






目的:找出最优解 方法:梯度下降法
图中的max应该为min

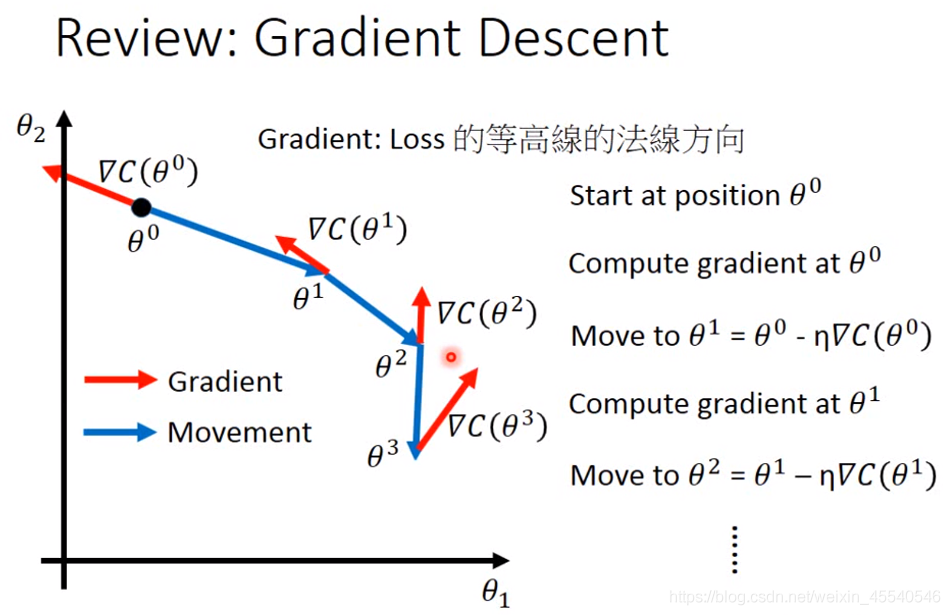
需要注意的内容:
1、学习率的选择
学习率对损失的影响
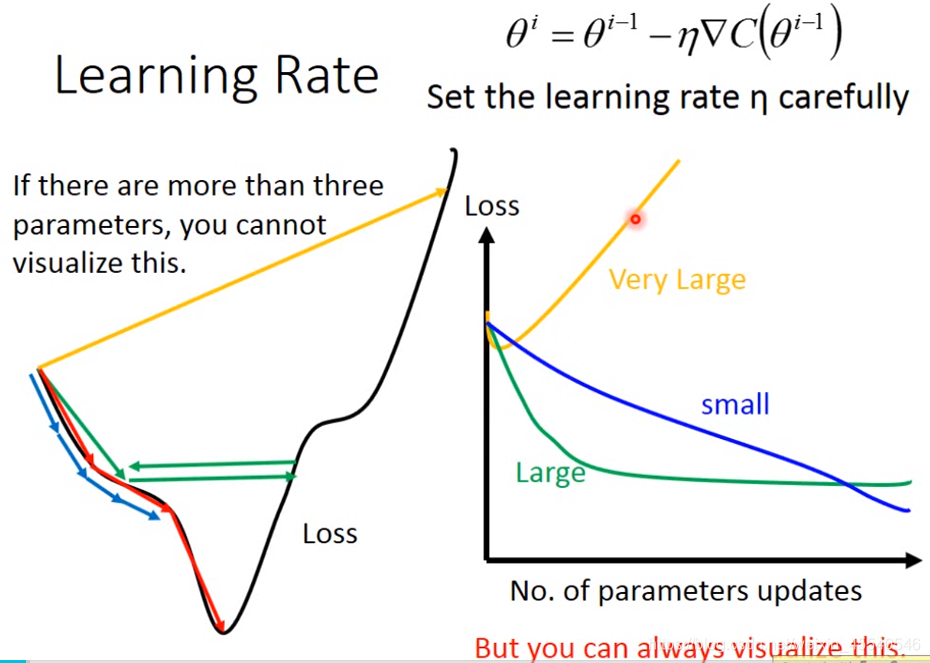
学习率过小会使得在迭代更新权值的过程中,梯度下降过程缓慢。设置过大容易使得训练模型跨过最优值,从而导致过拟合。
2、自适应学习率的调节
自动调节学习率
最基本、最简单的大原则是:学习率通常是随着参数的更新越来越小。
在起始点的时候,通常是离最低点比较远的,这时候步伐就要跨大一点;经过几次更新之后,会比较靠近目标,这时候就应该减小学习率,让他能够收敛在最低点的地方

开始时,离目标值很大可以设置较大的学习率,然后逐渐的减少学习率。
不同的参数应该设置不同的学习率,以达到最好的效果。(因材施教)
