







 本文分析了某教育平台的用户活跃度、课程推荐策略和用户流失情况。用户登录数据显示,广东是登录最频繁的省份,工作日用户活跃度高于非工作日,且用户登录集中在8点至22点。用户流失率为30.49%,建议针对不同活跃度用户采取不同的服务策略。在课程推荐方面,统计了最受欢迎的前10门课程,提出基于物品的协同过滤算法为高学习进度用户推荐课程。
本文分析了某教育平台的用户活跃度、课程推荐策略和用户流失情况。用户登录数据显示,广东是登录最频繁的省份,工作日用户活跃度高于非工作日,且用户登录集中在8点至22点。用户流失率为30.49%,建议针对不同活跃度用户采取不同的服务策略。在课程推荐方面,统计了最受欢迎的前10门课程,提出基于物品的协同过滤算法为高学习进度用户推荐课程。
一、 背景
近年来,随着互联网与通信技术的高速发展,学习资源的建设与共享呈现出
新的发展趋势,各种网课、慕课、直播课等层出不穷,各种在线教育平台和学习
应用纷纷涌现。尤其是 2020 年春季学期,受新冠疫情影响,在教育部“停课不
停学”的要求下,网络平台成为“互联网+教育”成果的重要展示阵地。因此,
如何根据教育平台的线上用户信息和学习信息,通过数据分析为教育平台和用户
提供精准的课程推荐服务就成为线上教育的热点问题。
提供了某教育平台近两年的运营数据,希望根据这些数据,为平台制定综合的线上课程推荐策略,以便更好地服务线上用户。
二、 目标
1. 分析平台用户的活跃情况,计算用户的流失率。
2. 分析线上课程的受欢迎程度,构建课程智能推荐模型,为教育平台的线上推荐服务提供策略
任务 1 数据预处理
任务 1.1 对照附录 1,理解各字段的含义, 进行缺失值、重复值等方面的必要处理,将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X 可从 1 开始往后编号), 并在报告中描述处理过程。
- login数据没有空值,无重复项,不用额外处理。
- study_information 表格,无重复项,price字段有缺失值,占比很小,可直接舍弃,school字段有大量缺失值,为非重要字段,因此不做处理。
- users表格,无重复项,user_id有部分缺失,占比很小,可直接舍弃。
import pandas as pd
import numpy as np
#分别导入三个数据表
login_data=pd.read_csv('login.csv',encoding='gbk')
study_information_data=pd.read_csv('study_information.csv',encoding='gbk')
users_data=pd.read_csv('users.csv',encoding='gbk')
#查看数据信息和数据空值统计,可以看到三个字段都没有缺失值
print(login_data.isnull().sum())
out:
user_id 0
login_time 0
login_place 0
dtype: int64
print(login_data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 387144 entries, 0 to 387143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 387144 non-null object
1 login_time 387144 non-null object
2 login_place 387144 non-null object
dtypes: object(3)
memory usage: 8.9+ MB
#统计重复值的数量,结果为0
print(login_data.duplicated().sum())
out:
0
-----------------------------------------------------------------------------------------
print(study_information_data.isnull().sum())
out:
user_id 0
course_id 0
course_join_time 0
learn_process 0
price 4238
dtype: int64
#查看数据信息,可以看到['user_id','course_id ','course_join_time','learn_process']字段都没有缺失值,price字段有数据缺失,数量为4238
print(study_information_data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 194974 entries, 0 to 194973
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 194974 non-null object
1 course_id 194974 non-null object
2 course_join_time 194974 non-null object
3 learn_process 194974 non-null object
4 price 190736 non-null float64
dtypes: float64(1), object(4)
memory usage: 7.4+ MB
#统计重复值数量,可得到为0
print(study_information.duplicated().sum())
out:
0
#去掉price为空的数据
study_information_data=study_information_data.loc[~study_information_data['price'].isna()]
-----------------------------------------------------------------------------------------
print(users_data.isnull().sum())
out:
user_id 67
register_time 0
recently_logged 0
number_of_classes_join 0
number_of_classes_out 0
learn_time 0
school 33412
dtype: int64
#查看数据信息,可以看到['register_time','recently_logged','number_of_classes_join'
# ,'number_of_classes_out','learn_time ']字段都没有缺失值,['user_id','school']字段有缺失值
print(users_data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 43983 entries, 0 to 43982
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 43916 non-null object
1 register_time 43983 non-null object
2 recently_logged 43983 non-null object
3 number_of_classes_join 43983 non-null int64
4 number_of_classes_out 43983 non-null int64
5 learn_time 43983 non-null object
6 school 10571 non-null object
dtypes: int64(2), object(5)
memory usage: 2.3+ MB
#统计user_id缺失值的占比
print(users_data.user_id.isnull().sum()/users_data.shape[0])
out:
0.0015233158265693563
#由于user_id是表的主键,且占比很小,因此直接舍弃
users_data=users_data.loc[~users_data['user_id'].isna()]
#统计重复值数量,可得到为0
print(user_data.duplicated().sum())
out:
0
任务 1.2 对用户信息表中 recently_logged 字段的“--”值进行必要的处理,
users 数据中 recently_logged 字段存在异常值“–”,该数据可能为缺失值,也可能是用户注册后不再进行登,结合后续分析与其余表格的可关联性,对“–”进行分类处理。对于在 study_information 中出现的选课信息的用户,采用其选课的最后时间来替换“–”。剩余的“–”异常值用注册时间来替换。
import pandas as pd
import numpy as np
#分别导入三个数据表
login_data=pd.read_csv('login.csv',encoding='gbk')
study_information_data=pd.read_csv('study_information.csv',encoding='gbk')
users_data=pd.read_csv('users.csv',encoding='gbk')
#查看'recently_logged'字段中'--'的相关信息,可以看到有5376条记录
print(users_data[users_data['recently_logged']=='--'].info())
out:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5376 entries, 11 to 43955
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 5376 non-null object
1 register_time 5376 non-null object
2 recently_logged 5376 non-null object
3 number_of_classes_join 5376 non-null int64
4 number_of_classes_out 5376 non-null int64
5 learn_time 5376 non-null object
6 school 3252 non-null object
dtypes: int64(2), object(5)
#如果用study_information的加入课程时间来填充'--',则需要连接表格
users_study_information=users_data.merge(study_information_data,how='inner',
on='user_id')
#需要找出每个user_id最近的登录时间,由于'course_join_time'是object类型,需要转换成datetime类型
study_information_data['course_join_time']=pd.to_datetime(study_information_data['course_join_time'])
#找到每个用户加入课程的最近时间
user_recently_select=study_information_data.groupby('user_id')['course_join_time'].max()
#将加入课程最近时间与主表连接
users_study_information=users_study_information.merge(user_recently_select,left_on='user_id',right_index=True,suffixes=('','_last'))
users_study_information['course_join_time_last']=users_study_information['course_join_time_last'].astype(str)
#将'--'填充为最近加入课程的时间
users_study_information['recently_logged']=users_study_information[['recently_logged','course_join_time_last']].apply(lambda row: row['course_join_time_last']
if row['recently_logged']=="--" else row['recently_logged'],axis=1)
#检查所有的'--'全部被填充,不需要再用注册时间来填充.
