







在信息爆炸的时代,高效筛选和分类内容成为刚需。本文将介绍一个基于 RSS 和 AI 的自动化工作流,它能智能解析光明日报头版文章,并按“综述”、“评论”、“文件”和“其他”自动分类存储到 Google Sheets。通过此案例,你将掌握 RSS 数据处理、AI 文本分类及表格自动化等技术,并能将其扩展至其他信息源,打造个性化的智能阅读系统。
1. 项目概述
这是一个我在实际使用中持续优化的工作流(Workflow),它能够自动抓取光明日报每日头版内容,并利用AI技术将文章智能分类为"综述"、"评论"、"文件"和"其他"四大类别,最终将结构化数据存入Google Sheets表格中。
通过本教程,你将掌握以下实用技能:
-
RSS信息获取与处理方法
-
基于时间维度的内容筛选技巧
-
通过HTTP Request获取网页全文的技术实现
-
大模型在文本分类中的实际应用
-
非结构化文本数据提取技术
-
Google Sheets API的集成使用
2. Workflow预览
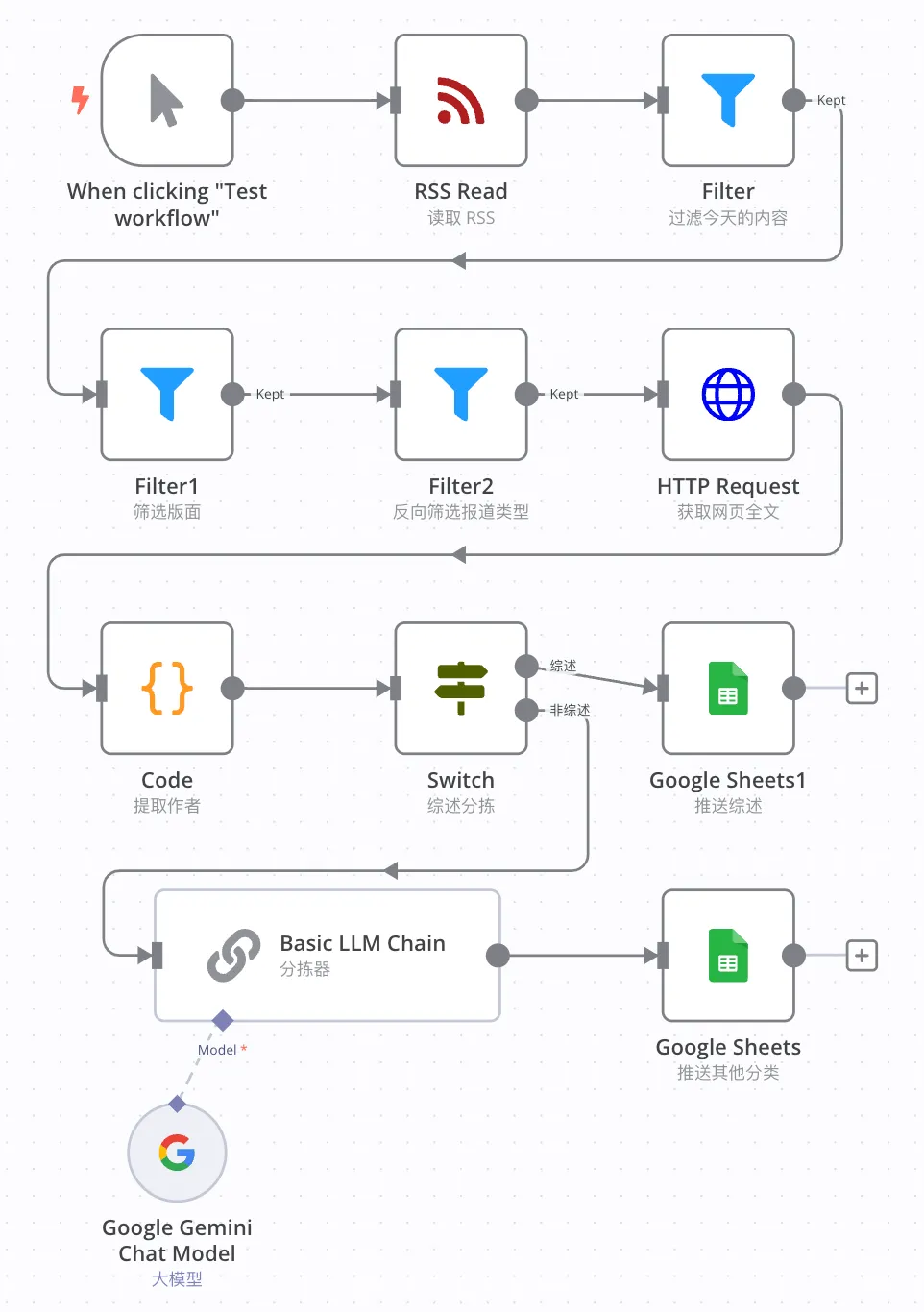
3. 详细实现步骤
3.1 RSS数据获取:RSS Read节点
这个节点是 n8n 的一个官方节点,它的作用是从指定的 RSS 地址获取数据。这不是一个 Trigger 节点,意味着它不会在 RSS 更新的时候自动触发 Workflow。
与之对应的是 RSS Trigger 节点,会在 RSS 地址更新后自动触发 Workflow。
两者的区别如下:
-
RSS Trigger vs RSS Read对比:
| 特性 | RSS Trigger | RSS Read |
|---|---|---|
| 触发机制 | 自动触发Workflow | 需手动/定时触发 |
| 内容范围 | 仅获取更新内容 | 获取全部内容 |
| 适用场景 | 高频少量更新 | 批量大量更新 |
配置建议:
-
光明日报RSS每日批量更新数十条内容,使用RSS Read更合适
-
配合定时任务(如cron job)在每日固定时间触发
-
避免使用RSS Trigger导致短时间内触发过多Workflow实例
你可以根据自己的需求选择,我在这里选择 RSS Read 是因为我选择的光明日报 RSS 是一个每日在指定时间点批量更新的订阅源。
因此,我将这个 Workflow 设置为手动触发,然后用另一个定时任务在每天指定时间触发这个 Workflow,通过 RSS Read 作为第一个节点获取 RSS 内容。 在这里,我不用 RSS Trigger 的原因是,在这种一次更新数十条的订阅源下。如果使用 RSS Trigger 作为启动器,它会在 RSS 更新的瞬间同时将 Workflow 运行数十次,引起服务器负载过高。
但使用 RSS Read 将最新的数十条内容一次读取,后续进行批处理,就不会有问题。
