







文章目录
Deep learning for depression recognition with audiovisual cues: A review
深度学习用于视听线索的抑郁症识别:综述
摘要
随着工作和生活节奏的加快,人们面临的压力越来越大,这就增加了患抑郁症的概率。然而,由于全球医患比例严重失衡,很多患者可能无法得到及时诊断。一个很有希望的进展是生理和心理学研究发现抑郁症患者和健康人在言语和面部表情上有一些差异。因此,为了改善当前的医疗保健,深度学习(DL)已被用于从音频和视频中提取抑郁线索的表示,以用于自动抑郁检测。为了对这些研究进行分类和总结,我们介绍了抑郁症自动评估的数据库和客观指标。我们还回顾了用于抑郁症自动检测的DL方法,以从音频和视频中提取抑郁症的表示。 最后,我们讨论了与使用DL自动诊断抑郁症相关的挑战和有前景的方向。
介绍
抑郁症是一种精神疾病,它给个人、家庭和社会带来了严重的负担。根据世界卫生组织(WHO)的数据,到2030年,抑郁症将成为最常见的精神疾病[1]。在严重的情况下,抑郁症会导致自杀[2,3]。一份由[3,4]发布的报告指出,大约50%的自杀与抑郁症有关。目前,抑郁症还没有独特有效的临床表征,这使得抑郁症的诊断既费时又主观[5]。由于金标准的评估或工具主要依赖于临床医生的主观经验,因此,要有一个统一的标准来诊断抑郁症的严重程度是一个挑战。其严重程度的主要诊断工具,例如,HAMD [6],依靠临床医生或个人自己进行的访谈,得出一个总结了患者的行为。抑郁症的诊断是复杂的,不仅取决于受试者的教育背景、认知能力和描述症状的诚实程度,还取决于临床医生的经验和动机。需要全面的信息和全面的临床培训才能准确诊断抑郁症的严重程度[7]。一些生物标志物,例如低血清素水平[8,9],神经递质功能障碍[10,11]和遗传异常[12,13],已被认为是抑郁症的指标。然而,尚不清楚哪种生物标志物是最有效的指标。因此,近年来,已经引入了许多自动抑郁估计(ADE)系统,以基于利用机器学习、语音识别和计算机视觉领域中开发的技术提取的视听线索来自动估计抑郁的严重程度[14-17]。ADE系统的目标是帮助临床医生从视听信息中有效地诊断抑郁症的严重程度。
设计代表性特征及其提取来估计抑郁症的严重程度是ADE深度学习架构的重要一步。ADE功能可以是手工制作的,也可以基于深度学习模型。广泛使用的手工制作特征的示例包括局部二进制模式(LBP)[18]、来自三个正交平面的局部相位量化(LPQ-TOP)[19]、来自三个正交平面的局部二进制模式(LBP-TOP)[20]以及其他(例如,面部动作单位(FAU)、标志、头部姿势、凝视)[21]。自2013年以来,抑郁症识别挑战赛,如视听情绪识别挑战赛(AVEC 2013)[22]和AVEC 2014 [23],通过人机交互记录抑郁症数据。手工制作的功能被认为可以为ADE带来良好的性能。然而,它们受到以下限制。首先,提取手工制作的特征需要大量的努力(例如,领域知识、时间和劳动力等)。 例如,LBP-TOP被广泛用于情感识别ADE。然而,如果我们开发类似于LBP-TOP的手工制作功能,我们必须拥有抑郁症的特定任务知识,而获得这些知识是耗费劳动力的。其次,一些隐含在视听信号中的判别模式不能很好地提取。最后,开发特征的动机来自研究者的主观假设。不同的研究者从不同的角度设计特征。
幸运的是,深度学习的快速发展推动了深度学习(DL)方法用于抑郁症识别的研究,并且不会受到上述挑战的影响,与手工制作的特征相比,它已经获得了有前途的性能。对于通过深度学习学习的特征,广泛的研究采用深度卷积神经网络(DCNN)来基于视听线索提取ADE的多尺度特征表示[24-35]。图1显示了ADE根据方法和数据库的演变。
