







目录
引言
最近在学习Pytorch和GAN网络代码,故从GitHub上下载了MNIST的源码进行了学习,并进行了解析和批注,如有不足之处,还请大神批评指正。
正文
言归正传,开始理解源码:
# 导入各种包,主要有argparse、os、numpy、torch,其中torch需要安装pytorch框架
import argparse # argparse模块的作用是用于解析命令行参数
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch这一部分是导入各种模块。
os.makedirs('images', exist_ok=True) 在当前目录创建"image"文件夹,名称就是images,exist_ok取值为Ture时,已存在该文件夹,也不会报错。
# 初始化参数,如rpoch次数,batch_size的大小等,sample_interval表示后续间隔保存CGAN图片的保存间隔。
parser = argparse.ArgumentParser() # 声明一个parser
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training") # 添加如下参数,并设定默认值
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches") # 后面的help是添加的描述
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args() # 读取命令行参数
print(opt) # 调用这些参数这部分代码是进行参数的设定,可以通过一条命令直接在cmd中设置参数并运行此代码。
比如往下读程序读到了'--n_epochs',就来前面找,找到第一个参数,'--n_epochs',这个参数的默认值200和类型int都在后面,意思就是将'--n_epochs'的值赋值为200,最后help中还有关于'--n_epochs'的解释。
img_shape = (opt.channels, opt.img_size, opt.img_size) 这些参数opt.channels, opt.img_size, opt.img_size便是需要去上一部分设定的参数的位置去找的,都是带有opt. 意思为图像的通道数为1,尺寸大小为28*28,通道数为1表示是灰度图。
cuda = True if torch.cuda.is_available() else False判断是否具备cuda进行GPU加速计算条件。
class Generator(nn.Module): #生成网络
def __init__(self):
super(Generator, self).__init__() #超类继承
def block(in_feat, out_feat, normalize=True): #定义一个静态方法,方便搭建网络
layers = [nn.Linear(in_feat, out_feat)] #对传入数据应用线性转换(输入节点数,输出节点数)
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) #批规范化,为了输入在激活函数的敏感区。所以BatchNorm层要加在激活函数前面
layers.append(nn.LeakyReLU(0.2, inplace=True)) #激活函数
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
) #快速搭建网络, np.prod 用来计算所有元素的乘积
def forward(self, z): #z代表输入
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img这一部分代码是搭建生成器神经网络,对于大神有自己的想法,对于小白就当成一个套路来做,就是每次搭建网络都这样写,只是改变一下*block里面的数字和激活函数来测试就行,等一段时间学懂了在自己变换神经元的层数和神经层。
inplace=True的意思是进行原地操作,例如x=x+5,对x就是一个原地操作,y=x+5,x=y,完成了与x=x+5同样的功能但是不是原地操作。
至于forward中的z是在程序后面的定义的高斯噪声信号,形状为64*100,其中img.size(0)为64,也就是一批次训练的数目batch_size的值。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity这段定义了一个判别网络,也可以是先拿一个套路来看,
adversarial_loss = torch.nn.BCELoss()定义了一个损失函数nn.BCELoss(),输入(X,Y), X 需要经过sigmoid, Y元素的值只能是0或1的float值,依据这个损失函数来计算损失。
(详细可参看文章:Pytorch详解BCELoss和BCEWithLogitsLossgenerator = Generator())
generator = Generator()
discriminator = Discriminator()这部分是初始化生成器和鉴别器。
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()这部分是给有nvidia的电脑使用GPU加速运算的代码。
os.makedirs('../../data/mnist', exist_ok=True) 这部分创建多级目录(刚开始介绍过),用来储存MNIST的数据资料,这个网络也是用MNIST数据集训练的。
dataloader = torch.utils.data.DataLoader(
datasets.MNIST('../../data/mnist', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
])),
batch_size=opt.batch_size, shuffle=True)这部分中主要的是DataLoader接口的应用:
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。(该段文字来源于文章:PyTorch 中的数据类型 torch.utils.data.DataLoader),简单来说就是你训练的数据集不是一股脑的全部丢进来,而是分成了一批一批的,这个接口函数就是将数据集分批并转化成可以处理的Tensor类型。
transforms.Compose([transforms.ToTensor(),transforms.Normalize(std=(0.5,0.5,0.5),mean=(0.5,0.5,0.5))]),则其作用就是先将输入归一化到(0,1),再使用公式”(x-mean)/std”,将每个元素分布到(-1,1)(来源:00_torchvision.transforms 数据标准化)。
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))这部分是定义了神经网络的优化器,Adam就是一种优化器,当然,优化器是有别的,你大可以选择SGD等别的优化器进行试验,当然,在这个网络中,代码的作者经过试验采用Adam优化器进行优化,里面的参数就是首先是网络类型,lr是学习率,可以在刚开始我们说的opt的参数那里找到数值,学习率的数值也是根据经验和试验进行设定的。Betas是动量梯度的下降,梯度下降是机器学习中用来使模型逼近真实分布的最小偏差的优化方法。(如果想要详细了解梯度下降可以参见文章:Optimization Algorithms优化算法 , 也可以以后需要再看)。