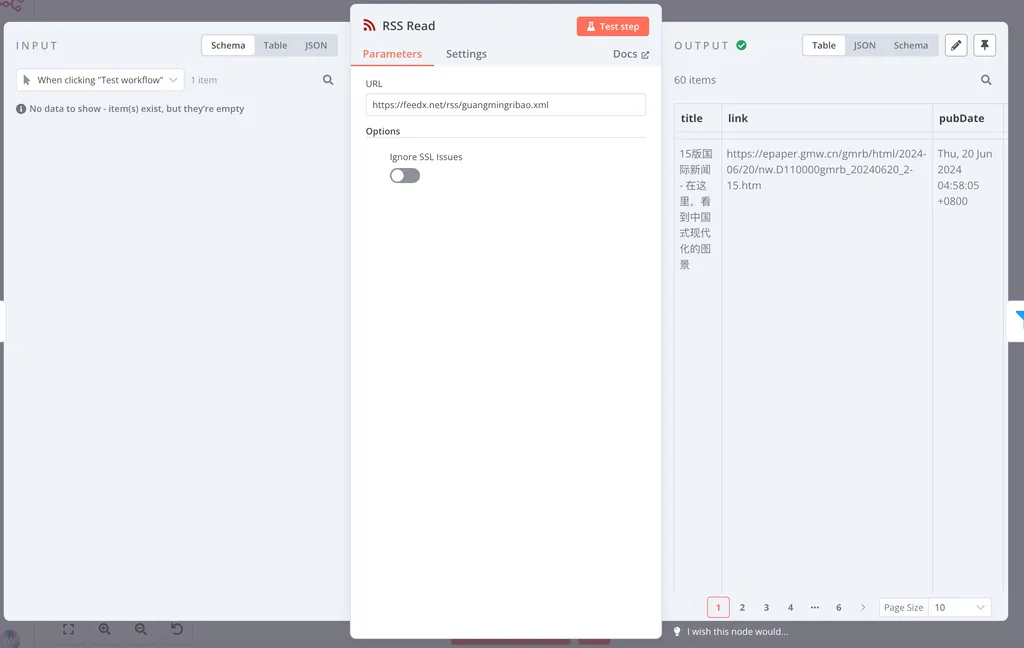
RSS Read 节点选项很少,你只要填入 RSS 地址即可。它的 OUTPUT 结构与 RSS 输出的结构完全相同。
3.2 内容过滤:时间维度筛选
经过阅读 RSS Read 输入的内容我们发现,这个 RSS 输出的文章是会跨越日期的。也就是说,它不止会给出今天的文章,还会有昨天,可能还有前天的。
我们要实现的目标是,将每日的新文章存入一个表格,因此我们需要一个 Filter 节点来过滤掉以前的文章。
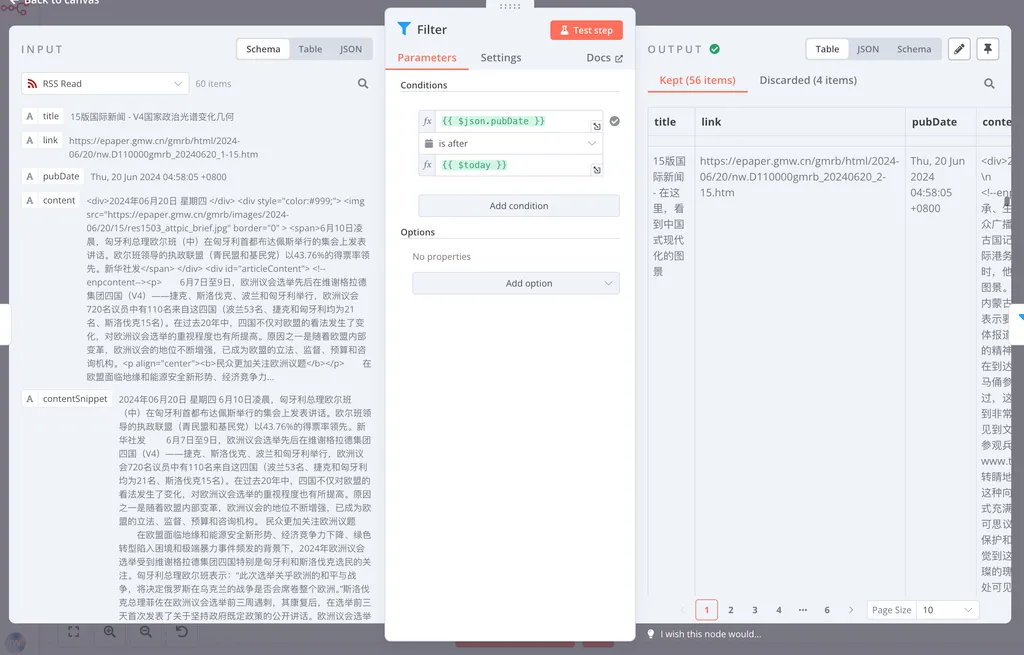
在 Filter 节点中,你可以通过 Add Condition 来添加过滤条件。我们可以看到,在这里我添加了一个条件。
这个条件是:
{{ $json.pubDate }} is after {{ $Today }}这个过程你是不需要太写代码的,在 n8n 的节点编辑界面,你可以将历史数据直接拖拽进文本框。在这里,我就是直接从这里拖进文本框的:
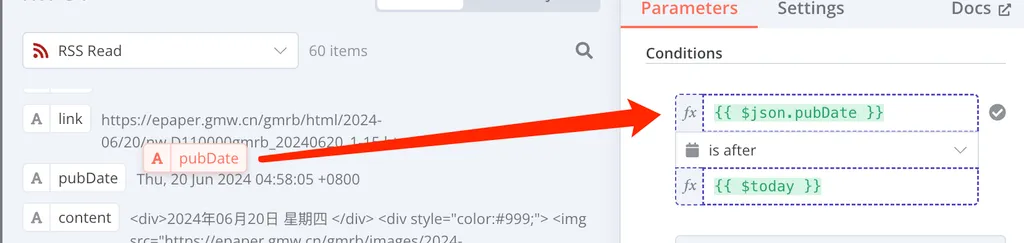
{{ $today }} 是一个 JS 代码,它代表今天的日期,会根据你每次运行 Workflow 的时间变动。在 n8n 中,文本框处于 Expression 模式时,你可以使用 {{ code }} 来插入 JS 代码。
与之对应的是 Fixed。在 Fixed 模式下,文本框里的内容将被完全视为文本,不做任何之行。
我们可以从输出看到,经过这个条件执行中,OUTPUT 面板里丢弃了 4 条结果,保留了 56 条结果。证明我们此次运行时,RSS 原本里包含了 4 条昨天的新闻。
实现要点:
-
添加Filter节点,设置条件
-
使用n8n表达式模式(Expression)动态获取当前日期
-
通过拖拽方式引用上游节点数据字段
技术细节:
-
$Today是n8n内置变量,自动转换为当前日期 -
表达式模式(
{{ }})支持JavaScript代码执行 -
固定模式(Fixed)则直接输出文本内容
3.3 版面筛选:多条件过滤
光明日报是一份很厚的报纸,但我日常只需要关注它的前几版,在我们使用的这个 RSS 地址里,它会将文章所处的报纸版面写进文章标题里。因此,我们需要再来一个 Filter 节点,过滤数据中不属于头几版的内容:
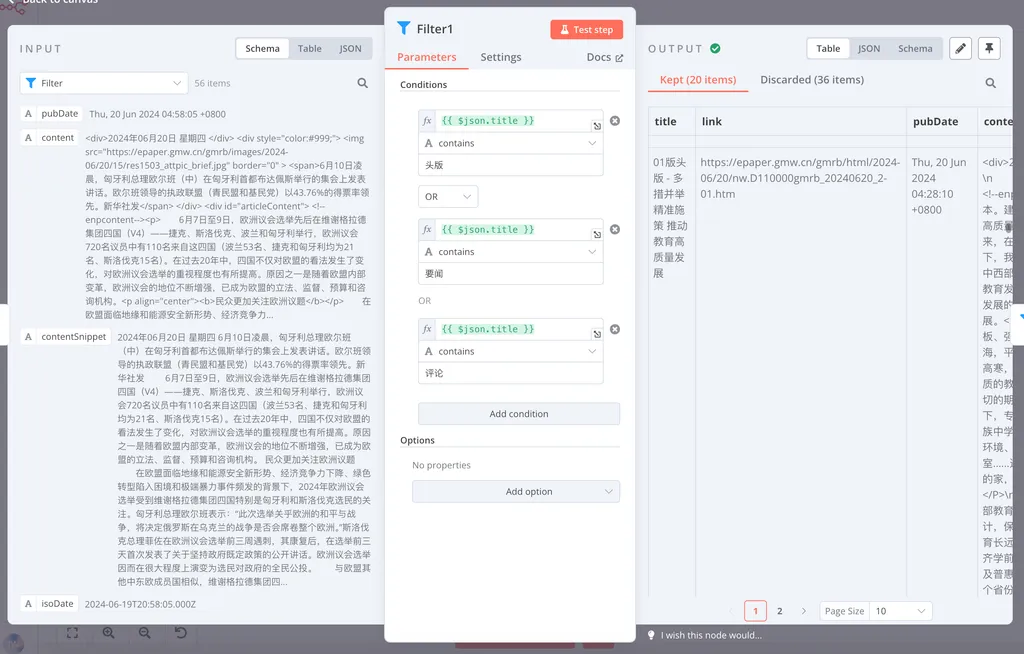
在这里,我添加了三个条件,他们之间用 or 的逻辑来链接。这意味着,只要文章标题中包含“头版”、“要闻”或“评论”的任意一个词,Filter 就会将它保留下来,剩下的丢弃。
到这一步,我们在 OUTPUT 面板中保留了 20 个数据,丢弃了 36 个数据。
业务规则:
-
只关注头版、要闻和评论版内容
-
通过标题中的版面标识进行筛选
Filter配置:
-
添加三个OR条件:
-
标题包含"头版"
-