自适应梯度调节(Adagrad)
Adagrad就是将不同参数的learning rate分开考虑的一种算法(adagrad算法update到后面速度会越来越慢,当然这只是adaptive算法中最简单的一种)

这里的w是function中的某个参数,t表示第t次update,
g
t
g^{t}
gt表示Loss对w的偏微分,而
σ
t
\sigma ^{t}
σt是之前所有Loss对w偏微分的方均根(根号下的平方均值),这个值对每一个参数来说都是不一样的
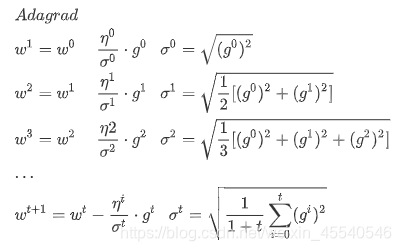
最好状态:每个不同参数,给其不同的学习率
可以采用:Adagrad

总结
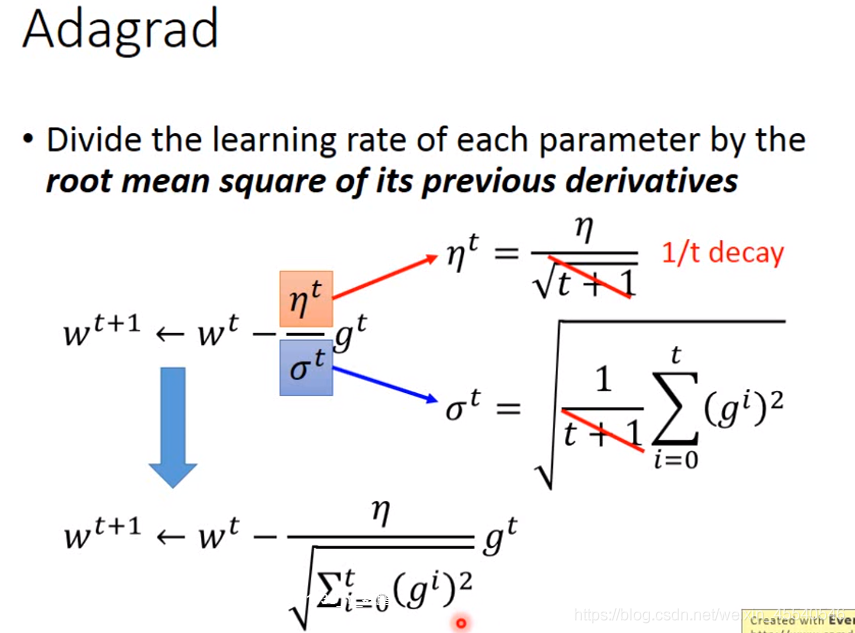
Adagrad的contradiction解释