# print(users_study_information[users_study_information['recently_logged']=='--'].count())
out:
user_id 0
register_time 0
recently_logged 0
number_of_classes_join 0
number_of_classes_out 0
learn_time 0
school 0
course_id 0
course_join_time 0
learn_process 0
price 0
course_join_time_last 0
dtype: int64
#输出指定表格
names=['user_id','register_time','recently_logged','number_of_classes_join','number_of_classes_out','learn_time','school']
task1_2=users_study_information.loc[:,names]
print(task1_2.info())
out:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 190796 entries, 0 to 190795
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 190796 non-null object
1 register_time 190796 non-null object
2 recently_logged 190796 non-null object
3 number_of_classes_join 190796 non-null int64
4 number_of_classes_out 190796 non-null int64
5 learn_time 190796 non-null object
6 school 38013 non-null object
dtypes: int64(2), object(5)
memory usage: 11.6+ MB
task1_2.to_csv('task1_2.csv')
任务 2 平台用户活跃度分析
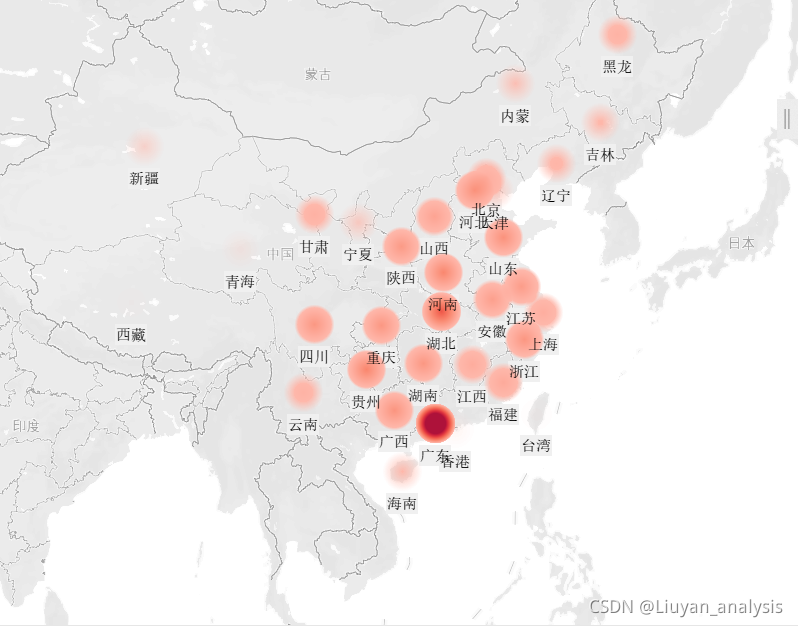
任务 2.1 分别绘制各省份与各城市平台登录次数热力地图,并分析用户分布情况。
由热力图可以看出广东为登录次数最多的省份
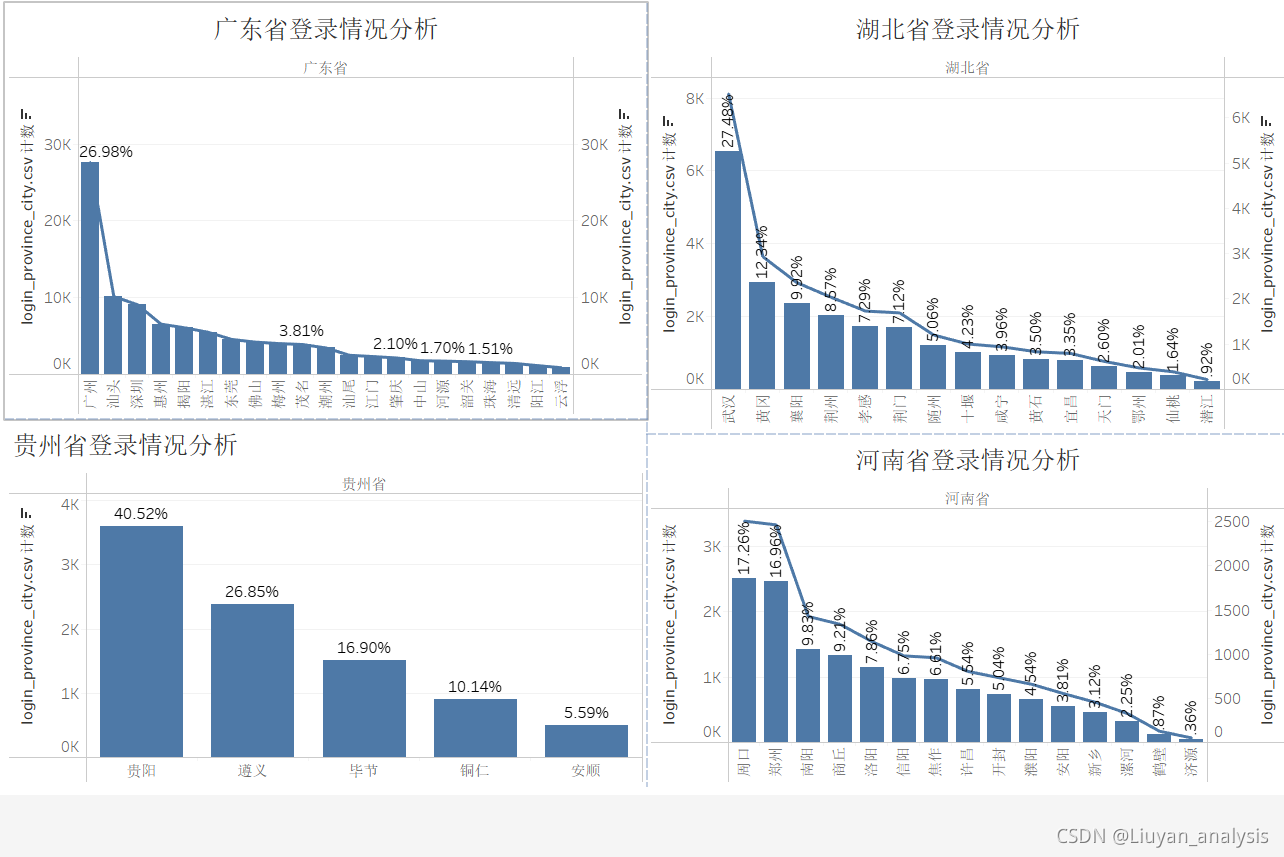
选出登录最多的四个省份分析各城市登录情况,可以看出登录分布在省份之间存在一定的集中性,例如广东主要集中在广州,湖北主要集中在武汉,贵州主要集中在贵阳,河南主要分布在周口和郑州。
分析和建议如下:
首先,对于用户数相对较为庞大的地区而言,该线上平台可以在此处加大宣传力度,进一步打开市场,增加顾客黏性。更为重要的是,对于这些重点地区增加调查,摸清该地区用户的特点和与其他地区的核心差异所在,为以后指定营销方案提供基础。其次,对于目前仍未重点开放的省市而言,不可盲目夸大范围, 投入资本。需要在保证重点地区人员稳定的情况下,再进行逐一攻破。与此同时,在调查中不难发现,线上教育平台用户的数量与相应地区的经济发展水平和互联网发展水平存在高度的相关关系,因此这些客观的因素也应该被纳入到相应的考虑范围中去
任务 2.2 分别绘制工作日与非工作日各时段的用户登录次数柱状图,并分析用户活跃的主要时间段。
2018年6月到2020年12月国家假期安排与调休表格,制作假期调休表格holiday
2018年节假日
中秋节:9月24日放假,与周末连休。
国庆节:10月1日至7日放假调休,共7天。9月29日(星期六)、9月30日(星期日)上班。
2019年节假日
一、元旦:2018年12月30日至2019年1月1日放假调休,共3天。2018年12月29日(星期六)上班。
二、春节:2月4日至10日放假调休,共7天。2月2日(星期六)、2月3日(星期日)上班。
三、清明节:4月5日放假,与周末连休。