标题包含"要闻"
-
标题包含"评论"
-
-
保留符合任一条件的文章
优化建议:
-
可考虑使用正则表达式实现更灵活的匹配
-
将过滤条件提取为变量,便于维护
3.4 内容类型筛选:精确过滤
光明日报还是一个内容丰富的报纸,它经常会有一些我不太关心的内容,比如文艺评论,比如图片摄影等等,我们还需要从文章中剔除这些类型。幸好,在我们使用的这个 RSS 地址里,它也会把报道类型写在标题里,于是,我就又添加了一个 Filter,它的配置如下:
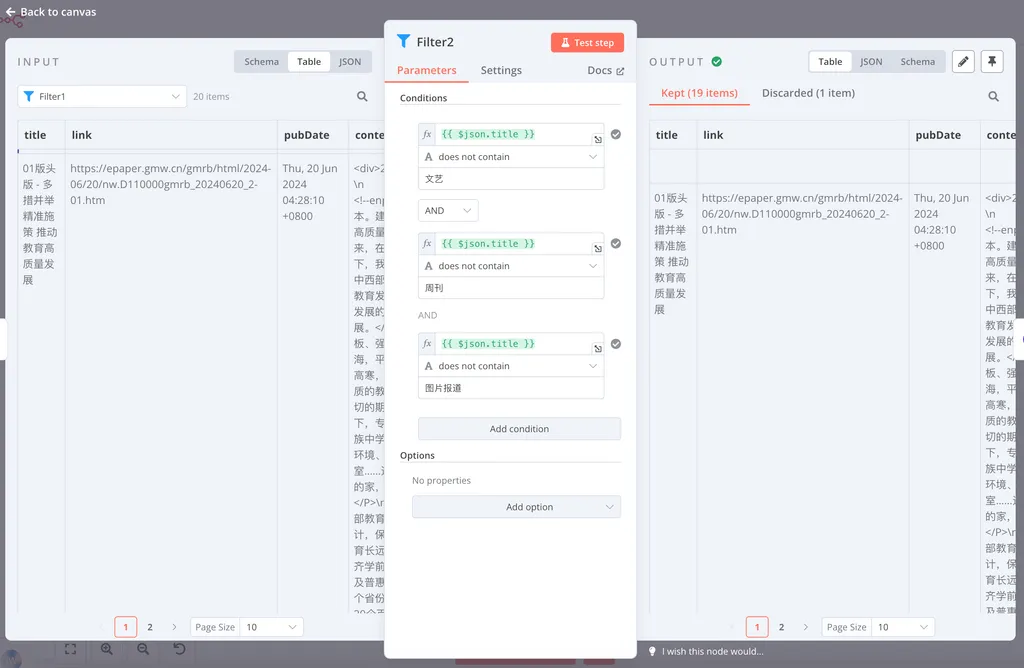
这已经是你第三次见到 Filter 节点了,我相信你已经可以从这张截图中理解我做了什么。
实现策略:
-
排除不关心的内容类型(如文艺评论、图片新闻等)
-
同样基于标题关键词进行过滤
注意事项:
-
过滤条件需根据实际需求动态调整
-
建议保留过滤日志,便于后续分析优化
3.5 网页全文获取:HTTP Request节点
如果是一般的 RSS,其实可以跳过这一步,包括这个光明日报的 RSS,它其实也在 RSS 里包含了文章全文。
但遗憾的是,这个 RSS 不包括作者,而我们想要对文章精准的分类,需要能知道文章的作者是谁。这时,我们就需要用 HTTP Request 节点,来帮助我们获取原始文章页面,并从 HTML 中提取作者:
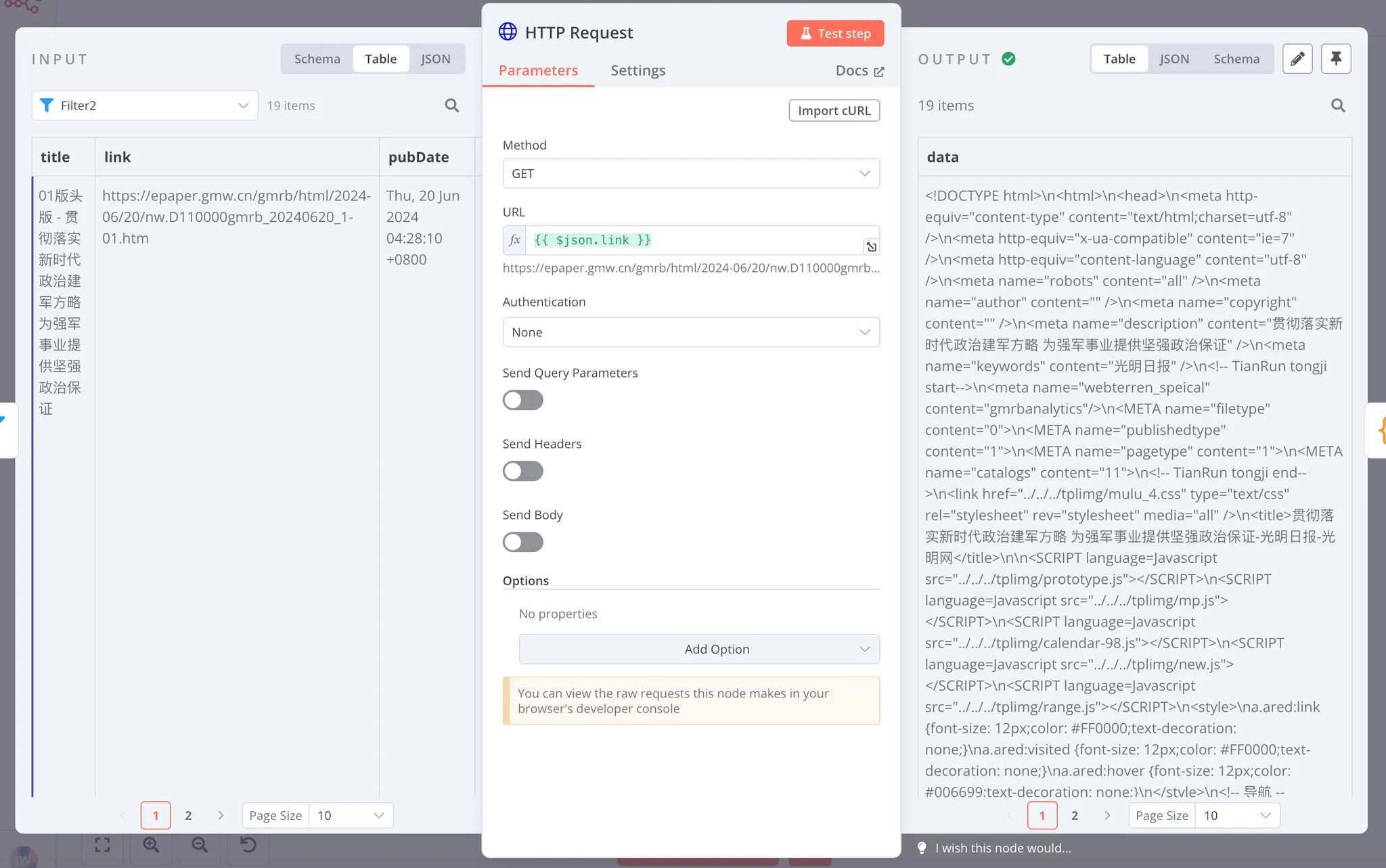
技术实现:
-
Method选择GET
-
URL动态获取:
{{ $node["Filter1"].json["link"] }} -
输出原始HTML内容
使用场景:
-
当RSS中缺少必要字段(如作者信息)时
-
需要获取完整正文内容时
HTTP Request 节点的作用是发起 HTTP 请求,它的作用有很多,但基础用法就是从一个 URL 中获得数据。在这种基础用法中,我们要选择它的 Method 为 Get。
然后,在 URL 参数中填入从 RSS 数据里活的的文章原始链接变量,这个节点的设置就完成了。
我们可以在 OUTPUT 中看到,与RSS 的结构化数据不同,我们发现它输出的是一个平文本,该文本就是 URL 所返回的网页 HTML 原文。
让我们进入下一步对 HTML 进行处理。
3.6 作者信息提取:Code节点实战
经过手工阅读 HTML,我们会发现在光明日报的网页上,它会在一个隐藏的地方标记文章作者,它被包裹在<founder-author>的 HTML 标签里:
<founder-author>梅常伟</founder-author>为了能够从每个页面的该标签中提取作者,我们需要使用 n8n 的 Code 节点。该节点用于实现那些 n8n 预设节点中不能实现的功能,它可以让你自己便携 JavaScript 或 Python 代码并运行。
我当然是不会写 JavaScript,因此我将问题抛给了 ChatGPT,我对它说:
