







顺序以周博磊老师强化学习纲要课程为主,增加王树森老师强化学习基础的知识补充,和蘑菇书的知识补充,作为学习记录
第⑦章:基于环境模型的强化学习
主要内容:
- 基于环境模型的强化学习概要
- 环境模型计算
- 基于环境模型的价值函数优化和策略函数优化
一、基于环境模型的强化学习概要
- 关于offline RL
- on-policy与off-policy
- on-policy:采样所用policy与目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新保持与目标policy一致
- off-policy:采样的policy与目标policy不一致,目标policy多次更新,采样后的数据可以多次使用
- online与offline
- online:与环境有交互,通过采集数据进行学习
- offline:不于环境交互,直接通过采集到的轨迹数据学习,达到目标最大化(也可以被定义为数据驱动(data-driven)形式的强化学习问题)

-
learning与planning
-
learning:环境初始未知,agent不知环境如何工作,agent通过不断与环境交互改进策略(形成模型)
-
planning:环境已知,知道环境运作规则,或agent能计算出模型,不需要与环境进行任何交互,只要知道当前状态,就可以寻找最优解。
-
planning是执行动作前做出的决策,称为规划,存在经典的规划算法可以求解相关问题(如MDP中的价值迭代和策略迭代就属于这一类动态规划的优化方法)
-
- offline RL的分类

- 首先,行为策略πβ与环境交互以收集经验并将其存储在静态数据集D中。
- 可选地过滤数据(例如,使用一些启发式或基于值的方法)以仅保留来自高回报轨迹的经验。
- 剩余样本可用于直接学习策略πθ、学习环境模型(动力学模型dynamics model)或轨迹分布的模型。
- 选择学习轨迹分布,我们可以将其用于规划,规划感兴趣的是选择具有最高回报的轨迹。
- 选择学习环境模型,可以选择是使用模型进行规划,还是模型与真实环境生成合成样本来学习策略。
- 选择学习策略,我们可以在演员-评论家算法和模仿学习方法之间进行选择,后者通常依赖于良好的过滤过程或适当的结果来限制学习的策略。
- 这里就涵盖了我们本章所讲的model-based,以及后面会提到的轨迹优化问题。
- on-policy与off-policy
-
环境模型定义(什么是model)
两部分组成:-
奖励函数
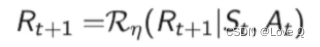
-
状态转移函数(基于当前状态和动作决定下一状态)
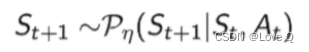
-
通常假设这两个函数之间是独立关系
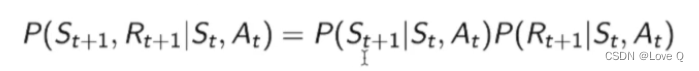
-
- 回顾:
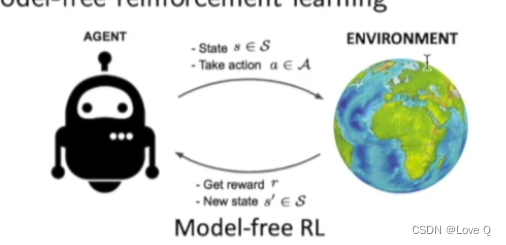
- 之前介绍的方法是model-free方法
- 即没有环境模型(即奖励函数和状态转移函数)
- 直接和环境交互训练策略函数(policy gradient方法)(采集到experience)
- 通过MC和TD方法学习价值函数
- 之前MDP问题中的预测和控制问题是基于环境模型解决的,通过动态规划的方法解决的(也就是上文提到的planning)(现实生活中没有明确的环境模型)
- 对于预测(就是计算每个状态的价值):将贝尔曼期望备份反复迭代,得到一个收敛的价值函数的值。最终得到每个状态的价值‘(策略已经确定)(t表示迭代次数)
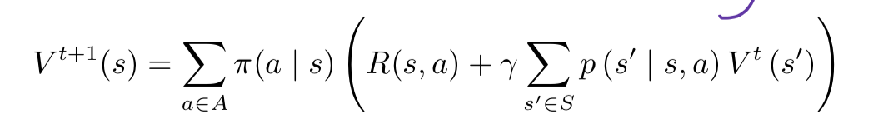
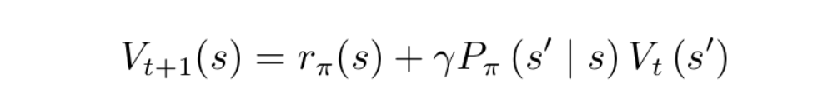
- 对于控制:(寻找最佳策略)
- 策略迭代:
- 包括两部分:策略评估和策略改进
- 保持当前策略不变,估算其状态价值函数
- 得到状态价值函数后,进一步推算其Q函数,对Q函数进行最大化(进行贪心操作argmax)改进策略

