






在课题研究时发现了LancsBox这个好东西,遂计划用其对100篇机械工程英文分析,构建语料库,并进行分析与校正,得到与研究方向适配度高的模型,得到相应的分析结果(图、表)。在网上查询所得资料较少,且难于理解,故自己动手丰衣足食,将学习经历记录如下。若侵立删
1.下载安装
最新版LancsBox6.0下载地址:#LancsBox: Lancaster University corpus toolbox
LancsBox官网会根据下载者的电脑推荐下载版本,下载后点击安装即可,无复杂操作。下载路径不要出现中文。
2.文献参考
Lancsbox6.0是一款多功能语料分析工具,适用于语料库语言学、翻译学、外语教学等领域的研究者。它可以用于计算与文本的频次结构相关的计量指标,除此之外,它还提供了统计功能和增加了可视化显示节点词的搭配关系。
[1] 杨苑.基于语料库的中国研究生英文学术论文中的非正式语体特征对比研究[C]//中国英汉语比较研究会.英汉语比较与翻译15.上海海事学,2023:2.DOI:10.26914/c.cnkihy.2023.114002.
LancsBox 作为英国兰卡斯特大学 VaclavBrezina 团队开发的新一代语料库软件。说它新,不仅仅是发行时间上的新,而且在理念和功能上比同类工具要新。语料库同行对当下流行的Wordsmith Tools和AntConc两款软件的功能比较熟悉。
LancsBox 不仅具备目前主流语料库 软件的常规功能,如关键词检索(KWIC)、检索词分布(Whelk)和文本工具(Text) 等,还创新优化了数据处理和信息呈现等方面功能,其中最为核心的就是搭配图解 (GraphColl),能够提供语料加工如POS、检索词汇的搭配词表和可视化搭配图(可视化显示节点词的搭配关系)。
LancsBox最大的特点是在常用功能后面植入了统计功能,统计功能可以根据用户需要进行调节。
LancsBox不仅能提供主流语料库软件具备的常规功能,还在检索方式、统计算法、数据处理和信息呈现等方面进行了创新性优化。该软件具有多项特色:
(1)支持智能检索词类、语法、语义标注和基于词类的精细化检索。
(2)提供丰富的统计算法,且支持自定义。
(3)支持多层次拓展搭配网络。
(4)数据可视化。
(5)可分析英、汉、法、德、俄等20多种语言。
(6)可读取txt、xml、doc、pdf、odt、xls、docx、xlsx、zip、csv等多格式文本。
(7)支持本地和部分在线语料库双向导入。
(8)可同时导入和分析多个语料库,且支持同屏对比。
检索使用语料库的方法可分为基于词形的方法(word-based method)和基于范畴的方法(category-based method)(Hunston2002)。前者一般基于生语料库,对语料库中的词形进行选择、排序、匹配、计算和统计,生成词表、主题词表、索引、搭配和N元结构;而后者则基于赋码语料库,以各种范畴(如词类)为基础进行类似的检索和分析。