近年来,基于音频[36]和视觉线索[37],已经发表了一些关于抑郁症识别和分析的详尽综述。这些调查为ADE提供了一个全面的范围。此外,基于2010年至2017年的研究,发表了DL情感识别的综述[38]。然而,还有两个方面尚未探索。由于现有的综述仅关注听觉或视觉线索来评估抑郁症的严重程度,因此视听线索的联合使用尚未得到充分讨论。此外,现有调查仅考虑传统方法,并且DL技术尚未纳入其分析。近年来,数字化语音识别技术加速了基于视听线索的抑郁症识别技术的发展和创新。目前,对多模态视听方法在抑郁症识别中的应用尚缺乏深入的研究。 我们的目标是填补现有广泛综述中的差距,包括越来越重要的基于视听线索的深度多模态ADE方法。
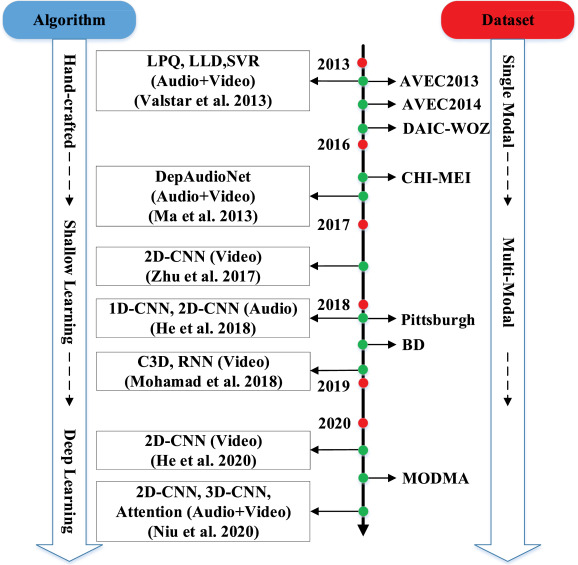
图一. ADE方法和数据库的演变。从2013年到2021年,基于特征提取的算法经历了从手工到浅层再到深度学习的三个不同阶段。与此同时,数据库从单一模式(例如,单独的音频或视频)到多模态(包含多种类型的数据)。
本文贡献
总之,我们对情感计算领域的贡献是:
(1)我们根据视听线索中ADE的DL提出了一项与抑郁症相关的全面调查。
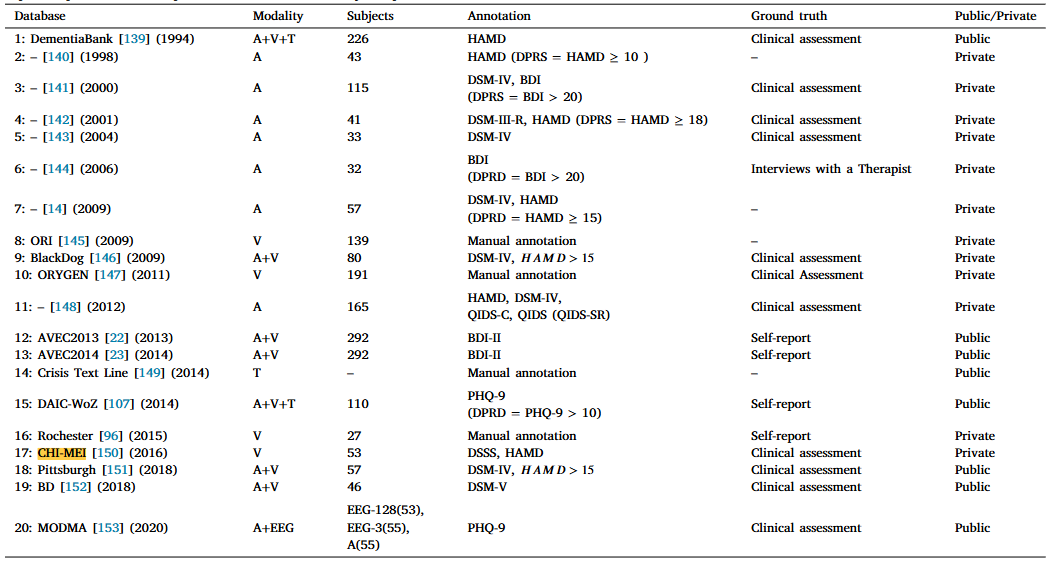
(2)我们详细回顾了1994年至2021年最重要的20个数据库。
(3)本文首先回顾了114篇基于视听线索的ADE研究,选取了78篇采用DL方法进行ADE的研究,并将其分为:(1)基于听觉模态的深度ADE网络;(2)基于视频模态的深度ADE网络(空间特征提取、时间特征提取);(3)基于视听线索的深度ADE网络。
(4)我们指出了悬而未决的问题和有前景的方向。
本文结构
我们全面回顾了基于深度神经网络的抑郁症自动检测方法,讨论了它们面临的挑战,并指出了未来的研究方向。在下文中,第2节提供了抑郁症的定义,并描述了抑郁症评估的客观标志物。第3节介绍了几个多模态抑郁症数据库。第4节详细回顾了深度ADE的一般方法,并介绍了几种基于视听线索的新型神经网络结构。其他问题在第5节中描述。第6节提供了基于我们的论述的结论。此外,为了清楚起见,本文的结构在图2中以图形方式示出。
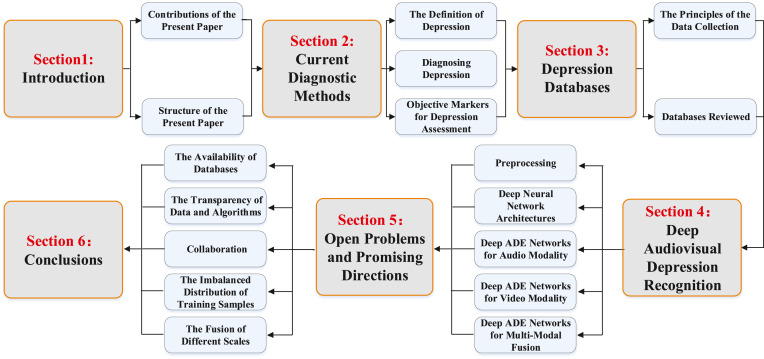
图二.本文的结构。
目前的诊断方法
为了更好地理解基于视听线索的抑郁症识别过程,接下来回顾抑郁症的定义,然后调查抑郁症的自动诊断方法。
抑郁的定义
1980年,罗素提出情绪状态可以表示为二维空间中的连续数值向量,称为Valence-Arousal(VA)空间,见图3。效价维度指的是两种类型的情绪状态,即,积极的和消极的。唤醒维度代表了情绪的强度,从困倦(或无聊)到高度兴奋。如图3所示,抑郁症位于VA空间的第三象限[39],对应于低觉醒和负效价。
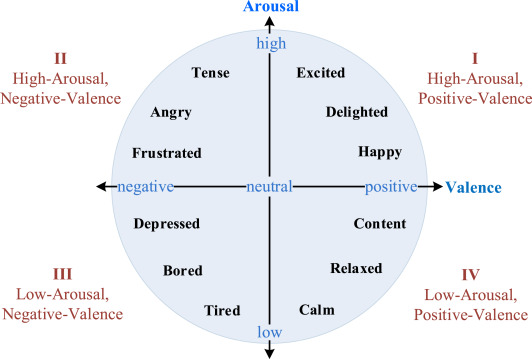
图三.二维情感空间,可以分为四个象限[40]。每一个象限都与各种情绪相关联。例如,高唤醒和积极情绪状态包括兴奋,高兴,快乐等。抑郁症可以放在VA的第三象限。
根据美国精神病学协会(阿帕)的精神疾病诊断和统计手册(DSM)[41]的定义,抑郁症可以进一步分为以下几类:重度抑郁症(MDD)、持续性抑郁症(心境恶劣)、破坏性情绪调节障碍(DMDD)、经前期焦虑障碍(PDD)、物质/药物诱导的抑郁症(S/M-IDD)、其他疾病导致的抑郁症(DDDAMC)、其他特定抑郁症(OSDD)或未特定抑郁症(UDD)。DSM提供了根据观察到的症状对精神障碍进行分类的一般标准。当一个人至少出现以下两种症状之一时,(1)一天中大部分时间情绪低落和/或(2)兴趣或快乐明显减少,同时伴有表1中至少四种或更多种症状并持续至少两周。 此外,预期上述症状也会导致临床上显著的社会、职业或其他重要功能领域的痛苦或损害。尽管如此,在一定程度上,这些不同类型的抑郁症相关疾病以相似的方式表现出来。