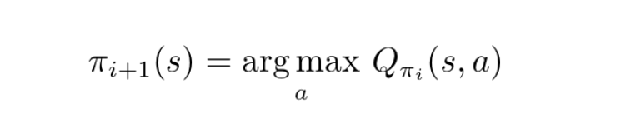
- 价值迭代:将贝尔曼最优方程当做更新规则来进行,直接用该方程进行迭代,迭代多次直到价值函数收敛

- 策略迭代:
- 对于预测(就是计算每个状态的价值):将贝尔曼期望备份反复迭代,得到一个收敛的价值函数的值。最终得到每个状态的价值‘(策略已经确定)(t表示迭代次数)
- 之前介绍的方法是model-free方法
- model-based与MDP的区别(之前的MDP中环境模型是直接给出的)
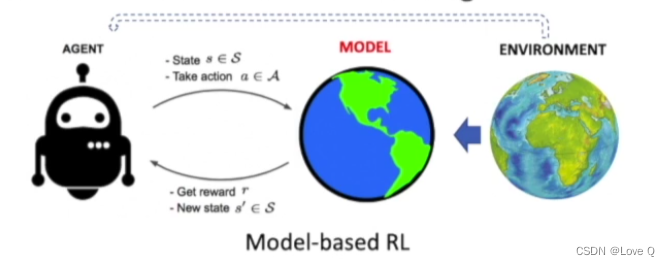
- 通过与环境的交互结果学习一个环境模型(即model,对环境的建模即奖励和状态转移函数)
- 重点:通过experience学习一个环境模型,用于更好的优化价值函数和策略函数的估计(利用planning的算法得到更好的策略)
- 此时agent不仅可以与环境交互,也可以与模型交互

-
model-based的RL算法结构(增加了下半部分)
- experience的用处增加

-
估计环境模型(model learning过程)
-
估计价值函数和策略函数
-
- experience的用处增加
-
model-based优势
-
方法具有更好的样本效率(sample efficiency)
-
本身sample efficiency在强化学习中就很重要
-
之前的算法中是在虚拟环境(游戏、象棋等),可以容易得到大量数据,在这方面影响并不大
-
现实生活中则很重要,例如机器手臂的模拟活动,实际操作很容易使机器手臂损坏
-
-
环境模型可以通过监督学习方法得到有效学习成果(使策略函数和价值函数优化更容易)
-
简单介绍:监督学习简单理解就是训练集本身存在标签(即已知数据及其对应输出),然后进行训练得到最优模型。
-
监督学习目标往往是让计算机去学习我们已经创建好的分类系统(具备对未知数据分类的能力)
-
-
不同算法的sample efficiency(学习系统达到任何选定的目标性能水平所需要的数据量)

(进化算法,gradient-free中无法得到gradient,需要大量尝试才能优化)(on-policy自己采集数据自己更新,每次都要重新采集数据)(off-policy保留了采集数据的策略和要优化的策略)(对model-based来说,对于一些简单问题很容易得到状态转移函数和奖励函数,同时也就很容易实现对价值函数等的优化)
-
-
存在问题
-
环境函数自身也需要通过神经网络等方式拟合,误差增加 (model-free误差来自对价值函数和策略函数的拟合)
-
环境模型的误差使结果进一步不能保证收敛 (即优化过程十分不稳定)
-
二、 环境模型计算
- 第一步目的:训练一个环境模型
- 首先与真实环境交互得到很多experience,从而得到某个状态和动作可能导致的下一奖励和状态等
- 通过监督学习的方法得到环境(可以直接从experience中提取出)
- 奖励函数是一个回归问题(训练一个回归模型)
- 回归问题是指:用于预测输入变量和输出变量之间的关系,特别是输入变量的值发生变化时,输出变量的值随之发生的变化
- 这里就是指对于某个状态的某个动作可以得到的奖励值的拟合
- 状态转移函数是一个密度估计问题(density estimation)
- 即输出是下一个状态的各种可能性,本身是一个概率分布的数据
- 上面两个问题可以通过监督学习方法进行训练和优化
- 选择常见损失函数优化环境模型(MSE均方误差,KL散度等)
- 常见环境模型类型(基于环境本身可以采取不同模型)
- 如下:(查表模型)(线性期望模型)(线性高斯模型)(高斯过程模型)(深度信念网络模型)

