



文章目录
最近在研究qwen3-8b本地部署,只有一张24GB的3090,好心酸,记录一下。
一、环境配置
(一)先配置python环境
先前调试过vllm0.4.1的环境,跑通义千问有报错…于是我又努力配了一套vllm0.9.1的(狗头)
安装顺序建议:先装vllm,它自带cpu的torch,若单纯安装vllm而不安装它的依赖,容易少包
之后卸载cpu的torch,装适配cuda的
最后看下transformers等依赖的版本是否过高,适当降降级,可以省去不少报错
虽然方法很麻烦,但是很好用,毕竟是主包含泪调出来的
cmake==4.1.0
modelscope==1.30.0
numpy==2.2.6
openai==2.2.0
pandas==1.5.3
torch==2.7.0+cu118
transformers==4.51.3
vllm==0.9.1
vllm_nccl_cu12==2.18.1.0.4.0
xformers==0.0.30
如果想知道其它未提到的依赖及其版本可以私信问我鸭~ (仅限vllm0.4.1和0.9.1的环境)
(二)再配置llama.cpp
教程参考博客
1、安装编译工具链 (Ubuntu系统):
sudo apt install build-essential
2、克隆仓库并编译,可选择cpu和gpu编译,此处选gpu
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build # CPU执行这条
cmake -B build -DGGML_CUDA=ON # GPU执行这条
cmake --build build --config Release
在build文件夹下生成文件如图
3、若想使用 python -m llama_cpp.server ...的命令部署模型,还需要安装llama-cpp-python依赖。
export LLAMA_CUDA=1
export FORCE_CMAKE=1
export CMAKE_ARGS="-DLLAMA_CUDA=on" # GPU版本
pip install --force-reinstall --no-cache-dir llama-cpp-python
可能遇到的问题
- 步骤2:执行cmake -B build报错如下, 即
在编译时缺少curl库,导致cmake配置失败
/llama.cpp$ cmake -B build
CMAKE_BUILD_TYPE=Release
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- GGML_SYSTEM_ARCH: x86
-- Including CPU backend
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
-- ggml version: 0.9.4
-- ggml commit: 7a50cf38
-- Could NOT find CURL (missing: CURL_LIBRARY CURL_INCLUDE_DIR)
CMake Error at common/CMakeLists.txt:86 (message):
Could NOT find CURL. Hint: to disable this feature, set -DLLAMA_CURL=OFF
-- Configuring incomplete, errors occurred!
解决方案: 安装相关依赖 重新编译
sudo apt install libcurl4-openssl-dev
cmake -B build -DCMAKE_BUILD_TYPE=Release # 或者重新执行步骤2的后两行
二、Qwen3-8B模型部署
我已经被这个模型只需要4G就能跑,你怎么跑起来要20G质疑麻了,不要这么狠心的对待一个大模型入门新手啊喂!
(一)模型下载
魔塔的snapshot_download方式,把要下载的模型/版本(or仓库分支)放到文件里读取,代码使用多线程下载,批量下载不要太爽嘿嘿,而且有断点下载,不怕程序中断导致从头下载了
这里我遇到中断程序后相关目录会生成lock文件不让我继续下载的问题,检查了一下lock文件可以安全删除,删了继续下,问题不大,一般单个下载不会遇到,批量可以注意一下
from modelscope.hub.snapshot_download import snapshot_download
(二)模型部署
首先激活虚拟环境,conda activate demo_test,可以顺便cd到代码文件夹(虽然没什么卵用,哈哈哈)
如果部署时遇到---model xxx 未找到命令这种报错,检查是否每行都有换行符,以及是否有多余空格
llama.cpp部署命令