我正在撰写一个 n8n 的 Workflow,需要从一个 HTML 网页中提取文章作者。文章作者被包裹在<founder-author>的 HTML 标签内。请帮我编写放在 Code 节点中的 JavaScript 代码,实现这一步骤。
ChatGPT 一般会给出详尽的指导,并给出代码:
const html = $node["RSS Feed Trigger"].json["data"]; // 假设 RSS Feed Trigger 节点输出了 HTML
const authorTagPattern = /<founder-author>\s*(.*?)\s*<\/founder-author>/s;
// 使用正则表达式提取标签内容
const matches = authorTagPattern.exec(html);
const authorContent = matches ? matches[1] : "Author not found"; // 检查是否找到匹配项
return {json: {author: authorContent}};可以看到,ChatGPT 生成的代码假定上一个节点是 RSS Feed Trigger,这与实际情况不符,所以我需要将其修改为:
const html = $node["HTTP Request"].json["data"]; // 假设 RSS Feed Trigger 节点输出了 HTML
const authorTagPattern = /<founder-author>\s*(.*?)\s*<\/founder-author>/s;
// 使用正则表达式提取标签内容
const matches = authorTagPattern.exec(html);
const authorContent = matches ? matches[1] : "Author not found"; // 检查是否找到匹配项
return {json: {author: authorContent}};然后进行测试运行,发现 Code 节点顺利运行,输出了所有有作者文章的作者:

调试技巧:
-
先在小样本上测试正则表达式
-
添加错误处理逻辑
-
记录提取失败的案例
3.7 硬规则分类:Switch节点应用
我们发现,所有官媒的“综述”这个类型的文章,都会在标题中包含“综述”二字。
因此,我们在对这类文章进行分类时,其实不用大语言模型参与。我们只需要用一个 if 或 Switch 节点就行了。这两个节点的区别:
| Switch | If |
| 可以进行多种结果的判断 | 只能进行两种结果的判断 |
| 判断结果可自定义变量,如“综述”、“非综述” | 判断结果只会输出 True 或 False |
在这一步,我们首先会发现上一步的 Code 输出里不带有此前的数据,因此在 Switch 节点的 Input 面板里没有文章标题了,这要怎么办呢?
