






案例来自: 一辩过工作室[www.yibianguo.com]
工作室专注于: 论文辅导、降重、查重、毕设-大数据 可视化大屏 机器学习
01、任务要求
任务一:数据预处理
任务 1.1 理解各字段的含义,进行缺失值、重复值等方面的必要处理,将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X 可从 1 开始往后编号),并在报告中描述处理过程。
任务 1.2 对用户信息表中recently_logged 字段的“--”值进行必要的处理,将处理结果保存为“task1_2.csv”,并在报告中描述处理过程。
任务二:用户整体情况分析
任务 2.1 分别绘制各省份与各城市平台登录次数热力地图,并分析用户分布情况。
任务 2.2 分别绘制工作日与非工作日各时段的用户登录次数柱状图,并分析用户活跃的主要时间段。
任务 2.3 记 为数据观察窗口截止时间(如:赛题数据的采集截止时间为2020 年 6 月 18 日)。
为用户 i 的最近访问时间, = − ,若 > 90天,则称用户 i 为流失用户。根据该定义计算平台用户的流失率。
任务三:用户课程选择分析
任务 3.1 根据用户参与学习的记录,统计每门课程的参与人数,计算每门课程的受欢迎程度,列出最受欢迎的前 10 门课程,并绘制相应的柱状图。受欢迎程度定义如下: = − min max− min。其中, 为第 i 门课程的受欢迎程度, 为参与第 i 门课程学习的人数, max和 min分别为所有课程中参与人数最多和最少的课程所对应的人数。
任务 3.2 根据用户选择课程情况,构建用户和课程的关系表(二元矩阵),使用基于物品的协同过滤算法计算课程之间的相似度,并结合用户已选课程的记录,为总学习进度最高的 5 名用户推荐 3 门课程。
任务 3.3 在任务 3.1 和任务 3.2 的基础上,结合用户学习进度数据,分析付费课程和免费课程的差异,给出线上课程的综合推荐策略。
02、研究思路及分析过程
任务一:数据预处理
●缺失情况分析:数值为0/空值的情况需要分开讨论,且关注缺失数据是否为真实缺失
●异常情况分析:对出现“--”的情况进行分析,且关注该符号的实际意义以及占比情况
●重复情况分析:对于重复数据进行删除
任务二:用户整体情况分析
●用户分布分析:根据海内外、省份分析、乡镇分析入手,找到核心差异点所在
●用户活跃度分析:细分整体情况与工作日差异
●用户流失情况分析:细分整体情况与用户流失风险
●线上管理决策建议:宣传、活跃度、流失为切口进行分析
任务三:用户课程选择分析
●用户参与课程情况:现有课程选择分析与受欢迎度计算
●用户课程推荐:基于协同过滤算法进行重点课程推荐
●收费课程与用户学习进度相关分析:线上课程综合推荐策略制定
03、数据预处理
数据下载:评论区回复关键字【数据集】获取。
import pandas as pd
import numpy as np
import datetime
import jieba
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False
from chinese_calendar import is_workday
from pyecharts import Bar缺失值处理
首先判断该缺失值是否为真实缺失。针对不同的数据缺失情况,本次分析将会采用不同的处理方式:
1、针对数值为 0 的情况,需要进行实际的分析,回归到原始数据中去,判断该数据为 0 时是否具有实际意义。如果没有就将其作为缺失值做删除处理。
2、针对数据为空值的情况,如果该特征数据缺失情况低于 10%,则结合该特征的重要性进行综合判断。如果字段重要性较低,则考虑直接删除,如果字段重要性较高,则进行插值法或者采用数据均值进行填补。
login=pd.read_csv('login.csv',encoding='gbk')
login.info()
# 没有缺失值输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 387144 entries, 0 to 387143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 387144 non-null object
1 login_time 387144 non-null object
2 login_place 387144 non-null object
dtypes: object(3)
memory usage: 8.9+ MB重复值处理
在完成缺失数据和异常数据处理之后,对数据进行重复值的删除处理。此处的重复值是指在数据表中用于分析的各个字段均一致。
#一天内重复登录的行为我们将视为一次登录即可,以减少数据量
# 方法一
# data1=login['login_time'].str.split(' ',expand=True)[0]
# login=pd.concat([login,data1],axis=1)
# login.rename(columns={0:'日期'},inplace=True)
# del login['login_time']
# login
# 方法二
def str_datetime(df,column_name='login_time'):
df[column_name]=pd.to_datetime(df[column_name])
df[column_name]=df[column_name].apply(lambda x:x.strftime('%Y-%m-%d'))
return df
login=str_datetime(login)
# 将同一日期用户重复登陆行为删除
login=login.drop_duplicates()
login输出结果:
267725 rows × 3 columns
# 以最近的时间为基准,计算出用户每一次登录距离现在的时间
login['时间差1']=pd.to_datetime(login['login_time']).max()-pd.to_datetime(login['login_time'])
login输出结果:
267725 rows × 4 columns
重新排序
login=login.reset_index()
del login['index']
