







可持续旅游业发展数学模型

解题思路
本题目标是构建一个可持续旅游业发展的数学模型,综合考虑经济、环境和社会三大要素,为朱诺市的旅游管理提供科学的决策支持。研究结果将帮助朱诺市在保证经济收益的同时,实现旅游业的可持续发展,减少生态退化的风险,并提升居民的生活质量。在解答美赛B题的过程中,首先我们需要对每个问题进行分析和建模。
对于问题一,我们的目标是建立一个可持续的旅游业发展模型,以优化朱诺市的旅游活动。我们从明确优化目标开始,考虑经济、环境和社会的多重目标。具体而言,经济目标是最大化旅游收入,环境目标是减少游客活动对环境的碳排放,社会目标则是提高居民满意度并减少基础设施压力。我们提出了一些决策变量,如每日邮轮到港数量、每日接待游客人数和游客税等,并结合相关的约束条件,如基础设施的承载能力和最大游客流量,建立了多目标优化模型。在求解方法上,我们采用了加权法和多目标优化算法(如NSGA-II和MOPSO),并进行了灵敏度分析,以评估关键参数变化对模型结果的影响。
对于问题二,我们需要考虑如何将这一模型推广到其他受过度旅游影响的地区。不同地区的特性各不相同,因此我们在调整模型时要结合各个目的地的地理环境、文化背景以及基础设施状况。具体来说,针对不同区域的环境承载力、文化遗产保护需求以及社会矛盾,调整模型中的碳排放目标、游客流量限制和居民满意度等因素。例如,在森林保护区域,我们可能需要增强环境保护目标的权重,在文化遗址保护区域,我们会加强游客数量控制等措施。通过对不同地区的适应性分析,我们确保模型能在不同环境下提供有效的优化方案。
