







文章目录
SFTNet: A microexpression-based method for depression detection
SFTNet:一种基于微表情的抑郁检测方法
论文小结
建立了一个新的数据集156名受试者(病例组76名,对照组80名)。
通过微表情分析[表情的平均出现次数(ANO)和平均持续时间(AD)]验证了抑郁症患者和非抑郁症患者在表情丰富度上存在很大差异。
提出了一个基于微表情的双处理流模型SFTNet能更准确检测抑郁症,准确率、精确度和召回率分别为0.829、0.817和0.837,代码可以获取。
摘要
背景与目的:抑郁症是一种典型的精神疾病,早期筛查可有效预防病情的加重。许多研究发现,抑郁症患者的表情与其他被试的表情不同,微表情已被用于精神疾病的临床检测。然而,基于微表情的抑郁症自动检测方法很少。
方法:建立一个包含156名受试者(病例组76名,对照组80名)的新数据集。所有的数据都是在一个新的情绪刺激实验和医患对话的背景下收集的。我们首先分析了病例组和对照组面部表情的平均出现次数(ANO)和平均持续时间(AD)。然后,我们提出了一个基于微表情的双处理流模型SFTNet,它由一个单时网络(STNet)和一个全时网络(FTNet)组成。该方法利用STNet对人脸图像进行单时间节点特征提取,利用FTNet对人脸图像进行全时间节点特征提取,决策网络将两种特征进行决策融合,识别抑郁症。SFTNet的代码可在https://github.com/muzixingyun/SFTNet上找到。
结果:所有被试的AD均小于20帧(2/3秒),对照组的面部表情更丰富。SFTNet在情绪刺激实验数据集上取得了优异的成绩,准确率、精确率和召回率分别为0.873、0.888和0.846。在医患会话数据集上进行了实验,准确率、精确度和召回率分别为0.829、0.817和0.837。SFTNet也可以应用于微表情检测任务,比SOTA模型更准确。
结论:在情绪刺激实验中,病例组被试更容易表现出负性情绪。与SOTA模型相比,我们的抑郁症检测方法更准确,可以帮助医生诊断抑郁症。
介绍
抑郁症是世界范围内常见的精神疾病。据世界卫生组织预测,2030年抑郁症将成为世界卫生系统的三大负担之一[1]。抑郁症通常表现为情绪低落和睡眠障碍等症状。一些患者还会出现躁狂/轻躁狂症状,严重时可能导致自杀[2]。抑郁症严重影响患者的身心健康、日常工作和生活。因此,早期发现和治疗抑郁症是非常重要的。在抑郁症的临床诊断方法中,非实验室方法的结构化/半结构化访谈是最常用的。在访谈过程中,临床医生根据结构化问卷(如汉密尔顿问卷)与患者进行交流规模[3]。这种诊断方法主观解释性强,结果与患者的诚信度有关,耗时较长[4]。因此,有必要建立一种快速有效的辅助方法,并与传统方法相结合。
一系列医学研究证明,抑郁症患者的某些行为特征(如面部活动单位(Au)、注视方向、语音语调等)与正常人有很大不同。研究[5]使用面部动作编码系统(FACS)将面部表情分解为AU进行分析,发现抑郁症患者笑得更少,更倾向于表现出一些负面表情。研究人员在研究中提出[6-8],抑郁症患者倾向于减少目光接触,凝视方向和眨眼。Fu等人[9]设计了面部表情识别和模仿实验。他们发现抑郁症患者模仿面部表情的能力下降。1981年,Leff等人[10]发现了抑郁症患者和精神分裂症患者之间的音调差异,并利用这种差异来区分这两种患者。Cannizzaro等人[11]证明了抑郁症的严重程度与患者的语速和停顿时间之间存在很强的相关性。