# # 地区拆分
# # 运行时间很长-而且切词并不准确,很多没有切除干净
# for i in range(login.shape[0]):
# li=[str(i.word) for i in HanLP.newSegment("crf").seg(login.iloc[i,2])]
# # li=[word for word in jieba.cut(login.iloc[i,2])]
# if len(li)==1:
# if '中国' in login.iloc[i,2]:
# login.loc[i,'国家']=login.iloc[i,2][0:2]
# login.loc[i,'省份']=login.iloc[i,2][2:]
# else:
# login.loc[i,'国家']=login.iloc[i,2]
# elif len(li)==2:
# login.loc[i,'国家']=li[0]
# login.loc[i,'省份']=li[1]
# else:
# login.loc[i,'国家']=li[0]
# login.loc[i,'省份']=li[1]
# login.loc[i,'地区']=li[2]
# if i % 10000 ==0:
# print(i)
# 改进版本
for i in range(login.shape[0]):
if login.loc[i,'login_place'][0:2]=='中国':
login.loc[i,'国家']='中国'
if '黑龙江' in login.loc[i,'login_place']:
login.loc[i,'省份']='黑龙江'
if len(login.loc[i,'login_place'])>5:
login.loc[i,'地区']=login.loc[i,'login_place'][5:]
else:pass
if '新疆维吾尔' in login.loc[i,'login_place']:
login.loc[i,'省份']='新疆维吾尔'
if len(login.loc[i,'login_place'])>7:
login.loc[i,'地区']=login.loc[i,'login_place'][7:]
else:pass
if '内蒙古' in login.loc[i,'login_place']:
login.loc[i,'省份']='内蒙古'
if len(login.loc[i,'login_place'])>5:
login.loc[i,'地区']=login.loc[i,'login_place'][5:]
else:pass
else:
login.loc[i,'省份']=login.loc[i,'login_place'][2:4]
login.loc[i,'地区']=login.loc[i,'login_place'][4:]
else:
li=[word for word in jieba.cut(login.iloc[i,2])]
if len(li)==2:
login.loc[i,'国家']=li[0]
login.loc[i,'省份']=li[1]
else:
login.loc[i,'国家']=li[0]
if i%10000==0:
print(f'{round(i*100/(int(login.shape[0])),2)}%')输出结果:
0.0%
3.74%
7.47%
11.21%
14.94%
18.68%
22.41%
26.15%
29.88%
33.62%
37.35%
41.09%
44.82%
48.56%
52.29%
56.03%
59.76%
63.5%
67.23%
70.97%
74.7%
78.44%
82.17%
85.91%
89.64%
93.38%
97.11%
# login.to_excel('用户地区切割.xlsx')
# 重新读取已经切分好城市的数据
login =pd.read_excel('用户地区切割.xlsx',index_col=0)
login输出结果:
267725 rows × 7 columns至此已经提取出login表中所有可能有用的信息
stu_info=pd.read_csv('study_information.csv',encoding='gbk')
stu_info输出结果:
194974 rows × 5 columns
stu_info.info()输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 194974 entries, 0 to 194973
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 194974 non-null object
1 course_id 194974 non-null object
2 course_join_time 194974 non-null object
3 learn_process 194974 non-null object
4 price 190736 non-null float64
dtypes: float64(1), object(4)
memory usage: 7.4+ MB
stu_info=stu_info.drop_duplicates()
stu_info.info()
#没有完全重复数据,但是存在价格缺失数据输出结果:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 194974 entries, 0 to 194973
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 194974 non-null object
1 course_id 194974 non-null object
2 course_join_time 194974 non-null object
3 learn_process 194974 non-null object
4 price 190736 non-null float64
dtypes: float64(1), object(4)
memory usage: 8.9+ MB
stu_info[stu_info.price.isnull()].course_id.value_counts()输出结果:
课程51 4011
课程96 227
