






在人工智能领域,大语言模型(LLM)的应用日益广泛,但通用大模型在特定任务上的表现往往差强人意。为了让大模型更好地满足业务需求,模型微调成为关键技术。本文将深入讲解基于低秩适配(LoRA)技术的大模型高效微调方法,带你从零开始完成一次高质量的模型微调实践。
一、为什么选择 LoRA 进行模型微调?
传统的全量参数微调需要消耗大量的计算资源和时间,对硬件设备要求极高。而 LoRA(Low-Rank Adaptation,低秩适配)技术通过在预训练模型上添加少量可训练参数,冻结大部分原始参数,在显著降低计算成本的同时,实现与全量微调相近的性能。其核心原理是将大矩阵的权重更新分解为两个低秩矩阵的乘积,大幅减少了需要训练的参数数量。这种方法不仅能在消费级 GPU 上完成微调任务,还能有效避免过拟合,让模型在特定领域数据上快速 “适应”。
二、LoRA 微调前的准备工作
1. 环境搭建
确保你的开发环境中安装了 Python 3.8 及以上版本,并配置好 CUDA(如果使用 NVIDIA GPU 加速)。推荐使用 Anaconda 或 Miniconda 进行虚拟环境管理,通过以下命令创建并激活新环境:
 安装所需的 Python 库,包括transformers、peft(用于 LoRA 实现)、datasets等:
安装所需的 Python 库,包括transformers、peft(用于 LoRA 实现)、datasets等:

2. 数据集准备
选择与微调任务相关的高质量数据集。例如,如果你想微调一个问答模型,就需要收集问答对数据。数据格式建议采用 JSONL,每行是一个 JSON 对象,包含输入文本和对应的输出文本,示例如下:
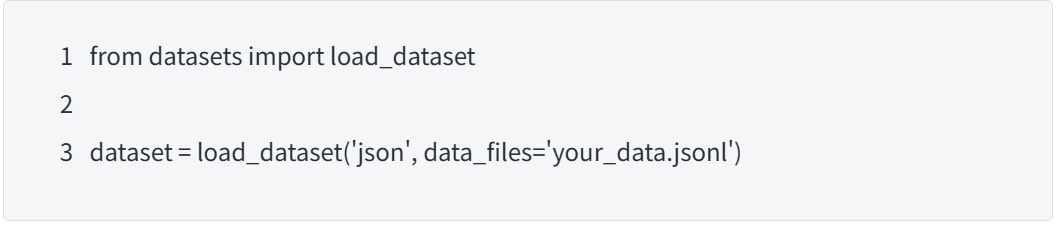
 使用datasets库加载数据集:
使用datasets库加载数据集:
3. 选择预训练模型
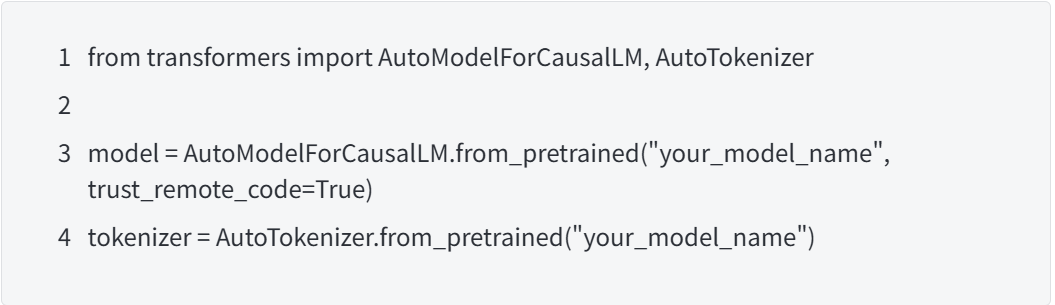
根据任务需求和硬件条件选择合适的预训练模型。例如,对于中文任务,可以选择THUDM/chatglm-6b、baichuan-inc/Baichuan2-7B-Base等模型;英文任务可考虑gpt2、llama系列模型。通过transformers库加载模型和分词器:
三、LoRA 微调实战
1. 配置 LoRA 参数
使用peft库配置 LoRA 相关参数,包括低秩矩阵的秩(r)、缩放因子(lora_alpha)和训练参数的权重衰减等:

2. 准备训练数据
对数据集进行预处理,将输入和输出文本转换为模型可接受的格式,并添加适当的标签:

3. 训练模型
使用transformers库的Trainer类进行训练,同时传入 LoRA 配置:

4. 合并 LoRA 权重与推理
训练完成后,将 LoRA 权重合并到原始模型中,方便后续部署和推理:
 推理示例:
推理示例:

四、常见问题与解决方案
- 显存不足:降低批次大小(per_device_train_batch_size),启用混合精度训练(bf16=True或fp16=True),或使用梯度累积技术。
- 模型效果不佳:检查数据集质量,调整 LoRA 参数(如r、lora_alpha),增加训练轮数或优化学习率。
- 训练过程中报错:仔细查看错误日志,确认模型、分词器和数据集的兼容性,更新相关库到最新版本。
通过以上步骤,你已经掌握了使用 LoRA 技术进行大模型高效微调的核心方法。在实际应用中,可以根据不同的业务场景(如智能客服、文档摘要、代码生成等)灵活调整数据和参数,让大模型更好地服务于你的需求。如果你在实践过程中有任何问题或新的想法,欢迎在评论区交流讨论!

















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









