






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
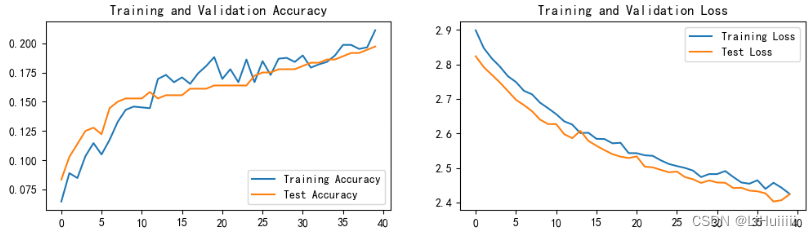
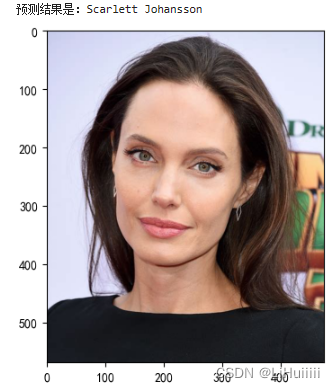
import torch import torch.nn as nn import torchvision.transforms as transforms import torchvision from torchvision import transforms, datasets import os,PIL,pathlib,warnings warnings.filterwarnings("ignore") #忽略警告信息 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") import os,PIL,random,pathlib data_dir = './6-data/' data_dir = pathlib.Path(data_dir) data_paths = list(data_dir.glob('*')) classeNames = [str(path).split("\\")[1] for path in data_paths] train_transforms = transforms.Compose([ transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸 # transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间 transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛 mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。 ]) total_data = datasets.ImageFolder("./6-data/",transform=train_transforms) train_size = int(0.8 * len(total_data)) test_size = len(total_data) - train_size train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size]) batch_size = 32 train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1) test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1) for X, y in test_dl: print("Shape of X [N, C, H, W]: ", X.shape) print("Shape of y: ", y.shape, y.dtype) break from torchvision.models import vgg16 device = "cuda" if torch.cuda.is_available() else "cpu" print("Using {} device".format(device)) # 加载预训练模型,并且对模型进行微调 model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型 for param in model.parameters(): param.requires_grad = False # 冻结模型的参数,这样子在训练的时候只训练最后一层的参数 # 修改classifier模块的第6层(即:(6): Linear(in_features=4096, out_features=2, bias=True)) # 注意查看我们下方打印出来的模型 model.classifier._modules['6'] = nn.Linear(4096,len(classeNames)) # 修改vgg16模型中最后一层全连接层,输出目标类别个数 model.to(device) model def train(dataloader,model,loss_fn,optimizer): size=len(dataloader.dataset) num_batchs=len(dataloader) train_loss,train_acc=0,0 for X,y in dataloader: X,y=X.to(device),y.to(device) pred=model(X) loss=loss_fn(pred,y) optimizer.zero_grad() loss.backward() optimizer.step() train_acc +=(pred.argmax(1)==y).type(torch.float).sum().item() train_loss+=loss.item() train_acc/=size train_loss/=num_batchs return train_acc,train_loss def test (dataloader, model, loss_fn): size = len(dataloader.dataset) # 测试集的大小 num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整) test_loss, test_acc = 0, 0 # 当不进行训练时,停止梯度更新,节省计算内存消耗 with torch.no_grad(): for imgs, target in dataloader: imgs, target = imgs.to(device), target.to(device) # 计算loss target_pred = model(imgs) loss = loss_fn(target_pred, target) test_loss += loss.item() test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() test_acc /= size test_loss /= num_batches return test_acc, test_loss learn_rate = 1e-4 # 初始学习率 # 调用官方动态学习率接口时使用 lambda1 = lambda epoch: 0.92 ** (epoch // 4) optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate) scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) #选定调整方法 import copy loss_fn = nn.CrossEntropyLoss() # 创建损失函数 epochs = 40 train_loss = [] train_acc = [] test_loss = [] test_acc = [] best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标 for epoch in range(epochs): # 更新学习率(使用自定义学习率时使用) # adjust_learning_rate(optimizer, epoch, learn_rate) model.train() epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer) scheduler.step() # 更新学习率(调用官方动态学习率接口时使用) model.eval() epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) # 保存最佳模型到 best_model if epoch_test_acc > best_acc: best_acc = epoch_test_acc best_model = copy.deepcopy(model) train_acc.append(epoch_train_acc) train_loss.append(epoch_train_loss) test_acc.append(epoch_test_acc) test_loss.append(epoch_test_loss) # 获取当前的学习率 lr = optimizer.state_dict()['param_groups'][0]['lr'] template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}') print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr)) # 保存最佳模型到文件中 PATH = './best_model.pth' # 保存的参数文件名 torch.save(model.state_dict(), PATH) print('Done') import matplotlib.pyplot as plt #隐藏警告 import warnings warnings.filterwarnings("ignore") #忽略警告信息 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.rcParams['figure.dpi'] = 100 #分辨率 epochs_range = range(epochs) plt.figure(figsize=(12, 3)) plt.subplot(1, 2, 1) plt.plot(epochs_range, train_acc, label='Training Accuracy') plt.plot(epochs_range, test_acc, label='Test Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, train_loss, label='Training Loss') plt.plot(epochs_range, test_loss, label='Test Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show() from PIL import Image classes = list(total_data.class_to_idx) def predict_one_image(image_path, model, transform, classes): test_img = Image.open(image_path).convert('RGB') plt.imshow(test_img) # 展示预测的图片 test_img = transform(test_img) img = test_img.to(device).unsqueeze(0) model.eval() output = model(img) _,pred = torch.max(output,1) pred_class = classes[pred] print(f'预测结果是:{pred_class}') predict_one_image(image_path='./6-data/Angelina Jolie/001_fe3347c0.jpg', model=model, transform=train_transforms, classes=classes)

- 总结:加油















04-30
 2万+
2万+
2万+
09-15
1万+
1万+
11-19
731
731
02-01
5458
5458
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