如何诊断抑郁症的问题已经引起了来自不同领域的许多研究者的关注。但对抑郁症发病机制的认识至今尚未统一和达成一致。然而,其发病机制通常被认为与皮质边缘系统功能障碍有关,降低了其活性和连接性[42-45]。人们认为抑郁症取决于遗传易感性和环境因素之间的相互作用[46,47]。在[48]中,人们发现猴子失去了母亲可能由于遗传易感性的影响而患有抑郁症。在[49]中,Remi等人发现,对于男性来说,由于环境因素的影响,在收养家庭中饮酒过多会增加患抑郁症的风险。 对于女性来说,养父母在被收养者年满19岁之前死亡,或者收养家庭中存在行为障碍的个人,会增加抑郁症的风险。
DSM经常受到批评,因为精神疾病之间的界限并不总是正确定义的。这导致根据[58,59]的报告,在美国,MDD导致的增量经济损失从2005年到2010年增长了21.5%,而经济损失估计为GDP的1%。
表1.与抑郁症相关的症状
| 情绪低落和/或兴趣或快乐明显减少 |
|---|
| 结合以下四项: |
| 1.不节食时体重显著减轻或体重增加(例如,一个月内体重变化超过5%),几乎每天食欲下降或增加(在儿童中,未能实现预期的体重增加); |
| 2.几乎每天都有失眠或嗜睡(无法入睡或过度睡眠); |
| 3.几乎每天都有精神上的激动或迟钝(可被他人观察到,而不仅仅是不安或被放慢的主观感觉); |
| 4.几乎每天都有无意识或过度或不适当的内疚感(可能是妄想)(不仅仅是自责或对生病的内疚); |
| 5.几乎每天思考或集中注意力的能力下降,或犹豫不决(主观认为或他人观察到); |
| 6.几乎每天都感到疲劳或能量损失; |
| 7.反复出现死亡的想法(不仅仅是害怕死亡),或者没有具体计划的反复自杀想法,自杀企图或自杀的具体计划。 |
诊断抑郁症
在初级保健环境中很难评估抑郁症的严重程度。抑郁症的诊断通常由于错误识别的机会、其耗时的性质以及并非所有抑郁症受试者都直接表现出抑郁症表现(例如,无助或绝望等)[60,61]。此外,生物因素、家庭/环境压力源和个人脆弱性的组合在影响MDD的发作方面起着至关重要的作用[62]。
目前,最常用的评估方法是访谈,例如,HAMD [6]或自我评估,例如,BDI(1961年第一版,1996年最新版)[63]。根据评估方法(HAMD和BDI)对每位患者进行评分,通过对21种抑郁相关症状进行评级来表征其严重程度。HAMD和BDI的主要区别在于HAMD需要20-30分钟的访谈,由临床医生填写评定问卷,而BDI需要5-10分钟完成自我报告问卷。此外,这两个评定量表考虑不同的测量:HAMD集中于神经植物性症状(例如,精神发育迟滞、体重、睡眠和疲劳等),而BDI侧重于对消极自我评价症状的自我评估。已证明HAMD和BDI在区分抑郁症患者和非抑郁症患者时具有一致性[64,65]。HAMD工具被认为是诊断抑郁症严重程度的金标准。然而,相关研究也暴露出一些问题[65-67]。最重要的是,一些典型的症状(即,失眠、情绪低落、激动、焦虑和体重减轻)被HAMD忽略。 对于HAMD问卷中的每一个问题,心理学家或临床医生应提供3-5个可能的答案来评定抑郁症的严重程度。在0-2、0-3和0-4的范围之一中的分数被分配以指示抑郁症的每种症状的严重程度。评分总和可分为5组:(正常:范围为0 - 7)、(轻度:范围为8 - 13)、(中度:范围为14 - 18)、(重度:范围为19 - 22)和(极重度:≥23)。虽然HAMD已经涵盖了许多抑郁症的症状,[68,69]评论说,只有一部分列出的症状是有用的估计抑郁症的严重程度。认为简单的“症状检查表”方法不足以评估ADE。