- 最简单的table lookup model
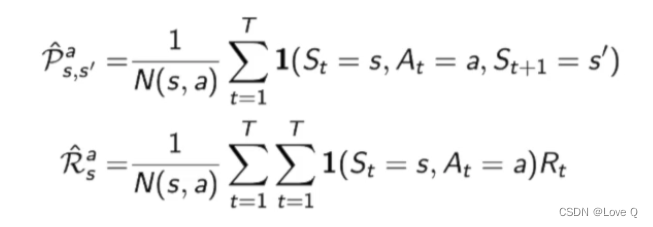
- 通过counting方法估计状态转移函数和奖励函数(数数方法)
- 简单理解就是:通过采样,将相同结果加和,再求出占比,可以知道给定某个状态后,采取某个行为进入下一个状态的概率(或者是通过加权平均估计出奖励函数)
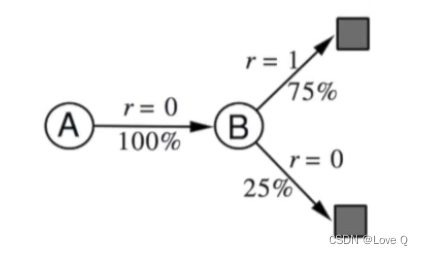
- 举例:
- 通过数据可知:经过A结点1次且下一次到达B,奖励为0;经过B结点8次,两次奖励为0,6次为1,经过计算可得如下结果
- 采样得到的轨迹:

- 状态转移估计:
- 如下:(查表模型)(线性期望模型)(线性高斯模型)(高斯过程模型)(深度信念网络模型)
- 引入模型后的问题
- 此时的结果的准确性,与估计出模型的准确性有很大关联
- 当环境模型并不准确时,规划planning得到的策略也并不准确
- 解决方法:
- 增加置信度的评判
- 如果环境模型置信度低,可以直接使用model-free方法:使用probabilistic model(Bayesian、Gaussian Process)(这种环境模型输出结果的时候自身会带不确定性)
- 基于model的强化学习方法
- model-free RL
- 没有model
- 从真实轨迹中学习策略、价值函数
- model-based RL
- 从真实轨迹中学习model
- 从模拟经验中估计策略、价值函数
- Dyna(dina)
- 从真实轨迹中学习model
- 从真实和模拟经验中估计策略、价值函数
- 方法介绍:
- 可以补充样本数量少的问题(有两种experience)
- real experience作用一是直接更新价值函数,作用二是估计模型
- 得到model后,得到模拟数据和真实数据结合,进一步更新函数(优势就在于可以用大量的模拟数据填补真实数据缺少的问题)
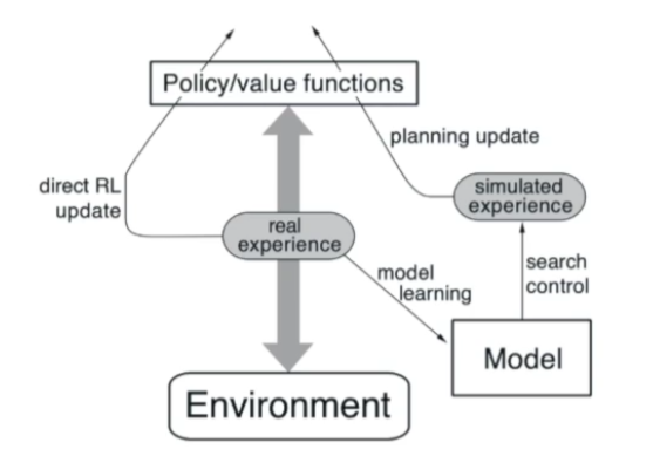
- 先用model-free的方法估计Q函数(abcd),再利用(e)估计环境模型model,然后对环境模型进行采样得到大量模拟数据,对Q函数进行更新

- 可以补充样本数量少的问题(有两种experience)
- model-free RL
三、基于环境模型的价值函数优化和策略函数优化
-
回顾:model-free中的基于价值函数和策略函数的优化
-
基于价值函数优化:Sarsa、Q-learning(估计状态价值)、DQN(使用神经网络)等