#LancsBox v.4.5.(Brezinaet al.2018)共有六大功能模块,分别是:关键词检索(KWIC)、检索词分布(Whelk)、搭配图解(GraphColl)、N元结构(N-grams)、词汇模块(Words)和文本工具(Text)。本文介绍了#LancsBox的其他五个功能模块,并以实例演示各模块的特色功能、操作步骤以及核心模块搭配图解在语言研究中的应用。
[3] 王靓婧,潘璠.新一代可视化语料库软件#LancsBox的核心功能和应用前景[J].当代外语研究,2020,(05):77-90.
国内对该语料库软件的了解和使用还处于起步阶段,我们对其功能进行简要介绍,以期能为我们将来的语料库语言学研究乃至其他社会科学研究服务。
下载语料库和词表。#LancsBox允许使用现有免费的八个语料库,包括LCMC,Brown,L-O-B,Climate,Newsbook,Shakespeare,V-U-L-C,BNC64,还有一个其他资源列表。
本文介绍了该软件的简要使用 ,包括下载和运行#LancsBox 4.5、KWIC工具、GraphColl工具、Whelk工具、Words Tool工具、N-gram Tool工具、Text Tool工具。
[4]杨石乔.兰卡斯特大学(语言、话语与社会)语料库语言学2019暑期学校综述[J].深圳职业技术学院学报,2020,19(04):24-30.DOI:10.13899/j.cnki.szptxb.2020.04.004.
本文主要涉及LancsBox的简要使用方法,以及其在机械工程领域对中英文语料库的分析。
3.功能简介
LancsBox6.0是一个强大的文本分析工具,具有以下七个主要功能:
-
KWIC (Key Word in Context): 允许用户查看特定关键词在文本中的上下文,帮助理解词汇的用法和语境。
-
GraphColl: 用于可视化词汇之间的搭配关系,展示词汇如何在语料库中共同出现。
-
Whelk: 提供对词汇和短语的深入分析,特别关注其语义和用法。
-
Words: 显示文本中词汇的各种统计信息,包括词频和词汇多样性。
-
Ngrams: 分析文本中的n元组(如二元组、三元组等),帮助识别常见的词组和模式。
-
Text: 允许用户直接分析和编辑文本,进行更细致的文本处理。
-
Wizard: 提供向导式的界面,帮助用户更轻松地进行复杂的分析任务。
LancsBox 6.0 支持多种文件类型进行文本分析,主要格式包括:
- 纯文本文件(.txt):简单文本文档的标准文本格式。
- CSV 文件 (.csv):逗号分隔值格式,适用于结构化数据。
- Excel 文件(.xls、.xlsx):Microsoft Excel 电子表格格式,允许进行结构化数据分析。
- XML 文件(.xml):用于结构化数据表示的可扩展标记语言文件。
- HTML 文件(.html):用于网络内容的超文本标记语言文件。
3.1 关键词检索-KWIC(Key Word in Context)
3.1.1 功能概述
KWIC 允许用户查看特定关键词在上下文中的出现方式,提供了一个结构化的视图,展示关键词前后的文本片段。这有助于研究者理解词汇的用法、语义和搭配。
3.1.2 主要特点
