存带宽的瓶颈(Qiu et al., 2016),而视频帧则实时通过FPGA。此外,当在专用集成电路(ASIC)上部署CNN时,足够小的模型可以直接存储在芯片上,而更小的模型可以使ASIC适合更小的芯片
正如你所看到的,较小的CNN架构有几个优点。考虑到这一点,我们直接关注与已知模型相比,具有更少参数但同等精度的CNN架构的识别问题。我们发现了这样一个架构,我们称之为SqueezeNet。此外,我们提出了一种更有纪律的方法来搜索新颖的CNN架构的设计空间
Related Work
Model Compression
我们工作的首要目标是在保持准确性的同时确定一个具有很少参数的模型。为了解决这个问题,一个明智的方法是采用现有的CNN模型并以有损方式压缩它,简要介绍了前人的方法(关于模型压缩)
CNN Microarchitecture
介绍前人的work
CNN Macroarchitecture
CNN微体系结构指的是单独的层和模块,而我们将CNN宏观体系结构定义为多个模块的系统级组织,形成端到端的CNN体系结构
神经网络设计空间探索
神经网络(包括深度和卷积神经网络)有很大的设计空间,有许多微体系结构、宏观体系结构、求解器和其他超参数的选择。很自然,社区想要获得关于这些因素如何影响神经网络准确性的直觉(即设计空间的形状)。神经网络的设计空间探索(DSE)的大部分工作都集中在开发自动化方法来寻找提供更高精度的神经网络架构。这些自动化的DSE方法包括贝叶斯优化(Snoek et al., 2012)、模拟退火(Ludermir et al., 2006)、随机搜索(Bergstra & Bengio, 2012)和遗传算法(Stanley & Miikkulainen, 2002)。值得赞扬的是,这些论文中的每一篇都提供了一个案例,其中提议的DSE方法产生了一个与代表性基线相比具有更高精度的NN架构。然而,这些论文并没有试图提供关于神经网络设计空间形状的直觉。在本文的后面,我们避开了自动化的方法——相反,我们重构CNN,这样我们就可以进行有原则的a /B比较,以研究CNN架构决策如何影响模型的大小和准确性
Squeezenet:用很少的参数保持精度
结构设计策略
我们在本文中的总体目标是识别具有很少参数的CNN架构,同时保持竞争的准确性。为了实现这一目标,我们在设计CNN架构时采用了三种主要策略:
策略1:用1x1过滤器替换3x3过滤器。给定一定数量的卷积滤波器的预算,我们将选择使这些滤波器中的大多数为1x1,因为1x1滤波器的参数比3x3滤波器少9X
策略2:将3x3滤波器输入通道的数量减少。考虑一个完全由3x3个过滤器组成的卷积层。该层参数总数为(输入通道数)(滤波器数)(3*3)。因此,为了在CNN中保持较小的参数总数,重要的是不仅要减少3x3滤波器的数量(参见上面的策略1),还要减少3x3滤波器的输入通道数量。我们使用挤压层将3x3过滤器输入通道的数量减少,我们将在下一节中描述
策略3:在网络的后期进行下采样,这样卷积层就有了大的激活图。在卷积网络中,每个卷积层产生一个输出激活图,其空间分辨率至少为1x1,通常比1x1大得多。这些激活图的高度和宽度由:(1)输入数据的大小(例如256x256图像)和(2)在CNN架构中下采样的层的选择来控制。最常见的是,通过设置(stride > 1)在一些卷积或池化层(例如(Szegedy et al., 2014;Simonyan & Zisserman, 2014;Krizhevsky et al., 2012)。如果网络的早期层有较大的步进,那么大多数层将有较小的激活图。相反,如果网络中的大多数层的步长为1,并且大于1的步长集中在网络的末端,那么网络中的许多层将具有较大的激活图。我们的直觉是,在其他条件相同的情况下,大的激活图(由于延迟的下采样)可以导致更高的分类精度。事实上,K. He和H. Sun对四种不同的CNN架构应用了延迟下采样,在每种情况下延迟下采样都导致了更高的分类精度(He & Sun, 2015)。
策略1和策略2是关于明智地减少CNN中参数的数量,同时试图保持准确性。策略3是关于在有限的参数预算下最大化准确性
The Fire module
我们对Fire模块的定义如下。Fire模块包括:挤压卷积层(只有1x1滤波器),输入扩展层,其中有1x1和3x3卷积滤波器的混合;我们在图1中对此进行了说明。在Fire模块中自由使用1x1过滤器是3.1节中策略1的应用。我们在Fire模块中公开了三个可调维度(超参数):s1x1、e1x1和e3x3。在Fire模块中,s1x1为挤压层(均为1x1)中的过滤器数量,e1x1为扩展层中1x1过滤器的数量,e3x3为扩展层中3x3过滤器的数量。当我们使用Fire模块时,我们将s1x1设置为小于(e1x1 + e3x3),因此挤压层有助于限制3x3滤波器的输入通道数量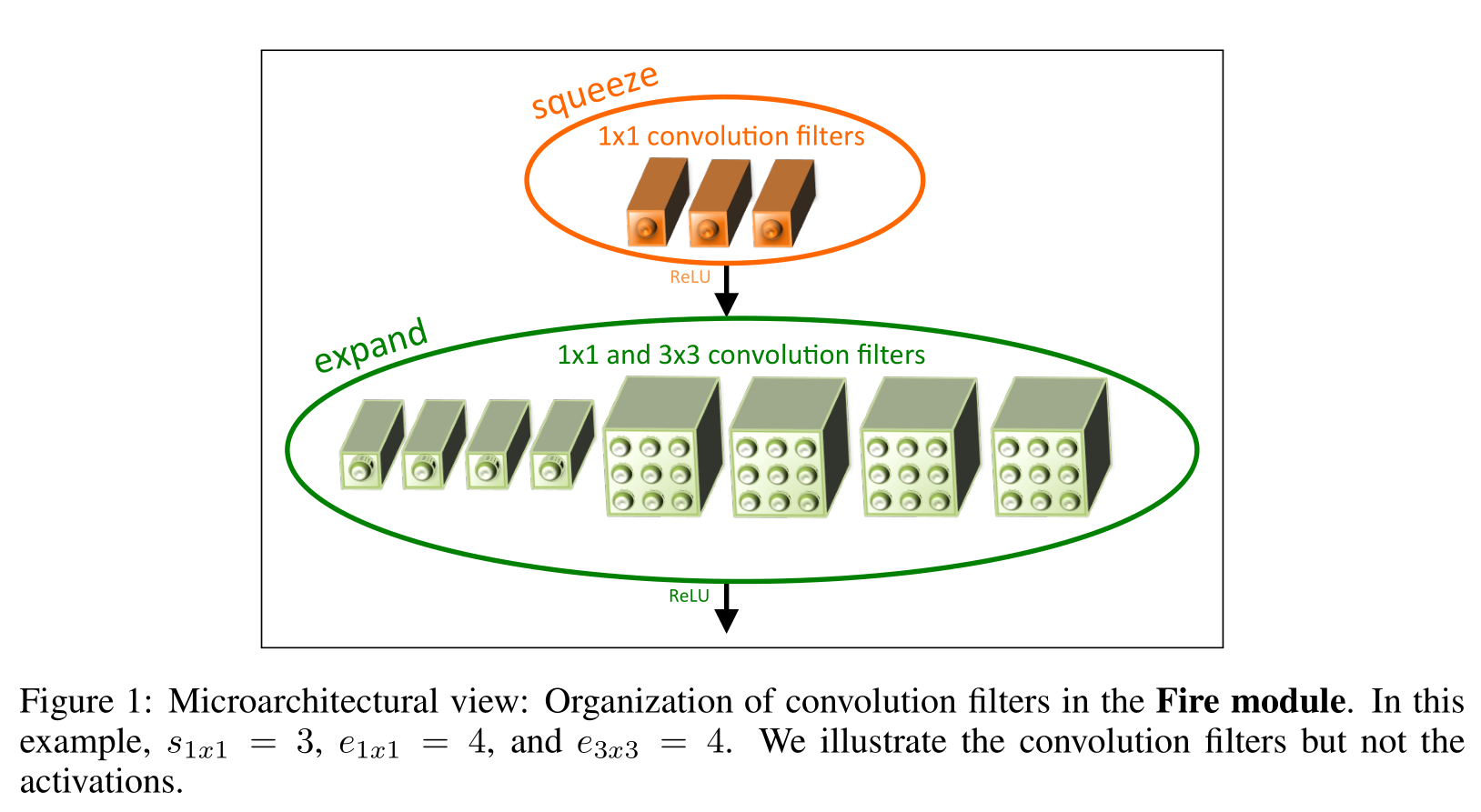