-
基于策略函数优化:Policy Gradient、Actor-Critic(A2C)等

-
-
环境模型两种利用方法(第一步:得到环境模型)
-
基于环境模型的价值函数优化(对环境模型进行采样,作为真实轨迹进行价值函数优化)(比较标准的流程如下)

-
基于环境模型的策略函数优化(将环境模型引入策略优化)
-
- 价值函数优化(直接方法)(得到模型过后如何进行planning):


- 对环境模型直接进行采样得到轨迹
- 利用采样结果使用之前的方法进一步计算(指对价值函数的计算) Monte-Carlo control Sarse Q-learning
- 策略函数优化:
- 关键:
- 将模型整合到policy gradient中(PG是model free)
- PG中,在公式推导过程中,环境模型中的状态转移函数其实并不需要(求导后为0)

- 探究在已知环境模型的情况下如何进一步优化PG方法
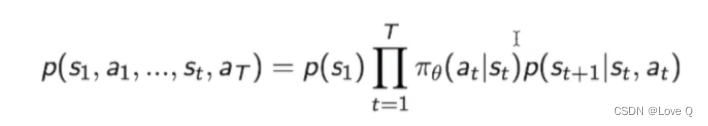
- 与控制论、最优控制的关系(也就是说,除了估计出模型外,具体的后续操作都是用的最优控制的思想)(也就是说,存在模型之后,就直接使用了最优控制的思想)
- model-based的策略优化受控制论影响深远(控制过程是为了优化controller)
- 在控制问题中,我们通过优化轨迹来最小化代价函数或者最大化回报函数
- 最优控制,是指在约束条件下达到最优的系统表现(就类似于在强化学习中在指定环境中希望得到的奖励最大)
- 此时环境模型称为system dynamics(系统动力学)函数s=f
- 代价函数(cost function)是对整个系统中需要优化的指标的汇总,通过使代价函数尽可能小来得到整个系统的最优表现(因为系统中会有很多优化指标)
- optimal control问题(system dynamics已知)(system dynamics就是环境模型)(就是这个f函数)

- cost function可以看做是RL中的negative reward,每一步控制都希望cost function可以尽可能的小,在满足这个环境模型即这个f函数的条件下对action动作进行优化。这样就是将环境模型加入了动作优化问题。
- 最优控制问题在控制理论中有很多现成算法可以对其进行轨迹优化:LQR / iLQR等(轨迹优化,也就是动作的选择)
- 所以最优控制问题与强化学习的基于策略优化思想有很深远的联系,接下来就是通过介绍将model learning加入最优控制问题的求解来表现model-based的策略优化问题思想(即上面所提到的轨迹优化问题)
- 要让车辆避开障碍物到达目标点,且system dynamics已知,那么这就是一个轨迹优化的最优控制问题

- model-based的策略优化受控制论影响深远(控制过程是为了优化controller)
- optimal contorl与model based方法的结合(基于模型的轨迹优化方法)
- 算法一:

- 由于dynamics model未知,将model learning和 trajectory optimization(轨迹优化)n结合
- 首先,运行基础策略得到轨迹(这里是随机策略,得到很多轨迹D)
- 利用轨迹学习dynamics model 即f使其可以最小化MSE(此时model由未知变已知)
- 利用optimal control方法优化,了解每一步的动作
- 2中利用强监督方法估计模型
- 3中利用LQR等方法计算最佳轨迹
- 问题:drifting,前期误差会很影响最终结果(也就是说在轨迹进行优化的时候,如果在最早的时候出现一点误差,那么产生的轨迹可能就会离得非常远了)而且模型有可能会掉到一个之前没有采样到的区域
- 解决方法是在算法1中加入迭代过程得到算法2

- 解决方法是在算法1中加入迭代过程得到算法2
- 算法二:

- 利用基础策略采集数据(与1相同)
- 循环(iteration)
- 利用轨迹估计dynamics model,最小化MSE
- 利用model轨迹优化得到动作,产生action后就会得到一条新的轨迹(即根据model决定了整个轨迹上的所有动作)(产生新轨迹,可能产生之前未采集到轨迹)
- 补充之前没有出现的状态动作等进入训练数据
- 实现model的不断更新,从而得到更准确的模型
- 问题:在估计模型之前就执行all planned actions(即估计出的完整轨迹),可能导致轨迹一开始就离需要轨迹很远(也就是循环中第二步利用model得到的动作后会得到一个新的完整轨迹)
- 算法三:

- 进一步改进:执行每一步都将后续轨迹估计出来
- 即MPC(Model Predictive Control)(在自动驾驶和控制里的常用算法)
- 对所有轨迹进行优化,但是执行时只执行最前面的轨迹,循环
- 产生整个轨迹,但实际只执行一步,执行完后再重新估计
- 将MPC的思想应用到model learning思想中
- 与2 的区别在于,在学习到model之后,首先根据model估计动作得到轨迹,但只执行轨迹的第一步,保存后继续迭代,根据model估计动作得到整个轨迹,依旧只执行一步(2是轨迹全部执行)

- 与2 的区别在于,在学习到model之后,首先根据model估计动作得到轨迹,但只执行轨迹的第一步,保存后继续迭代,根据model估计动作得到整个轨迹,依旧只执行一步(2是轨迹全部执行)
- 算法四:最终算法(结合了policy learning 和model learning 和optimal learning)(此时才是得到了基于环境模型的策略函数优化)
- 流程:
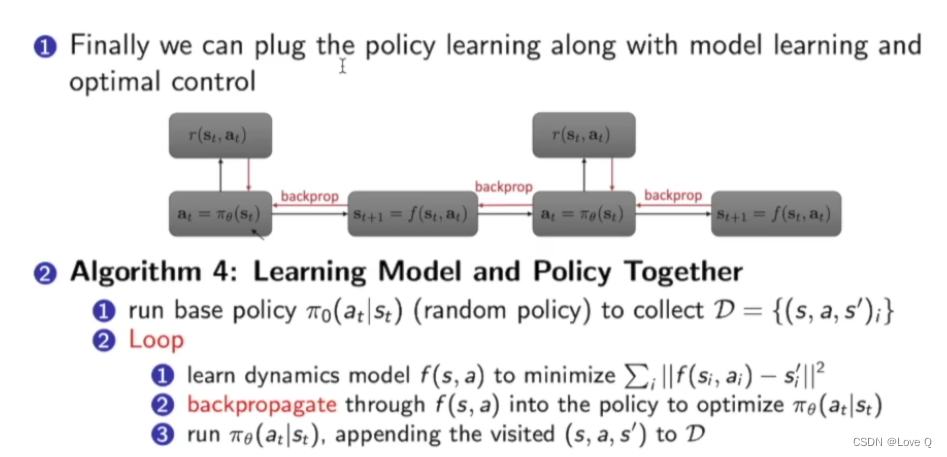
- 第一步同样是得到轨迹
- Loop
- 学习得到环境模型(model learning)
- 对环境模型进行反向传播更新参数,优化我们想得到的policy
- 通过我们2中产生的policy进一步产生新的data放入data set中
- 补充:黑盒白盒模型
- 黑盒模型:
- 不关心奖励函数和状态转移函数的计算方法
- 训练模型的目的只是用于采样数据
- 白盒模型:
- 环境模型的函数表示已知
- 可以通过概率密度和梯度两种信息进行学习
- 同样可以用于采集数据
- 黑盒模型:
- 参数化模型(dynamics使用什么模型来拟合)(也就是环境模型用什么来拟合)
- global model(每个状态都用同一个模型):
- 直接使用一个大型神经网络拟合
- 优势:本身更具有表现力,可以使用大量数据进行拟合
- 缺点:需要大量数据,数据少的话无法达到预期效果
- local model:(现在多用这个梯度)
- 使用随时间变化(time-varying)的linear-Gaussian dynamics(随不同状态有不同模型)
- 优势:数据有效性高
- 缺点:数据集大时非常缓慢,且会有很多个model(每个点都需要一个local model)
- 可以简单定义为

- 状态转移概率本身是高斯分布
- 环境模型f可以定义为线性动态系统(linear dynamic system)
- 对其求梯度可以得到local gradient

- 可以直接估计参数At和Bt,得到参数后可以采样得到下一状态
- 对local model进行拟合

- The probabilistic approximator model的好处是它会把它不确定的区域显示出来,最右边这个图我们可以看到有些区域是有观测的,区域不确定性是为0的;
- 对于灰色区域并没有得到观测点,不确定性是非常高的。
后面一部分得到的观测点是比较密集的,所以不确定性是比较低的。 - 这样也是time-varying linear-Gaussian的好处,可以对不确定性进行建模。
- 此处借鉴了博主Wwwilling的原创文章,原文链接:https://blog.csdn.net/qq_43058281/article/details/114646283
- global model(每个状态都用同一个模型):
- 流程:
- 算法一:
- 关键:















 1676
1676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









