







| 论文标题 | MobileNetV2: Inverted Residuals and Linear Bottlenecks |
|---|---|
| 论文作者 | Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen |
| 发表日期 | 2018年01月01日 |
| GB引用 | > Sandler Mark, Howard Andrew, Zhu Menglong, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[J]. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520. |
| DOI | 10.1109/CVPR.2018.00474 |
摘要
本文介绍了MobileNetV2,一种新的移动架构,改进了多个任务和基准上的移动模型性能。MobileNetV2采用倒残差结构,其中捷径连接位于薄瓶颈层之间。中间扩展层使用轻量深度卷积来过滤特征。实验表明,去除瓶颈层中的非线性可以提高性能。MobileNetV2在ImageNet分类、COCO目标检测和PASCAL VOC图像分割任务上进行了评估,并展示了其在准确性和计算复杂度之间的权衡。该网络还用于构建轻量级的目标检测框架SSDLite和简化版的DeepLabv3,称为MobileDeepLabv3。
论文概述
本论文提出了一种新型的移动端神经网络架构MobileNetV2,旨在提升移动模型在多个任务和基准测试中的表现,同时适应不同的模型规模。MobileNetV2的核心创新在于“反向残差结构”,该结构通过在瓶颈层之间建立快捷连接,使模型在保持较低计算量和内存占用的情况下,仍然能实现高效的特征提取。
主要结论:
- 反向残差网络:MobileNetV2提出的反向残差模块通过扩展层和线性瓶颈层的组合,促进了信息的有效流动,减少了计算需求。模块中使用的深度可分离卷积技术显著降低了计算复杂度,并在多个基准测试中表现出色。
- 线性瓶颈的应用:在瓶颈层中去除非线性激活函数,可以保留更多信息,从而增强了模型的表现。这种设计理念表明,非线性在计算复杂度和信息保持之间存在权衡。
- 移动友好的对象检测框架:论文中还引入了名为SSDLite的框架,优化了传统单次检测器SSD,使其在移动设备上效率更高。
- 性能和效率的平衡:MobileNetV2显著降低了参数数量和计算操作的复杂性,模型大小约为MobileNetV1的一半,从而实现了更快的推理速度和更高的准确度。
研究问题
如何在保持准确性的前提下,设计一种新的神经网络架构,使其更适合移动和资源受限的环境,并且能够显著减少所需的计算操作和内存需求?
研究方法
实验研究: 本文描述了一种新的移动架构MobileNetV2,并通过实验证明了该架构在多个任务和基准测试中改进了移动模型的性能。同时,作者通过实验展示了如何利用SSDLite框架将这些移动模型应用于物体检测,并通过减少DeepLabv3的形式构建了MobileDeepLabv3用于移动语义分割。
比较研究: 文中通过对比不同的模型设计,如MobileNetV1、ShuffleNet以及NasNet-A等,来评估MobileNetV2的性能。实验结果显示,MobileNetV2在准确性和计算复杂度之间找到了更好的平衡。
混合方法研究: MobileNetV2结合了多种技术,包括深度可分离卷积、线性瓶颈层和倒残差结构。这种混合方法使得模型既能在计算资源有限的环境下保持高效,又能达到较好的性能表现。
系统分析: 文中讨论了网络内部操作的信息流解释,特别关注了瓶颈层的设计如何影响网络的表达能力和容量。这种分析为未来研究提供了重要的方向,即探索网络的表达能力与其容量之间的分离。
研究思路
理论框架
- 反向残差结构:MobileNetV2的核心是反向残差块与线性瓶颈的组合。这种结构允许信息在网络中更有效地传递,同时保持较低的计算需求。
- 深度可分离卷积:该模型依赖于深度可分离卷积,将常规卷积操作分解为逐通道的卷积和逐点(1×1)卷积。这种分解显著减少了计算量和内存占用。
- 输入/输出域的解耦:论文提出将输入输出域与变换的表达能力解耦,以便于对模型进行更深入的分析和理解。
研究方法
- 网络设计:
- 采用反向残差块,每个块首先通过扩展卷积(以高维度表示输入),然后使用轻量级的深度可分离卷积进行特征过滤,最后再用线性卷积将特征投影回低维度。
- 在每个反向残差块中加入快捷连接,以增强梯度的传播能力,从而提高模型的训练效果。 - 模型训练与评估:
- 使用标准的图像分类(ImageNet)、目标检测(COCO)、图像分割(PASCAL VOC)等数据集进行模型的训练与评估。