在做gradient descent的时候,希望的是当梯度值即微分值
g
t
g^{t}
gt越大的时候(此时斜率越大,还没有接近最低点)更新的步伐要更大一些,但是Adagrad的表达式中,分母表示梯度越大步伐越小,分子却表示梯度越大步伐越大,两者似乎相互矛盾
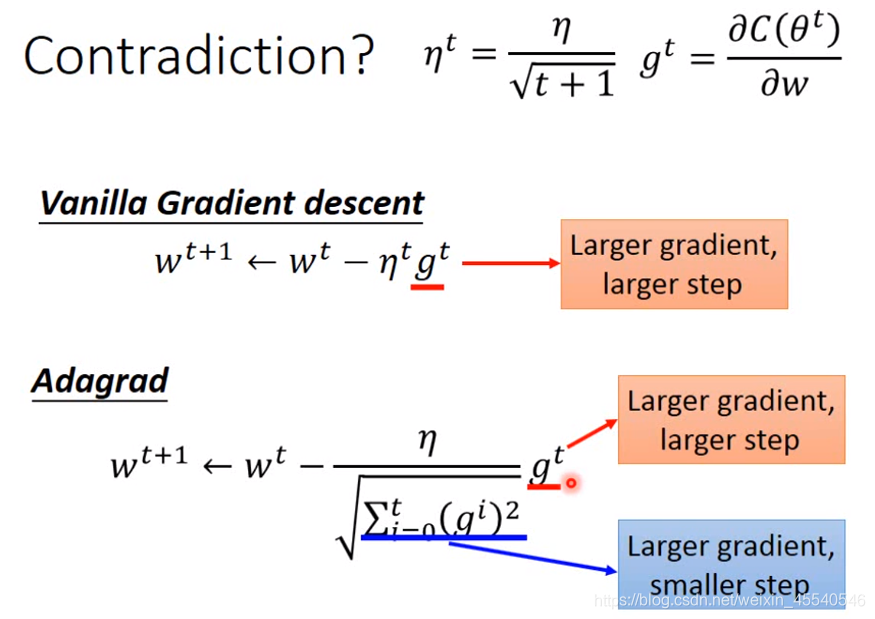


g:梯度;η:学习率
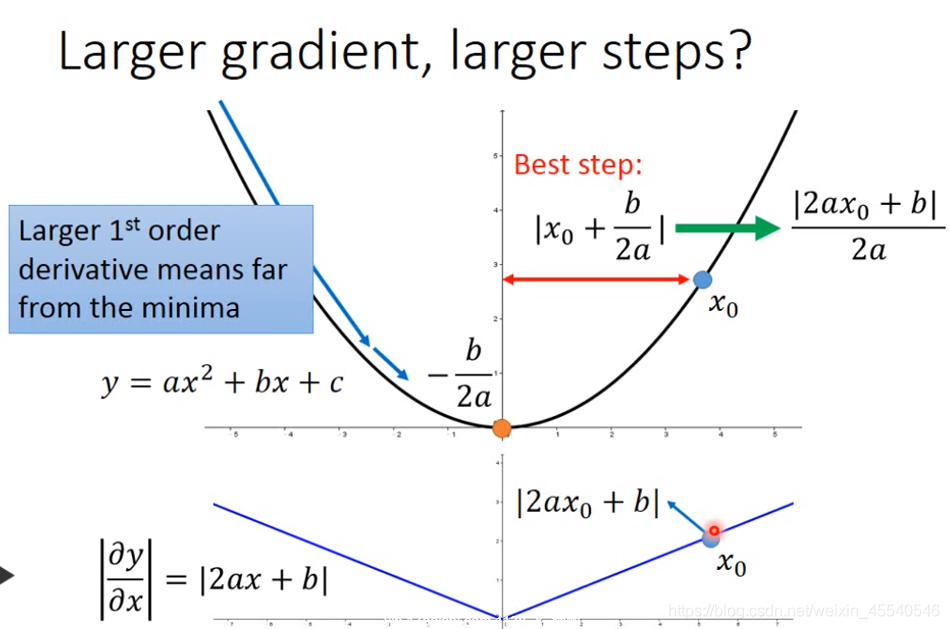
梯度越大,离远点越远,跨出去的步伐越大。
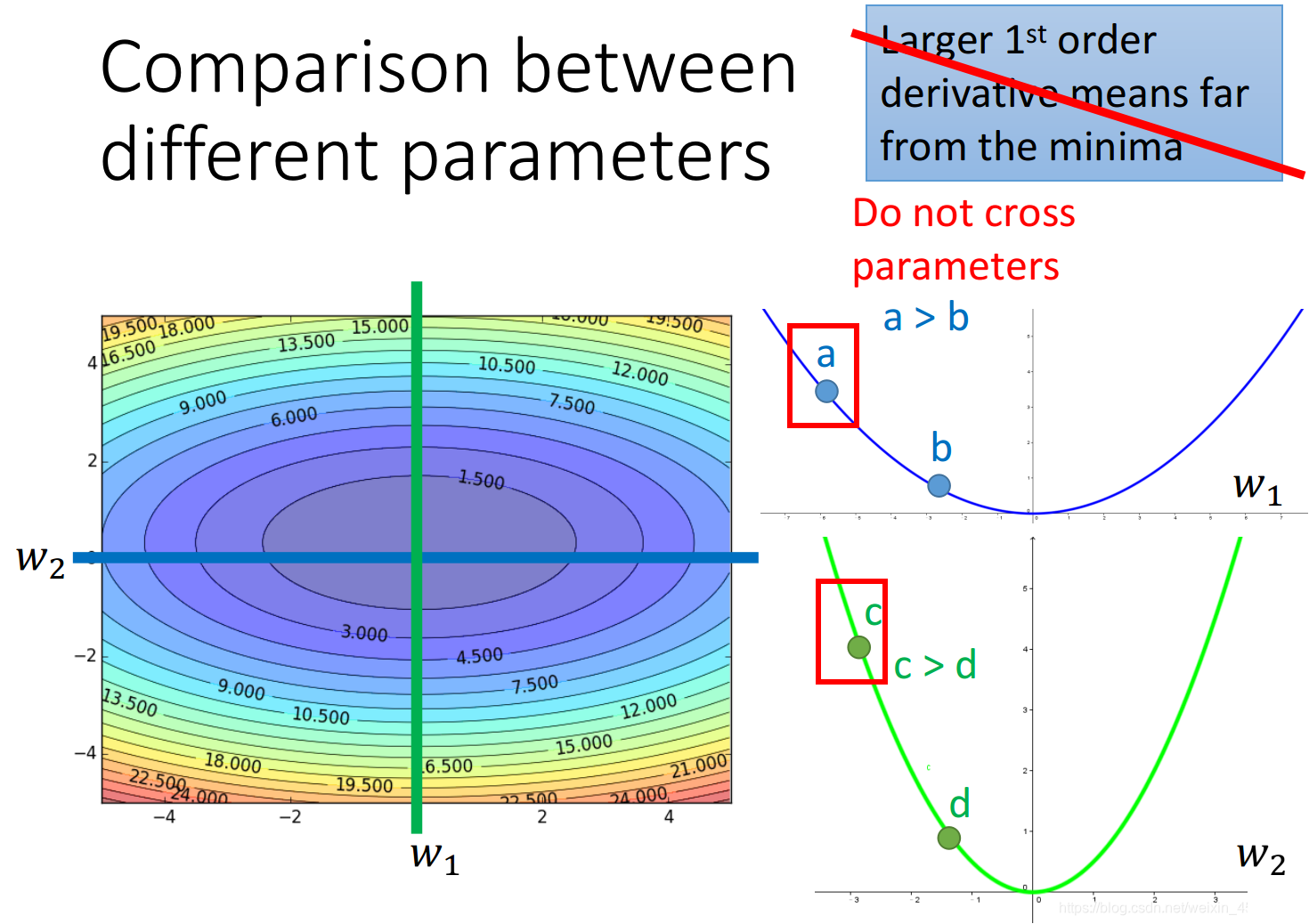
在有多个参数的时候,上述的结论有可能是不成立的。
gradient越大,离最低点越远这件事情在有多个参数的情况下是不一定成立的