如上所述,从临床角度对抑郁症的定义也可能取决于自我报告量表和清单(SRSIs)提供的评分。常见的评估工具有BDI/BDI-II、PHQ-2/8/9(患者健康问卷,这里2、8或9是问题的数量)和抑郁和躯体症状量表(DSSS)。为了进一步理解SRSI,下面介绍BDI。BDI是一种SRSI,通常用作抑郁症的评估工具[70]。它由21个问题组成,包括认知、情感和躯体症状,以及几种负面表现(例如,自我评价和自我批评)。BDI/BDI-II的每一个项目都由多项选择定义,并由一个数值(范围:0-3)加权。BDI评分的范围为0 - 63((无或轻微抑郁:范围为0 - 13),(轻度:范围为14 - 19),(中度:范围为20 - 28),(重度:范围为29 - 63))。 最初,BDI不是专门设计的,对于初级保健使用,但其实际性能[71]表明它也适用于初级保健会议。
尽管SRSI已广泛用于各种研究,特异性和灵敏度高达80%至90%,但它们仍然存在某些问题[72]。具体而言,SRSI不考虑观察到的症状的临床意义,并且与临床访谈相比,在报告不同性状或特征时允许个体差异[73]。此外,SRSI不能很好地区分抑郁症的不同亚型[64]。此外,SRSI易受有意或无意报告偏倚的影响[74]。总体而言,尽管在提供有效的抑郁症诊断方面存在困难[75-77],但SRSI已以各种方式被广泛采用,例如在初级卫生保健和研究中。SRSIs用于广泛筛查以促进抑郁症评估的成本效益已得到强调[78]。
表2列出了一些用于评定抑郁症的量表,例如,HAMD、BDI、PHQ-9、抑郁症状量表(IDS)、16项抑郁症状快速量表(QIDS)、Zung抑郁自评量表(Zung-SDS)和10项Montgomery-A-Sberg抑郁量表(MADRS)等。但是,究竟哪一种更有效,目前还没有统一的结论。在[84]中发现,BDI-II和PHQ-9具有足够的可靠性、收敛/判别效度和相似的变化反应性。他们认为PHQ-9将成为未来抑郁症的诊断标准,因为与BDI-II相比,它的问题更短。当选择适当的抑郁筛查工具时,这些发现支持在寻求减肥手术的患者中使用PHQ 9作为BDI-II的可行替代方案[85]。
表2.常用抑郁评分量表

许多抑郁症评定量表可用于抑郁症评估,它们可以用于不同的场景。从宏观分析的角度来看,HAMD对抑郁症的诊断上级DSM-IV,但DSM-IV抑郁症状可以为治疗方案的选择提供有意义的信息。从微量分析的角度来看,HAMD也常用于选择性5-羟色胺再摄取抑制剂[86]。
抑郁症评估的客观指标
通常认为抑郁症的表现会受到各个方面的影响[87,88]。可观察的行为信号在精神病学领域是不被接受的。然而,在这些领域的一些研究仍然获得了流行至今。客观标记在心理学中已被广泛采用;它们可用作相关领域的客观诊断工具(即,初级临床机构、心理机构)。他们提供了一个强大的评估工具,帮助临床医生有效地诊断严重程度,并为易感个体提供后期反馈和宝贵的建议。随着可穿戴设备的发展,已经设计了一种交互式虚拟工具,用于部署在智能手机平台上,以帮助诊断抑郁症受试者或疑似人群[17]。 因此,迫切需要设计新的评估工具,例如开发诊断工具来研究新的标志物。 以往的研究对客观的生理,生物和行为标记物提高了精神病诊断的效率,并有潜力降低抑郁症造成的社会经济成本[57,89]。
在被公认为现代精神病学之父的Emil Kraepelin的早期工作中,他将抑郁的声音定义为“患者低声说话,缓慢,犹豫,单调,有时口吃,耳语,在他们说出一个词之前尝试几次,在谈话中间变得沉默”。事实上,Mehrabian等人[91]认为面部表情,语音和语义信息分别占情感计算消息的55%,38%和7%。在[36]中,言语被认为是分析抑郁症的关键客观标志,涵盖了广泛的特征(例如,韵律、源、声学和声道动力学)。