- 采用各种实验设置,如不同的输入分辨率和宽度乘数,以探讨模型在准确性和计算复杂度之间的权衡。 - 对象检测与分割:
- 介绍了名为SSDLite的一个轻量级目标检测架构,该架构尽可能替换标准卷积为深度可分离卷积,提高效率。
- 针对移动语义分割任务,提出了一个基于MobileNetV2的简化版DeepLabv3模型。
线性瓶颈层
考虑一个由 n n n个层组成的深度神经网络,每个层 L i L_i Li都有一个具有维度 h i × w i × d i h_i \times w_i \times d_i hi×wi×di的激活张量。在本节中,我们将讨论这些激活张量的基本属性,我们将把它们视为具有 d i d_i di维度的 h i × w i h_i \times w_i hi×wi“像素”。非正式地讲,对于一组实数图像输入,我们说所有层的激活集合(对于任何层 L i L_i Li)形成一个“感兴趣的流形”。人们长期以来一直认为,在神经网络中的感兴趣流形可以嵌入到低维子空间中。换句话说,当我们查看深层卷积层的所有单独的 d d d轴像素时,编码在这些值中的信息实际上位于某个流形上,该流形进而可嵌入到低维子空间中(请注意,流形的维度与可以通过线性变换嵌入的子空间的维度不同)。
乍一看,可以通过简单地降低层的维度来捕捉并利用这种事实,从而降低操作空间的维度。MobileNetV1 [27] 成功地利用了这一优势,通过一个宽度乘数参数,在计算效率和准确率之间进行了有效的权衡,并将其纳入了其他网络中高效的模型设计[20]。按照这个直觉,宽度乘数方法允许我们降低激活空间的维度,直到感兴趣的多重集覆盖整个空间。然而,当我们回想起深度卷积神经网络实际上具有非线性坐标变换(如ReLU)时,这种直观想法就失效了。例如,当应用到一维空间的一条直线时,ReLU会产生一条射线,而在RN空间中,则通常会产生一个有 n n n个关节的部分线性曲线。
可以看出,通常如果一个层变换 R e L U ( B x ) ReLU(Bx) ReLU(Bx)的结果具有非零体积 S S S,那么映射到内部 S S S的点是通过输入的线性变换 B B B获得的,这表明对应于全维度输出的输入空间部分,仅限于线性变换。换句话说,深度网络只有在输出域的非零体积部分上具有线性分类器的能力。 请参阅补充材料以获取更正式的陈述。
另一方面,当 RELU 压缩通道时,它在该通道中不可避免地丢失信息。然而,如果我们有很多通道,并且激活流形中有结构,那么信息可能仍然保留在其他通道中。在补充材料中,我们展示了如果输入流形可以嵌入到一个显著低维的激活空间子空间中,则 RELU 变换会在可表达函数集合中引入所需的复杂性,同时保留信息。

总之,我们强调了两个性质,它们表明感兴趣的流形应该位于高维激活空间的一个低维子空间中:
1. 如果感兴趣的流形在 ReLU 变换后仍保持非零体积,则它对应于线性变换。
2. ReLU能够完整地保留关于输入流形的信息,但前提是输入流形位于输入空间的一个低维子空间中。
这两种见解为我们优化现有的神经架构提供了经验上的线索:假设感兴趣的流形是低维的,我们可以通过在卷积块中插入线性瓶颈层来捕获它。实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏太多信息。通过实验证明,在瓶颈中使用非线性层确实会使性能下降几个百分点,进一步验证了我们的假设3。需要注意的是,类似的结果也出现在 [29] 中,其中传统的残差块输入中的非线性被移除,并且这导致在 CIFAR 数据集上取得了更好的性能。在本文剩余部分,我们将使用瓶颈卷积。 我们将输入瓶颈大小与内核大小之比称为扩展比率。
反向残差块
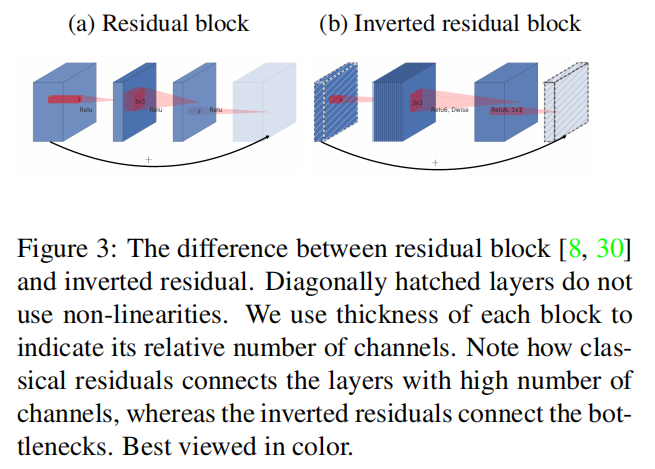
瓶颈块类似于残差块,其中每个块包含输入,然后是几个瓶颈,最后是扩展[8]。然而,由于直观地认为瓶颈实际上包含了所有必要的信息,而扩展层仅仅是对张量进行非线性变换的一种实现细节,因此我们直接在瓶颈之间使用捷径。图3展示了设计之间的差异。插入捷径的动机与经典残差连接的动机相似:我们希望提高梯度在乘法层之间传播的能力。然而,倒置的设计在内存效率方面要高得多(见第5节),并且在我们的实验中表现得稍微好一些。
瓶颈卷积的时间复杂度和参数数量。 基本实现结构如表 1 所示。对于大小为 h × w h \times w h×w的块,扩张因子 t t t和内核大小 k k k, d ′ d^{\prime}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3619
3619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