基于上述临床发现,研究者们提出了许多抑郁症检测方法。Yuan等人[12]使用眼动仪提取的眼动特征来识别抑郁症患者,准确率为0.83。He等人[13]建立了一个深度局部全局注意力卷积神经网络(DLGA-CNN),从面部视频中挖掘特征,用于抑郁症识别。研究[14,15]使用音频特征来识别抑郁症,并取得了很好的效果。也有一些研究人员使用脑电图(EEG)特征来自动检测抑郁症[16-18]。
除了使用单个特征进行抑郁症识别之外,还可以将多个特征组合用于多模态抑郁症检测。Rejaibi [19]在结合音频特征和面部特征后,将准确率提高到0.956。Ye等人[20]构建了一种基于语音特征和文本特征的抑郁症识别方法,准确率达到0.912。Haque等人[21]首先将面部表情特征,文本特征和语音特征相结合,然后使用扩张卷积来获得时间序列特征。DAIC-WOZ数据集上的F1评分为0.77。
随着医学研究的不断深入,微表达技术正逐渐应用于精神疾病的临床检测。微表情是一种快速变化的表情,持续时间仅为1/25秒至1/2秒,常表现一个人内心压抑的真实情绪[22]。研究[23]使用生态学梅斯识别范式比较了正常个体和抑郁个体在微表情识别任务准确性上的差异,显示抑郁个体和非抑郁个体在微表情的识别和表达上存在差异。研究[24,25]还发现,抑郁症患者对积极情绪的识别速度明显长于非抑郁症患者。由于微表情的持续时间较短,即使是经过专门训练的人也很难在微表情识别任务中实现高准确度[22,26]。 计算机视觉的快速发展为微表情识别任务提供了机遇。文献[27-30]中提出的微表情识别方法的准确率达到0.70-0.90。
通过对上述研究的深入分析,我们发现抑郁症视频数据集的采集呈现出周期长、案例稀少、隐私保护程度高等特点。这导致了包含明确面部信息的可公开访问的数据集的有限可用性。然而,积累大量准确的面部数据集对于全面调查抑郁症患者的面部表情至关重要。许多研究表明,抑郁症患者的面部表情与健康人不同,微表情被认为对检测精神疾病很有价值。然而很少有学者提出基于微表情的抑郁检测方法。因此,我们的工作重点主要围绕以下几个方面:
·我们对156名被试进行了情绪刺激实验,记录了被试观看不同情绪图片时表情的变化。
·我们分析了病例组和对照组在情绪刺激测试下7种表情的平均出现次数(ANO)和平均持续时间(AD),发现抑郁症患者和非抑郁症患者在表情丰富度上存在很大差异。
·我们构建了一个新的模型SFTNet来提取微表情特征。与传统的从顶点帧和起始帧提取微表达信息的特征提取器不同,SFTNet直接从原始微表达序列中提取特征。SFTNet采用时间注意机制来区分每个时间节点的重要性。SFTNet还强调了轮廓信息的重要性,在SFTNet中增加了轮廓捕获模块。SFTNet的准确度为0.873的抑郁症识别任务,这超过了最先进的(SOTA)模型的动作识别和微表情识别任务。SFTNet在微表情识别任务上也取得了优异的成绩。
图1.我们研究的结构。
本研究的结构如图1所示。第二节介绍了抑郁症检测和微表情特征提取的相关研究进展。第三部分介绍了情绪刺激实验和数据预处理方法。第四部分提出了一种新的抑郁症识别模型SFTNet。第五节介绍并讨论了实验结果。第六节概述并讨论了未来的工作。