Name: course_id, dtype: int64
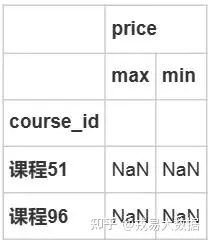
stu_course=stu_info.groupby(['course_id']).agg({'price':['max','min']})
stu_course[(stu_course['price']['max']-stu_course['price']['min'])!=0]
#不存在差异定价,且51和96课程价格为nan,其中51和96课程共计4238条数据,暂时不做处理输出结果:
# 将进度转化成为数值型,从而便于计算
stu_info['learn_process']=stu_info['learn_process'].apply(lambda x:int(x.split('width:')[-1].split('%')[0]))
# 对加入时间进行相同操作
stu_info=str_datetime(stu_info,column_name='course_join_time')
stu_info输出结果:
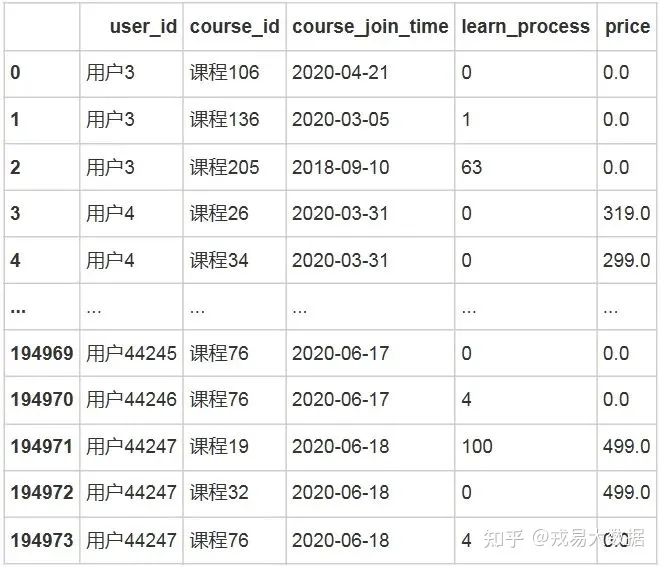
194974 rows × 5 columns至此已经提取出login表中所有可能有用的信息
users=pd.read_csv('users.csv',encoding='gbk')
users输出结果:
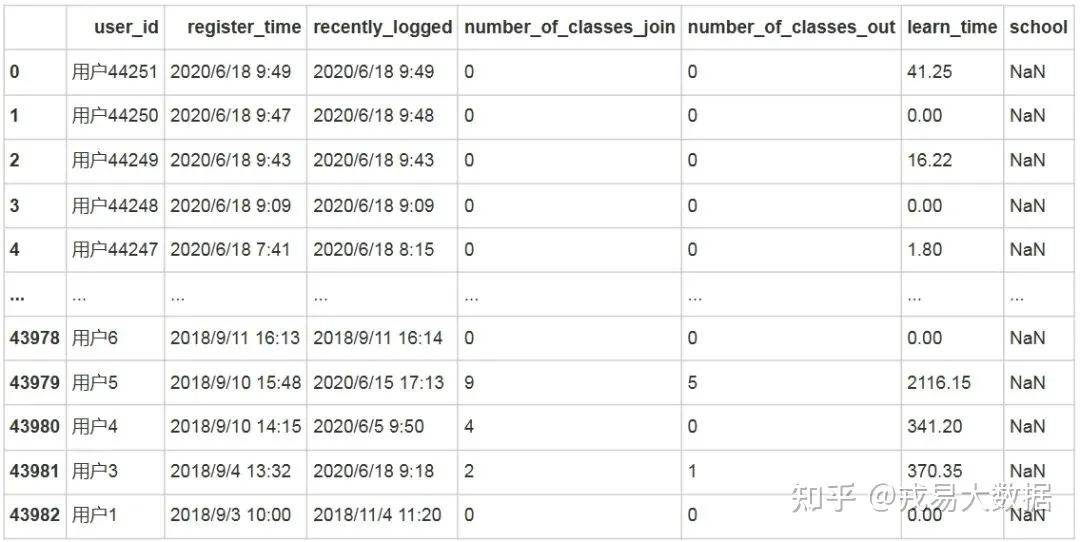
43983 rows × 7 columns
users.info()输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 43983 entries, 0 to 43982
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 43916 non-null object
1 register_time 43983 non-null object
2 recently_logged 43983 non-null object
3 number_of_classes_join 43983 non-null int64
4 number_of_classes_out 43983 non-null int64
5 learn_time 43983 non-null float64
6 school 10571 non-null object
dtypes: float64(1), int64(2), object(4)
memory usage: 2.3+ MB考虑到用户ID是用户的唯一标识,确实为缺失情况,而非正常可不填选项,且缺失的数据相对较少,因此删除数据。
学校数据字段缺失严重,考虑为实际选填数据,暂时保留,并且创建是否填写学校信息。
users=users[~users.user_id.isnull()]
users.info()输出结果:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 43916 entries, 0 to 43982
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 43916 non-null object
1 register_time 43916 non-null object
2 recently_logged 43916 non-null object
3 number_of_classes_join 43916 non-null int64
4 number_of_classes_out 43916 non-null int64
5 learn_time 43916 non-null float64
6 school 10569 non-null object
dtypes: float64(1), int64(2), object(4)
memory usage: 2.7+ MB
# 将是否填写学校信息设置成为0、1变量,作为后续可能有用的信息
users['是否填写学校信息']=users['school']
users.是否填写学校信息[~users['是否填写学校信息'].isnull()]=1
users.是否填写学校信息[users['是否填写学校信息'].isnull()]=0
users.是否填写学校信息.value_counts()
d:\miniconda3\lib\site-packages\ipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d:\miniconda3\lib\site-packages\ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
This is separate from the ipykernel package so we can avoid doing imports until
d:\miniconda3\lib\site-packages\pandas\core\series.py:992: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._where(~key, value, inplace=True)
d:\miniconda3\lib\site-packages\ipykernel_launcher.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
after removing the cwd from sys.path.输出结果:
0 33347
1 10569
Name: 是否填写学校信息, dtype: int64异常值处理
可以看出有一些recently_logged时间和现在的时间很接近,有一些很远,因此可以将‘--’进行进一步分析。
●用户注册后未登录
●用户注册后就未退出登录 使用login中的最新登录信息进行替换
因此考虑使用学习时间加上注册的时间作为其最近的登录时间,且设置一天学习8小时为上限。
keys=login.groupby('user_id').login_time.max().index.tolist()
