







 本文介绍了决策树的基础知识,包括预测函数、优化函数和训练方法。决策树模型通过二叉树结构对数据进行划分,以达到分类或回归的目的。优化函数如纯度(Gini Impurity)和信息熵用于衡量数据集的纯净度。训练过程中,通过选择最优特征划分以最小化损失函数。防止过拟合的方法包括限制树的深度和设定最小样本数。对于回归问题,损失函数和预测值处理方式有所不同。
本文介绍了决策树的基础知识,包括预测函数、优化函数和训练方法。决策树模型通过二叉树结构对数据进行划分,以达到分类或回归的目的。优化函数如纯度(Gini Impurity)和信息熵用于衡量数据集的纯净度。训练过程中,通过选择最优特征划分以最小化损失函数。防止过拟合的方法包括限制树的深度和设定最小样本数。对于回归问题,损失函数和预测值处理方式有所不同。
//个人学习记录,如有错误请指正
//大部分图片公式来源于《hand on machine learning with scikit-learn and tensorflow》
//部分公式来源于互联网
决策树是一种偏向分类的技术,但是它同时也可以用来进行回归。
预测函数
我们都知道二叉树,那决策树实际上就与二叉树类似,我们的模型在形态上是一颗二叉树,树的每个内部节点都会根据个特征对数据集进行划分,例如特征值满足特定标准的进入左子树,不满足的进入右子树,这样从根开始,整个数据集就不断被划分为小数据集,直到叶结点,每个叶结点都会指定一个特定的预测值,这就是所谓的决策树模型,它非常直观,且容易理解。
优化函数
因为我们会在在叶结点上给予特定的预测,所以我们期望被分配到特定叶结点的实例都具有相同的真实值。也就是说,当每一个节点对数据集根据特征值进行划分时,我们希望被划分出来的两部分在被预测值上都尽量“纯净”,这样我们的预测才最有效。因此首先我们需要对划分的纯净度的度量。这里我们有两种度量方式,一种是纯度(giniimpurity),一种是信息熵(entropy)。
纯度:

纯度等于1减去数据集中各类数据占比的平方的和,可见如果数据集中实例类别越少,或者某个类别占比更多,那么纯度数值就会越低,表示数据集越纯。当数据集只有一类数据时,纯度会减少为0,是最纯的状态。
信息熵:

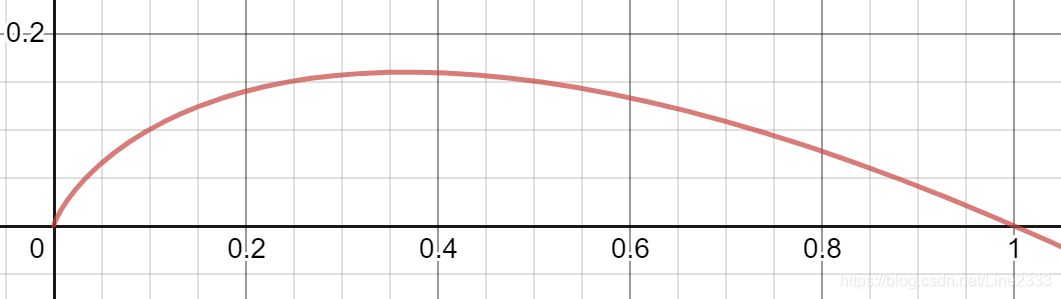
这个图像是f(x)=-plogp 在0-1范围内的图像,我们可以看出,p越靠近0或者1,函数值越小。再看信息熵的公式,我们发现同样的,当类别越少,单个类别占比越大,信息熵越小,信息熵的值也就越小。
因此这两个公式都可以用来作为决策树的优化函数的基础,因为他们具有共同的特点:数据集越纯,值越小。但是两个指标在实践中也稍有不同,纯度更倾向于将大数量的类别划分出来,而信息熵则相比更平衡一些。
当然这两个并不能直接作为优化函数,而需要进行如下组合,得到CART损失函数。也就是说我们的目标是,我们希望在经过根据某个特征值划分后,两个节点的数据集的纯度(或信息熵)加权最小。

训练方法
决策树的训练方法就可以比较简单粗暴了,在每一个节点时,针对每一个特征划分方法进行一次划分,并且计算损失函数,最后选择损失函数最小的特征划分方法作为该节点划分方法即可。
这里有一点需要注意,我们需要避免决策树的过拟合,我们有几种方法,第一,可以限制决策树深度,第二可以在训练时规定数据集小于一定数量是就停止继续划分。
回归
前面我们主要的例子都是进行分类,而我们如何进行回归呢?这里主要有两个方面不同,第一损失函数,对此,我们可以采用以下式子作为损失函数。

第二在预测值上,我们可以将预测值进行一定的离散化,这样可以简化训练,并且避免过拟合。

















 2942
2942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