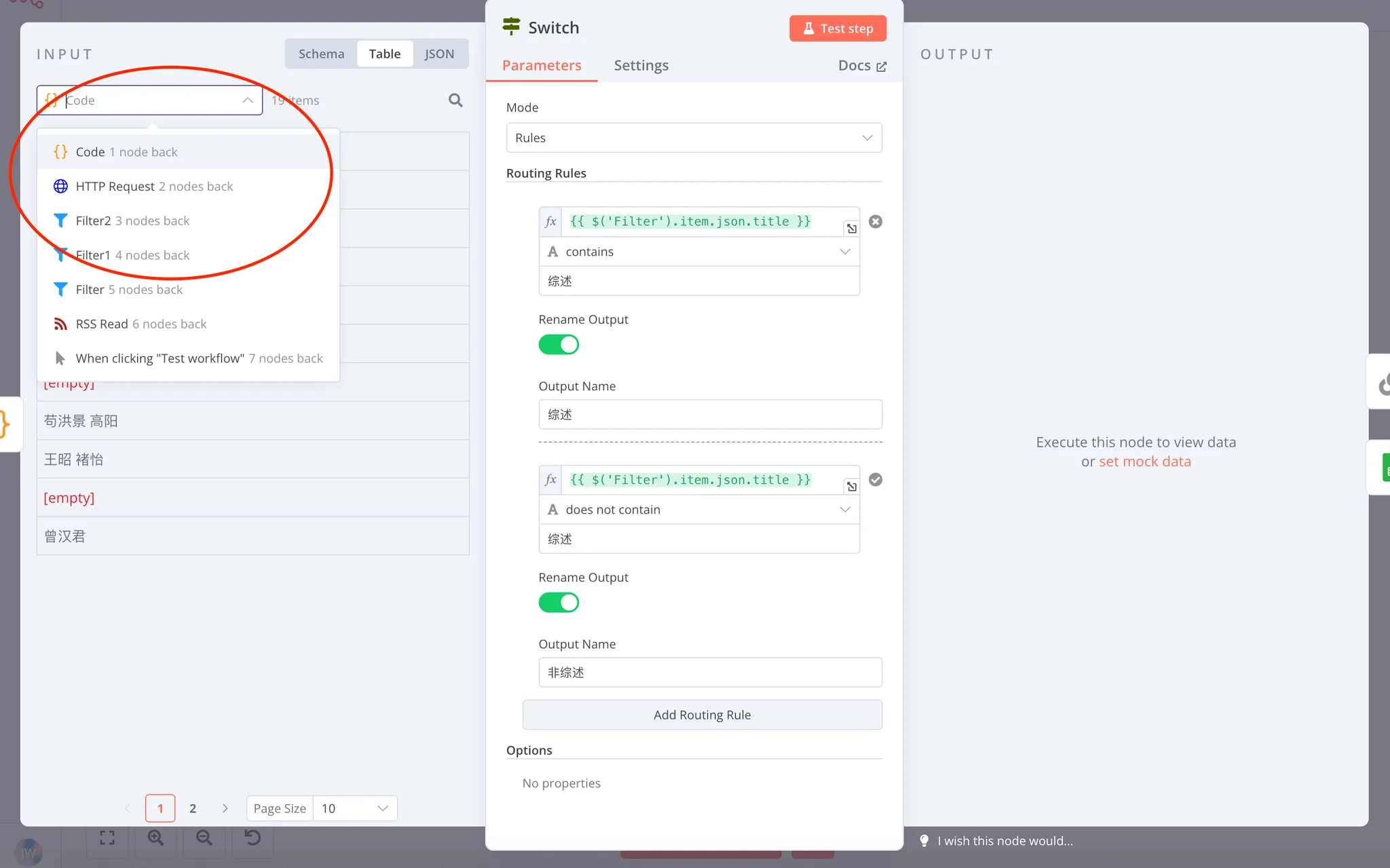
我们可以在 INPUT 面板的标题处,选择之前的节点 Filter。这时,我们就可以和之前一样,拖拽我们想要的标题属性进入 Routing Rules 里做判断了。
这里我选择了从 Filter 里读取 title 属性来做判断。但如果你还记得,我们在 Filter 1 和 Filter 2 里丢弃了不少不符合我们需求的条目。
但在 n8n 中,整个工作流里的数据,遵循隐式行列传递,这意味着当数据流抵达下游节点时,仅会以上游 1 个步骤的节点输出的数据为准进行执行。
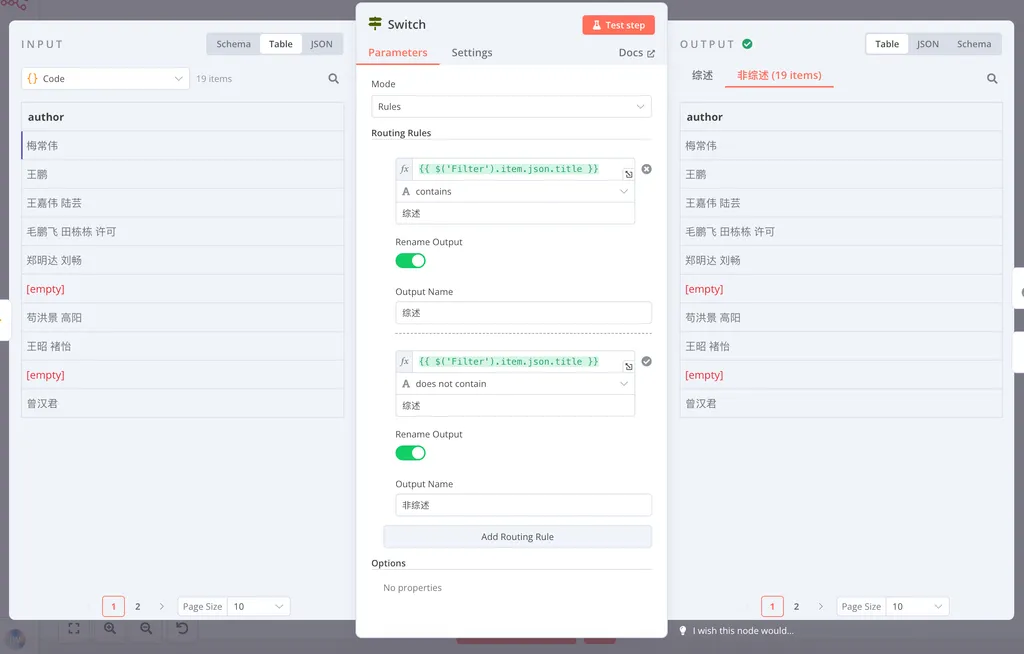
仍以本例做说明,Filter 节点里有 56 个条目,运行到 Switch 时,已经只剩 19 个条目了。此时,我从 Filter 里读取 title,它只会读取剩下的这 19 个条目的 title,不会把被丢弃的 37 个条目找回来。
并且,这 19 个条目的标题也是行列对齐的,你不用在意中间丢弃的是哪些行去做手工的对齐。
分类逻辑:
-
标题含"综述" → 直接归类为"综述"
-
其他 → 进入AI分类流程
节点选择:
-
Switch节点支持多条件分支
-
比If节点更灵活,可自定义输出分支
数据流说明:
-
n8n采用隐式行列传递机制
-
下游节点只能访问上游节点的输出数据
-
自动保持数据行对应关系
3.8 AI智能分类:Basic LLM Chain实践
接下来,我们开始接入 AI 了。
n8n 中内置了 LangChain 节点,它被称为 Advance AI,它能实现很多功能,在本例中我们使用的是最简单的功能,因此,我们要添加的是一个 Basic LLM Chain。这个节点顾名思义,就是最基础的接入大语言模型的节点。

这个节点的配置非常简单,它只有两个主要选项,一个是 Prompt 一个是 Text。
Prompt 有两个选项,一个是 Define below(在下方定义),一个是 Take from previous node automatically(从之前的节点获取)。在这里,我们要选择 Define below,这样 Text 参数就会出现。我在 Text 中填入了以下 Prompt:
Prompt工程:
你将扮演一个文章分类器,为以下文章进行分类。分类包括"评论"、"文件"和"其他"。
分类规则:
- 评论:
1. 含社论、评论等字眼