- 上下文展示: 用户可以选择一个或多个关键词,KWIC 会显示这些词在文本中出现的上下文,通常包括关键词前后各几词。
- 高亮显示: 关键词在上下文中会被高亮显示,便于快速识别。
- 可排序和过滤: 用户可以根据需要对结果进行排序和过滤,例如按频率、字母顺序等。
- 多语料库支持: 可以在不同的语料库中执行 KWIC 分析,适用于多种语言和文本类型。
3.1.3 应用场景
- 语言研究: 研究者可以分析特定词汇的用法和变化,了解语言的使用模式。
- 语义分析: 通过查看关键词的上下文,研究者可以探讨词汇的语义和搭配关系。
- 文本比较: 可以在不同文本之间进行比较,分析关键词的使用差异。
3.1.4 使用方法
- 选择关键词: 用户输入想要分析的关键词。
- 查看结果: 系统生成包含关键词上下文的列表,用户可以浏览和分析。
- 导出数据: 用户可以将结果导出为文本或其他格式,以便进一步分析或报告。
3.2 搭配图解-GraphColl(Collocation Graph)
3.2.1 功能概述
GraphColl 提供了一种直观的方式来展示和分析不同词汇如何在文本中共同出现。通过图形化的方式,用户可以轻松识别出常见的搭配和词汇关系。
3.2.2 主要特点
- 可视化展示: 通过图形图表展示词汇之间的搭配关系,使得复杂的数据变得易于理解。
- 搭配强度: GraphColl 通常显示词汇之间的搭配强度,即它们在语料库中共同出现的频率。
- 互动性: 用户可以与图表进行互动,例如点击某个词汇以查看与之搭配的其他词汇和相关数据。
- 多种布局: 提供不同的图形布局(如网络图、条形图等),以适应不同的分析需求。
3.2.3 应用场景
- 语言研究: 研究者可以分析常见的搭配和短语,了解词汇的使用模式和语境。
- 词汇教学: 教师可以利用搭配图帮助学生理解词汇之间的关系,提高词汇学习的有效性。
- 文本分析: 在分析特定文本时,GraphColl 能帮助识别关键词的搭配,提高文本理解的深度。
3.2.4 使用方法
- 选择词汇: 用户可以选择分析的关键词或词组。
- 生成搭配图: 系统会生成包含该词汇及其搭配词的图表。
- 分析结果: 用户可以查看各词汇之间的关系,深入分析它们的搭配强度和使用频率。
3.3 检索词分布-Whelk (Vocabulary Analysis)
3.3.1 功能概述
Whelk 提供了一种综合的方法来分析单词和短语,包括它们的语法、语义和用法。这一功能旨在帮助研究者更深入地理解词汇的特性和在语料库中的表现。
3.3.2 主要特点
- 词汇特征分析: Whelk 能够分析单词的各种属性,包括词性、词义、搭配等,帮助用户理解词汇的多样性。
- 语法结构: 提供对词汇在句子中的语法功能的分析,支持用户了解词汇如何在不同上下文中运作。
- 语义关系: Whelk 还可以探讨词汇之间的语义关系,例如同义词、反义词和上下位词的关系。
- 例句检索: 用户可以查看包含特定词汇的例句,以便更好地理解其用法和语境。
3.3.3 应用场景
- 语言学研究: 研究者可以利用 Whelk 分析特定词汇的用法及其在不同语境中的变化。
- 词汇教学: 教师可以利用该功能帮助学生理解词汇的多层次含义和用法,提高学习效果。