通过python3 -m llama_cpp.server --help查看各参数。
对于gguf模型,采用llama.cpp(其实也算ollama)进行部署
python -m llama_cpp.server \
--model /home/.../Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf \
--model_alias qwen3-8b-q5 \
--host ... \
--port 8081 \
--n_gpu_layers -1 \
--n_ctx 40960
--chat_format chatml
参数解析
--model # 本地模型路径
--model_alias # 模型名称,调用时可根据模型名称定位到具体模型(好像没啥用)
--host # 部署ip
--port 8081 # 接口
--n_gpu_layers -1 # -1是将全部加载至GPU,如果资源不够可以设置20或者99等,溢出来的会用cpu加载
--n_ctx 40960 # 长上下文最大长度,资源不够可以减小
--chat_format chatml # 聊天模版
执行llama部署命令可能报错:系统中libstdc++.so.6缺少GLIBCXX_3.4.30 解决方案:
# 查看当前虚拟虚拟环境中是否有GLIBCXX_3.4.30 (修改具体路径,将demo_test换为具体虚拟环境名称)
strings /home/../anaconda3/envs/demo_test/lib/libstdc++.so.6 | grep GLIBCXX_3.4.30
# 若查找后没有输出,即系统中没有,需要升级安装,安装后再strings..查看
conda install -c conda-forge libstdcxx-ng
vllm部署命令
我把vllm从0.4.1升级到0.9.1之后,起服务的速度变慢了,它要等个1-2分钟才能把服务起好,不造为啥,可能变强了也变秃了吧~
python -m vllm.entrypoints.openai.api_server \
--model /home/.../Qwen3-8B-AWQ \
--served-model-name qwen3-8b-awq \
--quantization awq \
--host ... \
--port 8081 \
--gpu-memory-utilization 0.8 \
--max-num-seqs 8 \
--max-model-len 8192 \
--tensor-parallel-size 1 \
--trust-remote-code
参数解析
# 开头的openai.api_server不要忘了写openai
--model # /home/.../Qwen3-8B-AWQ \ # 这里写至模型所在文件夹即可
--served-model-name qwen3-8b-awq \ # 模型名称
--host ... \
--port ... \
--quantization awq \ # ----若是量化模型,这行必须写,例如gptq、int8、int4...(?)其它的可以不写,具体要自己百度~
--gpu-memory-utilization 0.7 \ # gpu显存的利用率上限(取值0~1),合理设置避免OOM
--max-num-seqs 8 \ # 最多同时处理n个推理请求,我这小卡也就设置个2了
--max-model-len 8192 \ # 最大上下文长度,token
--tensor-parallel-size 1 \ # 指定张量并行的gpu数量
--trust-remote-code
(三)运行显存情况
- vllm方式运行
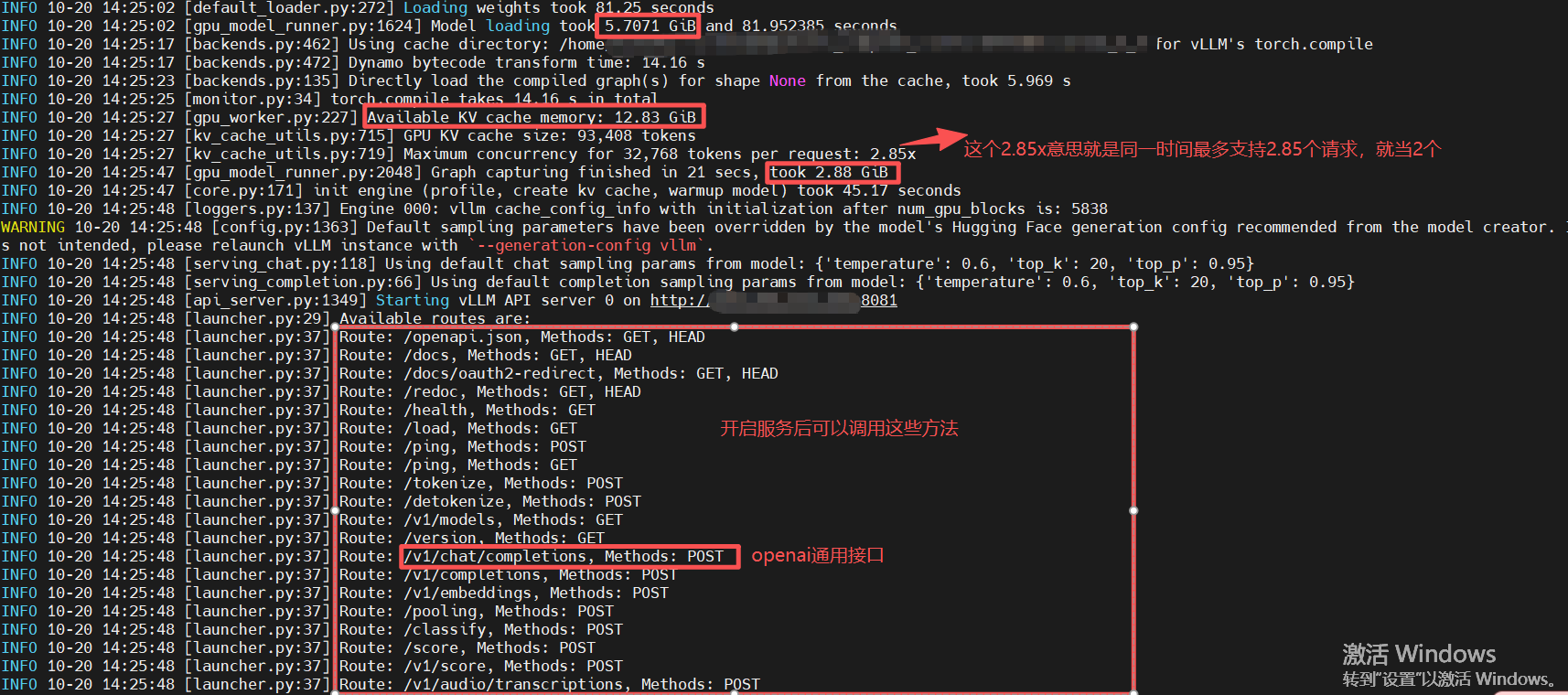
Qwen3-8B-AWQ量化模型,设置的长上下文32768,我的显卡直接噌到22GB
模型基础显存5.7G + kv缓存12.83G + 图形2.88G ≈ 22G oh…(小岳岳:我的天哪.GIF)
- llama.cpp方式运行
Qwen3-8B-GGUF量化模型Q5_K_M.gguf,设置的长上下文40960,只需要11.5G左右,是AWQ的一半…最大的Q8_0在相同参数下也只需要17.5G左右的显存。

唉,幻视甲方了,谁不想用最少的资源跑最牛逼的模型?要是我这24GB能把豆包部署上就好了(开个玩笑…)
三、模型测试
思考模式软开关
我是用linux命令部署的模型,没有在代码里预加载之类的,只能用软开关了
提示词末尾软开关,空格+思考模式 .... /think,... /no_think,一定要有空格o_o
用例展示
其实模型运行时间还挺不好说的,提示词短,问的简单,一两秒就出结果;提示词长了,复杂了,可能要十多秒;数据量大了,运行一两分钟也是有的,所以很讨厌被问 “你这个模型要运行多长时间?”