2. 评论员文章
3. 特定作者(列举20+官方笔名)
- 文件:
1. 政府文件全文/摘要
- 其他:
1. 不符合上述分类的内容
只回复分类名,不输出其他内容。
待分类内容:
标题:{{ $('Filter1').item.json.title }}
作者:{{ $('Code').item.json.author }}
正文:{{ $('Filter1').item.json.contentSnippet }}这段 Prompt 的作用顾名思义,前面是判断规则,最后通过 Javascripts 变量,引入每篇文章的标题、作者和正文。
如果你希望用来判断其他内容,自己去做 Prompt 调整就行。
n8n 的所有 AI 节点与一般节点不同,还至少需要一个额外的子节点来完成配置,也就是你需要选一个具体的模型。在这里,我给它挂上了 Google Gemini Chat Model(因为免费):
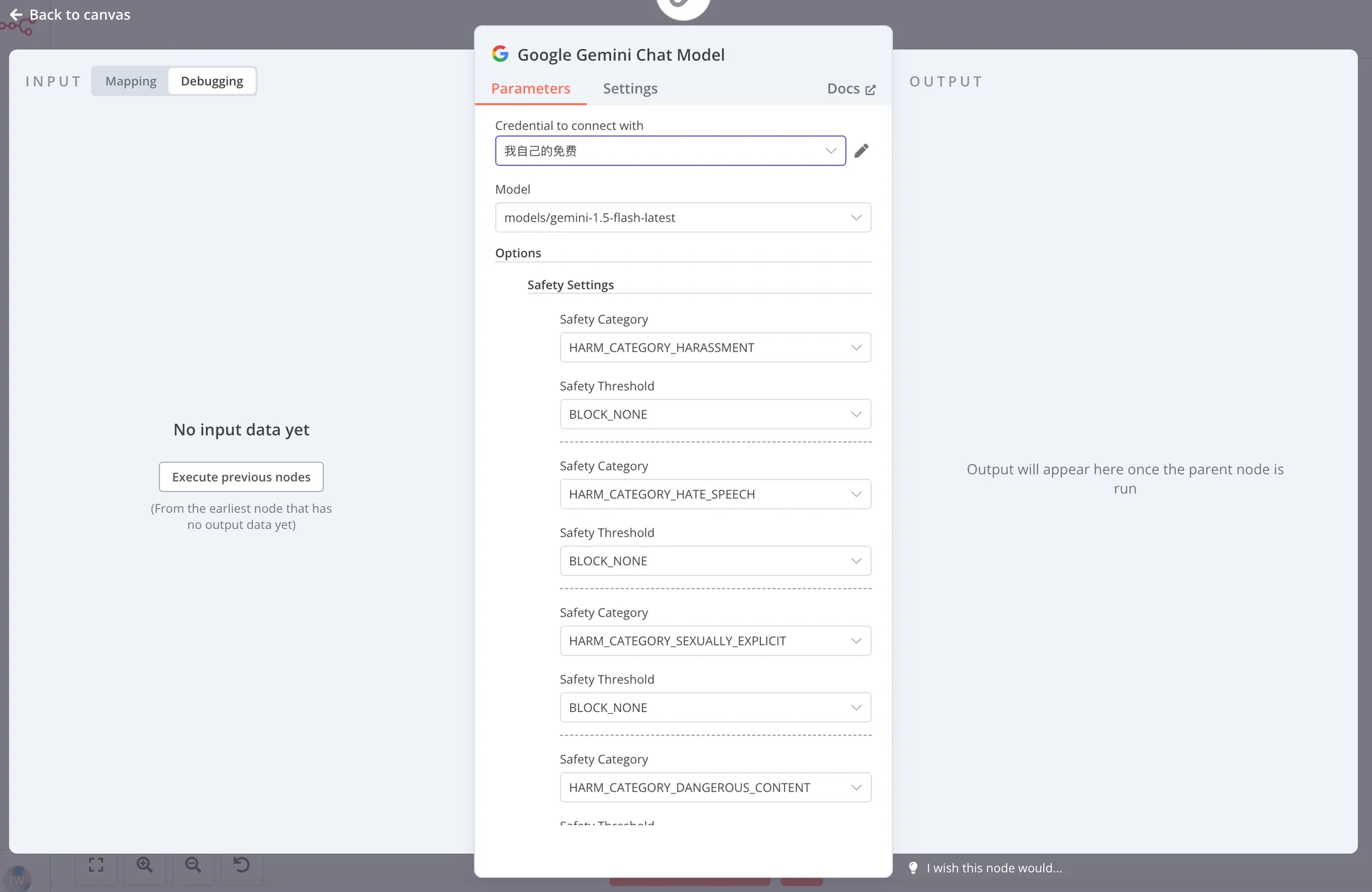
在子节点中,我们需要对模型进行单独的设置,首先是 Credential(凭据),也就是你自己的 Google Gemini API Key,这里不会教你如何申请,你可以自己去搜一下。
然后第二个是 Model 选项,在你配置完 Credential 后,它会自动刷新你可使用的模型版本,我这里选择了免费量大的 gemini-1.5-flashlatest。
根据 Google 对模型的定义,该模型还支持设置 Safety Settings,也就是 API 对一些敏感内容的拦截阈值,我们全都拉到完全不拦截,这个节点就完成啦:
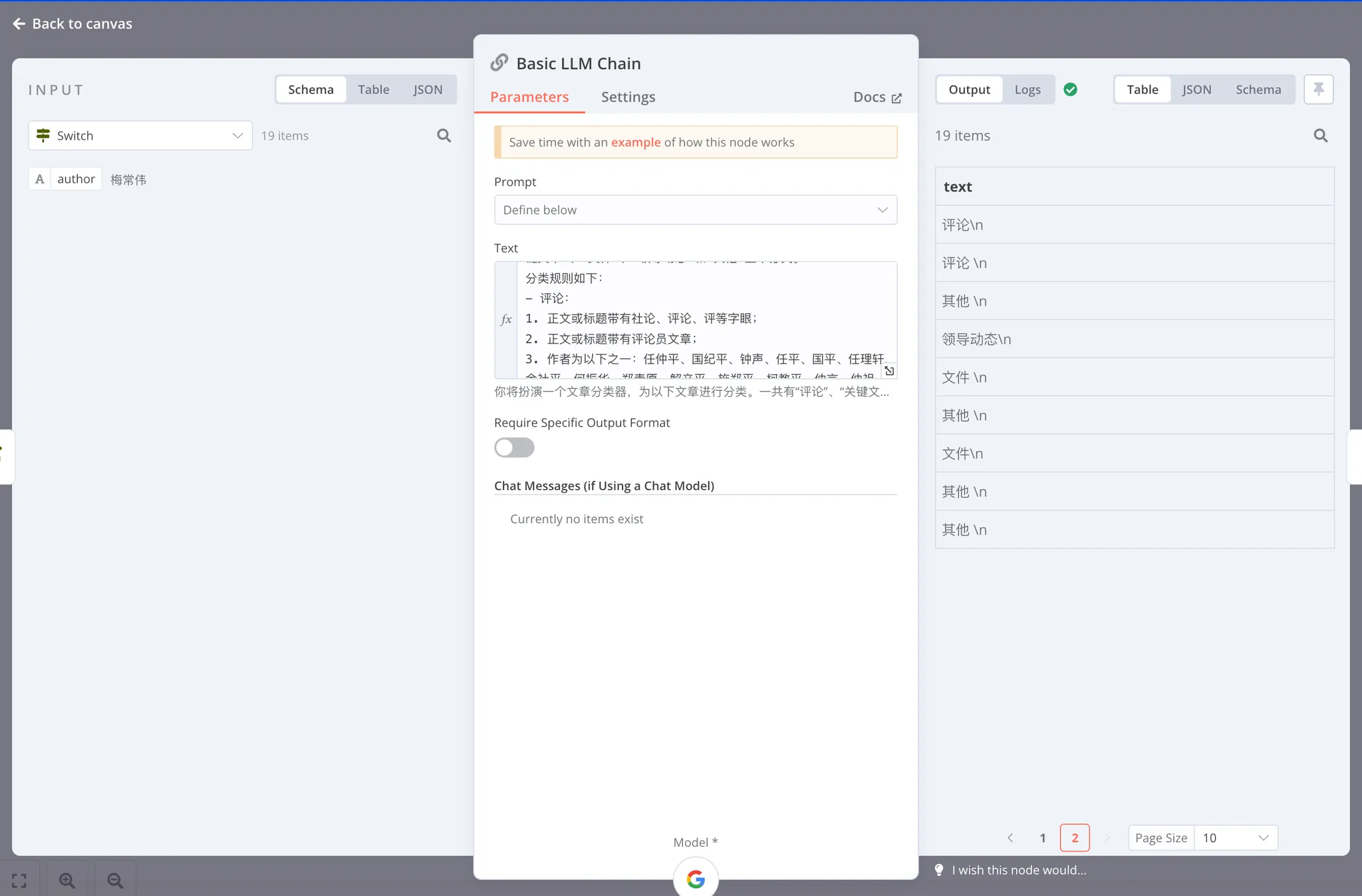
试运行一下,它的生成过程较慢,在运行的过程中编辑器里会显示目前处理到第几条数据,你应该会在 OUTPUT 看到一列输出文章类型的数据:
模型配置:
-
选择Google Gemini Chat Model
-
使用gemini-1.5-flash-latest版本
-
调整安全设置阈值
性能优化:
-
批量处理提高效率
-
设置合理的超时时间
-
记录分类结果置信度
3.9 数据存储:Google Sheets集成
其实到此为止,我们已经完成了文章分类筛选的工作,但是为了方便我们获取分拣结果,我们一般还是要把它导入到一个数据库里的,比如 notion,比如 Excel。
在这里,我选择了我常用的 Google Sheets,也就是 Google 的在线表格:
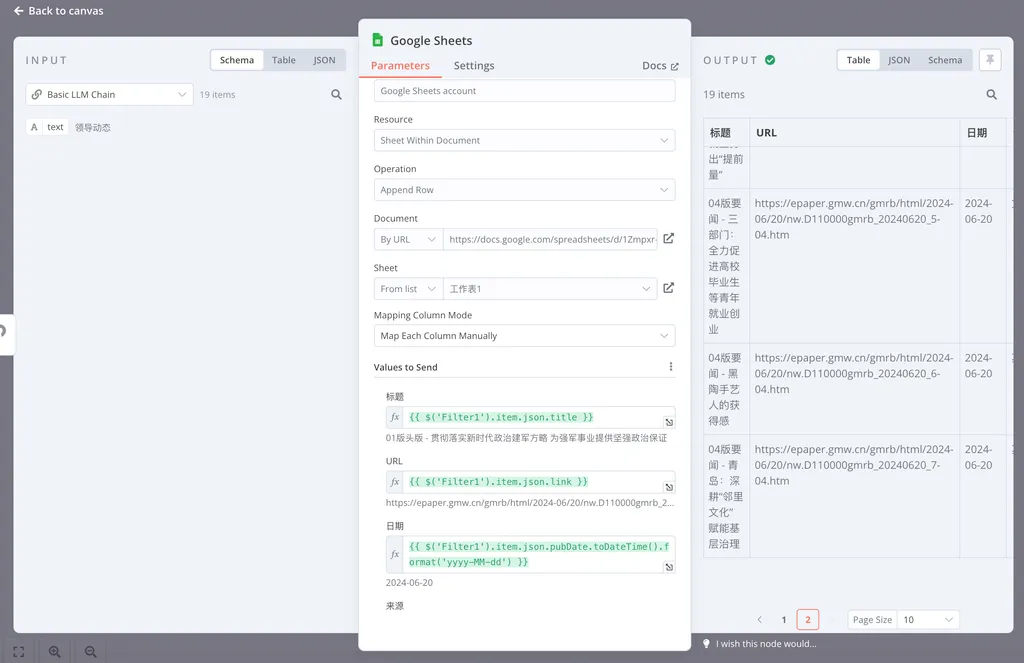
我们首先添加一个 Google Sheets 节点,还是先添加 Google Sheets 的 Credential,这个过程略去(你可以参考 n8n 官方节点)。
然后 Resource 选 Sheets Within Document。
Operation 选择 Append Row(添加行)。
Document 这里选择贴 By URL,然后去你的 Google Sheets 中将预先建立好的用于存储数据的表格地址复制过来贴到这里。
在贴完地址之后,你应该会在 Sheet 里看到对 Sheet 的选择(和 Excel 一样,每个工作簿有多个表格,你要选一个)。
最后,在 Mapping Column Mode 这里选择 Map Each Column Manually(手工映射列)。
到这里,如果一切正常,你可以在下方找到一个 Add Column to Send 的按钮,点击之后,它会列出表格里所有已经有的表头:
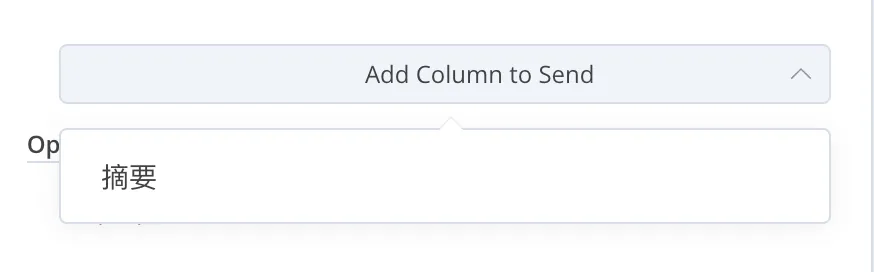
点击之后,就会在 Values to Send 里添加一个可以映射的配对:
这个时候,你就按照之前的思路,将各个变量拖进去就可以啦。我的表格里有这些列,它们在工作流里对应的变量分别是这样的:
| Sheets 里的列 | 工作流里的变量 | 解释 |
| 标题 | {{ $('Filter1').item.json.title }} | 从 Filter1 节点读取的标题 |
| URL | {{ $('Filter1').item.json.link }} | 从 Filter1 节点读取的原文地址 |
| 日期 | {{ $('Filter1').item.json.pubDate.toDateTime().format('yyyy-MM-dd') }} | 从 Filter1 节点读取的日期,进行日期格式化为“年-月-日” |
| 来源 | 光明日报要闻 | 写死的“光明日报来源” |
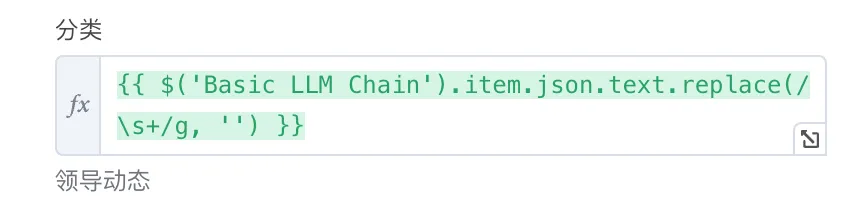
| 分类 | {{ $('Basic LLM Chain').item.json.text.replace(/\s+/g, '') }} | 从 Basic LLM Chain 读取的文章分类,去除 AI 可能输出的换行符 |