- 文本分析: Whelk 可用于分析特定文本中的关键词,揭示其在上下文中的重要性和功能。
3.3.4 使用方法
- 选择词汇: 用户输入要分析的单词或短语。
- 查看分析结果: 系统将展示该词汇的各种特征和相关信息,包括词性、搭配、示例等。
- 深入研究: 用户可以根据需要进一步探索词汇的语义和语法结构。
3.4 检索词统计-Words (Word Statistics)
3.4.1 功能概述
Words 功能提供了一种系统的方法来分析文本中的词汇,帮助用户了解词汇的使用频率、多样性以及其他相关统计信息。
3.4.2 主要特点
- 词频统计: 用户可以查看文本中每个单词出现的频率,识别高频词和低频词。
- 词汇多样性: 计算文本的词汇多样性指标,如类型-令牌比(TTR),帮助评估文本的语言丰富程度。
- 停用词处理: 可以选择是否排除常见的停用词(如“的”、“是”、“在”等),以便更精确地分析有意义的词汇。
- 词汇分布: 提供词汇在文本中的分布情况,帮助用户了解关键词在不同段落或章节中的出现频率。
- 图表和可视化: 生成图表(如词频柱状图)以便于用户直观理解统计结果。
3.4.3 应用场景
- 语言研究: 研究者可以使用 Words 功能分析特定文本的词汇特征,了解语言使用的模式。
- 文本比较: 可以对不同文本进行比较,分析它们的词汇使用差异。
- 写作分析: 作家和编辑可以利用该功能评估文本的语言风格和复杂度。
3.4.4 使用方法
- 导入文本: 用户上传或粘贴要分析的文本。
- 生成统计报告: 系统会自动分析文本并生成包含词频、词汇多样性等信息的报告。
- 查看和导出结果: 用户可以查看分析结果并选择导出为不同格式以便进一步使用。
3.5 N元组分析-Ngrams (N-grams Analysis)
3.5.1 功能概述
Ngrams 功能允许用户识别和分析文本中的常见词组或短语,帮助研究者理解语言的使用模式和搭配关系。
3.5.2 主要特点
- 多种 n 值: 用户可以选择分析不同数量的词(如二元组、三元组等),以适应不同的研究需求。
- 频率统计: 提供每个 n 元组在文本中出现的频率,帮助用户识别常见的短语或搭配。
- 上下文分析: 通过分析 n 元组的上下文,用户可以更好地理解这些短语的用法和语境。
- 可视化展示: 生成图表或列表,以便用户直观查看 n 元组的频率和分布情况。
- 过滤选项: 用户可以设置过滤条件,例如排除常见的停用词,以便更准确地分析有意义的 n 元组。
3.5.3 应用场景
- 语言研究: 研究者可以利用 Ngrams 功能分析特定短语的使用情况,探索语言的搭配和语义特征。
- 文本分析: 在内容分析中,识别常见的二元组或三元组有助于揭示文本的主题和结构。
- 自然语言处理: Ngrams 分析在机器学习和文本挖掘中广泛应用,帮助构建语言模型和信息提取系统。
3.5.4 使用方法
- 导入文本: 用户上传或粘贴要分析的文本。
- 选择 n 值: 用户选择要分析的 n 值(如 2、3 等)。
- 生成 n 元组报告: 系统会自动分析文本并生成包含 n 元组及其频率的报告。