最后,在问题三中,我们需要为朱诺旅游理事会编写一份建议备忘录,提供具体的政策建议。基于模型求解的结果,我们预测了当前游客流量超出基础设施承载力的程度,并提出了游客数量限制和税收政策以平衡游客流量和收入。在建议中,我们还提到将收入的部分用于环保项目、基础设施建设和社区发展,并提出开发次要景点来分流游客。通过这些措施,我们预期能显著减少游客的碳排放,降低基础设施压力,并提升居民的生活质量,为朱诺市的可持续旅游提供长期解决方案。
整体而言,我们通过建立多目标优化模型,结合实际情况的灵活调整,为朱诺市及其他旅游地区的可持续发展提供了理论依据和实用的决策工具。
一、模型假设与符号说明
1.1 模型基本假设
1)假设游客税对游客数量的影响呈线性变化
根据经济学原理,价格弹性在一定范围内是线性近似的,适用于游客税在合理范围内的变化情况。
2)假设城市基础设施的承载能力是固定值
虽然基础设施可以通过投资扩建提升,但短期内其最大承载能力是有限的,因此可以视为固定值。
3)假设每日邮轮到港数量有限且可控
港口的基础设施和调度能力决定了每日能够接纳的邮轮数量。在实际操作中,港口可以通过预约系统限制到港邮轮的数量。
4)假设每艘邮轮和每位游客的碳排放量是已知的常量
基于历史数据和文献研究,可以合理估计邮轮航行及游客活动的平均碳排放量,并视为稳定值。
5)假设模型中涉及的成本和收入与市场平均水平一致
为减少模型复杂度,我们使用市场平均数据作为收入和成本估算的基础。
1.2 符号说明


二、数据预处理
2.1 数据采集
在本问题中,我们对朱诺市2023年邮轮产业的相关数据进行了详细分析,数据主要来源于《CBJ Cruise Impacts 2023 Report》。报告详细描述了邮轮产业的经济、社会和环境影响,为模型的构建和验证提供了关键数据支持。以下是数据搜集的主要内容:
-
邮轮与游客数量
朱诺市是阿拉斯加州的重要邮轮停靠点,2023年接待了超过700次邮轮停靠,吸引了167万名邮轮游客和36,000名船员。邮轮类型以大型邮轮为主,占游客总量的98%,中型和小型邮轮各占1%。这一数据有助于我们构建邮轮停靠与游客数量之间的关系。 -
经济影响
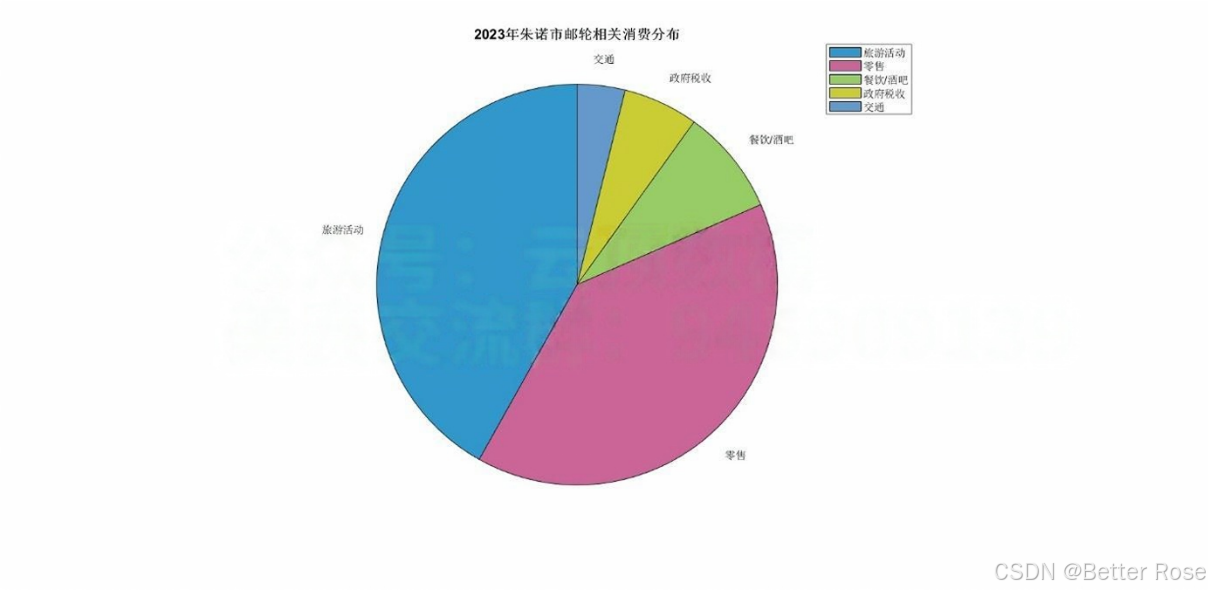
朱诺市的邮轮产业在2023年直接产生了3.75亿美元的消费,其中游客消费占3.2亿美元,邮轮公司消费为3,900万美元,船员消费为1,600万美元。游客在旅游活动和零售上的支出占总消费的79%,具体分布为:
旅游活动:1.52亿美元。
零售:1.44亿美元。
餐饮/酒吧:3,100万美元。
政府税收:2,200万美元。
交通:1,400万美元。
3. 市政收入
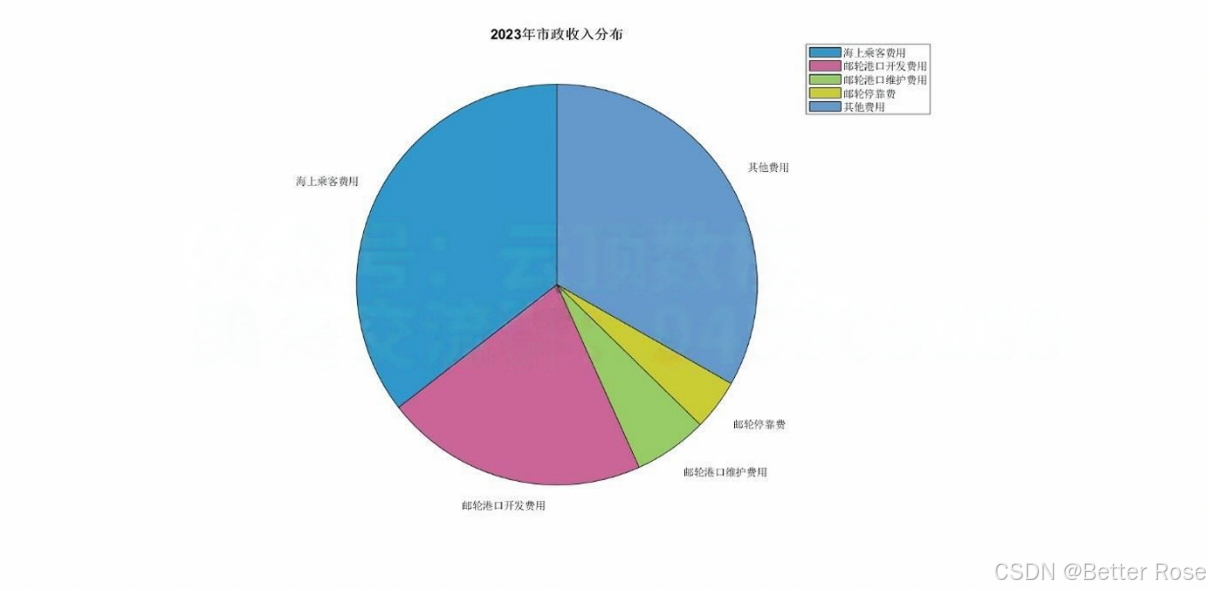
邮轮相关支付和税收收入为朱诺市政府提供了稳定的资金支持。2023年,邮轮相关支付总计2,228万美元,其中包括:
海上乘客费用:823万美元。
邮轮港口开发费用:492万美元。
邮轮港口维护费用:138万美元。
邮轮停靠费:95万美元。
其他费用:约770万美元。
此外,税收收入主要来源于销售税(1,770万美元)、酒店税(60万美元)和财产税(220万美元)。
4. 游客与船员消费行为
游客和船员的消费行为是模型中重要的输入变量:
游客消费:游客的主要支出集中在零售、旅游活动、餐饮和交通,平均消费为192美元/人。