The SqueezeNet architecture
现在我们来描述一下SqueezeNet的CNN架构。我们在图2中说明了SqueezeNet从一个独立的卷积层(conv1)开始,然后是8个Fire模块(fire2-9),最后以一个卷积层(conv10)结束。从网络的开始到结束,我们逐渐增加每个fire模块的过滤器数量。在conv1、fire4、fire8和conv10层之后,SqueezeNet以2步长执行最大池化;这些相对较晚的池放置是根据3.1节中的策略3。我们在表1中展示了完整的SqueezeNet架构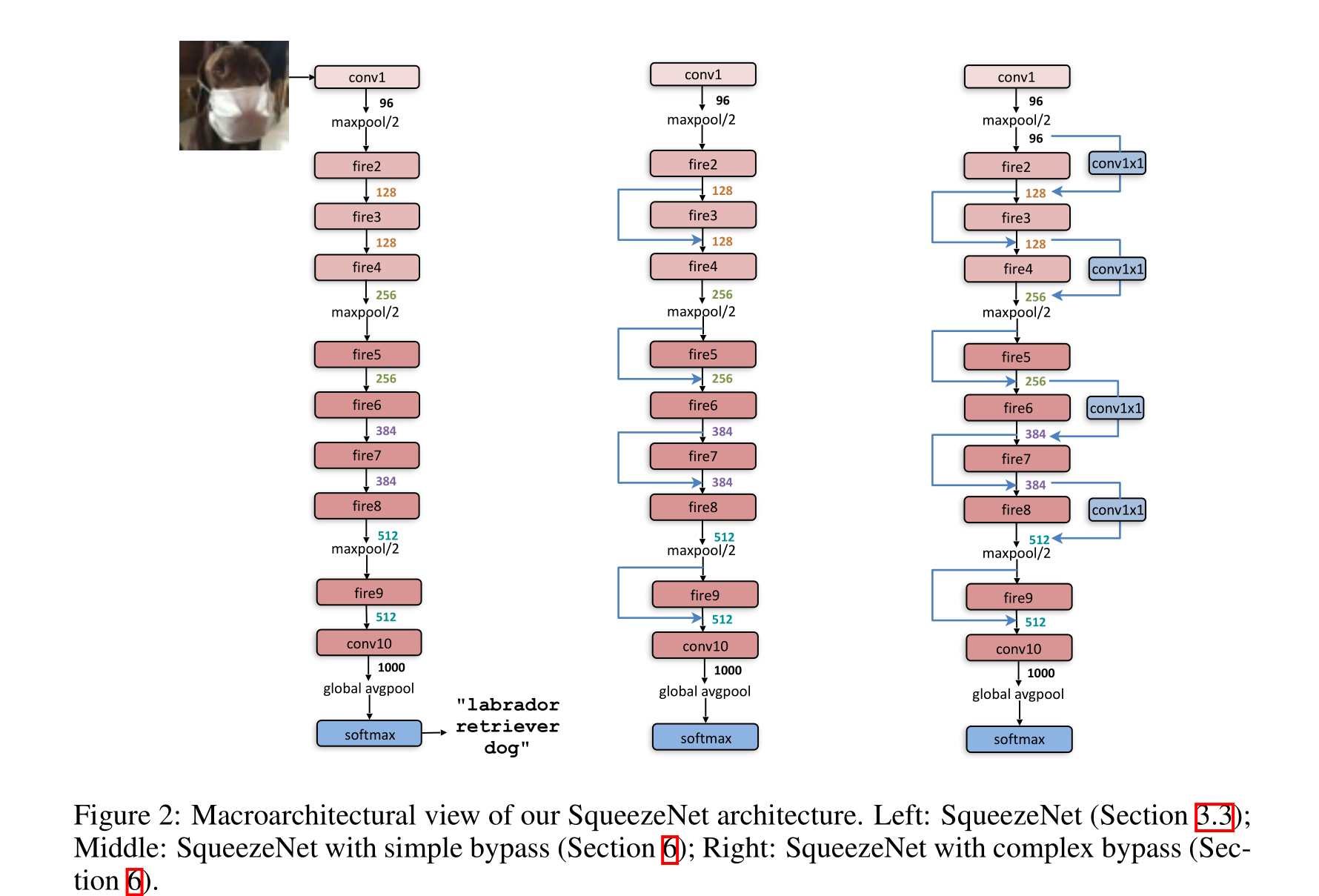

3.3.1其他挤压细节
为简洁起见,我们从表1和图2中省略了关于SqueezeNet的一些细节和设计选择。我们在下面提供这些设计选择。这些选择背后的直觉可以在下面引用的论文中找到
•为了使1x1和3x3过滤器的输出激活具有相同的高度和宽度,我们在扩展模块的3x3过滤器的输入数据中添加一个1像素的零填充边界。
•ReLU (Nair & Hinton, 2010)应用于挤压层和膨胀层的激活。•Dropout (Srivastava et al., 2014)在fire9模块之后应用50%的比例。
•注意《SqueezeNet》缺少完全连接的层;这种设计选择的灵感来自于NiN (Lin et al., 2013)架构。
•在训练SqueezeNet时,我们以0.04的学习率开始,并在整个训练过程中早期降低学习率,如(Mishkin et al.)所述
•Caffe框架本身不支持包含多个过滤器分辨率(例如1x1和3x3)的卷积层(Jia et al., 2014)。为了解决这个问题,我们用两个独立的卷积层来实现我们的扩展层:一个层有1x1过滤器,一个层有3x3过滤器。然后,我们将这些层的输出在通道维度中连接在一起。这在数值上等同于实现一个包含1x1和3x3滤波器的层
我们以Caffe CNN框架定义的格式发布了SqueezeNet配置文件,研究社区已经移植了SqueezeNet CNN架构,以便与许多其他CNN软件框架兼容:
• MXNet (Chen et al., 2015a) port of SqueezeNet: (Haria, 2016)