- 查看和导出结果: 用户可以查看分析结果并选择导出为不同格式以便进一步使用。
3.6 文本工具-Text (Text Analysis)
3.6.1 功能概述
Text 功能提供一个界面,用户可以在其中导入、编辑和分析文本。这一功能允许研究者对文本进行各种处理,以便进行更深入的分析。
3.6.2 主要特点
- 文本导入和编辑: 用户可以上传现有的文本文件,或者直接在界面中输入或粘贴文本内容。
- 文本清洗: 提供工具用于清理文本,例如去除多余的空格、标点和特殊字符,以确保分析的准确性。
- 语料库构建: 允许用户创建和管理自己的语料库,便于后续分析和比较。
- 基本统计: 提供关于文本的基本统计信息,包括字数、句子数和段落数等,帮助用户快速了解文本结构。
- 搜索和高亮: 用户可以在文本中搜索特定词汇或短语,并高亮显示其在文本中的位置,便于分析。
3.6.3 应用场景
- 语言研究: 研究者可以利用 Text 功能分析特定文本中的语言使用,进行语法和语义分析。
- 文本比较: 可以将不同文本进行比较,分析它们的结构和内容差异。
- 写作支持: 作家或编辑可以在此功能中进行文本编辑和修改,提升写作质量。
3.6.4 使用方法
- 上传或输入文本: 用户可以选择上传文件或直接在文本框中输入内容。
- 进行文本处理: 使用提供的工具进行文本清洗和统计分析。
- 查看分析结果: 系统会生成有关文本的各种统计信息和分析结果。
- 导出结果: 用户可以将处理后的文本和分析结果导出为不同格式,以便进一步使用。
3.7 向导-Wizard (Wizard)
3.7.1 功能概述
Wizard 功能通过逐步引导用户完成各种分析过程,使得即使是没有技术背景的用户也能轻松使用 LancsBox 的高级功能。它旨在简化操作流程,降低使用门槛。
3.7.2 主要特点
- 分步指导: Wizard 提供逐步的指引,用户可以跟随向导完成特定的分析任务,如选择分析类型、输入文本和设置参数。
- 自定义选项: 用户在向导的每一步都可以根据自己的需求进行自定义设置,例如选择要分析的词汇、文本范围、分析方法等。
- 实时反馈: 在每一步中,用户可以看到实时反馈,帮助他们理解所做的选择及其对分析结果的影响。
- 多种分析类型: Wizard 支持多种分析类型,包括 KWIC、搭配分析、n 元组分析等,用户可以根据研究目标选择合适的分析方法。
- 结果导出: 完成分析后,用户可以轻松导出结果,便于后续的研究和报告编写。
3.7.3 应用场景
- 语言研究: 研究者可以利用 Wizard 功能进行复杂的文本分析,尤其适合初学者或对工具不熟悉的用户。
- 教育培训: 教师可以使用 Wizard 帮助学生掌握文本分析的基本方法和技巧。
- 数据分析: 在需要处理大量文本数据时,Wizard 提供了一个有效的解决方案,帮助用户系统地分析数据。
3.7.4 使用方法
- 启动 Wizard: 用户在 LancsBox 中选择 Wizard 功能,开始分析过程。
- 按照步骤操作: 根据向导的提示,用户逐步输入文本、选择分析类型和设置参数。
- 查看和分析结果: 完成所有步骤后,用户可以查看分析结果,并进行必要的调整或导出。