此外,面部区域周围的图案对于抑郁估计也是重要的。手和身体姿势包括在与抑郁估计相关的某些模式中。视觉线索对于估计抑郁症是必不可少的。认为瞳孔扩大与抑郁症有一定关系。在[92]中,认为更快的瞳孔运动代表健康对照的阳性。抑郁受试者在某些情况下瞳孔扩张反应较慢[93-98]。在[99]中,人们发现瞳孔偏差和直径对于评估抑郁症也很重要。此外,面部表情的因素(例如,愤怒、悲伤、喜悦、惊讶、厌恶、恐惧等)被视为抑郁症检测的区分线索。假设一个人被诊断为抑郁症。在这种情况下,他们将在他们的面部表情中表现出低表达性[17,87,96,100 -104]。 这些特征包括减少的目光接触[105]、注视方向[104,106 -108]、眼睑活动[109]、虹膜运动[110]和眼睛张开/眨眼[96,110,111]。眼球运动和眨眼也被认为是对抑郁症进行分类的区别特征[109]。此外,自发微笑的持续时间[106,108],微笑的强度[104,106,108],嘴巴动画[111],缺乏微笑[105]也被认为包含抑郁检测的有价值的模式。
动作单位(Au)是肌肉群或个体肌肉的基本动作,最初由Ekman等人提出[112],然后由Cohn等人采用[14]来分析抑郁状态。在[113]中提出了一种新的基于AU的方法,称为区域单元(RU)。罗斯用于表示包围AU的面部区域。Au已被用于评价抑郁症的严重程度,并取得了令人满意的结果[100- 102,114 -126]。后来,人们发现[109]头部姿势和运动也包含用于评估抑郁症严重程度的判别模式[17,96,100 - 104,106,108,110,111,117,127 -130]。具体而言,46个点已被用于使用主动外观模型(AAM)来训练3D人脸模型以提取头部姿势和运动特征。面部动画和运动的可变性也被用于抑郁症检测[17,100,102,111]。身体姿势(例如:上半身、下半身和手)也是非常重要的检测特征[128-132]。Gratch等人。[107]发现足部敲击和自适应器也有助于抑郁症的检测。此外,面部肌肉的活动、皮肤电反应和外周血压也会引起不自主的变化,这些变化往往反映了抑郁症常见的、持续的消极思想和悲伤情绪。在[133]中发现,脑电图记录可能具有与抑郁症相关的某些模式。在[134,135]中,功能性近红外光谱(fNIRS)也被认为是帮助抑郁症诊断任务的工具[136]。
此外,研究发现抑郁症可导致神经生理和神经认知异常,这在通过面部手势、语音清晰度等进行的个体交流中得到证明[37,137]。因此,我们集中在这方面的审查视听信号的ADE。从基于视听线索的机器学习的角度来看,抑郁症识别问题可以被看作是一个分类和回归问题。例如,在AVEC 2013和AVEC 2014竞赛中,ADE任务可以被认为是回归问题,目的是估计抑郁水平,即,每个音频和视频的BDI-II。在AVEC 2016 [123]中,第一个目的是估计PHQ-8评分,这可以被认为是一个回归问题,而第二个目的是将受试者分类为抑郁或非抑郁,这是一个分类问题。AVEC 2017 [138]中的任务也是估计PHQ-8评分,这可以被视为回归问题。
表3.过去20年来被审查的作品中采用的视听数据库的摘要。缩略语:DPRD抑郁、SCDL自杀、NTRL中性、无抑郁或自杀、M男性人数、F女性人数DSM -精神障碍诊断和统计手册、HAMD -汉密尔顿抑郁评定量表、BDI -贝克抑郁量表、QIDS -抑郁症状快速量表、PHQ-9 -患者健康问卷。注:DSM是语料库中所有抑郁症患者的临床评分,以满足重度抑郁症的标准。
抑郁症数据库

见图4。从AVEC 2014数据库中的视频剪辑中随机选择图像沿着及其BDI-II抑郁严重程度评分[23]。为了保护参与者的隐私,图像被模糊,眼睛的区域被遮挡。从不同的行中,可以看到抑郁症的严重程度在图像中从无增强到严重。
数据收集的原则
