







 本文介绍了如何在Ubuntu环境下使用YOLOV5进行目标检测,包括下载库、使用预训练模型检测图片和实时摄像头、创建并标注数据集以进行模型训练,以及最终部署自定义模型的过程。
本文介绍了如何在Ubuntu环境下使用YOLOV5进行目标检测,包括下载库、使用预训练模型检测图片和实时摄像头、创建并标注数据集以进行模型训练,以及最终部署自定义模型的过程。
目录
环境准备
系统环境:Ubuntu 20.4,pycharm,anconda
下载YOLOV5库
git clone https://github.com/ultralytics/yolov5
安装好后会在当前路径生成一个yolov5的文件夹,点击requerments.txt查看自己环境是否满足
可以通过pip指令快速安装
cd yolov5
pip install -r requestments.txt基本操作
使用ultralytics模型检测图片
ultralytics是一个托管在pytoch的resource仓库的一个模型,有很多的模型选择,有大模型,小模型,中等模型等,不同的模型有不同的表现
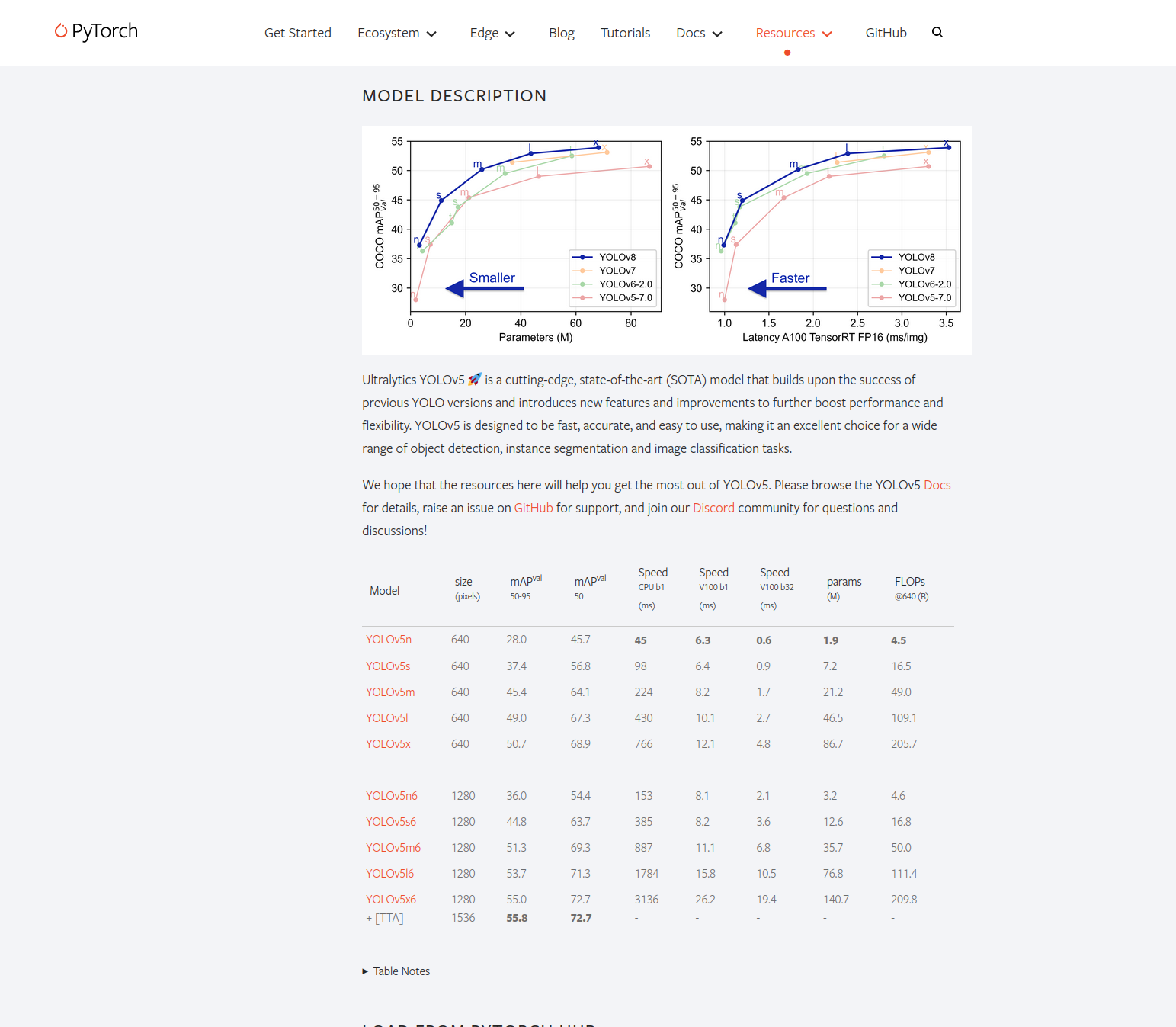
import torch
import cv2
'''
#导入YOLOv5模型,第一个参数如果是 'github',应该被操作为 github repo with format ``repo_owner/repo_name[:ref]`` with an optional ref (tag or branch), for example 'pytorch/vision:0.10'. If ``ref`` is not specified,the default branch is assumed to be ``main`` if it exists, and otherwise ``master``.如果是本地资源 it should be a path to a local directory.
'''
#使用小模型保持轻量和快速
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 加载图像
img = 'https://ultralytics.com/images/zidane.jpg'
# 进行目标检测
result = model(img)
# 获取渲染后的图像
rendered_img = result.render()[0]
# 将图像从BGR转换为RGB
rendered_img_rgb = cv2.cvtColor(rendered_img, cv2.COLOR_BGR2RGB)
# 使用OpenCV显示图像
cv2.imshow('YOLOv5 Detection Result', rendered_img_rgb)
cv2.waitKey(0)
cv2.destroyAllWindows()注意:如果不进行图像转化可能会导致图片的颜色失真
调用实时摄像头检测
import torch
import cv2
import numpy as np
# 导入YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 加载图像
img = 'https://ultralytics.com/images/zidane.jpg'
# 进行目标检测
result = model(img)
cap=cv2.VideoCapture(0)#使用网络摄像头捕获图片
while cap.isOpened():
ret, frame = cap.read()
result = model(frame)
#result.render()只返回图像数组
cv2.imshow('YOLO',np.squeeze(result.render()))
if cv2.waitKey(10) & 0xFF == ord('q'):#如果检测到键盘按下q退出
break
cap.release()
cv2.destroyAllWindows()
模型训练
调用网络摄像头拍摄数据集
import uuid #给每个图片一个独特的ID
import os
import time
import cv2
IMAGES_PATH=os.paimport uuid
import os
import time
import cv2
IMAGES_PATH=os.path.join('data','images')#保存的地址为data/images
labels=['awake','drowsy'] #标签名
nums_imges=20 #拍摄一组标签要多少张
cap=cv2.VideoCapture(0)
for label in labels:
#print(label)
print('Collecting images for label: {}'.format(label))
time.sleep(5)
for img_num in range(nums_imges):
print('Collecting images for image: {},image num {}'.format(label,img_num))
ret, frame = cap.read()
imgname=os.path.join(IMAGES_PATH,label+'.'+str(uuid.uuid1())+'.jpg')
cv2.imwrite(imgname,frame)
cv2.imshow('Image Collection',frame)
time.sleep(2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()拍摄好后在data/image会存放我们拍摄的数据集
下载标注软件
这里使用的是labelImg(比起labling他可以选择标签脚本的输出格式)
在这里查看自己的安装方式
https://github.com/HumanSignal/labelImg?tab=readme-ov-file
标注数据集