4. 实例分析
4.1 建立语料库
在学术网站下载文献的PDF或其他格式→保存在指定文件夹中(建议将需要分析的内容,如Introduction、Abstract等,单独提取出来保存为txt文件,以防识别错误)
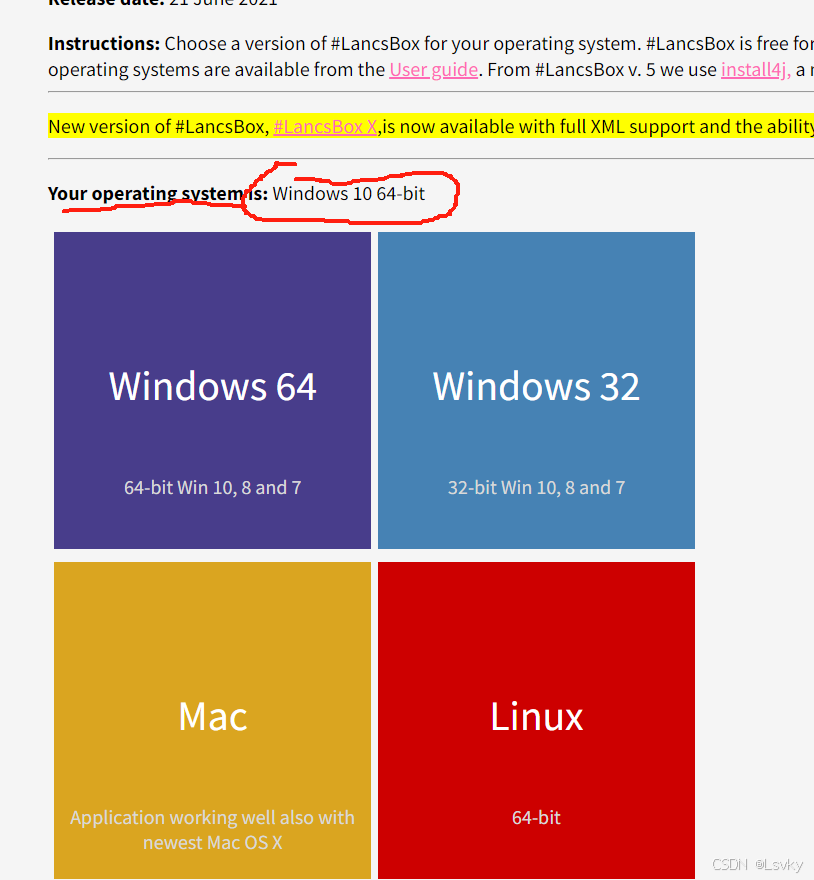
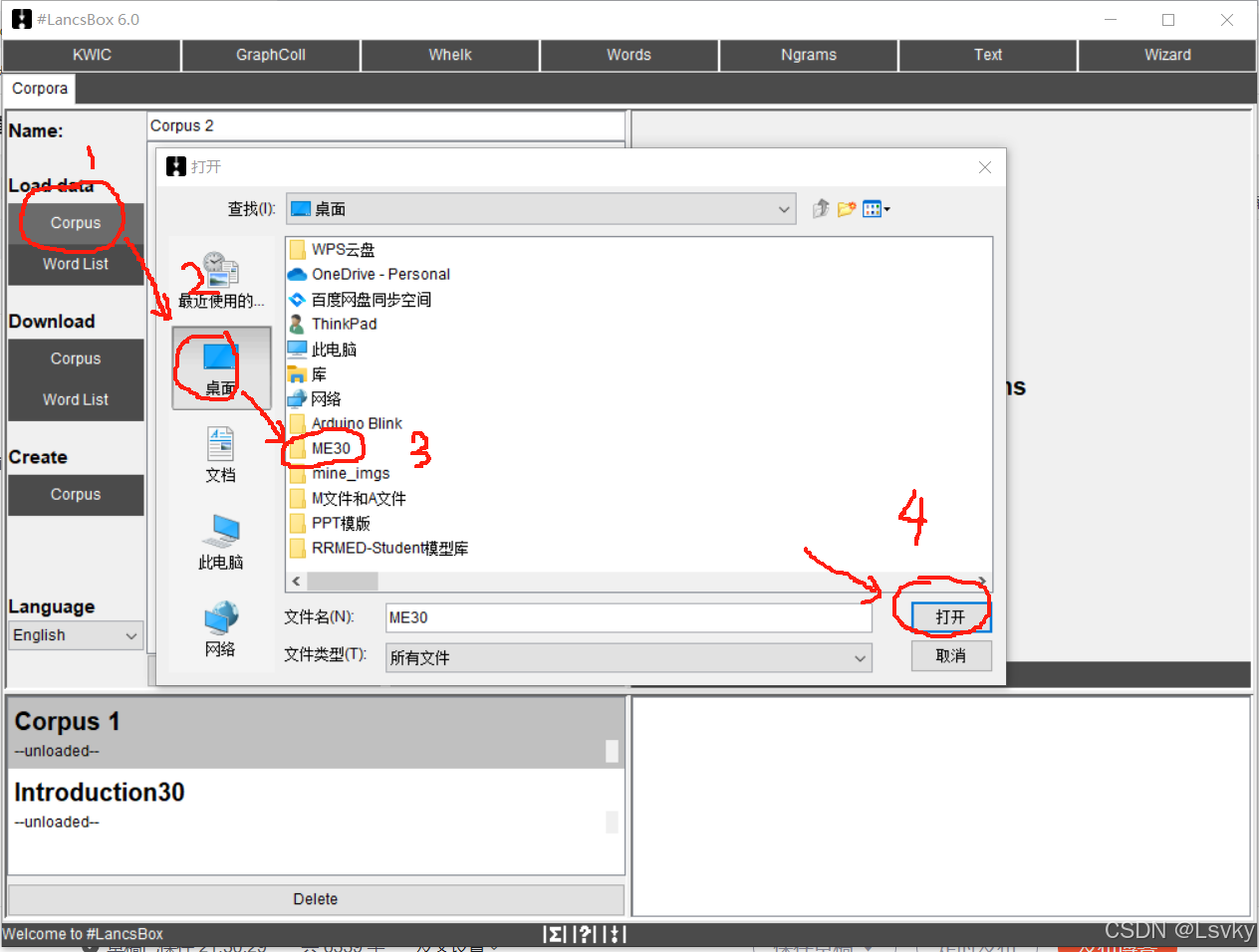
双击图标,打开#LancsBx→Corpus→文件所在位置→打开
 →
→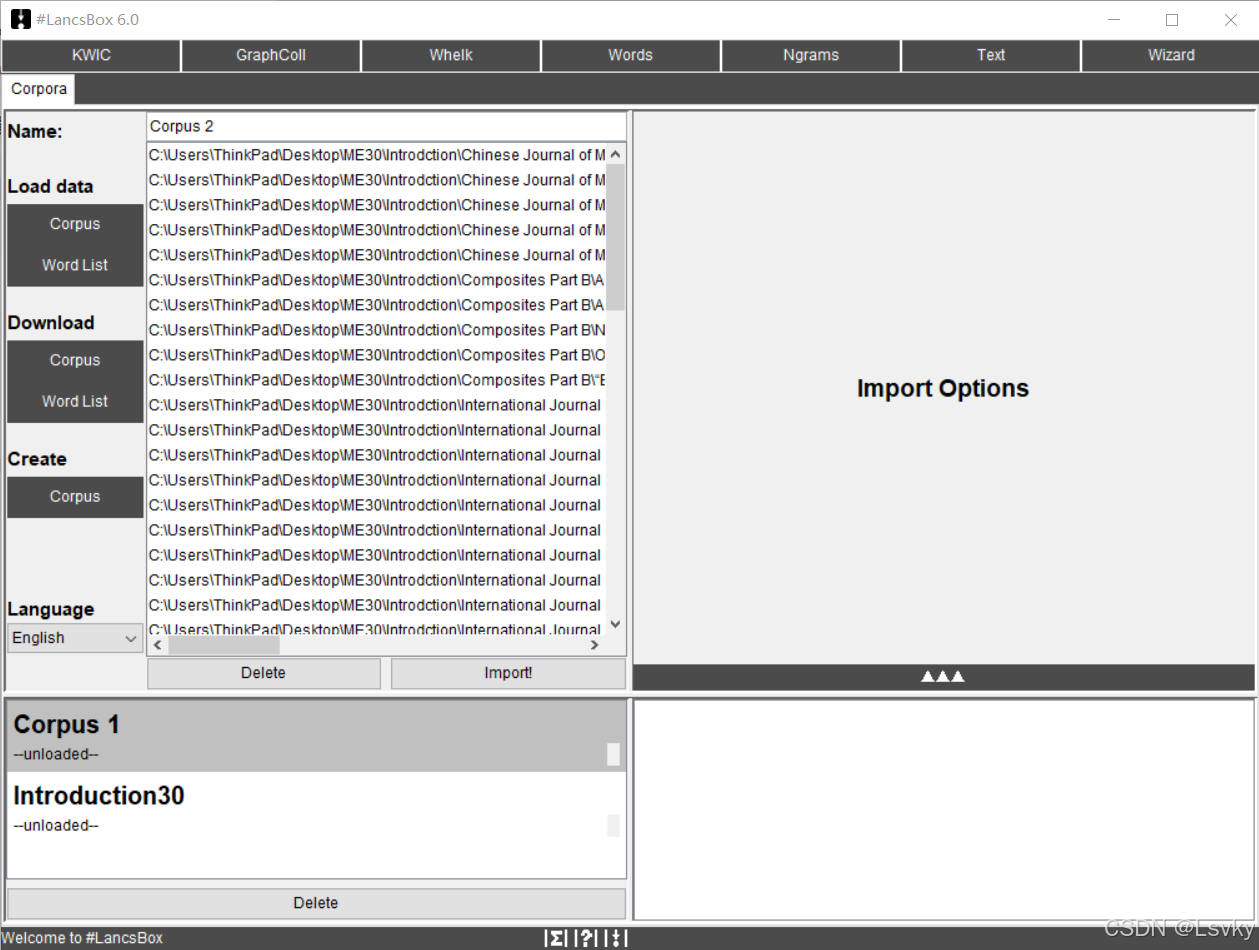
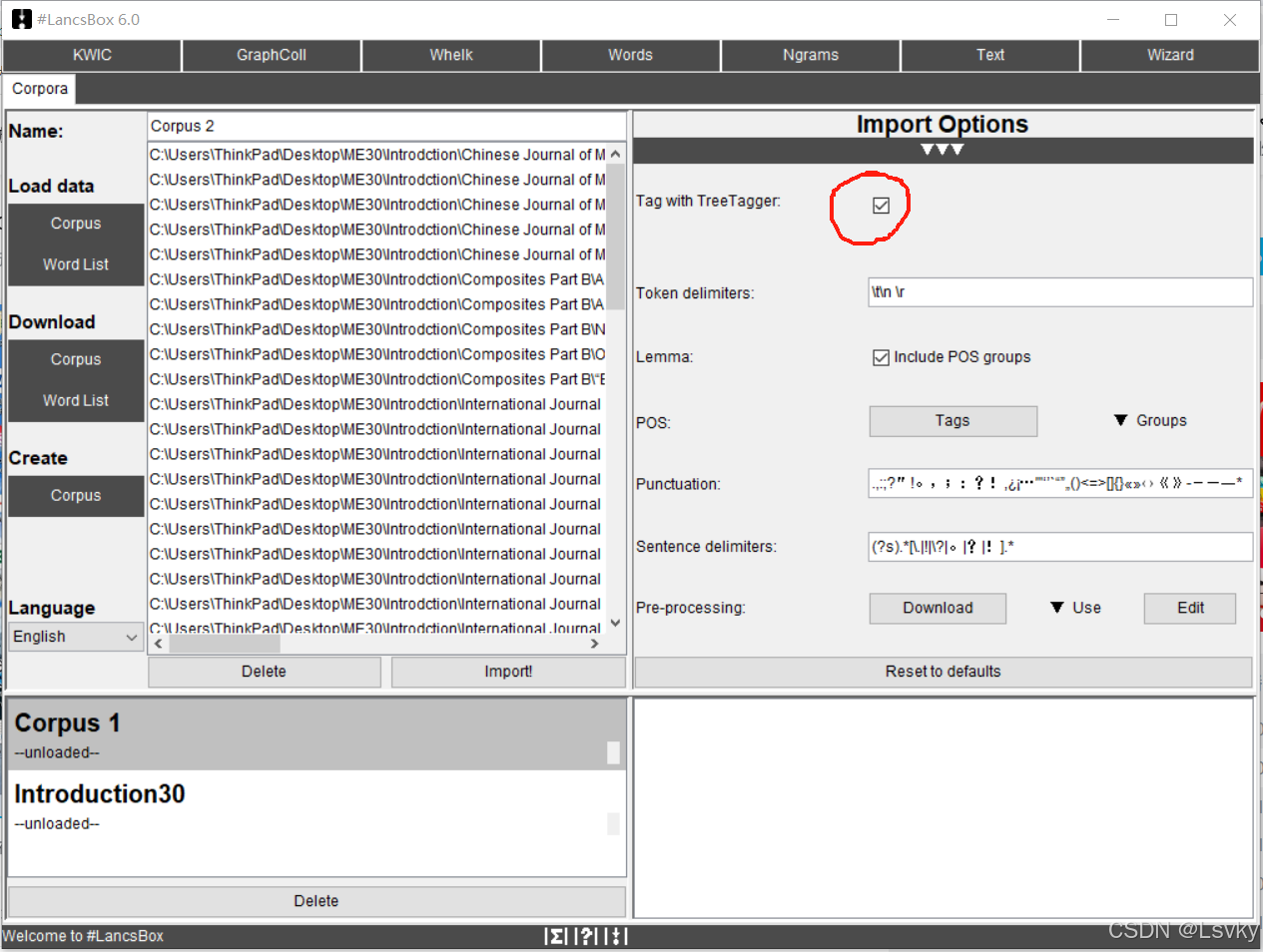
点击“白色正三角x3”符号,进行词性赋码确认→右边第一个选项,默认勾选进行词性赋码(不需要可取消,减少加载时间,但建议选中)
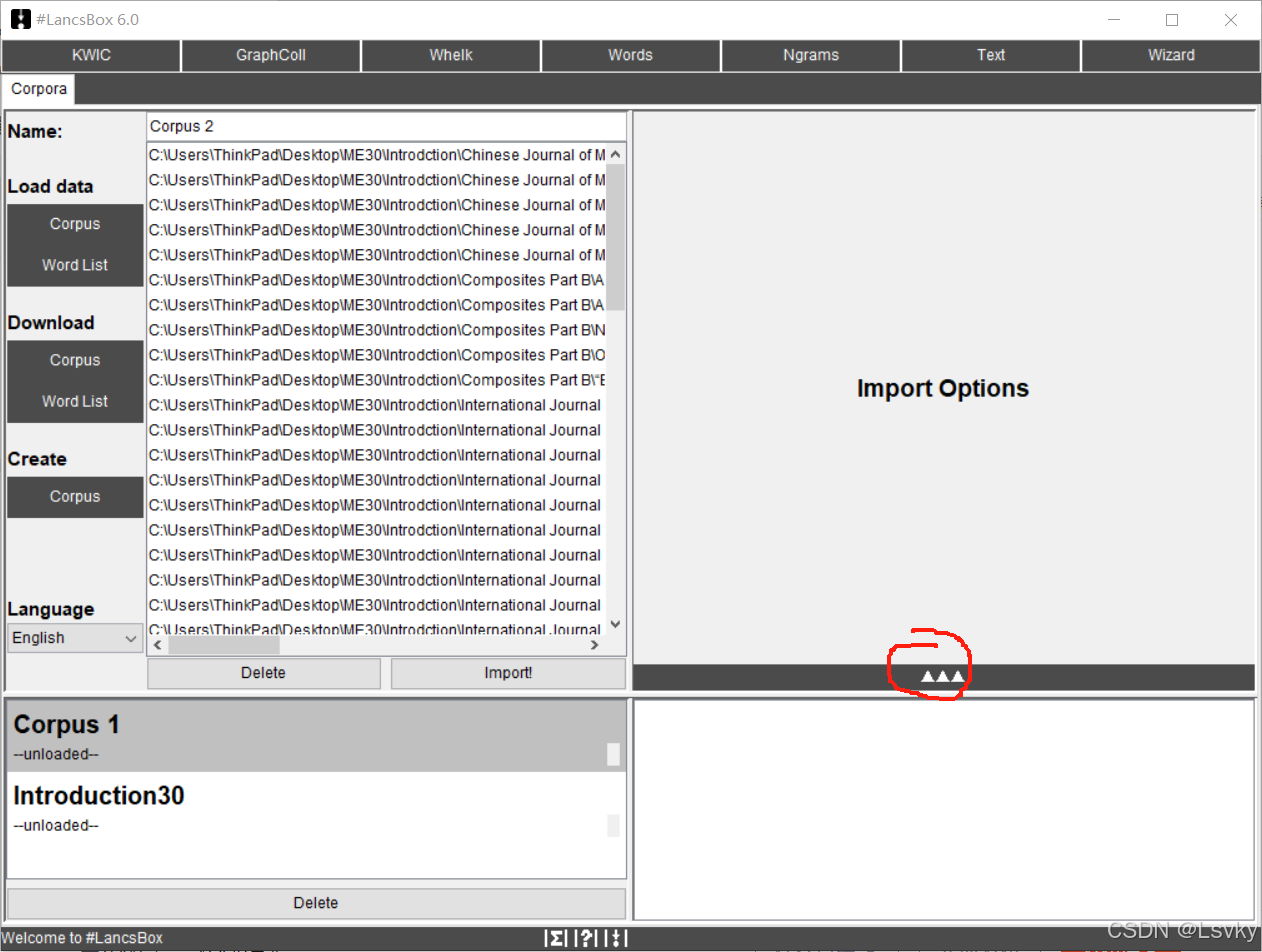 →
→
中间方框进行重命名→左侧“Language”选择目标语言→点击“import”导入
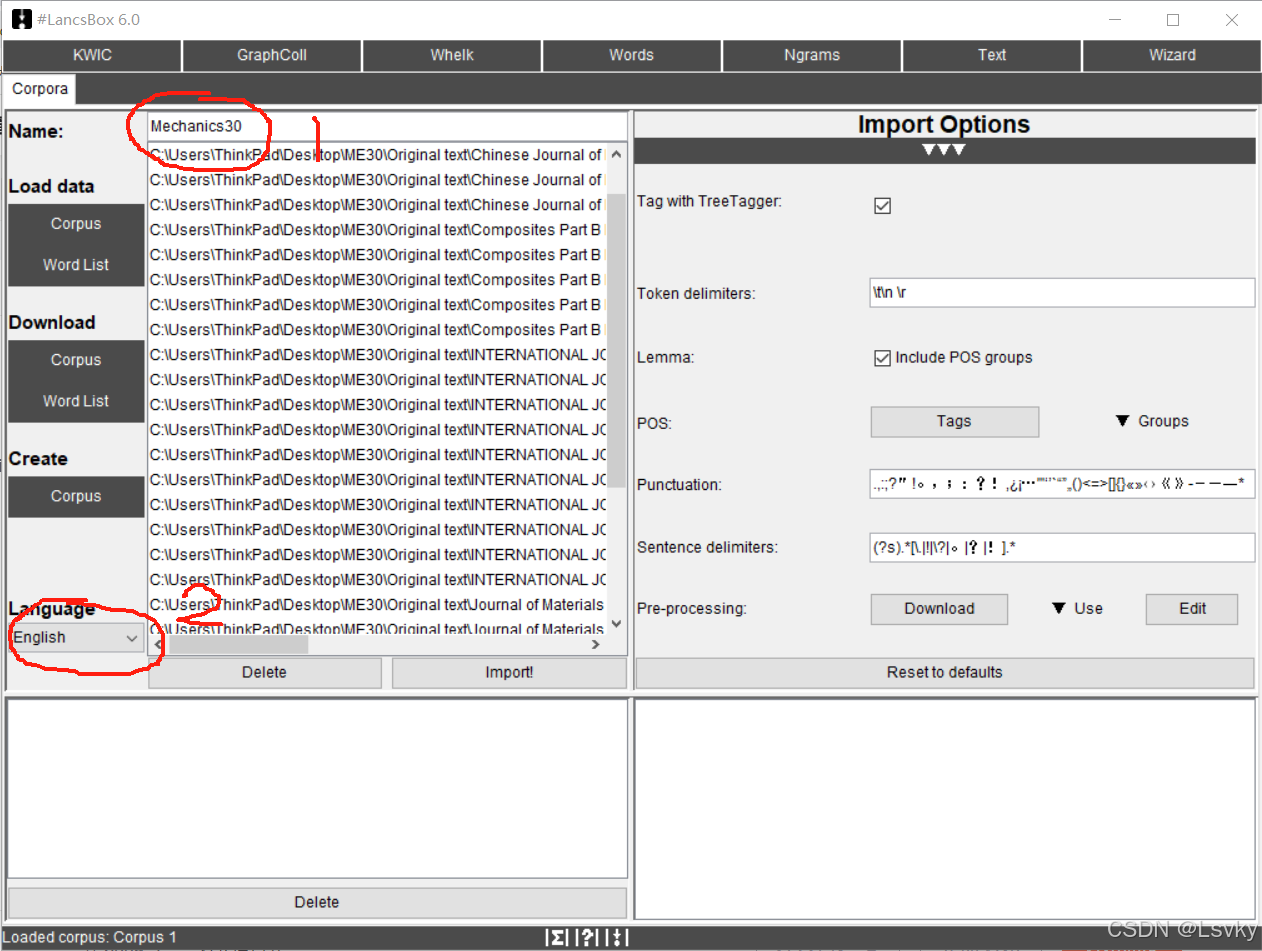 →
→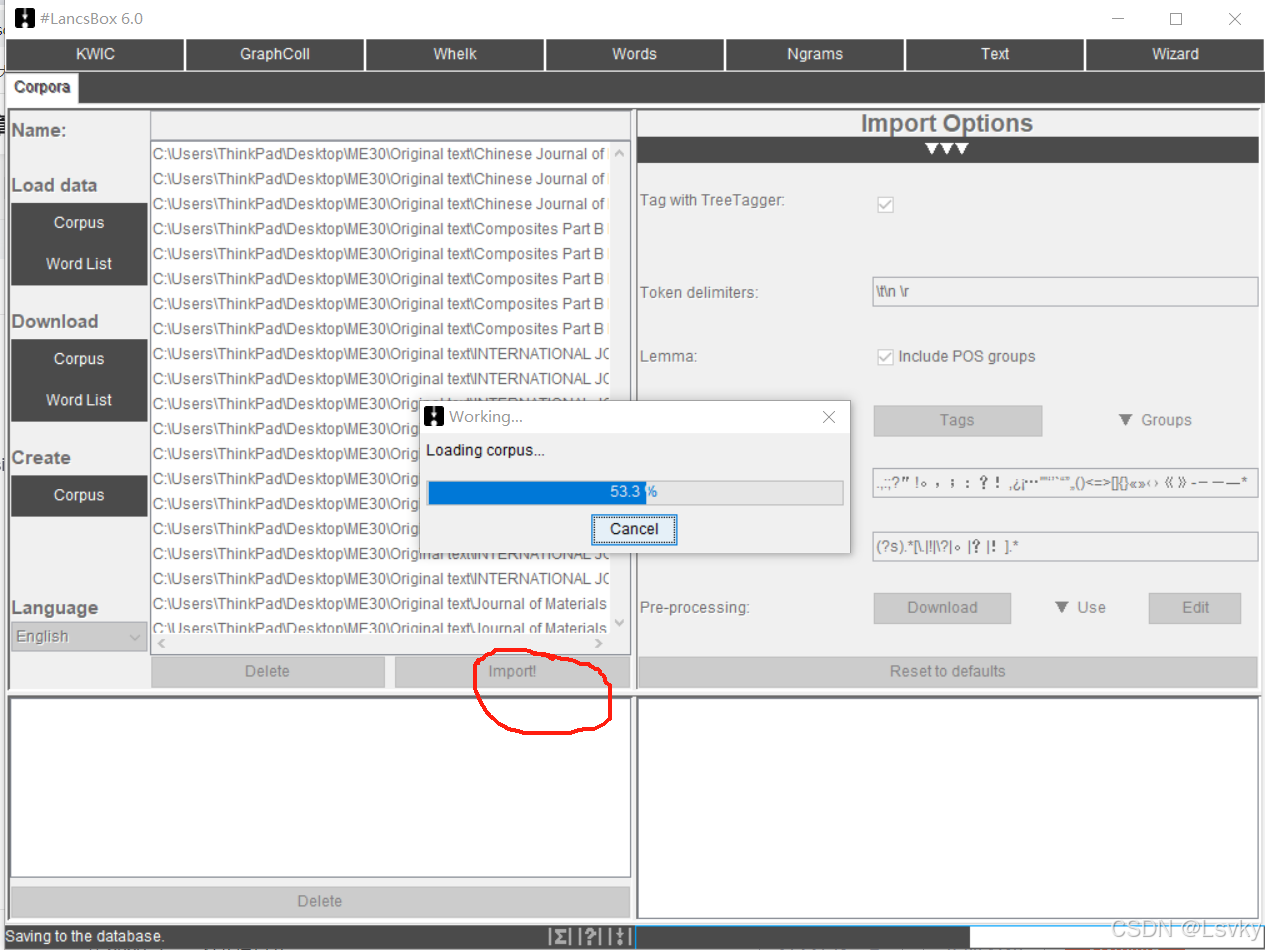
导入成功
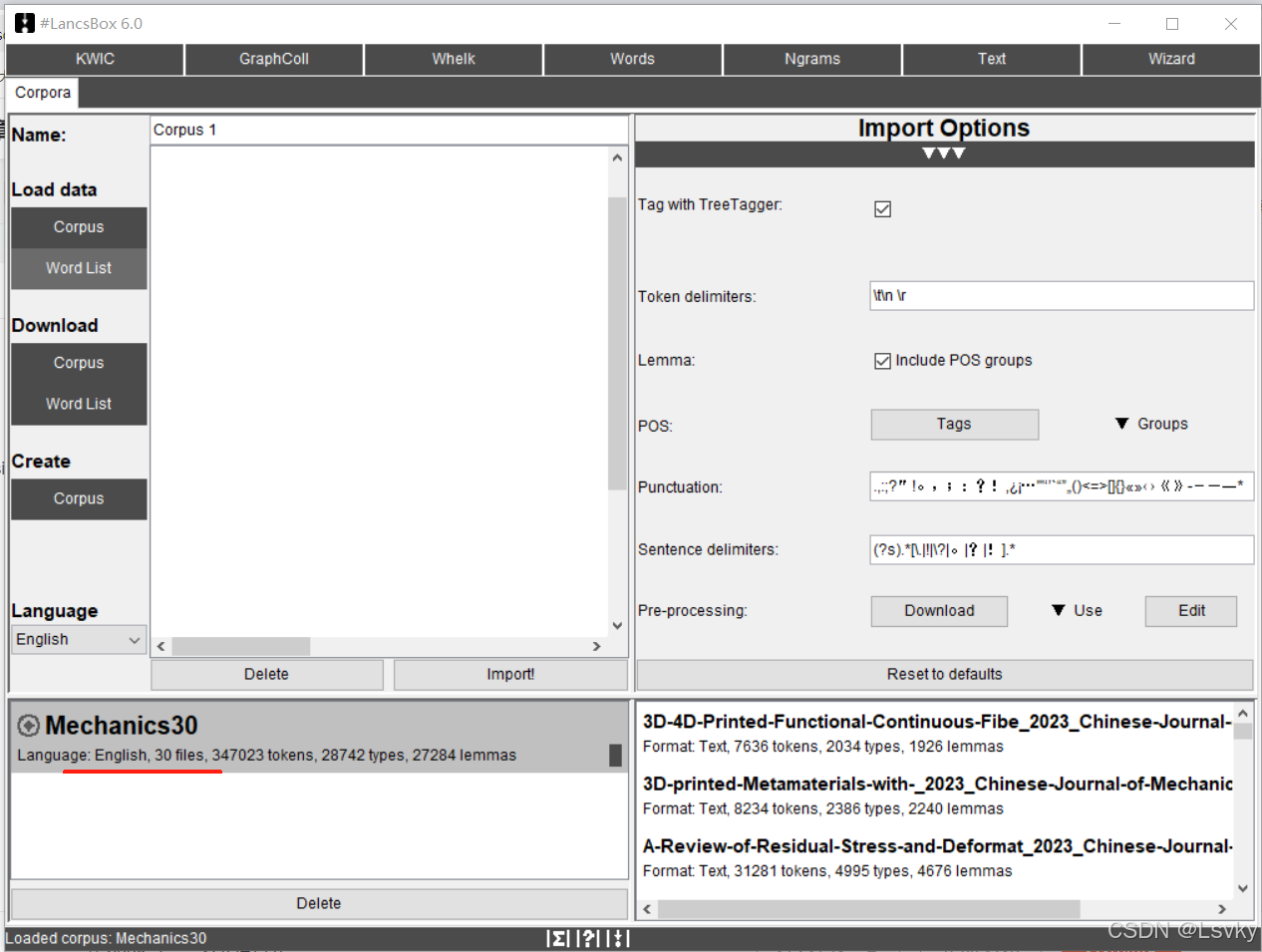
LancsBox还可以下载语料库(有待研究),下载的语料库保存在:
“LancsBox下载位置”>#LancsBox>resources>downloads
4.2 关键词检索
要对文章进行KWIC,首先要确认自己需要检索什么样的关键词,进行词汇使用分析、语言模式识别或者文本比较。本文针对研究论文撰写,故使用的功能是“分析识别关键研究和趋势”和“确保在论文中对关键词的使用一致,提升学术写作质量”。
可以通过以下步骤确认搜索关键词:
- 定义主题:明确研究的主要问题。
“机械/电主轴铣床”,细化为具体方面,如“五轴铣头”。
- 查阅文献:阅读与研究主题相关的文献、论文、书籍,注意其中常出现的术语和关键词,参考相关研究的引用和参考文献列表,找出相关的关键词。
在机械工程领域,排名前六的期刊是:
《Chinese Journal of Mechanical Engineering》、《Composites Part B Engineering》、《INTERNATIONAL JOURNAL OF MACHINE TOOLS & MANUFACTURE》、《INTERNATIONAL JOURNAL OF MECHANICAL SCIENCES》、《Journal of Materials Processing Technology》、《MECHANISM AND MACHINE THEORY》。
常见的关键词有:
主轴系统、高速电主轴、电主轴、重型机床、刀片、轴承腔、高速铣削、油滴、轨迹、有限元法、气相流场、加工精度、ANSYS、动力学分析、仿真、数值模拟、概率密度函数、相似准则、装配工艺、装配精度、精度可靠性、装配工艺设计、动刚度、内冷却、温度场、热-结构耦合、热接触、热分析、热变形