四、劳动节:5月1日至4日放假调休,共4天。4月28日(星期日)、5月5日(星期日)上班。
五、端午节:6月7日放假,与周末连休。
六、中秋节:9月13日放假,与周末连休。
七、国庆节:10月1日至7日放假调休,共7天。9月29日(星期日)、10月12日(星期六)上班。
2020年节假日
一、元旦:2020年1月1日放假,共1天。
二、春节:1月24日至2月2日放假调休,共10天。 [2]
三、清明节:4月4日至6日放假调休,共3天。
四、劳动节:5月1日至5日放假调休,共5天。4月26日(星期日)、5月9日(星期六)上班。
五、端午节:6月25日至27日放假调休,共3天。6月28日(星期日)上班。
六、国庆节、中秋节:10月1日至8日放假调休,共8天。9月27日(星期日)、10月10日(星期六)上班。
import pandas as pd
import numpy as np
#导入登录数据
login_data=pd.read_csv('login.csv',encoding='gbk')
print(login_data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 387144 entries, 0 to 387143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 387144 non-null object
1 login_time 387144 non-null object
2 login_place 387144 non-null object
#查看'login_place'字段可以看出有些登录只有国家,有些只有省份信息,没有城市信息
print(login_data.login_place)
out:
0 中国广东广州
1 中国广东广州
2 中国广东广州
3 中国广东广州
4 中国广东广州
...
387139 中国湖北武汉
387140 中国湖北
387141 中国天津
387142 中国北京
387143 中国江西南昌
#生成省份和城市信息
login_data['login_province']=login_data.login_place.apply(lambda x : x[2:4] if len(x)>2 else np.NaN)
login_data['login_city']=login_data.login_place.apply(lambda x : x[4:6] if len(x)==6 else np.NaN)
print(login_data.info())
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 387144 entries, 0 to 387143
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 387144 non-null object
1 login_time 387144 non-null object
2 login_place 387144 non-null object
3 login_province 379413 non-null object
4 login_city 268935 non-null object
#将'login_time'改成datetime类型
login_data['login_time']=pd.to_datetime(login_data['login_time'])
login_data['week']=login_data['login_time'].apply(lambda x :x.weekday())
day_list=[1,2,3,4,5]
#先划分周一到周五为工作日,周六周日为非工作日
login_data['work_or_not']=login_data['week'].apply(lambda x : '工作日' if x in day_list else '非工作日' )
print(login_data['work_or_not'])
out:
0 工作日
1 工作日
2 工作日
3 工作日
4 工作日
...
