







项目要点
- 导入cifar图片集: (train_image, train_label), (test_image, test_label) = cifar.load_data() # cifar = keras.datasets.cifar10
- 图片归一化处理: train_image = train_image / 255
- 定义模型: model = keras.Sequential()
- 输入层: model.add(layers.Conv2D(64, (3, 3), activation='relu', input_shape=(32, 32, 3)))
- 添加卷积层: model.add(layers.Conv2D(64, (3, 3), activation='relu'))
- Conv2D(filters, kernel_size, strides, padding, activation=‘relu’, input_shape)
- filters: 过滤器数量
- kernel_size: 指定(方形)卷积窗口的高和宽的数字
- strides: 卷积步长, 默认为 1
- padding: 卷积如何处理边缘。选项包括 ‘valid’ 和 ‘same’。默认为 ‘valid’
- activation: 激活函数,通常设为 relu。如果未指定任何值,则不应用任何激活函数。强烈建议你向网络中的每个卷积层添加一个 ReLU 激活函数。
- input_shape: 指定输入层的高度,宽度和深度的元组。当卷积层作为模型第一层时,必须提供此参数,否则不需要。
- 添加BN层: model.add(layers.BatchNormalization()) # 1.最重要的作用是加快网络的训练和收敛的速度; 2.控制梯度爆炸防止梯度消失; 3.防止过拟合
- 添加池化层: model.add(layers.MaxPooling2D()) # 可以加快计算速度和防止过拟合的作用。
- 添加dropout: model.add(layers.Dropout(0.25)) # 防止神经网络过拟合的手段。随机的拿掉网络中的部分神经元
- 添加全局平均池化: model.add(layers.GlobalAveragePooling2D()) # 替代全连接层, 减少参数数量,减少计算量,减少过拟合
- 添加输出层: model.add(layers.Dense(10, activation='softmax'))
- 查看模型结构: model.summary()
- 配置模型:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])- 训练模型: history = model.fit(train_image, train_label, epochs=30, batch_size=128)
-
模型评估: model.evaluate(test_image, test_label)
-
先BN再 activation 效果较好
-
过拟合处理方式, 正则化: L1, L2, droptout, BN
1 数据集简介
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示。
- 下面这幅图就是列举了10各类,每一类展示了随机的10张图片:

与 MNIST 数据集中目比, CIFAR-10 具有以下不同点:
- CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
- CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
- 相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。 直接的线性模型如 Softmax 在 CIFAR-10 上表现得很差
2 导包
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Dense
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow as tf
cpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())3 数据导入
cifar = keras.datasets.cifar10
(train_image, train_label), (test_image, test_label) = cifar.load_data()
train_image.shape, test_image.shape # ((50000, 32, 32, 3),(10000, 32, 32, 3))
# 归一化处理
train_image = train_image / 255
test_image = test_image / 2554 建立模型
Conv2D 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,过滤器的数量决定了卷积层输出特征个数,或者输出深度。因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量。
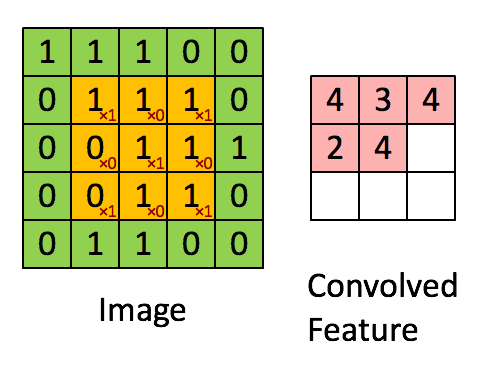
Conv2D(filters, kernel_size, strides, padding, activation=‘relu’, input_shape)
- filters: 过滤器数量
- kernel_size: 指定(方形)卷积窗口的高和宽的数字
- strides: 卷积步长, 默认为 1
- padding: 卷积如何处理边缘。选项包括 ‘valid’ 和 ‘same’。默认为 ‘valid’
- activation: 激活函数,通常设为 relu。如果未指定任何值,则不应用任何激活函数。强烈建议你向网络中的每个卷积层添加一个 ReLU 激活函数。
- input_shape: 指定输入层的高度,宽度和深度的元组。当卷积层作为模型第一层时,必须提供此参数,否则不需要。
GlobalAveragePooling2D()作用:
全局平均池化 作用:如果要预测K个类别,在卷积特征抽取部分的最后一层卷积层,就会生成K个特征图,然后通过全局平均池化就可以得到 K个1×1的特征图,将这些1×1的特征图输入到softmax layer之后,每一个输出结果代表着这K个类别的概率(或置信度 confidence),起到取代全连接层的效果。
优点:
- 和全连接层相比,使用全局平均池化技术,对于建立特征图和类别之间的关系,是一种更朴素的卷积结构选择。 # 替换全连接层
- 全局平均池化层不需要参数,避免在该层产生过拟合。
- 全局平均池化对空间信息进行求和,对输入的空间变化的鲁棒性更强。
# 定义神经网络
model = keras.Sequential()
model.add(layers.Conv2D(64, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D())
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D())
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.Conv2D(256, (1, 1), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.25))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(128))
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
model.summary()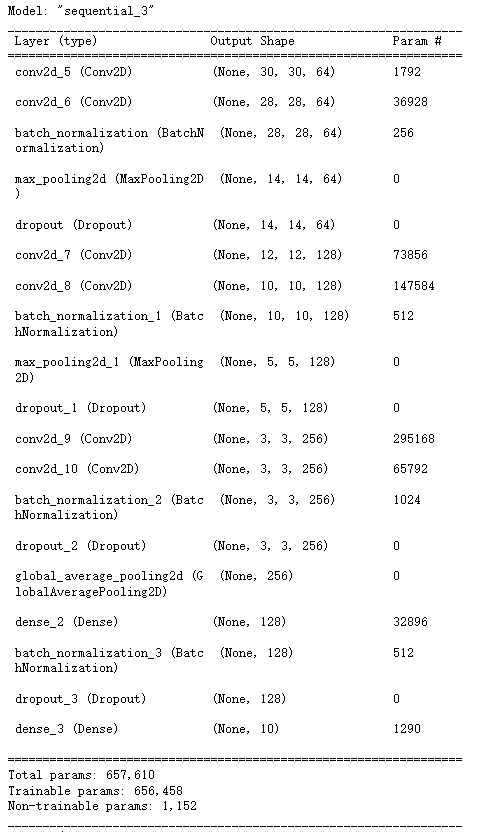
5 模型训练
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
history = model.fit(train_image, train_label, epochs=30, batch_size=128) 
model.evaluate(test_image, test_label) # [0.7276686429977417, 0.7903000116348267]![]()
- 存在一定的过拟合
6 一个简化的模型
- 注意输出层前需要添加全连接层, 不然报错.
# 定义神经网络
model = keras.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation = 'relu', input_shape = (32, 32, 3)))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(10, activation='softmax'))
# 配置网络
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['acc'])
# 训练模型
histroy = model.fit(train_image, train_label, epochs=30, batch_size=128)

7 优化模型
7.1 深度网络
# 如何优化 # 深度网络
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
for _ in range(20):
model.add(tf.keras.layers.Dense(256, activation = 'relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))
7.2 L2正则化
# 如何优化
# l2正则
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
model.add(tf.keras.layers.Dense(512, activation = 'relu', kernel_regularizer = 'l2'))
model.add(tf.keras.layers.Dense(256, activation = 'relu', kernel_regularizer = 'l2'))
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))
7.3 添加dropout层
# dropout
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
model.add(tf.keras.layers.Dense(512, activation = 'relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(256, activation = 'relu'))
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))
7.4 添加alphadropout层
# alphadropout
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
model.add(tf.keras.layers.Dense(512, activation = 'relu'))
model.add(tf.keras.layers.AlphaDropout(0.5))
model.add(tf.keras.layers.Dense(256, activation = 'relu'))
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))
7.5 先BN再 activation (比先激活再BN效果好一点)
# BN操作 # dropout
# 先BN再 activation 效果较好
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
model.add(tf.keras.layers.Dense(512))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))
7.6 先激活再BN层
# 先激活再BN层
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = [32, 32, 3]))
model.add(tf.keras.layers.Dense(512, activation = 'relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dense(256, activation = 'relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
# 配置网络
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
histroy = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data=(x_valid_scaled, y_valid))















 1719
1719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