- 列出同义词:考虑与主题相关的同义词或相关术语。在本文案例中:
电主轴铣床:Electric spindle milling machine、milling machines
机械主轴铣床:Mechanical spindle milling machine
五轴铣头/铣刀:Five-axis milling head/milling cutter
- 列出相关术语:在特定领域中,术语的使用可能与普通语言不同,确保了解行业特定的用词。
- 生成关键词:使用在线关键词生成工具(如 Google Trends、AnswerThePublic、Ubersuggest)获取流行搜索词。在学术数据库(如 Google Scholar、IEEE Xplore)中输入主题,查看系统推荐的关键词。
- 识别热点:查看该领域内的最新研究,识别当前的研究热点和趋势,查看相关文献的摘要和关键词部分。
- 再次搜索:在数据库或搜索引擎中使用想到的关键词进行初步搜索,看看返回的结果是否相关。根据搜索结果调整和优化关键词,以获取更相关的文献。
- 此外,还应当注重论文中的元话语应用。如:
元话语是表明作者态度以及构建作者、文本和读者之间关系的手段。在人际互动型元话语中,( 1 )机械工程作者主要通过形容词 “ important ” 和 “necessary ” 来直接阐述研究的重要性和必要性;(2)模糊限制语主要被用来 推测命题的可能性,机械组最常使用情态动词 could ;(3)机械学引言中最常使用的强调语分别为动 词“ demonstrate ” 和 “ show ” 、 “ find ” 。( 4 )自我提及语在语料库中较少使用,因为 作者通常更喜欢用“ the analysis ” , “ the present study ” 来概述研究程序或强调研究目的。( 5 ) 机械工程作者喜欢使用指令性动词(如 see , note )和第一人称复数( inclusive we )来提 高读者的参与度。参与标记语的典型代表第二人称代词(you , your )未出现在数据中。[5]龙琦. 机械工程和应用语言学英语学术期刊论文引言元话语特征对比研究[D]. 华南理工大学, 2017.
5.研究结论
- 在学术论文中,使用以下术语来表示“本研究”或“本设计”是常见的选择,具体取决于上下文:
This study: 通常用于强调研究的具体目标、方法或结果,适合在引入研究结果或讨论部分时使用。
例如:“This study demonstrates that...”
The study: 较为中性,适合在讨论已有的研究或在总结时使用。它可以指代已经提到的研究,避免重复。
例如:“The study found that...”
The design: 更专注于研究的设计或方法,适合在描述实验设计或方法论时使用。
例如:“The design of the sensor allows for...”
This research: 类似于“this study”,但略显正式,适合在强调研究的重要性或贡献时使用。