相关工作
为了研究抑郁症患者与普通人情绪变化的差异,一些研究设计了多种情绪刺激方法。Han等人[31]从中国人脸情绪图片系统(CFAPS)[32]中选取了160张情绪人脸图片(40张正面图片,40张负面图片,80张中性图片),以获得抑郁症患者对不同情绪人脸图片的关注度。Beevers等人[33]设计了一个情绪注意力实验,要求受试者观看一个由恐惧、悲伤、快乐和中性面部表情组成的2 × 2矩阵,同时跟踪受试者的眼睛状态,以研究创伤后应激障碍(PTSD)与抑郁症之间的关系。这些研究[34-36]要求受试者观看来自国际情感图片系统(IAPS)的非面部图像[37],以研究患者的大脑功能。 上述研究揭示了两种方法进行情绪刺激实验,使用面部图像或非面部图像作为刺激源。然而,研究[38,39]发现,抑郁症患者识别面部表情的能力与正常人不同,这可能导致使用面部图像无法诱导受试者的情绪。 因此,我们选择使用非面部图像作为情绪刺激的刺激源实验。值得注意的是,我们的实验共涉及156名参与者,而研究中的参与者分别为34、45和42人[34-36]。
基于人脸信息的方法作为抑郁症自动检测的主要方向之一,已经取得了很大的进展。De梅洛等人[40]首先使用时间池化方法将3D视频信息压缩为2D编码图片,然后将编码图片和视频中的帧馈送到双流模型中以预测抑郁症的严重程度。该模型在AVEC 2013和AVEC 2014数据集上分别达到RMSE 7.97和RMSE 7.94。Song等人[41]提出了另一种基于人类行为基元的抑郁症严重程度预测模型。首先,从视频中提取特征序列,如Au,注视方向和头部姿势,然后使用两种光谱图像(光谱热图和光谱向量)来表示特征序列,并将其输入到由1D卷积神经网络(1D-CNN)组成的模型中,以预测抑郁症的严重程度。该模型在AVEC 2013上的RMSE为8.10,7.15 AVEC 2014数据集上。
在微表情识别方面,Liong等人[42]提出了一种新的特征提取器双加权定向光流,用于从顶点帧和起始帧中提取微表情识别的特征。在CASME II和SMICHS数据集中,F1评分分别为0.61和0.62。Lei等人[43]使用图卷积神经网络(GCN)提取了顶点帧和起始帧的面部关键点特征和Au特征,并将其嵌入到面部图像表示中,用于微表情识别。该方法在CASME II和SAMM数据集上取得了良好的效果。霍尔等人[44]提出了SSSN用于微表情识别。SSSN的输入是顶点帧和起始帧之间的光流信息。Wang等人[45]使用多个具有权重共享的2D-CNN模型从不同的时间节点提取面部特征,然后使用1D-CNN模型提取用于微表情检测的时间特征。Peng等人 [46]提出了一种端到端的微表情识别方法AKMNet,直接从微表情视频片段中提取信息进行微表情检测。
与上述研究不同的是,我们的情绪刺激实验使用的是IAPS中的非人脸图片,而不是人脸情绪图片。在设计基于微表情的抑郁症识别模型时,我们不从顶点帧和起始帧中提取微表情特征,而是从原始数据中提取微表情特征。因此,我们设计了一个单一的时间模型(STNet)和一个完整的时间模型(FTNet),从多个时间域提取空间信息。STNet使用3D-CNN网络而不是多个2D-CNN网络来从不同的时间节点提取面部特征。Majumder等人[47]利用眼睛,嘴唇和眉毛的面部特征点来形成情感识别的轮廓,并取得了显着的成果。这强调了轮廓信息在情感识别中的有效性。受此研究的启发,我们在STNet中添加了轮廓捕获模块。 第五节中的消融实验证明了单个组件的有效性。