收集抑郁症数据需要从医院或心理诊所招募一些参与者,这是抑郁症研究中最具挑战性的部分。如现有研究所述,抑郁受试者和健康对照者均按照DSM-IV [41]标准[14,92,93,95,117,130]和Scinor HAMD [14,118,130,132]进行评估。此外,国际神经精神访谈(MINI)[154]已被用于诊断抑郁症的严重程度,QIDS-SR已被用于定义它。BDI已被广泛应用于评估抑郁症的严重程度[92]。在其他情况下,几个标准,PHQ-9 [17,100 -102,106,107]和BDI-II [22,23]旨在评估与抑郁症相关的症状。其他征聘办法(例如,传单、海报、社交网络、个人联系人和邮件列表)也被用于若干研究。
为了获得评估抑郁水平的有价值的模式,应该仔细设计实验环境。在一般情况下,一些协议在实验之前签署。如果数据收集发生在医院,则应首先安排一些设备(例如,摄像机、麦克风和传感器),并应计划要记录的变量的细节。接下来,应收集参与者的详细信息(例如,记忆记录表和认知能力)。例如,在[155]中,患者必须满足以下标准:(1)诊断为MDD或其他精神障碍;(2)能够理解并满足方案的要求;(3)没有其他可能干扰结果的临床背景(例如,谵妄、痴呆、遗忘或其他症状);(4)没有评估双相情感障碍症状;(5)在过去三个月内不能满足DSM-IV的标准;(6)能够理解美式英语。 此外,健康对照组必须满足相同的标准。特别是,健康的人在过去一年中不应该有任何与抑郁症有关的症状。所有音频样本都是在同一年和相同的环境中收集的(即,房间和其他实验设置)。
如上所述,收集环境或设置对于记录数据至关重要。在某些情况下,情绪诱导被用来在参与者中产生特定的情绪反应,这在健康对照组和抑郁受试者之间是不同的[36]。此外,访谈也被用来发现抑郁症的症状,在访谈中也发现了一些与抑郁症密切相关的自发情绪模式[113]。总的来说,访谈由临床医生、心理学家、精神病学家、虚拟人访谈员进行,并由计算机引导以生成多个数据样本。
关于模态,语音和视频样本[14,16,17,101,103,104,106 - 108,111,120,128 - 130,156 -160]以及生理信号[107,161,161 -167]和文本[107,115]都被用来提高抑郁症评估的性能。然而,具体的方式是由所使用的设备决定的。数据收集阶段。对于音频剪辑,计算机或膝上型计算机已被用于记录数据样本(即,AVEC 2013 [22]、AVEC 2014 [23]、AVEC 2016 [123])。对于视频模态,面部和整个身体已经由多个摄像机从不同角度分别记录[14]。此外,基于眼睛温度的热图像已被用于确定抑郁症的严重程度[168]。微软Kinect也被用于记录参与者的上半身[100,106]。参与者之间的距离约为一米。设计了一种便携式三电极EEG设备来收集脑电图数据[166]。与情绪诱导一样,不同的研究在具体设置上也有所不同。
数据库综述
深度抑郁识别需要足够的数据来训练判别模型。由于抑郁症的敏感性,数据收集具有挑战性。因此,不同的研究小组都试图收集自己的数据库,研究评估工具的抑郁估计。因此,数据库是否开放对ADE起着非常重要的作用。在这篇综述中的114项研究中,只有5%的研究包含不向公众提供的私人数据集。在这次审查中,共审查了20个数据库,只有8个数据库可供公众使用。在这里,我们介绍的数据库已被广泛采用的抑郁症检测的审查研究。此外,我们还涵盖其他私人发布的数据库。表3总结了上述数据库,包括受试者数量、注释评分、基础事实、可用性和其他详细信息。图 4显示了AVEC 2014数据库中的一些图像示例。为了进一步突出ADE的数据库,我们只回顾最流行的数据库。
1-BlackDog数据库[146]由一个名为BlackDog研究所的组织收集,专注于澳大利亚悉尼的临床研究。80名参与者(年龄从21岁到75岁不等)参加了会议。为了确保实验的可用性,所有参与者都必须遵守DSM-IV的标准。语音数据记录在采访者和参与者之间的对话。临床互动是通过询问特定问题(8组)来进行的,其中要求参与者描述由特定情绪刺激的事件。