• Chainer (Tokui et al., 2015) port of SqueezeNet: (Bell, 2016)
• Keras (Chollet, 2016) port of SqueezeNet: (DT42, 2016)
• Torch (Collobert et al., 2011) port of SqueezeNet’s Fire Modules: (Waghmare, 2016)
Evaluation of SqueezeNet
在评估SqueezeNet时,我们使用AlexNet5和相关的模型压缩结果作为比较的基础
在表2中,我们在最近的模型压缩结果的背景下回顾了SqueezeNet。现在,使用SqueezeNet,与AlexNet相比,我们实现了模型尺寸减少50倍,同时达到或超过AlexNet的前1和前5精度。我们在表2中总结了上述所有结果。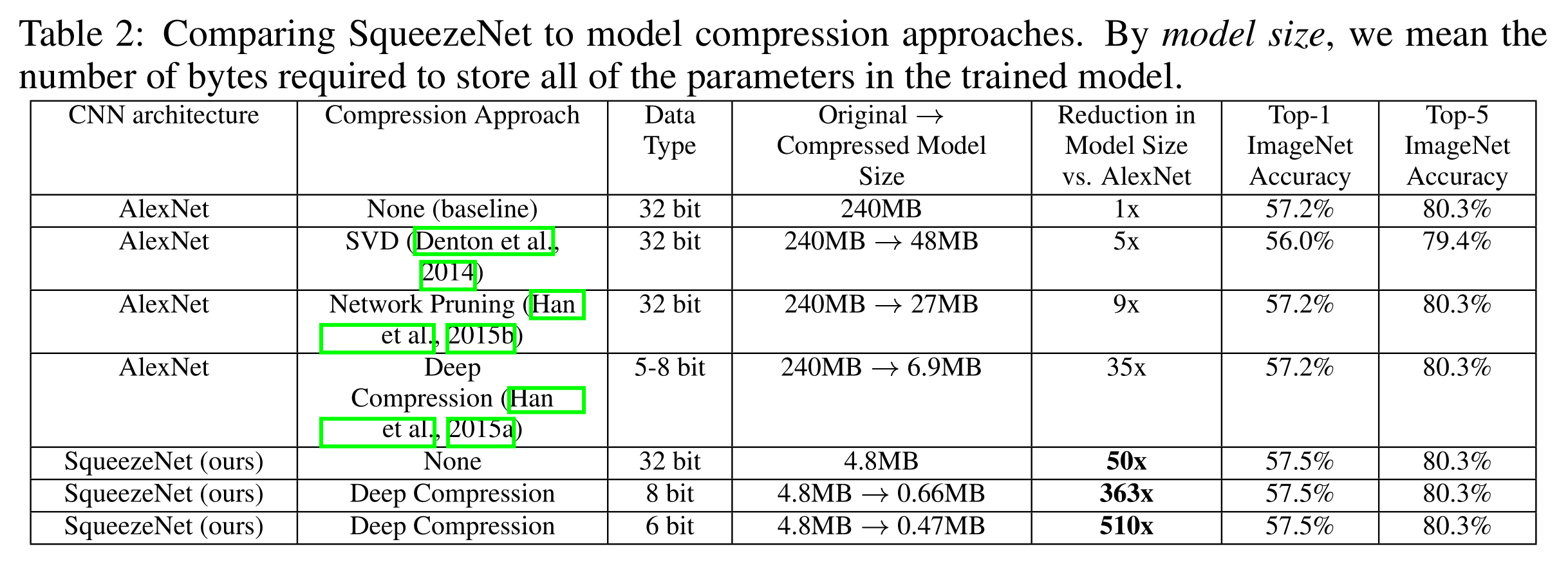
看起来我们已经超越了模型压缩社区的最先进的结果:即使使用未压缩的32位值来表示模型,SqueezeNet的模型尺寸也比模型压缩社区的最佳努力小1.4倍,同时保持或超过基线精度。到目前为止,一个悬而未决的问题是:小模型是否适合压缩,或者小模型是否“需要”密集浮点值所提供的所有表示能力?
为了找到答案,我们将深度压缩(Han等人,2015)应用于SqueezeNet,使用33%稀疏性6和8位量化。这产生了一个0.66 MB的模型(比32位AlexNet小363x),其精度与AlexNet相当。此外,在SqueezeNet上应用6位量化和33%稀疏度的深度压缩,我们产生了0.47MB的模型(比32位AlexNet小510倍),具有相同的精度。我们的小模型确实可以压缩
此外,这些结果表明,深度压缩(Han et al., 2015a)不仅在具有许多参数的CNN架构(例如AlexNet和VGG)上工作得很好,而且还能够压缩已经紧凑的、完全卷积的SqueezeNet架构。深度压缩将SqueezeNet压缩了10倍,同时保留了基线精度。总而言之:通过将CNN架构创新(SqueezeNet)与最先进的压缩技术(Deep compression)相结合,我们将模型尺寸缩小了510倍,而与基线相比,精度没有下降
CNN微架构设计空间探索