数据集和预处理
我们的数据是在情绪刺激实验下收集的。数据来源于山东省精神卫生中心。我们的研究获得了中国临床试验注册伦理委员会的批准,并严格按照世界医学会的伦理守则(赫尔辛基宣言)进行。受试者在数据收集之前被告知实验的细节。
情绪刺激实验
共有156名受试者(病例组76名,对照组80名)参加了实验。摄像头和声卡
用于记录实验过程中受试者的视频和相应的音频。摄像机的帧速率设置为30 f/s,声卡的采样频率为48 kHz。在受试者面前放置监视器,受试者坐在距离监视器约一米的绿色屏幕前接受情绪刺激实验。在所有受试者参与情绪刺激实验之前,两名专科医生根据汉密尔顿量表与受试者交谈。对话的视频和音频被同时记录下来,我们将其命名为医生-患者对话数据集。面试结束后,医生给受试者的汉密尔顿评分。我们将得分低于8分的受试者分为对照组,其余为病例组。
情绪刺激实验包括三个部分:积极情绪刺激实验、中性情绪刺激实验和消极情绪刺激实验。受试者面前的显示屏按顺序播放30张用于情绪刺激的图片。所有图片均摘自IAPS,其中包含十张积极刺激、神经刺激和消极刺激的图片。每张图片在显示器上停留6秒钟,每个情绪刺激实验持续1分钟。我们将每次记录的数据称为积极、中性和消极情绪刺激数据集,统称为情绪刺激数据集。
微表达序列提取
微表达序列提取过程如图2所示。为了防止实验开始和结束时外部噪声数据的干扰,我们只保留了视频中200-1500帧的数据。为了屏蔽其他信息对面部信息的影响,我们还使用OpenFace工具包[48]来对齐和裁剪每帧的面部区域。裁剪后,每个受试者的数据由1300张大小为112 × 112的人脸图像组成。在完成上述操作后,我们定义一个窗口大小为 w w w,步长为 s s s的滑动窗口,对每个受试者的面部数据进行微表情采样。
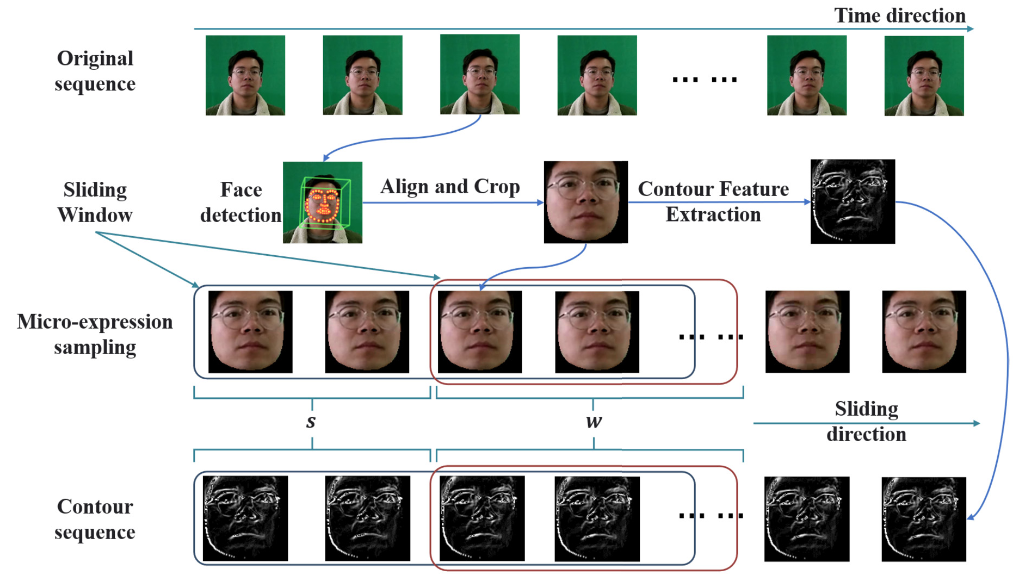
图2.数据预处理和微表达采样过程。原始数据首先通过诸如面部对准、裁剪和轮廓特征提取之类的操作逐帧地处理。然后,使用滑动窗口对微表达式进行采样,其中’ w w w’表示窗口大小,' s s s’表示窗口的滑动步长。
轮廓提取
面部轮廓是STNet输入的一部分(详见第4节),我们使用Sobel算子提取它。Sobel算子是一种一阶差分算子,常用于图像轮廓提取。Sobel算子由矩阵A和B组成,其中
G x = − 1 0 1 − 2 0 2 − 1 0 1 G_{x}=\begin{matrix}-1&0&1\\-2&0&2\\-1&0&1\end{matrix} Gx=−1−2−1000121 G y = − 1 − 2 − 1 0 0 0 1 2 1 G_{y}=\begin{matrix}-1&-2&-1\\0&0&0\\1&2&1\end{matrix} Gy=−101−202−101
G x G_x Gx和 G y G_y Gy
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