2 -AVEC 2013数据库[22]是从视听抑郁语料库中精选出来的,涵盖了来自292人进行人机交互的340个视频。参与者的平均年龄为31.5岁(范围从18岁到63岁)。采用BDI-II标记每个音频和视频片段。在这个数据库中,组织者只提供了总共150个音频和视频片段,分为三个等价的分区(培训,开发和测试集)。与前面提到的数据库不同,AVEC 2013是开放的,供研究人员设计ADE系统。
3 -AVEC 2014语料库[23]选自AVEC 2013语料库。唯一的区别是AVEC 2014语料库包含两个任务,即Freeform和Northwind。因此,每个分区覆盖100个数据样本。因此,AVEC 2014共包含300个数据样本。BDI-II用于标记每个音频和视频剪辑。
4 -DAIC数据库是基于美国的半结构化临床互动收集的。进行了四种类型的访谈:面对面,会议,Wizard-of-Oz(人机对话),和自动。该数据库包含189个交互会话,并且由视听提示以及生理数据(例如,皮肤电反应(GSR)、心电图(ECG)和呼吸)。此外,在交互过程中还收集了文本模态。使用不同的言语和非言语特征来注释语料库。DAIC与AVEC 2013和AVEC 2014在研究人员开放获取方面相同。
5 -在CHI-MEI数据库[150]中,采用六个离散视频(即厌恶,恐惧,悲伤,惊讶,愤怒和快乐)来唤起受试者根据他们的面部区域和对他们的言语反应表达他们的表情。由台湾奇美医学中心的临床医生从受试者的语音反应中收集奇美语音数据库。在这个数据集中收集了音频和视频数据。总共招募了15名BD、15名UD和15名健康对照用于CHI-MEI。此外,参与者必须在数据收集之前完成基线记录。之后,参与者观看了六段情感视频。
6-匹兹堡数据库[151]涉及57名(34名女性,23名男性)抑郁症参与者,他们来自抑郁症的临床治疗。年龄范围为19 - 65岁(平均= 39.65)。所有参与者都必须满足DSM-IV的MDD标准。由10名随机临床访谈者在第1、7、13和21周评估MDD的严重程度。该数据库也开放供公众使用。
7 -BD数据库[152]涉及一家医院精神卫生服务的46名患者和49名健康对照。采用SKIP-TURK半结构式访谈法对所有患者进行社会人口学和临床特征分析,并在随访0、3、7、14、28 天时采用Young躁狂量表(YMRS)和MADRS评定抑郁和躁狂症状,第3个月进行改变。在此步骤中,记录了视听样本。因此,每个视频会话分别由YMRS/MADRS评级注释。该数据库用作AVEC 2018中的挑战数据。
8 -MODMA数据库[153]是从中国的音频和EEG信号中收集的,用于精神障碍分析。经验丰富的精神科医生从医院严格招募所有参与者。EEG数据库包含使用传统的128电极弹性帽记录的数据样本,以及新的可穿戴3电极EEG记录仪,可广泛使用。53名受试者在静息和欠刺激状态下记录了128个电极的脑电信号,55名受试者在静息状态下记录了3个电极的脑电信号。具体到音频数据,通过允许参与者接受采访,阅读故事和观看情感图片,从52名受试者中收集样本。
根据表3中提到的数据库,进行以下讨论:
(1)由于数据库由不同的实验室或组织记录,视频记录设备的类型可能会有所不同。匹兹堡的数据库采用了四台硬件同步的模拟摄像机:两台分别放置在距离参与者左右约15米处,用于监控头部和肩部,第三台摄像机用于全身记录,而第四台则记录采访者的活动,并配有两个麦克风来记录演讲。其他数据库使用摄像头来监控参与者的面部/上半身的活动。