哪怕豆包关闭深度思考模式,不使用流式输出,运行结果也需要十多秒吧(?)我太难了
OK写到这本来想展示个postman调用,李奶奶的,postman天天加载中什么劲鸭
有说extra_body无效的,我没管一直带着了。好了postman老实了,展示下:
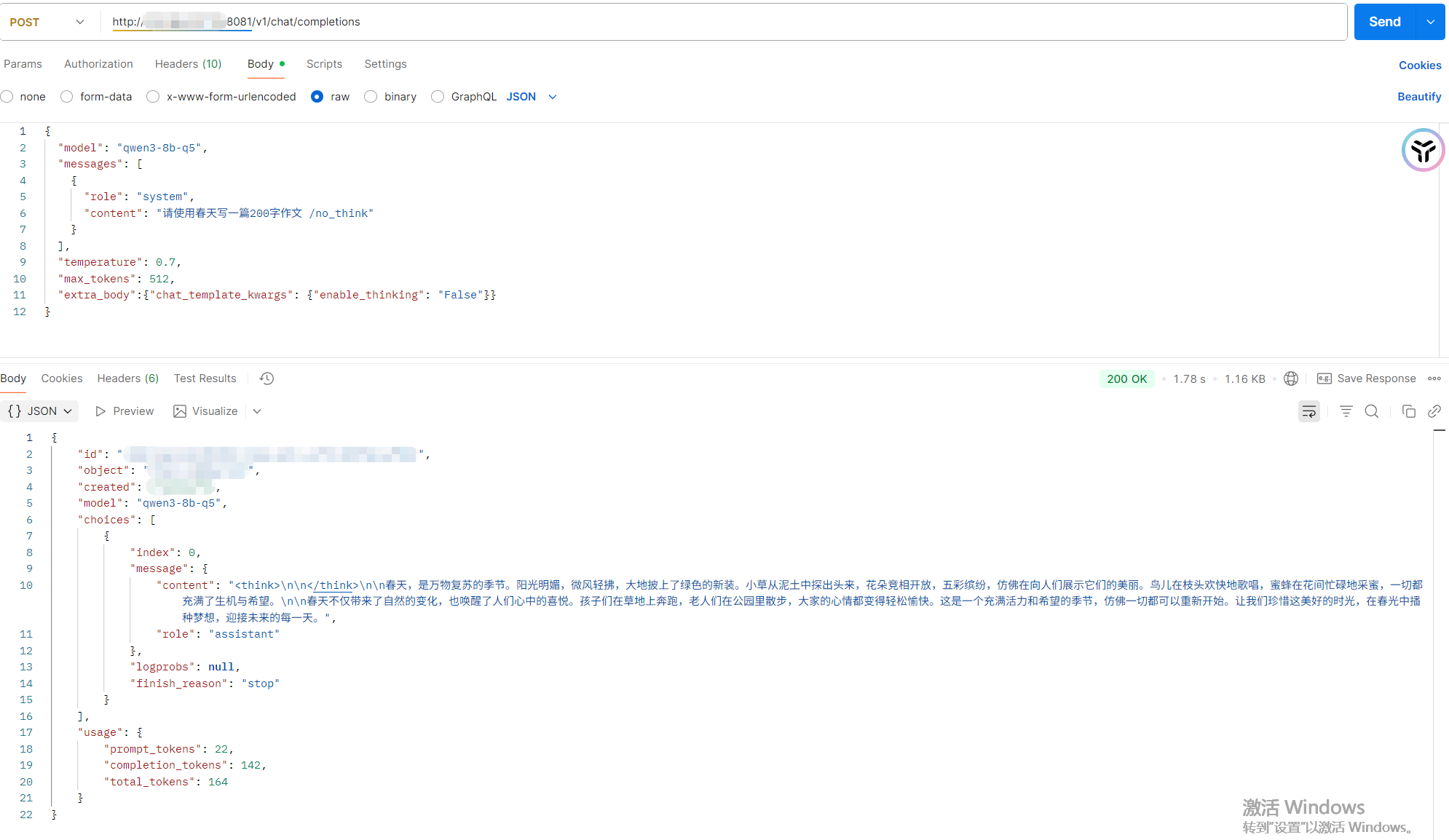
对于AWQ测试的时候没遇到过非思考模式下依旧输出空白think块的问题,但是GGUF就有,俺也不知道咋整,烦人

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