到目前为止,我们已经提出了小型模型的架构设计策略,并遵循这些原则创建了SqueezeNet,并发现SqueezeNet比AlexNet小50倍,具有相同的精度。然而,SqueezeNet和其他模型存在于一个广泛的、很大程度上未被探索的CNN架构设计空间中。我们将这种架构探索分为两个主要主题:微架构探索(每个模块层的维度和配置)和宏观架构探索(模块和其他层的高级端到端组织)
我们的目标不是在每个实验中最大化准确性,而是了解CNN架构选择对模型大小和准确性的影响
CNN微架构元参数
在SqueezeNet中,每个Fire模块都有我们在3.2节中定义的三维超参数:s1x1, e1x1和e3x3。SqueezeNet有8个fire模块,共有24个维度的超参数。为了对类似squeezenet的架构的设计空间进行广泛的扫描,我们定义了以下一组更高级别的元参数,它们控制CNN中所有Fire模块的尺寸。我们将basee定义为CNN中第一个Fire模块中的扩展滤波器的数量。在每个频率Fire模块之后,我们增加了扩展滤波器的数量。换句话说,对于Fire模块i,扩展过滤器的数量为ei = basee +(incre * [i/freq])在Fire模块的i扩展层中,有些滤波器是1x1的,有些是3x3的;我们定义ei = ei,1x1 + ei,3x3与pct3x3(在[0,1]范围内,在所有Fire模块上共享)作为扩展过滤器为3x3的百分比。换句话说,ei,3x3 = ei∗pct3x3,和ei,1x1 = ei∗(1 - pct3x3)。最后,我们使用称为挤压比(SR)的元参数定义Fire模块的挤压层中的过滤器数量(再次,在[0,1]范围内,由所有Fire模块共享):si,1x1 = SR∗ei(或等效si,1x1 = SR∗(ei,1x1 + ei,3x3))。SqueezeNet(表1)是我们用前面提到的一组元参数生成的一个示例体系结构。具体来说,《SqueezeNet》拥有以下元参数:basee =128, incre =128, pct3x3 =0.5, freq =2, SR =0.125。
挤压比
我们建议通过使用挤压层来减少3x3滤波器所看到的输入通道的数量,从而减少参数的数量。我们将压缩比(SR)定义为压缩层中滤波器的数量与扩展层中滤波器的数量之比。我们现在设计了一个实验来研究挤压比对模型尺寸和精度的影响。
权衡1x1和3x3过滤器
我们提出通过用1x1滤波器代替3x3滤波器来减少CNN中的参数数量。一个悬而未决的问题是,空间分辨率在CNN滤波器中有多重要?