387139 工作日
387140 工作日
387141 工作日
387142 工作日
387143 工作日
Name: work_or_not, Length: 387144, dtype: object
#根据国家节假日信息生成节假日表
holiday=pd.read_excel('D:/Python数据分析与挖掘实战/赛题A:教育平台的线上课程智能推荐策略'
'/holiday.xls')
#查看前5条记录
print(holiday.head())
out:
日期 节假日 remark 星期
0 2019-09-24 中秋 非工作日 周五
1 2019-09-25 中秋 非工作日 周六
2 2019-09-26 中秋 非工作日 周日
3 2019-10-01 国庆 非工作日 周一
4 2019-10-02 国庆 非工作日 周二
#要合并表,需要将'日期'类型转换成相同
login_data['login_time']=login_data['login_time'].astype(str)
holiday['日期']=holiday['日期'].astype(str)
#分别取到日期和时间
login_data['日期']=login_data['login_time'].apply(lambda x : x.split(' ')[0])
login_data['时间']=login_data['login_time'].apply(lambda x : x.split(' ')[1])
login_data_work=login_data.merge(holiday,how='left',on='日期')
#将之前的工作日与非工作日根据节日信息更正
login_data_work['day']=login_data_work.apply(lambda row : row['work_or_not'] if pd.isnull(row['remark']) else row['remark'],axis=1)
#查看最终表信息