还记得吗?我们在第六步用 Switch 节点硬筛选了“综述”类文章,这意味着,你要在那里也添加一个 Google Sheets 节点,然后同样的配置。
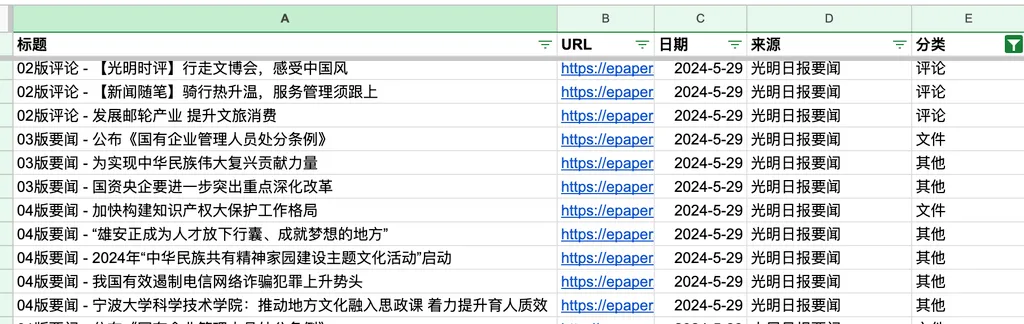
如果一切顺利的话,回到 Google Sheets,你会发现文章已经被成功分拣完成啦~
配置步骤:
-
设置Google Sheets凭据
-
选择操作类型为"Append Row"
-
手动映射字段:
-
标题:
{{ $('Filter1').item.json.title }} -
URL:
{{ $('Filter1').item.json.link }} -
日期:
{{ $('Filter1').item.json.pubDate.toDateTime().format('yyyy-MM-dd') }} -
分类:
{{ $('Basic LLM Chain').item.json.text.replace(/\s+/g, '') }}
-
数据格式化技巧:
-
日期标准化处理
-
去除多余空白字符
-
添加数据来源标识
4. 示例Workflow下载
使用说明:
-
在n8n中新建Workflow
-
选择"Import from File"
-
需重新配置:
-
Google Gemini API密钥
-
Google Sheets访问凭据
-
5. 扩展应用场景
5.1 RSS内容聚合处理
-
将多个RSS源合并处理
-
统一分类标准
-
建立个人知识库
5.2 内容过滤优化
-
基于关键词/正则的精确过滤
-
结合用户反馈持续优化规则
-
建立黑白名单机制
5.3 多平台集成方案
-
输出到Notion/Obsidian
-
生成每日摘要报告
-
对接社交媒体自动分享
6. 总结与展望
本方案展示了如何将传统RSS阅读与现代AI技术结合,实现内容的高效分类管理。关键在于:
-
结构化思维:将复杂流程分解为可管理的节点
-
混合判断逻辑:结合规则引擎与AI模型
-
灵活扩展性:便于适配不同数据源和业务需求
官方资源推荐:
未来可考虑加入:
-
用户偏好学习
-
自动摘要生成
-
多语言支持
-
移动端通知
希望这个案例能为你构建自己的智能信息处理系统提供启发!有用的话记得点赞收藏噜!


















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