我们在本实验中使用以下元参数:basee = incre =128, freq =2, SR = 0.500,我们将pct3x3从1%变化到99%。换句话说,每个Fire模块的扩展层在1x1和3x3之间划分了预定义的过滤器数量,在这里我们将这些过滤器的旋钮从“主要1x1”转到“主要3x3”。与前面的实验一样,这些模型有8个Fire模块,遵循图2中相同的层组织。我们将实验结果显示在图3(b)中。注意,图3(a)和图3(b)中的13MB模型是相同的架构:SR =0.500, pct3x3 =50%。我们在图3(b)中看到,使用50%的3x3滤波器时,前5个精度稳定在85.6%(?图中85.3),进一步增加3x3滤波器的百分比会导致更大的模型尺寸,但在ImageNet上没有提高精度
CNN宏观结构设计空间探索
我们在宏观体系结构级别探讨有关Fire模块之间的高级连接的设计决策。受ResNet的启发(He et al., 2015b),我们探索了三种不同的架构:
•Vanilla SqueezeNet(根据前面章节)。
•SqueezeNet与一些Fire模块之间的简单旁路连接。(灵感来自Sri- vastava et al., 2015;He et al., 2015b)。
•SqueezeNet在其余Fire模块之间具有复杂的旁路连接
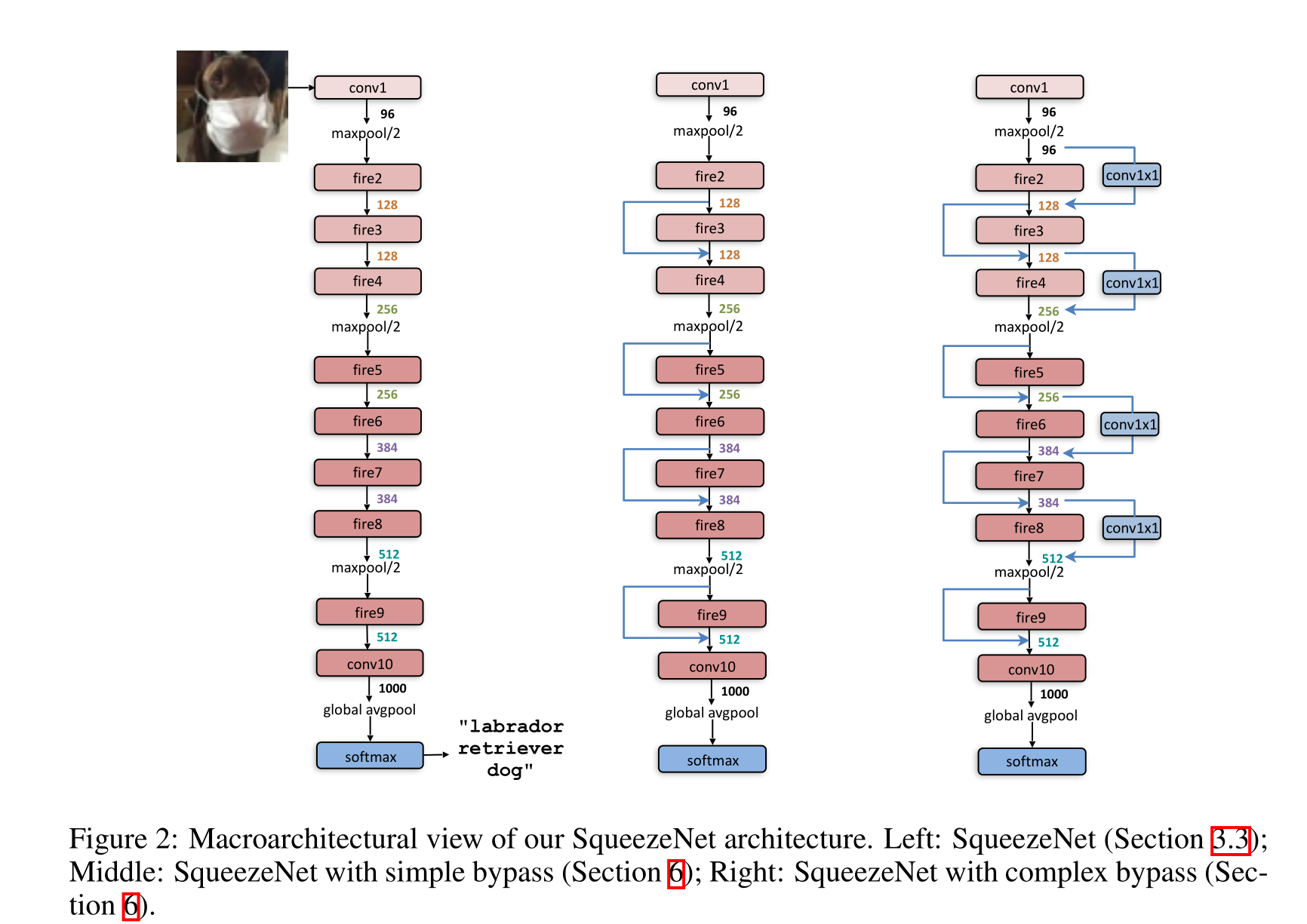
我们的简单旁路架构在Fire模块3、5、7和9周围添加了旁路连接,要求这些模块在输入和输出之间学习残差函数。和ResNet一样,为了在Fire3周围实现旁路连接,我们将Fire4的输入设置为(Fire2的输出+ Fire3的输出),其中+运算符是元素加法。这改变了应用于这些Fire模块参数的正则化,并且,根据ResNet,可以提高最终的准确性和/或训练完整模型的能力
一个限制是,在简单的情况下,输入通道的数量和输出通道的数量必须相同;因此,只有一半的Fire模块可以进行简单的旁路连接,如图2中图所示。当不能满足“相同数量的通道”要求时,我们使用复杂的旁路连接,如图2右侧所示。虽然简单的旁路“只是一根电线”,但我们将复杂的旁路定义为包含1x1卷积层的旁路,其滤波器数量设置等于所需的输出通道数量。注意,复杂的旁路连接会向模型中添加额外的参数,而简单的旁路连接则不会