如下图所示,w1和w2分别是loss function的两个参数,loss的值投影到该平面中以颜色深度表示大小,分别在w2和w1处垂直切一刀(这样就只有另一个参数的gradient会变化),对应的情况为右边的两条曲线,可以看出,比起a点,c点距离最低点更近,但是它的gradient却越大

随机梯度下降
随机梯度下降的方法可以让训练更快速,传统的gradient descent的思路是看完所有的样本点之后再构建loss function,然后去update参数;而stochastic gradient descent的做法是,看到一个样本点就update一次,因此它的loss function不是所有样本点的error平方和,而是这个随机样本点的error平方

随机梯度下降法(Stochastic Gradient Descent, SGD)采用单个训练样本的损失来近似平均损失。随机梯度下降法采用单个训练数据即可对模型参数进行一次更新,大大加快了训练速度。
stochastic gradient descent与传统gradient descent的效果对比如下:
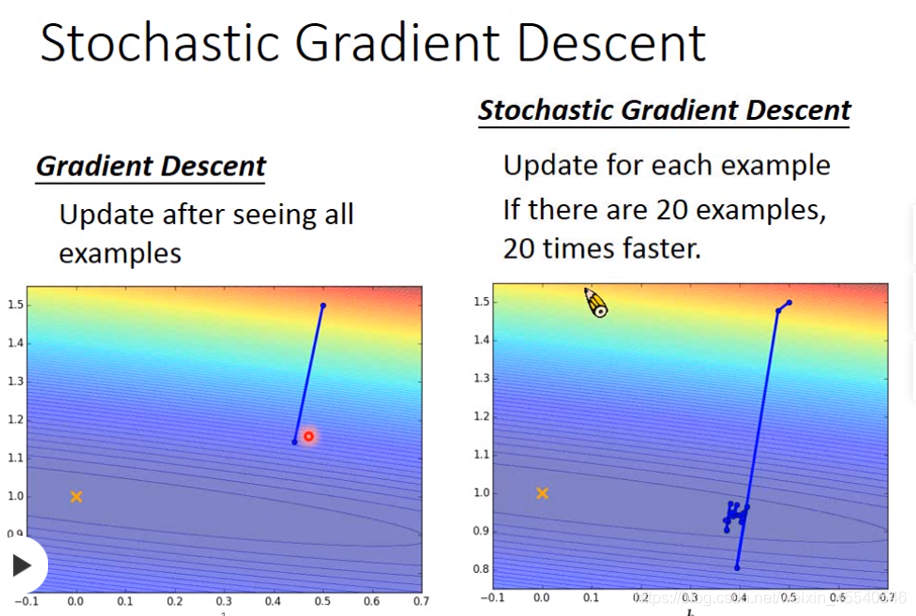
随机梯度下降利用单个样本的损失就可以进行一次迭代,所以加快了训练速度。
Feature Scaling(特征归一化)
特征缩放,当多个特征的分布范围很不一样时,最好将这些不同feature的范围缩放成一样
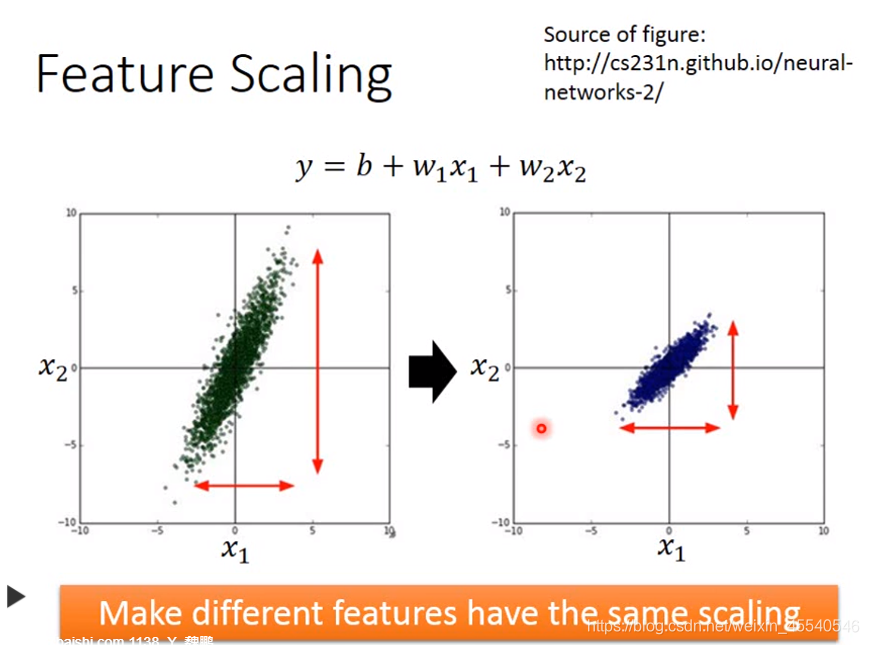
使得不同的特征有着相同的标度率(使得更新参数时比较方便)
原理解释:
y
=
b
+
w
1
x
1
+
w
2
x
2
y = b + w_{1}x_{1} + w_{2}x_{2}