values=login.groupby('user_id').login_time.max().values.tolist()
login_time={}
for i in range(len(keys)):
login_time[keys[i]]=values[i]
u_2=users[users.recently_logged!='--']
u_1=users[users.recently_logged=='--']
for i in range(u_1.shape[0]):
if u_1.iloc[i,0] in login_time.keys():
u_1.iloc[i,2]=pd.to_datetime(login_time[u_1.iloc[i,0]])
else:
if pd.to_datetime(u_1.iloc[i,1])+datetime.timedelta(days = int(u_1.iloc[i,5])/480 )>pd.to_datetime('2020-06-18'):
u_1.iloc[i,2]=pd.to_datetime('2020-06-18')
print('修改时间为最新时间')
else:
u_1.iloc[i,2]=pd.to_datetime(u_1.iloc[i,1])+datetime.timedelta(days = int(u_1.iloc[i,5])/480 )
users=pd.concat([u_1,u_2])
d:\miniconda3\lib\site-packages\pandas\core\indexing.py:1720: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._setitem_single_column(loc, value, pi)修改时间为最新时间
# 还是以最近的时间为基准,计算出用户登陆注册行为的时间差
str_datetime(users,column_name='register_time')
str_datetime(users,column_name='recently_logged')
users['register_logged_time']=pd.to_datetime(users['recently_logged'])-pd.to_datetime(users['register_time'])
users['register_now_time']=pd.to_datetime(users['register_time']).max()-pd.to_datetime(users['register_time'])
users['logged_now_time']=pd.to_datetime(users['recently_logged']).max()-pd.to_datetime(users['register_time'])
users输出结果:
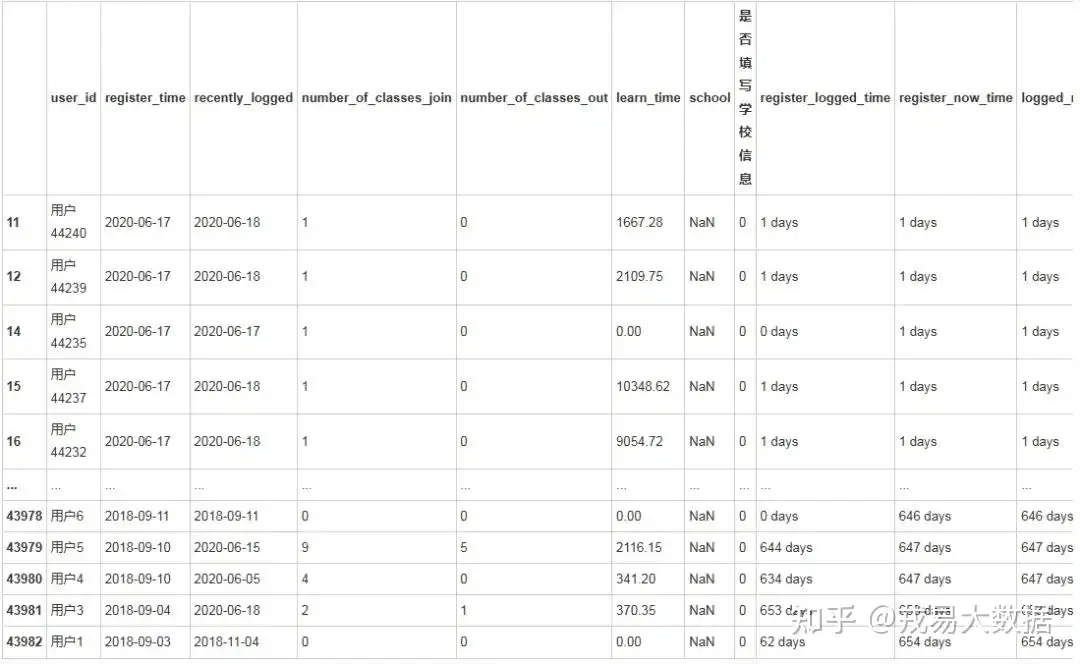
43916 rows × 11 columns
# 现在加入的班级的数量
users['number_of_classes_now']=users['number_of_classes_join']-users['number_of_classes_out']
users输出结果:
43916 rows × 12 columns至此已经完成所有的信息提取与数据预处理过程。
一辩过工作室 http://www.yibianguo.com
论文辅导、降重、查重 毕设大数据 大屏可视化 机器学习
04、用户整体情况分析
计算选课数量
def nx_data(df=stu_info,group_name=['course_id','user_id']):
# 得到共现字典
user_dic={}
stu_info_data=df.groupby(group_name)['course_id'].count().unstack()
column=stu_info_data.columns.tolist()
for i in range(stu_info_data.shape[0]):
user_dic[column[i]]=stu_info_data[stu_info_data[column[i]]==1].index.tolist()
#构造共现矩阵
course_name=list(set(df['course_id'].values.tolist()))
course_data=pd.DataFrame(data=np.zeros(shape=(len(course_name),len(course_name))),index=course_name,columns=course_name)
for value in user_dic.values():
if len(value)==1:
pass
else:
for i in range(len(value)):
for j in range(i+1,len(value)):
course_data.loc[value[i],value[j]]+=1
return (user_dic,course_data)
user_dic,course_data=nx_data()
for i,key in enumerate(user_dic.keys()):
users.loc[i,'选课数量']=len(user_dic[key])
users输出结果:
43916 rows × 13 columns地区合并
取最近的登录地点合并。
In[20]:
# login=pd.read_excel('用户地区切割.xlsx',index_col=0)
login_1=login.sort_values(by=['user_id','时间差1'])
login_del=login_1.user_id.drop_duplicates()
login_diff=login.iloc[list(login_del.index),:]
users_all=pd.merge(users,login_diff,how='left')
users_all.to_excel('全部信息.xlsx')
users_all=users_all.reset_index()
users_all=users_all.drop(columns=['index'])
users_all输出结果:
43916 rows × 19 columns用户分布分析
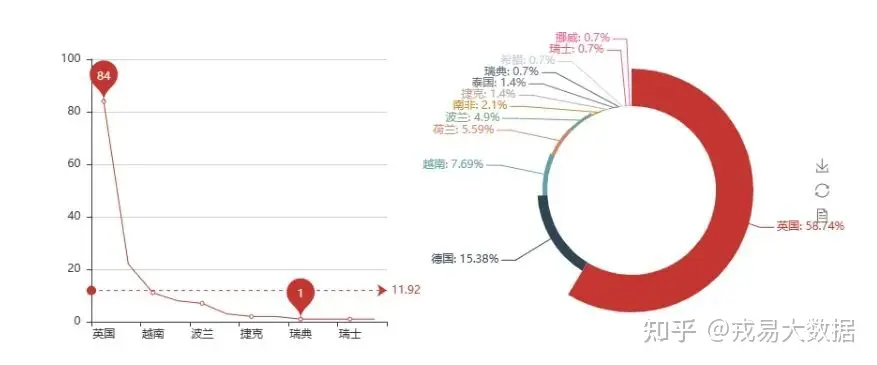
●海内外分布
country=login[login['国家']!='中国'].国家.value_counts().index.tolist()
country_count=login[login['国家']!='中国'].国家.value_counts().values.tolist()
login.国家.value_counts()输出结果:
中国 267582
英国 84
德国 22
越南 11
荷兰 8
波兰 7
南非 3
泰国 2
捷克 2
瑞典 1
希腊 1
瑞士 1
挪威 1
Name: 国家, dtype: int64
from pyecharts import Line, Pie, Grid
line=Line()
line.add( "",country,country_count,mark_point=["max", "min"],mark_line=["average"])
pie = Pie("", title_pos="55%")
pie.add( "", country, country_count, radius=[45, 65],center=[74, 50],legend_pos="80%",legend_orient="vertical",rosetype="radius",is_legend_show=False,is_label_show = True)
grid = Grid(width=900)
grid.add(line, grid_right="55%")
grid.add(pie, grid_left="50%")
grid输出结果:
●中国省份分布
# login=pd.read_excel('用户地区切割.xlsx',index_col=0)
provice=login[login['国家']=='中国'].省份.value_counts().index.tolist()
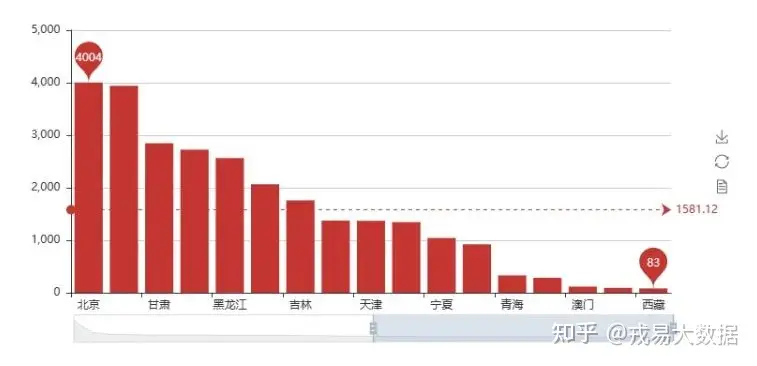
provice_count=login[login['国家']=='中国'].省份.value_counts().values.tolist()
bar=Bar()
bar.add('',provice,provice_count,mark_point=['max','min'],mark_line=['average'], is_datazoom_show=True)
bar输出结果:
# 热力图的可视化部分,直接运行会出现空白的问题,因此可以生成html文件
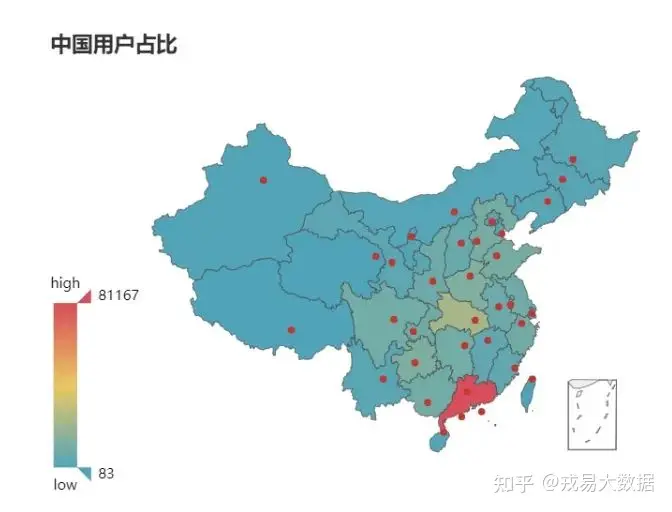
from pyecharts import Map
map = Map("中国用户占比", '', width=600, height=400)
map.add("", provice, provice_count, visual_range=[min(provice_count), max(provice_count)], maptype='china', is_visualmap=True,
visual_text_color='#000')
map.render(path="中国用户占比.html")
map输出结果:
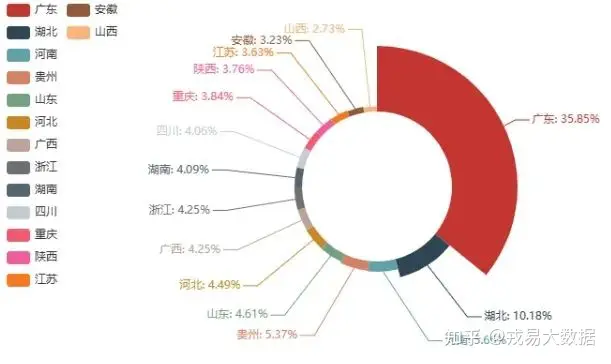
from pyecharts import Pie
pie = Pie()
pie.add(
'',
provice[:15],provice_count[:15], #'':图例名(不使用图例)
radius = [40,75], #环形内外圆的半径
is_label_show = True, #是否显示标签
legend_orient = 'bottom', #图例垂直
rosetype="radius", #玫瑰饼图
legend_pos = 'left'
)
pie输出结果:
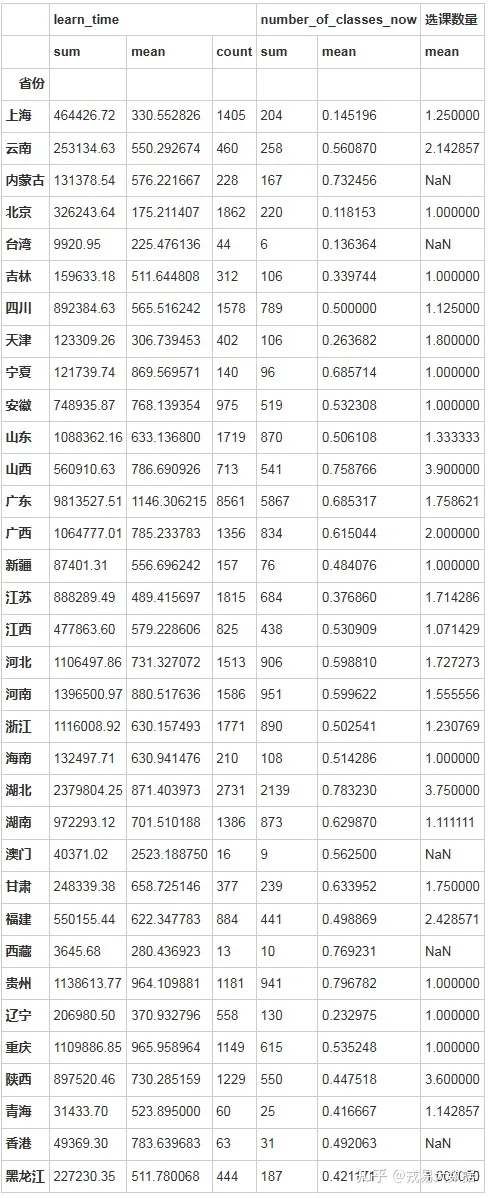
用户分布行为差异
由于地区间差异较大,且营销策略等差异化,因此对不同省份的用户进行分析可以看出用户存在以下特点。
●广东、澳门、贵州、重庆等地区人均学习时长较长,但澳门仅拥有16人数据。因此,可以考虑该地区是否存在潜在需求。
●山西、湖北、陕西等地则人均选课需求较高。
users_all.groupby(['省份']).agg({'learn_time':['sum','mean','count'],'number_of_classes_now':['sum','mean'],'选课数量':['mean']})输出结果:
用户活跃度分析
# 根据用户的登录时间进行活跃用户可视化
line=Line()
line.add('',
users_all[users_all['recently_logged']>'2020-01-01'].groupby(by='recently_logged').user_id.count().index.tolist(),
users_all[users_all['recently_logged']>'2020-01-01'].groupby(by='recently_logged').user_id.count().values.tolist(),
mark_point=['max'])
line输出结果:
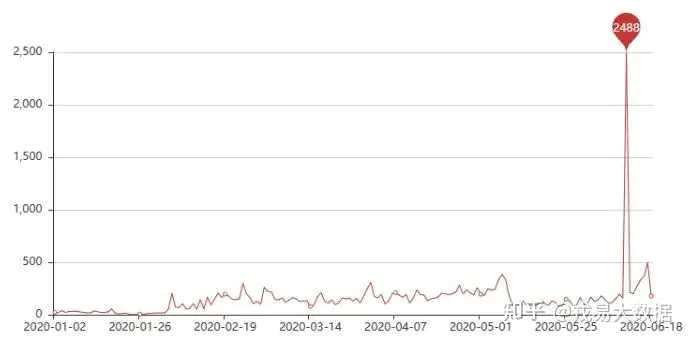
●活跃异常点分析
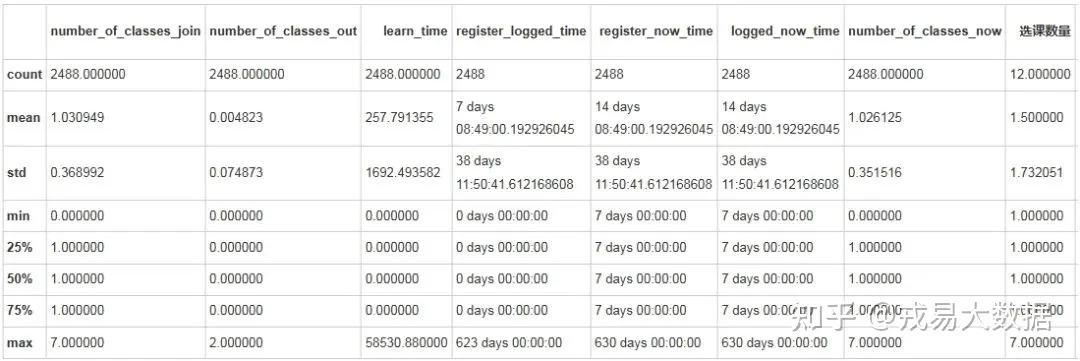
users_all[users_all['recently_logged']=='2020-06-11'].describe()
# 1/4注册时间到距离最新时间都是7天,考虑是进行了推广活动输出结果:
users_all[users_all['recently_logged']=='2020-06-11']输出结果:
2488 rows × 19 columns
#6月11日有一个异常点
#非省份因素
users_all[users_all['recently_logged']=='2020-06-11'].groupby(['省份']).user_id.count()