(2)从开放性的角度来看,大部分数据库仅用于自己的研究,尚未公开发布用于抑郁症识别研究。在本次综述的114项研究中,62%同时考虑了AVEC 2013和AVEC 2014数据库,29%考虑了DAIC数据库。DAIC-WOZ、BD数据库[152]、匹兹堡数据库[151]和MODMA数据库仅部分向公众开放。此外,还提供了AVEC 2013和AVEC 2014组织者的原始音频和视频,供研究人员提取手工制作和深度学习的特征,因此更多的研究采用了AVEC 2013和AVEC 2014数据库。
(3)大多数数据库都是在美国和欧盟地区收集的。中国只有一个数据库可供研究人员使用,那就是MODMA。
(4)在回顾的研究中,共采用了20个不同的抑郁症数据库。就模式而言,大多数数据库涉及一个或多个(例如,音频、视频、生理信号、文本)。如表3所示,有12个数据库被评为单峰,占60%。在单模态类别中,50%使用音频模态。原因是音频可以在任何环境中轻松收集。对于多模态数据库,只有8个可用,占40%。
(5)数据库的另一个重要方面是主题的数量。就受试者的数量而言,所有数据库都由相对较小的数据样本组成,这是因为抑郁症是一种精神障碍,并且也被抑郁症受试者保密。AVEC 2014涉及292名受试者,数据样本来自这些受试者,而其余数据库涉及的受试者相对较少。罗切斯特数据库涉及的受试者最少,并且不对公众开放。
深度视听抑郁识别
本节介绍ADE中采用的常规程序,即,预处理、深度特征提取和分类/回归。在下文中,文献被分为三组:(1)用于音频模态的深度ADE网络;(2)用于静态图像的深度ADE网络;以及(3)用于图像序列的深度ADE网络。此外,还介绍了不同的网络类型为所提到的群体沿着进行讨论。
自2013年以来,深度学习方法受到了计算机视觉社区的极大关注。本文的目的是(i)从视听线索中查看与抑郁症相关的最新工作信息,以及(ii)综合 DL 应用于抑郁症评估的关键收获。
为了实现这些目标,自2013年以来,我们进行了两阶段文献检索(IEEE Xplore,Springer Link,Web of Science和ACM数字图书馆)。我们的第一阶段搜索产生了480项研究。在第二阶段,我们将搜索限制在采用听觉和视觉线索识别抑郁症的研究中。之后,我们对这些研究进行了人工排序,通过浅层和DL方法,获得了114篇与抑郁症相关的研究。然后,我们集中在本综述中考虑的78项研究,采用DL的ADE。出于本综述的目的,这些选定的研究在以下章节中根据ADE的DL按方式(音频和视频)进一步分类。
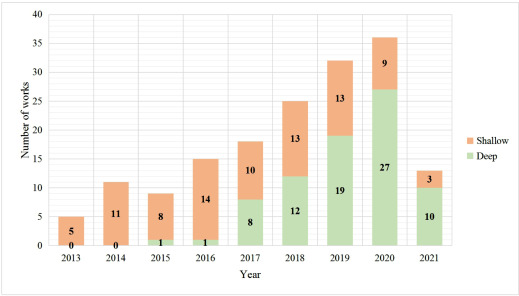
图五. 2013年至2021年,研究出版物数量。为了进一步说明采用深度学习识别抑郁症,浅层和深层研究按出版年份进行统计。
图5显示了2013年至2021年的研究出版物数量。根据图5,可以得出以下结论:(1)从2013年到2021年,相关出版物迅速增加,表明基于视听线索的ADE是一个快速增长的领域。特别是在2013年和2014年,抑郁症子挑战提供了一个动机,以评估从视听线索的严重程度。然后,在2016年和2017年与抑郁症相关的挑战中,多项研究尝试使用深度学习从另一个角度分析抑郁症,从而发表了一些新颖的研究。
(2)自2017年以来,ADE的DL受到了高度关注。2017年和2018年的兴趣急剧上升可归因于2016年的[24]和2017年的[28]。
预处理
传统的和端到端的方案在实际的抑郁识别和分析之前都需要一些预处理。
在78项综述的研究中,53项(该数字将与视频模态的研究重叠)采用不同的音频模态策略进行了预处理。例如,音频的采样率被处理为16 kHz或其他速率(例如,AVEC 2013)。为了生成音频数据的频谱图,采用离散
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8914
8914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