print(login_data_work.info())
out:
0 user_id 392089 non-null object
1 login_time 392089 non-null object
2 login_place 392089 non-null object
3 login_province 384338 non-null object
4 login_city 272437 non-null object
5 week 392089 non-null int64
6 work_or_not 392089 non-null object
7 日期 392089 non-null object
8 时间 392089 non-null object
9 节假日 17082 non-null object
10 remark 17082 non-null object
11 星期 15166 non-null object
12 day 392089 non-null object
dtypes: int64(1), object(12)
memory usage: 41.9+ MB
#保存数据
login_data_work.to_csv('login_data_work.csv',index=False)
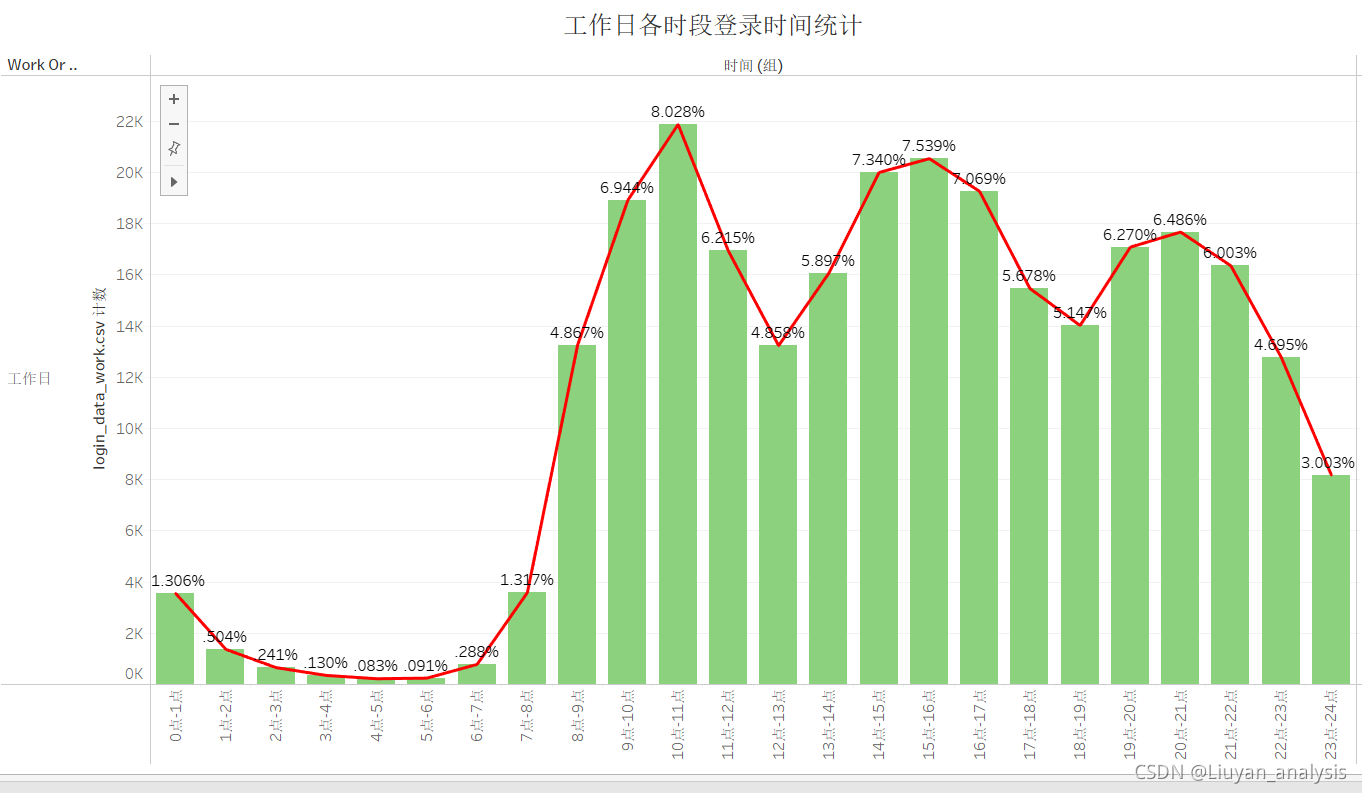
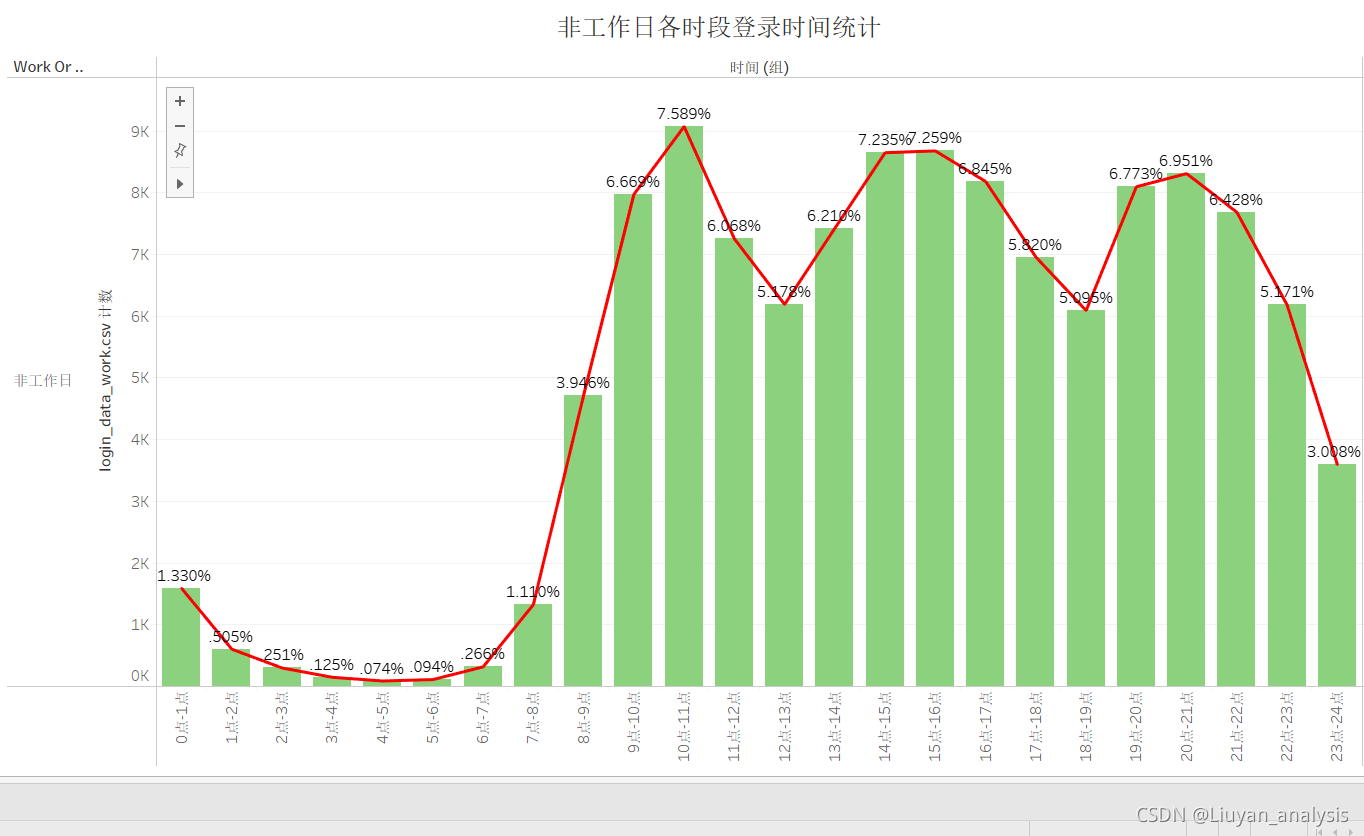
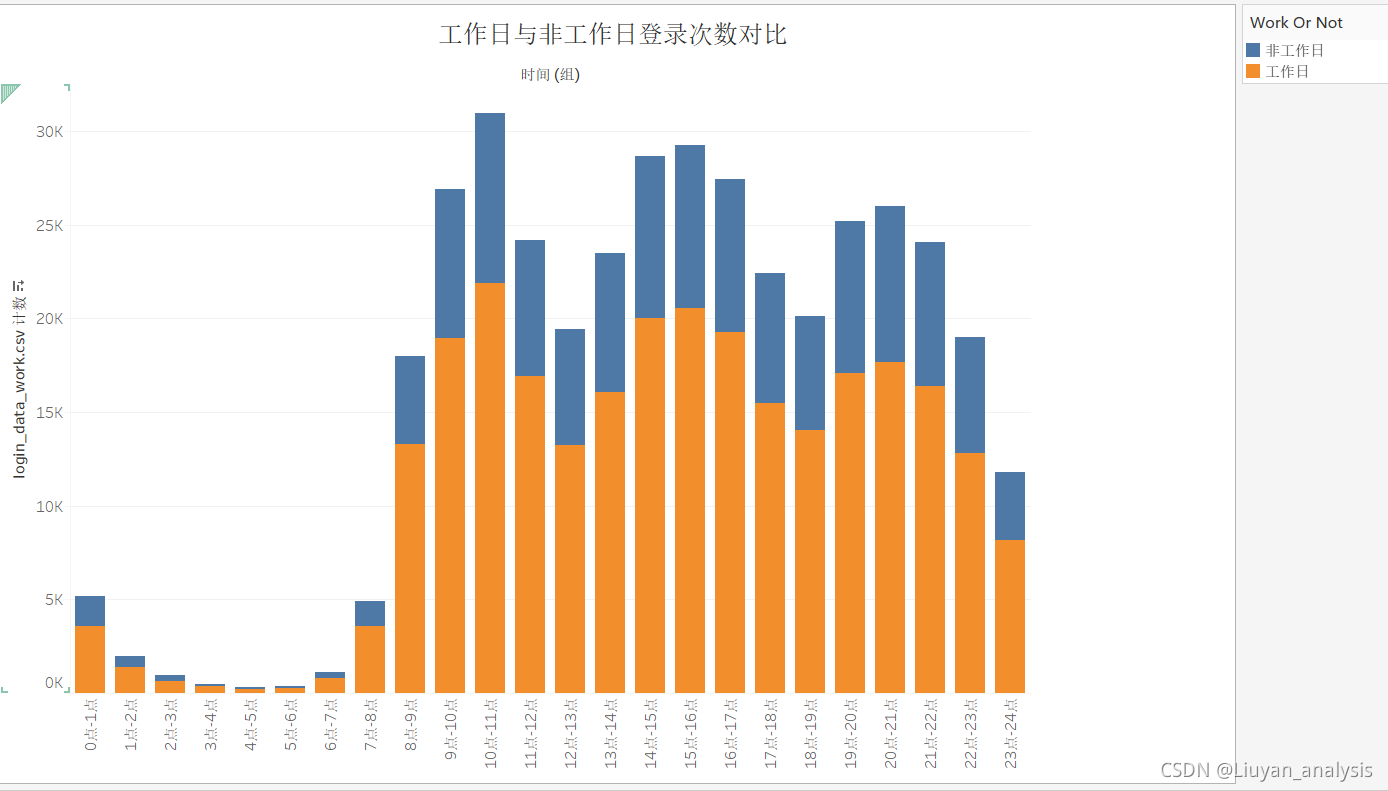
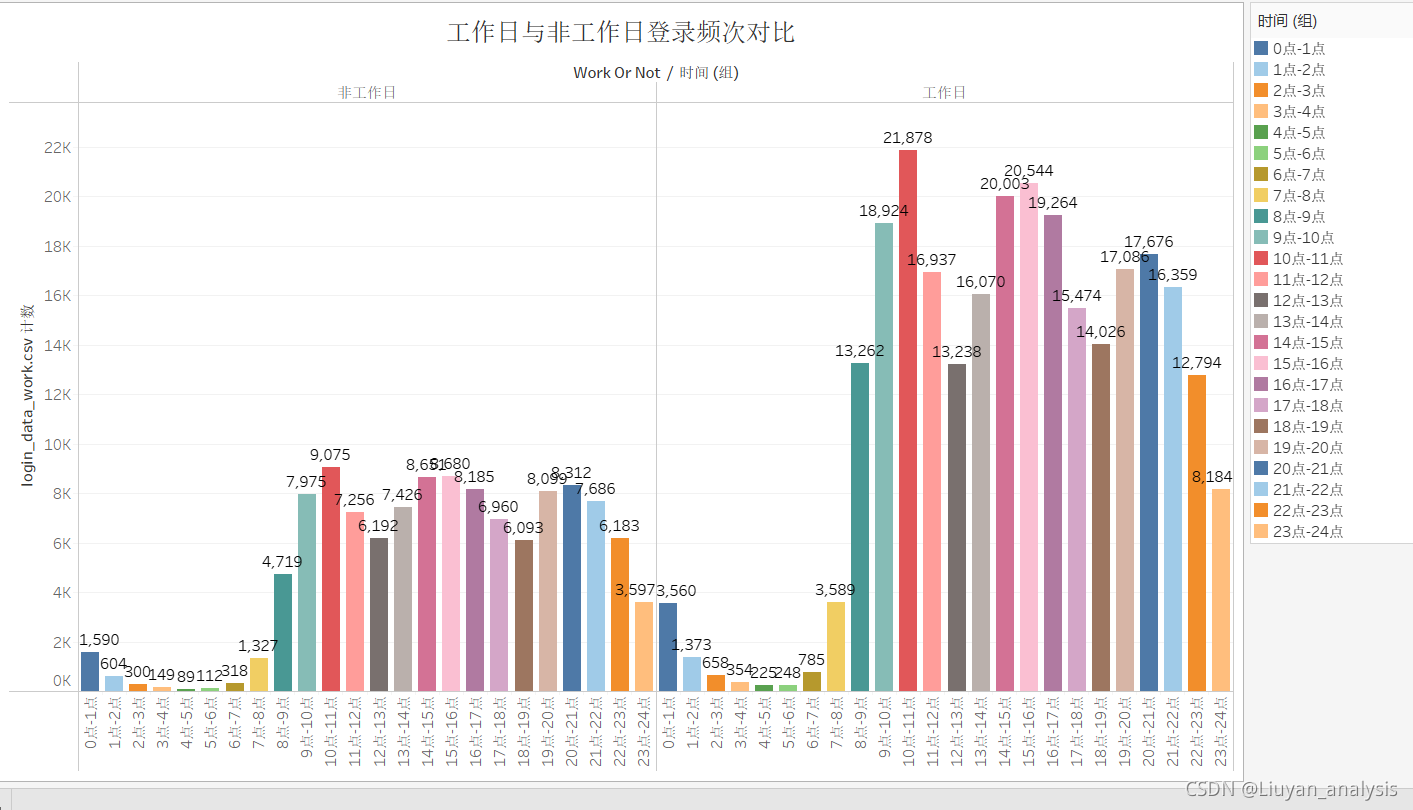
由以上可以分析出:
1.工作日的登录次数明显大于非工作日。
2.用户登录时间主要集中在8点-22点之间。
3.从早上7点用户登录数开始增加。
4.用户登录数有三次回落,11点-13点,可能是由于午休造成,17点-19点可能是由于下班引起
22点-24点可能是由于睡眠引起。