# 筛选出填写信息差异较大,因此考虑是当时进行学校注册优惠活动?
users_all[users_all['recently_logged']=='2020-06-11'].是否填写学校信息.value_counts()输出结果:
1 2292
0 196
Name: 是否填写学校信息, dtype: int6●工作日活跃度差异分析
# 区分工作日和休息日
for i in range(users_all.shape[0]):
if i == 0:
if is_workday(pd.to_datetime(users_all.iloc[i,2])):
users_all.loc[0,'是否工作日']=1
else:
users_all.loc[0,'是否工作日']=0
else:
if is_workday(pd.to_datetime(users_all.iloc[i,2])):
users_all.iloc[i,-1]=1
else:
users_all.iloc[i,-1]=0
users_all.是否工作日.value_counts()
# 可以看出工作日登录的时间较少,周末登录时间占比相对较高输出结果:
1.0 33044
0.0 10872
Name: 是否工作日, dtype: int64
users_all.groupby(['是否填写学校信息','是否工作日']).user_id.count()输出结果:
是否填写学校信息 是否工作日
0 0.0 8964
1.0 24383
1 0.0 1908
1.0 8661
Name: user_id, dtype: int64用户流失情况分析
ar=[str(aa)[:-14] for aa in users_all.groupby(['logged_now_time']).logged_now_time.count().index.tolist()]
kr=users_all.groupby(['logged_now_time']).logged_now_time.count().values.tolist()
line1=Line()
line1.add('',ar[:],kr[:],mark_line=["average"])
line2=Line()
line2.add('',ar[:140],kr[:140],mark_line=["average"])
line3=Line('')
line3.add('',ar[:30],kr[:30],mark_line=["average"])
line4=Line('')
line4.add('',ar[:10],kr[:10],mark_line=["average"])
grid = Grid()
grid.add(line1, grid_left="55%",grid_top='55%')
grid.add(line2, grid_right="55%",grid_top='55%')
grid.add(line3, grid_left="55%",grid_bottom='55%')
grid.add(line4, grid_right="55%",grid_bottom='55%')
grid输出结果:
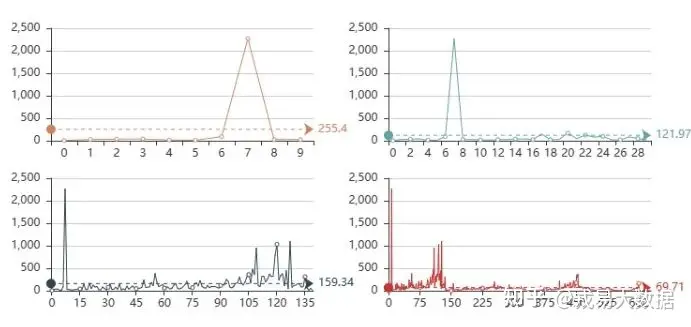
●分省份流失情况分析
users_all.groupby(['省份','logged_now_time']).user_id.count().unstack()
#对流失时间进行划分输出结果:
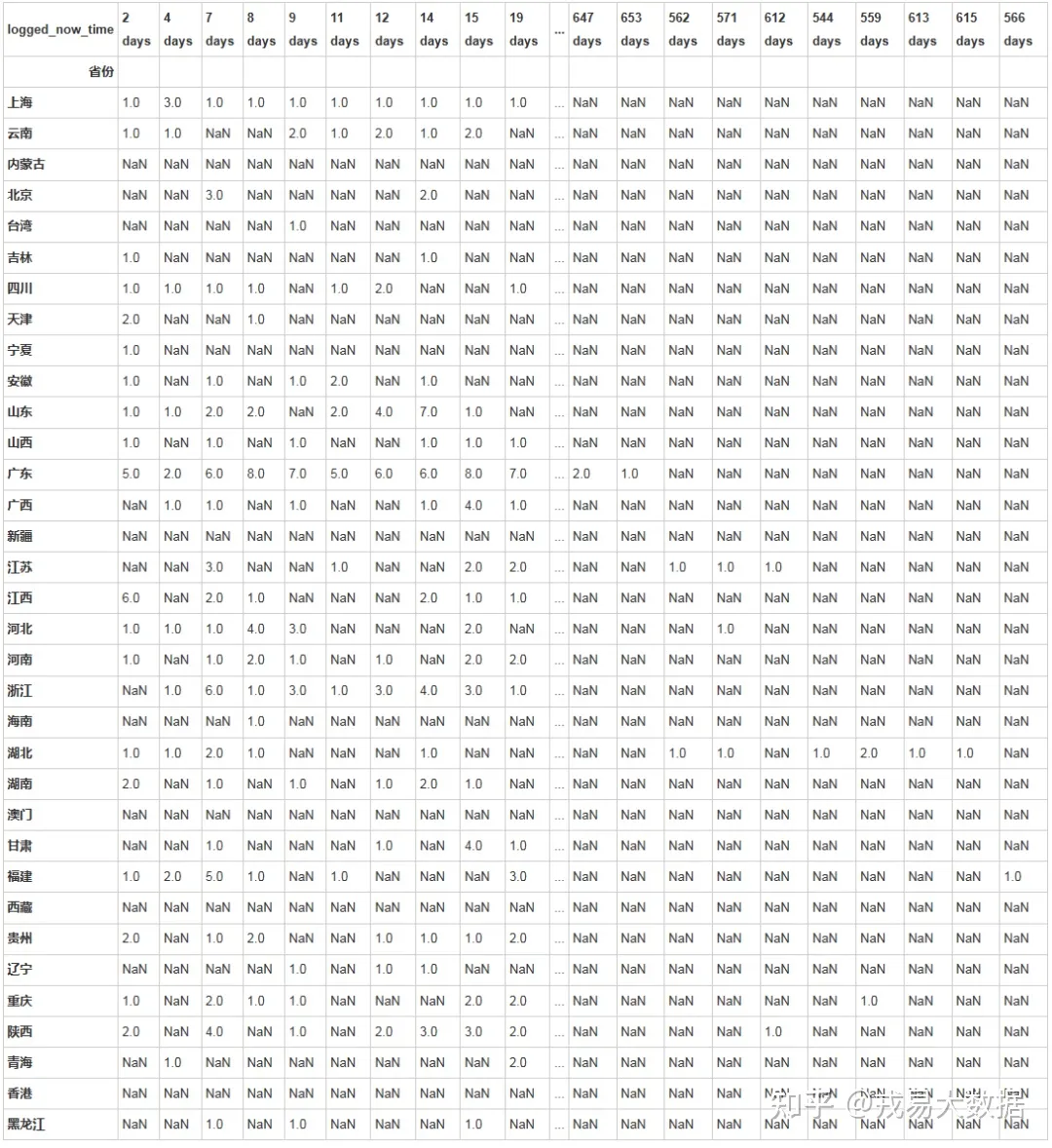
34 rows × 629 columns
for i in range(users_all.shape[0]):
if int(str(users_all.loc[i,'logged_now_time'])[:-14]) > 150:
users_all.loc[i,'流失时间划分']='大于150天'
elif 90 <= int(str(users_all.loc[i,'logged_now_time'])[:-14]) < 150:
users_all.loc[i,'流失时间划分']='大于90天'
elif 30 <= int(str(users_all.loc[i,'logged_now_time'])[:-14]) < 90:
users_all.loc[i,'流失时间划分']='大于30天'
elif 15 <= int(str(users_all.loc[i,'logged_now_time'])[:-14]) < 30:
users_all.loc[i,'流失时间划分']='大于15天'
elif 7 <= int(str(users_all.loc[i,'logged_now_time'])[:-14]) < 15:
users_all.loc[i,'流失时间划分']='大于7天'
elif 0 <= int(str(users_all.loc[i,'logged_now_time'])[:-14]) < 7:
users_all.loc[i,'流失时间划分']='7天内'
users_all输出结果:
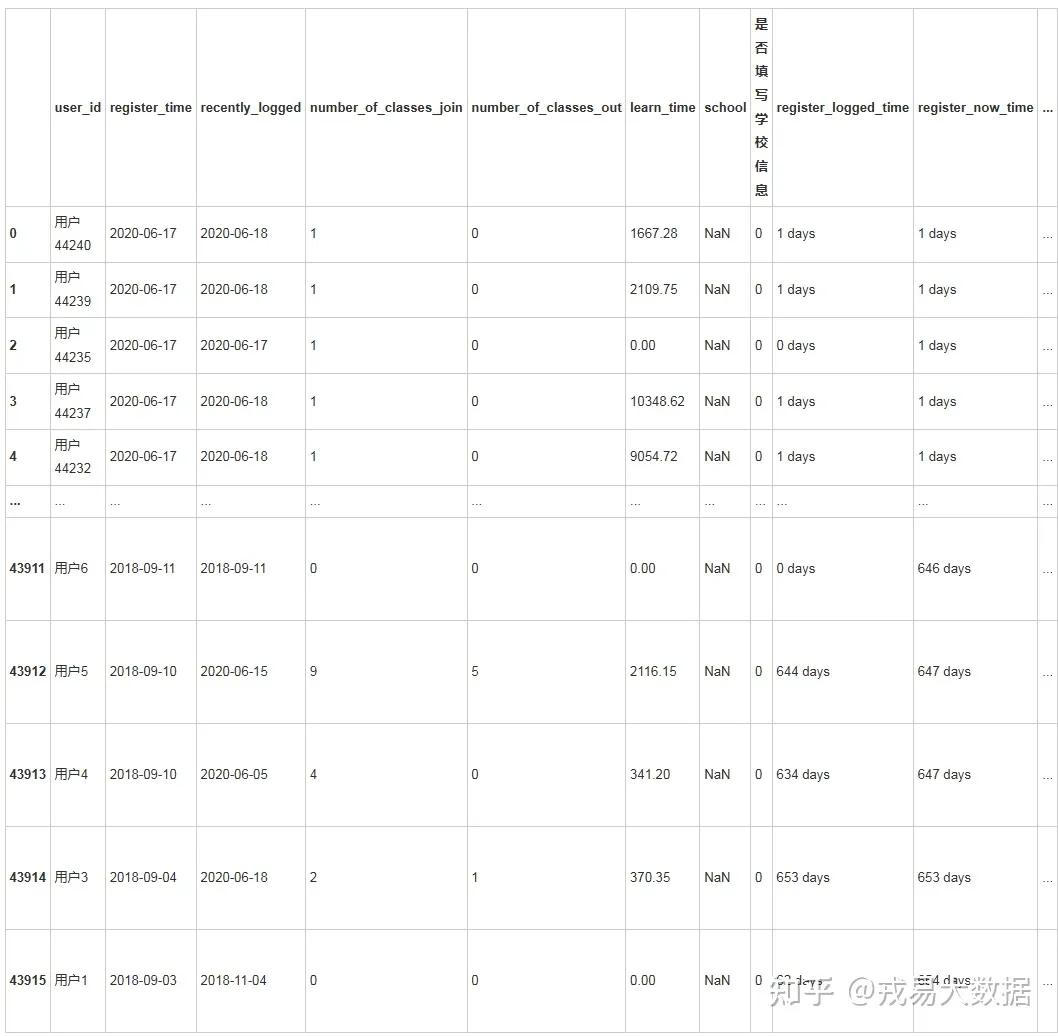
43916 rows × 21 columns
users_all.groupby(['省份','流失时间划分']).user_id.count().unstack()输出结果:
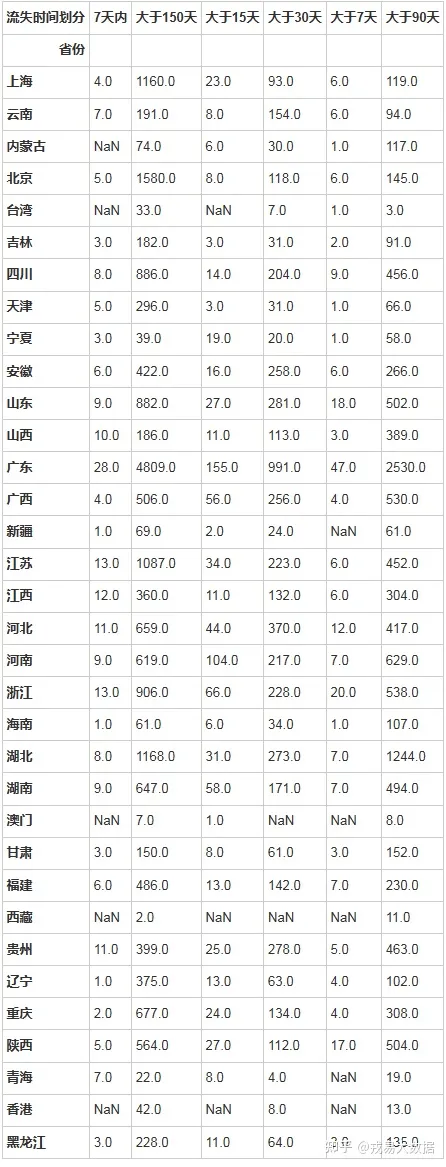
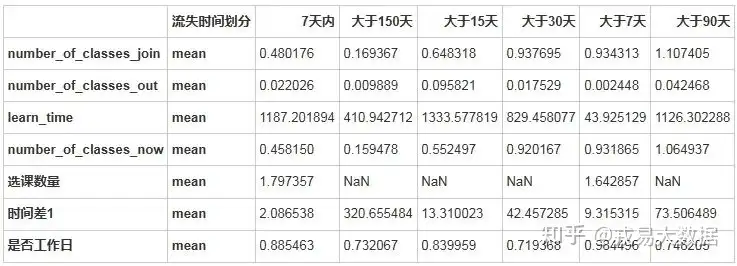
是否选课对流失影响分析
加入课程的用户仍会流失,因为其在7天,15天,30天内人均加入课程并没有太大差异。
选择课程的用户在0-15天内活跃的可能更大。
users_all.groupby(['流失时间划分']).agg(['mean']).T输出结果:
05、用户课程选择分析
选课人数最多课程
bar1=Bar()
bar1.add('',stu_info.course_id.value_counts().index.tolist()[:30],stu_info.course_id.value_counts().values.tolist()[:30]
,mark_line=['average']
,mark_point=['max','min']
, is_datazoom_show=True)
bar1输出结果:
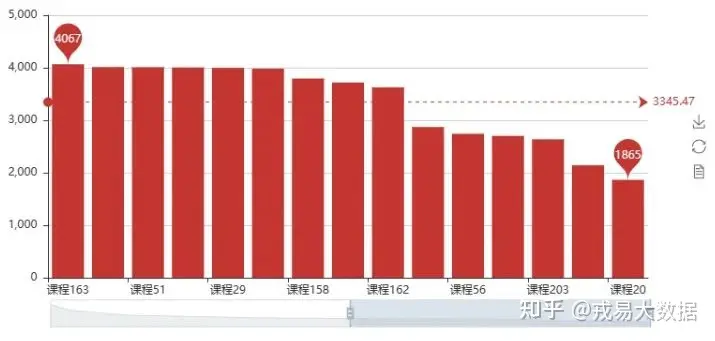
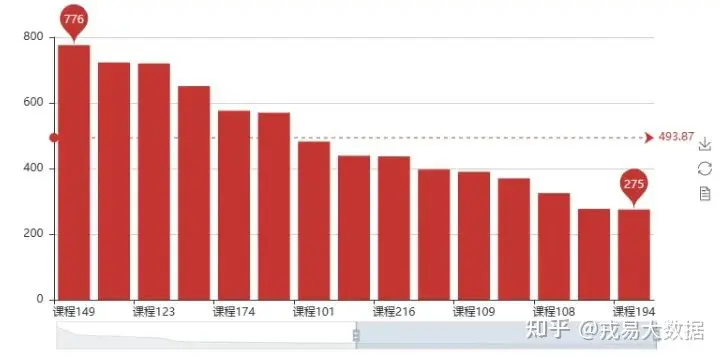
●最受欢迎免费课程
bar1=Bar()
bar1.add('',stu_info[stu_info['price']==0].course_id.value_counts().index.tolist()[:30]
,stu_info[stu_info['price']==0].course_id.value_counts().values.tolist()[:30]