for epoch in range(opt.n_epochs):从这句开始进行训练,训练的次数就是opt.n_epochs,也是从我们刚开始说的参数设定的地方查到。
for i, (imgs, _) in enumerate(dataloader): dataloader中的数据是一张图片对应一个标签,所以imgs对应的是图片,_对应的是标签,而i是enumerate输出的功能,代表序号,enumerate用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中,所以i就是相当于1,2,3…..的数据下标。
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)这部分定义的相当于是一个标准,vaild可以想象成是64行1列的向量,就是为了在后面计算损失时,和1比较;fake也是一样是全为0的向量,用法和1的用法相同。
real_imgs = Variable(imgs.type(Tensor))这句是将真实的图片转化为神经网络可以处理的变量。
接下来训练生成网络:
optimizer_G.zero_grad() #optimizer.zero_grad()意思是把梯度置零这句话就是在每次的训练之前都将上一次的梯度置为零,以避免上一次的梯度的干扰。
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))这部分就是在上面训练生成网络的z的输入值,np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)的意思就是输入从0到1之间,形状为imgs.shape[0], opt.latent_dim的随机高斯数据。
gen_imgs = generator(z)开始得到一个批次的图片,上面说了这些数据是分批进行训练,每一批是64张,所以,这这一批图片为64张。
g_loss = adversarial_loss(discriminator(gen_imgs), valid)这句是计算生成器的损失,adversarial_loss就是在前面定义的adversarial_loss = torch.nn.BCELoss()损失函数来计算损失。
g_loss.backward()
optimizer_G.step()这部分是套路,进行反向传播和模型更新,所有的优化器Optimizer都实现了step()方法来对所有的参数进行更新。
接下来训练判别网络:
optimizer_D.zero_grad()首先,梯度清零,和生成网络一样。
real_loss = adversarial_loss(discriminator(real_imgs), valid)#判别器判别真实图片是真的的损失
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)#判别器判别假图片是假的的损失
d_loss = (real_loss + fake_loss) / 2这部分是很重要了,这个时候这个公式必须上来:
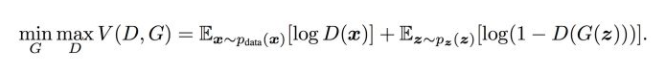
其实我的理解就是判别器去判别真实图片是真的的概率大,并且判别假图片是真的的概率小,说明判别器越准确所以说是maxD,生成器就是想生成真实的图片来迷惑判别器,所以理论上想让生成器生成真实的图片概率大,由于公式第二部分表示生成器的损失,G(z)前有个负号,所以如果结果小则证明G生成的越真实,所以说minG。
d_loss.backward()
optimizer_D.step()仍然是和是和生成网路一样的套路。
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)这一部分就是将生成的图片的25张保存下来。
结语
关于这个GAN网络,很多东西还当成了套路来用,以后再慢慢深入了解,如果文中有错误也希望各位大神不吝赐教。
GitHub源码
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs('images', exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
parser.add_argument('--batch_size', type=int, default=64, help='size of the batches')
parser.add_argument('--lr', type=float, default=0.0002, help='adam: learning rate')
parser.add_argument('--b1', type=float, default=0.5, help='adam: decay of first order momentum of gradient')
parser.add_argument('--b2', type=float, default=0.999, help='adam: decay of first order momentum of gradient')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
parser.add_argument('--latent_dim', type=int, default=100, help='dimensionality of the latent space')
parser.add_argument('--img_size', type=int, default=28, help='size of each image dimension')
parser.add_argument('--channels', type=int, default=1, help='number of image channels')
parser.add_argument('--sample_interval', type=int, default=400, help='interval betwen image samples')
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs('../../data/mnist', exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST('../../data/mnist', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=opt.batch_size, shuffle=True)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, opt.n_epochs, i, len(dataloader),
d_loss.item(), g_loss.item()))
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)













 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