5.非工作日的最高登录频次为9075,为4点-5点时间段,工作日的最低登录频次为21878,是非工作日的两倍多,为10点-11点时间段。
6.非工作日的最低登录频次为89,为10点-11点时间段,工作日的最高登录频次为225,是非工作日的两倍多,为4点-5点时间段。
分析和建议如下:
工作日和非工作日的登陆频次基本一致,均在上午 8:00-11:00,下午 14:00-17:00,晚上 20:00-21:00 出现三个高峰,波动趋势基本一致。并且工作日登陆最高峰值在上午 10:00-11:00 出现最高峰值,非工作日在夜间出现峰值,所以根据出现峰度的区间,在线教育平台可以在该时间段加强系统维护,保证课程流畅度,并在该时间段多植入相关课程广告以及相关课程销售活动,以此留住更多客户,提高课程的吸引力和销售额。
任务 2.3 记𝑇end为数据观察窗口截止时间(如:赛题数据的采集截止时间为
2020 年 6 月 18 日), 𝑇end为用户 i 的最近访问时间, 𝜎𝑖 = 𝑇end − 𝑇𝑖,若𝜎𝑖 > 90天,则称用户 i 为流失用户。根据该定义计算平台用户的流失率。
import pandas as pd
#导入'user_study_information'表格,获取用户的最近登录信息
user_study_information=pd.read_csv('users_study_information.csv',encoding='utf-8')
#6/18 23:59为截止时间
end_day='2020/6/19'
#计算最后登录时间与截止时间的时间差
user_study_information['diff_day']=(pd.to_datetime(end_day)-
pd.to_datetime(user_study_information['recently_logged'])).dt.days
print(user_study_information['diff_day'])
out:
0 0
1 0
2 0
3 1
4 1
..
