







思路
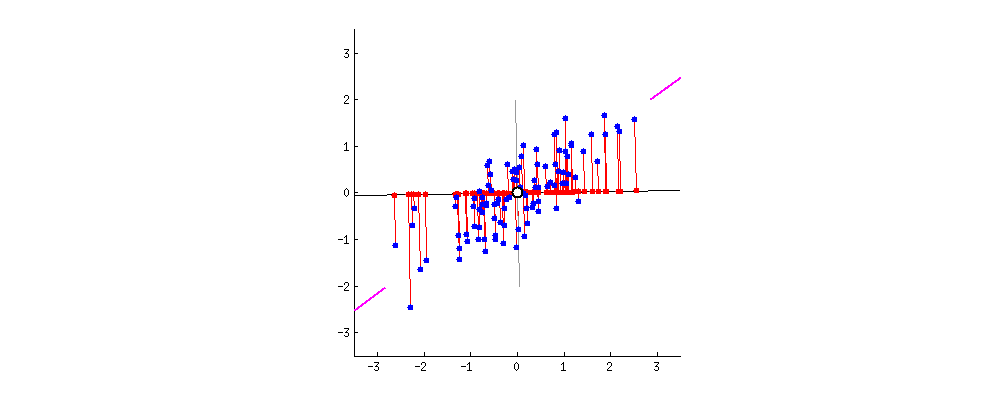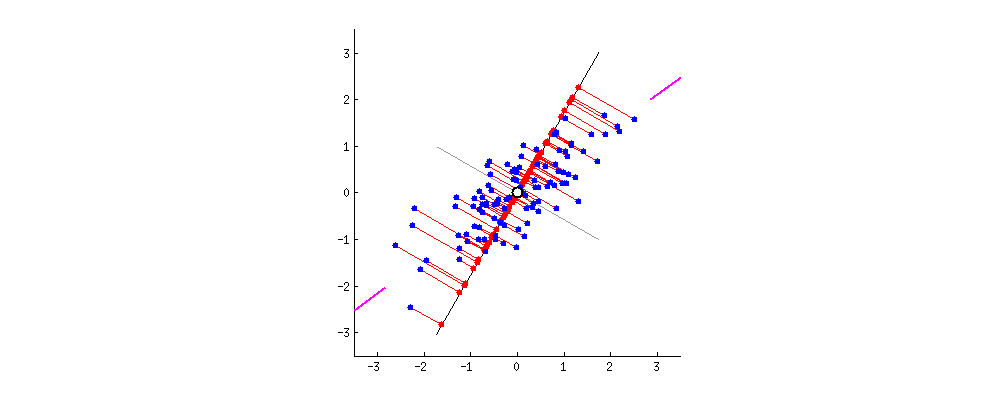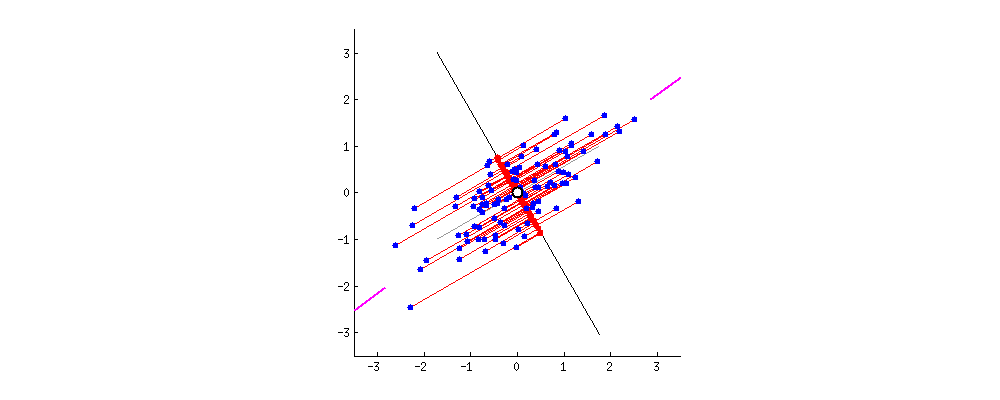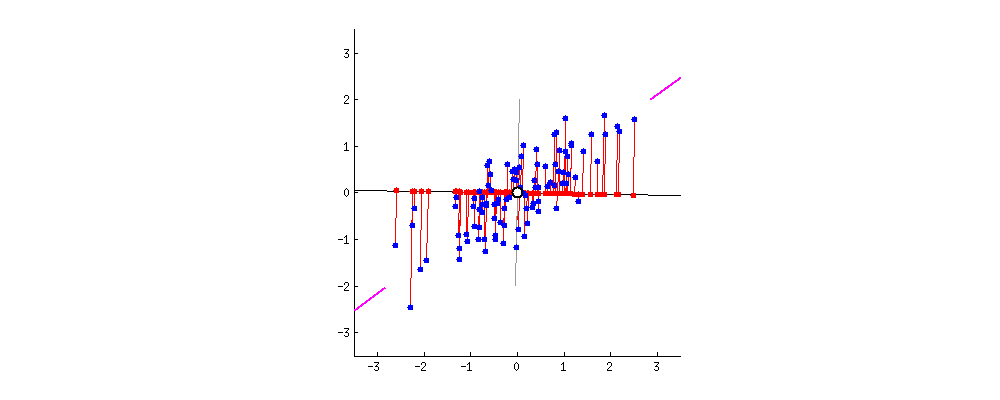
主成分分析、Principal Component Analysis、PCA的推导有很多种途径,我们选择一种,容易理解的来讲解。我们的目的是降维,但是不能胡乱的降,观察下面这组数据:

我们画的是二维情况,但是具体到高维也是可以的。
μ
是我们目测一个比较好的降维之后的投影方向。但是这只是目测,我们怎么规定这个准则呢?我们规定:
投影之后样本竟可能分散,即样本方差尽可能大。
推导
样本点
xi
除了可以看成点,还可以看成一条以原点为起点,
xi
点为终点的向量。样本点
xi
在坐标轴上的投影长度为:
length=||xi||⋅cos(θ)
其中 θ 为向量 μ 和向量 x 的夹角。我们带入向量内积计算公式得:
length=xi⋅μ||μ||
令 ||μ||=1 ,则可以把这个长度转化成坐标,有在 μ 坐标轴上新坐标为:
yi=xi⋅μ=xTiμ
所以在新坐标里样本方差为
1m∑im(yi−y)2
y 是样本均值。我们样本去均值化就方便计算(注:这步去均值化在变换前就可以实施)。所以我们的目标就是:
max 1m∑imyi2=1m∑im(xiTμ)2=1m∑imμTxixiTμ=μT(1m∑imxixiT)μ
latex这个 μ 实在是加粗不能,凑合看吧,它是个向量。
我把问题写清楚一点:
{max μTMμs.t. μTμ=1
其中M当然等于 (1/m∑mixixiT) 啦~
用拉格朗日乘数法解决这个优化问题:
L(μ,λ)=μTMμ−λ(μTμ−1)
∇μL=Mμ−λμ=0
得到
Mμ=λμ
至此我们知道啦。搞了半天, μ 是特征向量, λ 就是对应的特征值啊!
整理与降维
我们回到方差最大化。发现方差为:
μTMμ=λ
所以特征值越大,我们用对应特征向量作为坐标轴(基)变换后的样本方差也就越大。如果我们选择前k个特征值对应的特征向量,则能达到降维的目的~
降维前:
x=x1⋅v1+x2⋅v2+...+xm⋅vm
降维后:
y=y1⋅μ1+y2⋅μ2+...+ym⋅μm
其中上标表示第几维坐标。















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