船员消费:船员的消费主要集中在餐饮和零售,平均消费为44美元/人。
除此之外,通过根据最新的搜索结果,朱诺市在2023年和2024年接待邮轮游客的详细信息进一步明确了邮轮停靠和游客数量的限制。
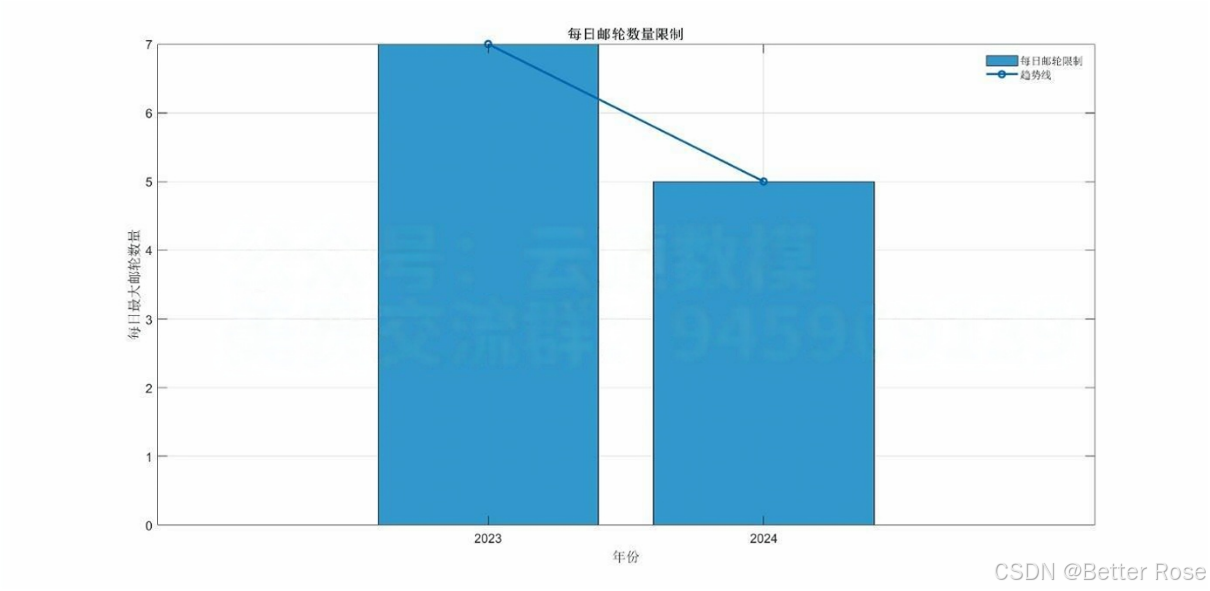
1.邮轮数量限制
2023年与2024年最大邮轮停靠量
2023年:每天最多接待7艘邮轮。
2024年起:通过协议限制每天停靠的大型邮轮数量不超过5艘。
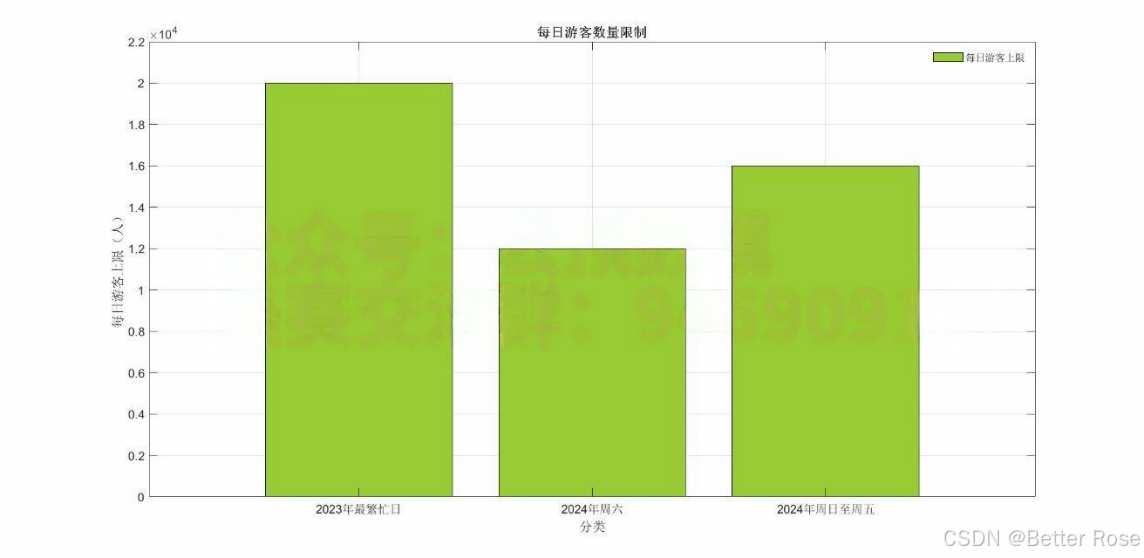
2.游客数量限制
每日最大游客数量
2023年:最繁忙的日子,游客数量可达 20,000 人。
2024年起:新的游客上限政策:
周日至周五:每日游客上限为16,000人。
周六:每日游客上限为12,000人。
三、问题一的模型建立与求解
3.1 阿拉斯加州朱诺市的可持续旅游业优化模型的建立
3.1.1模型目标与意义
3.1.2决策变量
3.1.3目标函数
3.2 阿拉斯加州朱诺市的可持续旅游业优化模型的求解
3.3 阿拉斯加州朱诺市的可持续旅游业优化模型的结果分析
四、问题二的模型建立与求解
4.1 其他受过度旅游影响目的地的特性
4.2 推广案例选择与分析:威尼斯
4.3 适配威尼斯的可持续旅游业优化模型调整
4.4 适配威尼斯的可持续旅游业优化模型结果分析
Memo
代码
数据分析
问题一
问题二

完整论文12540字论文以及代码,请看文章下方~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