190791 13
190792 13
190793 0
190794 0
190795 0
Name: diff_day, Length: 190796, dtype: int64
#计算流失率
loss_rate_90=user_study_information.loc[user_study_information['diff_day']>90].shape[0]/user_study_information.shape[0]
on.loc[user_study_information['diff_day2']>30].shape[0]/user_study_information.shape[0]
print('流失率_90:{:.2%}'.format(loss_rate_90))
out:
流失率_90:30.49%
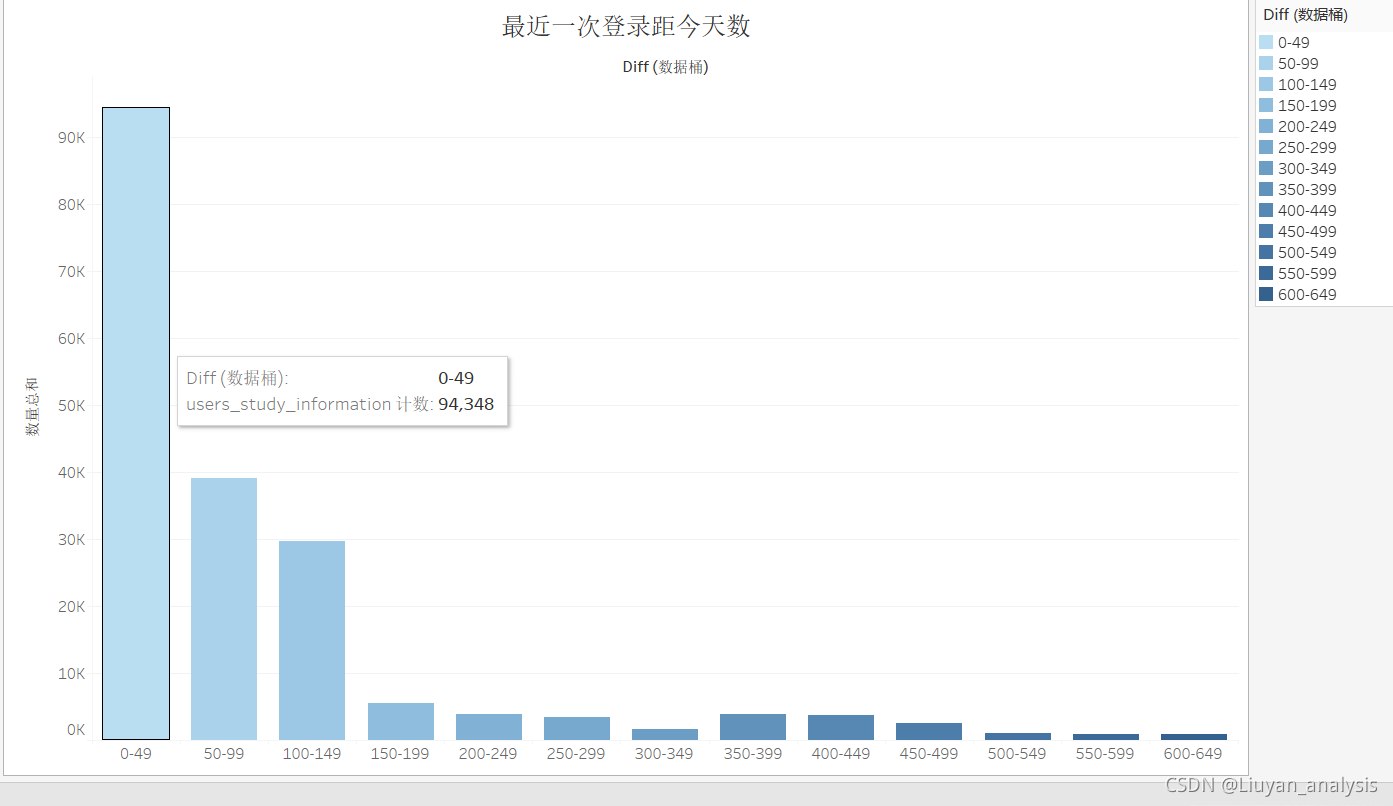
分析与建议:
可以看出用户90天的用户流失率为30%,大部分的客户的最近一次登录都在50天之内,对于未流失的客户可以定义50天以为的为活跃用户,50-99天的为易流失用户。
对于活跃的客户,作为重点客户关注,保持高质量的服务, 应该提高满意度,增加留存;
对于较活跃用户,应该赠送优惠券或推送活动信息,提高用户的登录率。
对于已经流失的用户可以发送短信召回。
任务 3.1 根据用户参与学习的记录,统计每门课程的参与人数,计算每门课
程的受欢迎程度,列出最受欢迎的前 10 门课程,并绘制相应的柱状图。受欢迎
程度定义如下:
𝛾𝑖 =(𝑄𝑖 – 𝑄min)/(𝑄max− 𝑄min)
其中, 𝛾𝑖为第 i 门课程的受欢迎程度, 𝑄𝑖为参与第 i 门课程学习的人数, 𝑄
max和𝑄min分别为所有课程中参与人数最多和最少的课程所对应的人数。
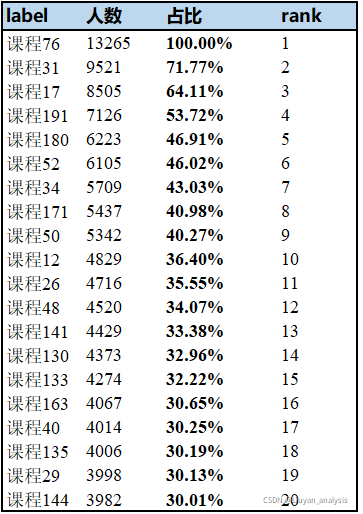
统计的课程排名如下:
分析和建议:
由上述图表来看,受欢迎程度排名前十门的课程分别是课程 76、课程 31、课程 17、课程 191、课程 180、课程 52、课程 34、课程 171、课程 50 和课程 12, 与其相对应的受欢迎指数分别是100% 、71.77%、64.11%、53.72%、46.91%、46.02%、43.03%、40.98%、40.27%、36.39%。其中受欢迎指数的最大值和最小值相差 0.6369, 参与课程 76 的用户人数超过一万名,而参与课程 12 的用户人数仅有 4829 名未达到课程 76 参与人数的一半,差距较为悬殊。这表明该教育平台上的优质课程呈现出较为明显的两极分化,相关人员在安排课程时应强调均衡发展,在保持特色优质课的同时,提高课程参与人数少的课程质量。
任务 3.2 根据用户选择课程情况,构建用户和课程的关系表(二元矩阵),
使用基于物品的协同过滤算法计算课程之间的相似度,并结合用户已选课程的记
录,为总学习进度最高的 5 名用户推荐 3 门课程。
#由于数据量太大,电脑内存不够,无法跑完全部数据,因此选取2019/10/13之前的日期来分析。
user_study_information['date1'] = user_study_information['course_join_time'].apply(lambda x: x.split(' ')[0])
data_test = user_study_information.loc[user_study_information['date1'].isin(['2019/10/13', '2019/10/14'])]
data_train = user_study_information.loc[user_study_information['user_id'].isin(data_test['user_id'])]
train = defaultdict()
data_train.loc[:, 'tmp'] = 1
user_course_pivot = data_train.pivot(index='user_id', columns='course_id', values='tmp')
col_name = user_course_pivot.columns
基于物品的协同过滤
# 1、建立物品-的倒排表,主键为用户
train = defaultdict()
data_train.loc[:, 'tmp'] = 1
user_course_pivot = data_train.pivot(index='user_id', columns='course_id', values='tmp')
# print(user_course_pivot.head(10))
col_name = user_course_pivot.columns
# print(col_name)
for item, user in user_course_pivot.iterrows():
a = []
for x in range(len(user)):
if ~np.isnan(user[col_name[x]]):
a.append(col_name[x])
train[item] = a
# 基于用户的协同过滤
def calc_corelate_user(train):
"""
train 是物品用户倒排表
矩阵N表示喜欢某物品的用户数
共现矩阵C其实就是余弦公式的分子
:param train:
:return:
"""
C = defaultdict(defaultdict) # 用户与用户共同喜欢物品的个数
N = defaultdict(defaultdict) # 用户个数
for u, items in train.items():
for i in items:
if i not in N.keys(): # 如果一维字典中没有该键,初始化值为0