,mark_line=['average']
,mark_point=['max','min']
, is_datazoom_show=True)
bar1输出结果:
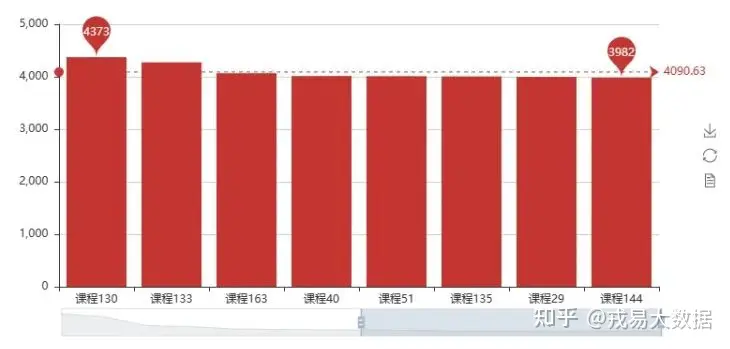
●最受欢迎收费课程
bar1=Bar()
bar1.add('',stu_info[stu_info['price']!=0].course_id.value_counts().index.tolist()[:15],stu_info[stu_info['price']!=0].course_id.value_counts().values.tolist()[:15]
,mark_line=['average']
,mark_point=['max','min']
, is_datazoom_show=True)
bar1输出结果:
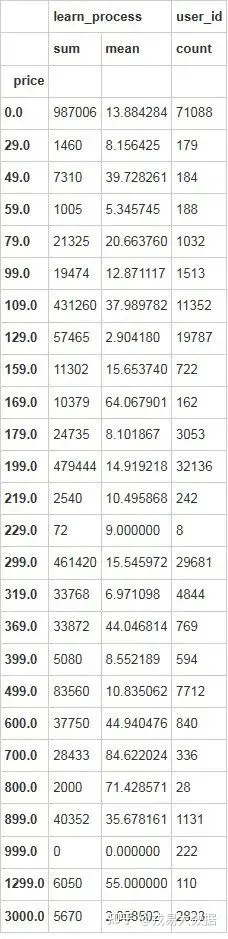
# 可以看出课程的价格为109时候,用户学习时间和数量都相对较优,但是随着价格的上升,用户学习时间突然下降
stu_info.groupby(['price']).agg({'learn_process':['sum','mean'],'user_id':['count']})输出结果:
stu_info[stu_info['price']==129].groupby(['course_id']).agg({'learn_process':['mean','count']})输出结果:

stu_info[stu_info['price']==109].groupby(['course_id']).agg({'learn_process':['mean','count']})
#可以看出在价格为109的时候,选择人数和课程学习时间均较长输出结果:
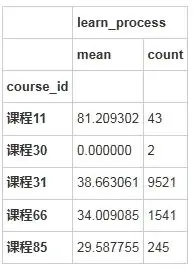
stu_info[stu_info['price']==299].groupby(['course_id']).agg({'learn_process':['mean','count']})输出结果:
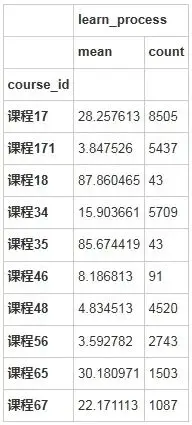
stu_info[stu_info['price']==369].groupby(['course_id']).agg({'learn_process':['mean','count']})输出结果:
学习时间最长的课程
stu_info_course=pd.DataFrame(stu_info.groupby(['course_id']).agg({'learn_process':['mean'],'price':['mean']}))
stu_info_course
# 可以将没有人学习的,或者是相对较少人学习的课程进行删除,而学习时长较长的课程为用户认为较为优质的课程,可以考虑后续重点推广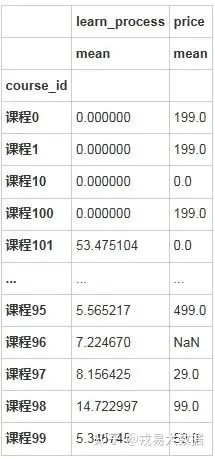
241 rows × 2 columns06、视频:
教育平台数据分析与可视化
博客首页: 一辩过工作室[论文辅导、毕业设计、查重降重]-CSDN博客
官网咨询: 一辩过工作室www.yibianguo.com

















 2298
2298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