几个注意的点:1.选择保存的目标地址为labels(可以自己改名),2.左边第八个存储格式设置为YOLO!!!,然后就可以开始标注了
训练模型
打开GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
找到Tranning,选择Train Custom Data在本地训练
找到
复制文本,在yolov5文件夹下新建yaml文件,讲内容修改为自己的模型
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../data # dataset root dir
train: images # train images (relative to 'path') 128 images
val: images # val images (relative to 'path') 128 images
nc: 2
# Classes (80 COCO classes)
names:
0: 'aawake'
1: 'drowsy'
在终端输入开始训练
python train.py --img 320 --batch 16 --epochs 500 --data dataset.yaml --weights yolov5s.pt
部署使用自己的模型
import os
import torch
import cv2
import numpy as np
# 导入YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='./yolov5/runs/train/exp4/weights/last.pt',force_reload=True)
# 加载图像
img = os.path.join('data','images','awake.8b8cd04e-049c-11ef-8905-c73773fbc0ea.jpg')
# 进行目标检测
'''
result = model(img)
result.print()
# 获取渲染后的图像
rendered_img = result.render()[0]
# 将图像从BGR转换为RGB
rendered_img_rgb = cv2.cvtColor(rendered_img, cv2.COLOR_BGR2RGB)
# 使用OpenCV显示图像
cv2.imshow('YOLOv5 Detection Result', rendered_img_rgb)
cv2.waitKey(0)
cv2.destroyAllWindows()
'''
cap=cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
result = model(frame)
#result.render()只返回图像数组
cv2.imshow('YOLO',np.squeeze(result.render()))
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()















 1787
1787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