除了改变正则化之外,我们很直观地认为,添加旁路连接将有助于缓解由挤压层引入的表示瓶颈。在SqueezeNet中,挤压比(SR)为0.125,这意味着每个挤压层的输出通道比伴随的扩展层少8倍。由于这种严重的降维,有限数量的信息可以通过挤压层。然而,通过在SqueezeNet上添加旁路连接,我们为信息在挤压层周围流动开辟了途径
我们用图2中的三个宏观架构训练了SqueezeNet,并在表3中比较了精度和模型大小。在整个宏架构探索过程中,我们固定了微架构以匹配表1中所描述的SqueezeNet。与普通的SqueezeNet架构相比,复杂和简单的旁路连接都提高了精度。有趣的是,**与复杂旁路相比,简单旁路能够提高精度。**在不增加模型尺寸的情况下,添加简单的旁路连接可使前1名的精度提高2.9个百分点,前5名的精度提高2.2个百分点
Conclusions
在这篇论文中,我们提出了一种更有纪律的方法来探索卷积神经网络的设计空间。为了实现这一目标,我们提出了SqueezeNet,这是一种CNN架构,其参数比AlexNet少50倍,并在ImageNet上保持AlexNet级别的精度。我们还将SqueezeNet压缩到小于0.5MB,比未压缩的AlexNet小510倍
我们在本文开头提到,小型模型更适合FGPAs的片上实现。自从我们发布了SqueezeNet模型以来,Gschwend已经开发了SqueezeNet的变体,并在FPGA上实现了它(Gschwend, 2016)。正如我们预期的那样,Gschwend能够将类似squeezenet模型的参数完全存储在FPGA中,并且消除了对片外存储器访问加载模型参数的需要
在本文的上下文中,我们主要关注ImageNet作为目标数据集。我们认为SqueezeNet将是一个很好的候选CNN架构,适用于各种应用,特别是那些小模型尺寸很重要的应用。















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