例如:“This research provides insights into...”
- 选择建议:
如果您强调的是研究的过程或结果,使用 “this study” 或 “this research” 会更合适。
如果您在总结或回顾前文提到的内容,可以使用 “the study”。
如果您专注于研究方法或设计,则使用 “the design” 是最合适的。
6.术语解释
KWIC(Key Word in Context):文本分析方法
GraphColl(Collocation Graph):可视化词汇搭配关系
Whelk(Vocabulary Analysis):词汇分析
Words(Word Statistics):词汇统计
Ngrams(N-grams Analysis):N元组分析
Text(Text Analysis):文本分析
Wizard(Wizard):向导
Corpora:被分析的文本集合。用户可导入和管理多个语料库,以便进行对比和分析。
Load data:加载数据的过程,用户可以将文本文件或数据集导入 LancsBox 进行分析。
Word List:显示特定文本中所有单词的列表,通常包括词频统计和其他相关信息。
Delete:删除功能,允许用户从语料库或分析结果中移除不必要的数据或项。
Import:导入功能,用户可以将外部文本或数据文件导入到 LancsBox 中进行分析。
tokens:文本中分割后的单词或符号。在文本分析中,tokens 是基本的分析单位。
types:文本中不同的词汇类型,通常用于计算词汇多样性(如类型-令牌比 TTR)。
lemmas:词汇的基本形式或词根。在分析中,lemmas 用于统一不同形式的词汇,以便进行更准确的统计。
Tag with Tree Tagger:用于对文本进行词性标注(POS tagging),将每个单词标记为其语法类别
Token delimiters:用于分隔文本中 tokens 的字符或符号,例如空格、标点符号等。
Lemma:单词的基本形式,用于统一分析不同形式的单词,如“running”和“ran”都可以标记为“run”。
POS(Part of Speech):词性,表示单词在句子中的语法角色,如名词、动词、形容词等。
Include POS groups:允许用户在分析中包含特定的词性组,以便进行更细致的分析。
Punctuation:文本中的标点符号,在文本分析中,标点符号的处理会影响 token 的划分和统计。
Sentence delimiters:用于划分句子的字符,如句号、问号和感叹号等,用于文本分割。
Pre-processing:在分析前对文本进行的清理和准备工作,例如去除停用词、标点符号和其他不必要的元素。
Reset to defaults:允许用户将设置恢复到默认状态,方便用户重新开始分析。
Loaded corpus:当前已加载到 LancsBox 中的语料库,用户可以对其进行分析和处理。

















 9194
9194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