y=b+w1x1+w2x2,假设x1的值都是很小的,比如1,2…;x2的值都是很大的,比如100,200…
此时去画出loss的error surface,如果对w1和w2都做一个同样的变动
△
w
\bigtriangleup w
△w,那么w1的变化对y的影响是比较小的,而w2的变化对y的影响是比较大的
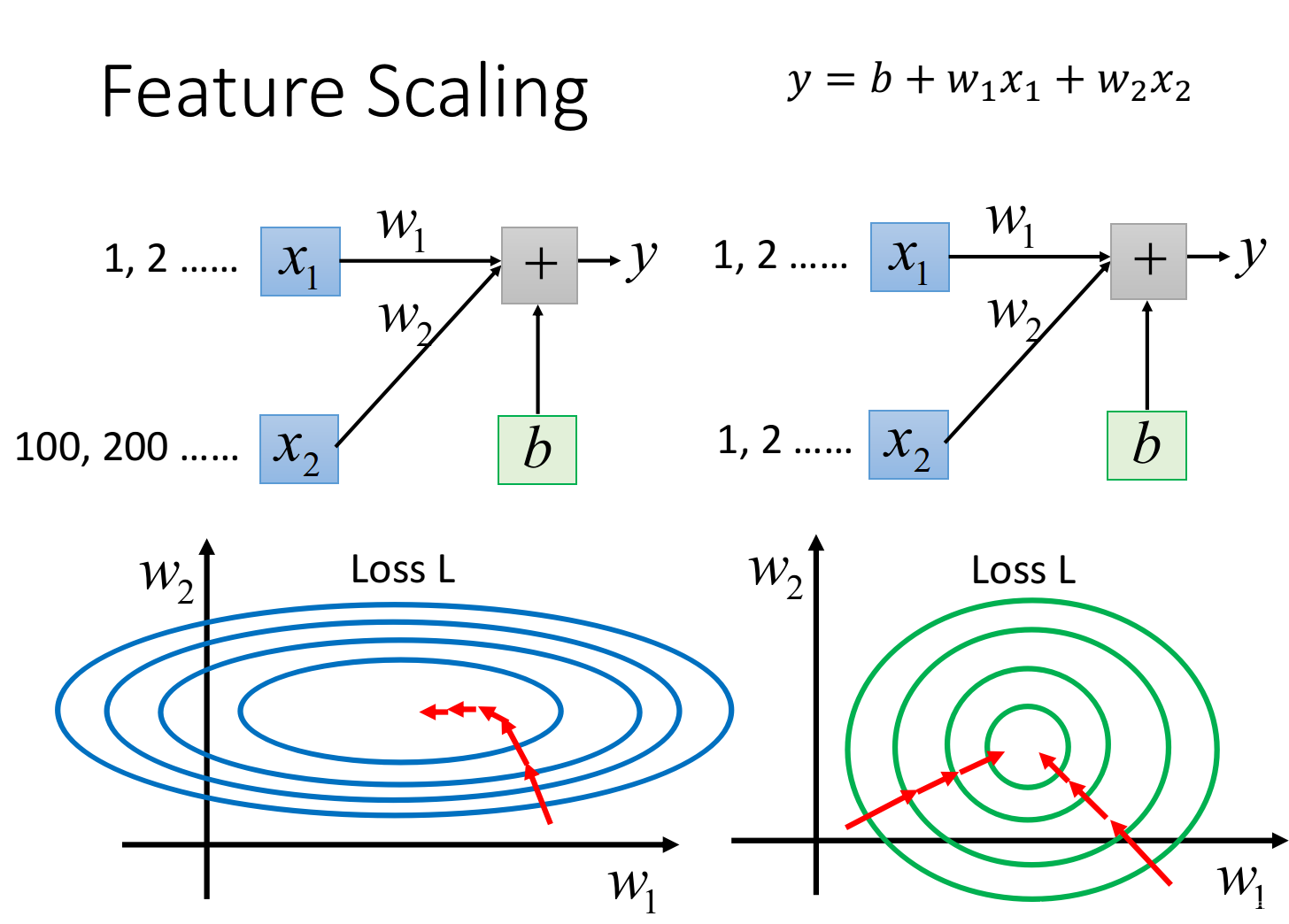
左边的error surface表示,w1对y的影响比较小,所以w1对loss是有比较小的偏微分的,因此在w1的方向上图像是比较平滑的;w2对y的影响比较大,所以w2对loss的影响比较大,因此在w2的方向上图像是比较sharp的
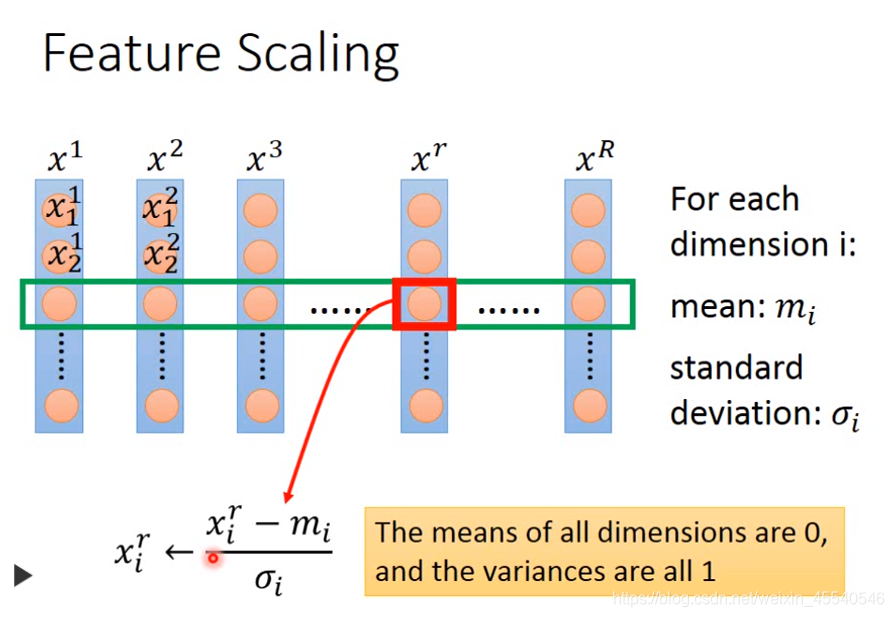
1、特征归一化的方法
将每个参数都归一化成标准正态分布。
假设有R个example(上标i表示第i个样本点),
x
1
,
x
2
,
.
.
.
,
x
R
x^{1},x^{2},...,x^{R}
x1,x2,...,xR,每一笔example,它里面都有一组feature(下标j表示该样本点的第j个特征)
对每一个demension i,都去算出它的平均值mean=
m
i
m_{i}
mi,以及标准差standard deviation=
x
i
r
=
x
i
r
−
m
i
σ
i
x_{i}^{r} = \frac{x_{i}^{r}-m_{i}}{\sigma _{i}}
xir=σixir−mi
对第r个example的第i个component,减掉均值,除以标准差,即














 2483
2483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