N[i] = 0
N[i] += 1
for j in items:
if i == j:
continue
if j not in C[i].keys(): # 如果二维字典中没有该键,初始化值为0
C[i][j] = 0
C[i][j] += 1
return C, N
def cal_matrix_W(C, N):
W = defaultdict(dict)
for i, related_items in C.items():
for j, cij in related_items.items():
W[i][j] = cij / math.sqrt(N[i] * N[j]) # 余弦相似度
return W
def recommend(train, user_id, W, K):
rank = dict()
ru = train[user_id] # 用户数据,表示某物品及其兴趣度
for i, pi in enumerate(ru): # i表示用户已拥有的物品id,pi表示其兴趣度
if pi not in W:
continue
# j表示相似度为前K个物品的id,wj表示物品i和物品j的相似度
for j, wj in sorted(W[pi].items(), key=operator.itemgetter(1), reverse=True)[0:K]:
if j in ru: # 如果用户已经有了物品j,则不再推荐
continue
rank[j] = rank.setdefault(j, 0) + wj * 1
return rank
C, N = calc_corelate_user(train)
W = cal_matrix_W(C, N)
del C, N
gc.collect()
# 查看用户17474选取的课程号
print('=====>', train['用户17474'])
out:
=====> ['课程12', '课程174', '课程184', '课程20', '课程24']
#查看课程间的相关系数
print(sorted(W['课程174'].items(), key=operator.itemgetter(1), reverse=True)[0:3])
out:
[('课程184', 0.6157454690707401), ('课程24', 0.582063665634392), ('课程20', 0.5769651995367001)]
#给用户17474推荐课程,课程175 的相关系数最高
rank = recommend(train, '用户17474', W, 10)
print(rank)
out:
{'课程175': 2.8377375013472523, '课程33': 2.1768586914727717, '课程52': 1.578556352663509, '课程31': 0.8145119846381295, '课程191': 0.800774964925876, '课程171': 1.0227457094318269, '课程76': 1.1898473215181766, '课程148': 0.27817432013209337, '课程26': 0.2719641466102106, '课程50': 1.1592379834855917, '课程210': 0.40467443029011024}
数据处理要求:
- 任务 1.1 应包含每个表中缺失值和重复值的记录数以及有效数据的记
- 录数。 任务 1.2 应包含 recently_logged 字段的“--”值的记录数以及数据处
- 理的方法。 任务 2.1 应包含各省份与各城市的热力地图以及主要省份和主要城市
- 的数据表格,并进行分析。 任务 2.2 应包含工作日与非工作日各时段的柱状图,并进行分析。
- 任务 2.3 应包含对流失率的定义,并给出流失率的结果。
- 任务 2.4 应根据计算结果给出合理的建议。
- 任务 3.1 应包含最受欢迎的前 10 门课程的参与人数、受欢迎程度及
- 柱状图。任务 3.2 应包含相应推荐算法的描述,并给出总学习进度最高的 5 个
- 用户的课程推荐数据。任务 3.3 应包含数据分析的方法、算法描述以及主要结果
附录 1 数据说明
附 件 包 含 三 张 数 据 表 , 分 别 为 users.csv ( 用 户 信 息 表 )、study_information.csv(学习详情表)和 login.csv(登录详情表),它们的数据说明分别如表 1、 表 2 和表 3 所示。
表 1 users.csv 字段说明
| 字段名 | 描述 |
| user_id | 用户 id |
| registration_time | 注册时间 |
| recently_logged | 最近访问时间 |
| learn_time | 学习时长(分) |
| number_of_classes_join | 加入班级数 |
| number_of_classes_out | 退出班级数 |
| school | 用户所属学校 |
表 2 study_information.csv 字段说明
| 字段名 | 描述 |
| user_id | 用户 id |
| course_id | 课程 id |
| course_join_time | 加入课程的时间 |
| learn_process | 学习进度 |
| price | 课程单价 |
表 3 login.csv 字段说明
| 字段名 | 描述 |
| user_id | 用户 id |
| login_time | 登录时间 |
| login_place | 登录地址 |

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









