







要点:
参考: 官方文档
飞桨预训练模型应用工具PaddleHub
一、概述
首先提个问题,请问十行Python代码能干什么?有人说可以做个小日历、做个应答机器人等等,但是我要告诉你用十行代码可以成功训练出深度学习模型,你相信吗?放心!这个真的可以有,飞桨的PaddleHub可以帮您轻松实现。
PaddleHub是飞桨生态下的预训练模型的管理工具,旨在让飞桨生态下的开发者更便捷地享受到大规模预训练模型的价值。用户可以通过PaddleHub便捷地获取飞桨生态下的预训练模型,结合Fine-tune API快速完成迁移学习到应用部署的全流程工作,让预训练模型能更好服务于用户特定场景的应用。
当前PaddleHub已经可以支持文本、图像、视频、语音和工业应用等五大类主流方向,为用户准备了大量高质量的预训练模型,可以满足用户各种应用场景的任务需求,包括但不限于词法分析、情感分析、图像分类、图像分割、目标检测、关键点检测、视频分类等经典任务。同时结合时事热点,如图1所示,PaddleHub作为飞桨最活跃的生态组成之一,也会及时开源类似口罩人脸检测及分类、肺炎CT影像分析等实用场景模型,帮助开发者快速开发使用。
PaddleHub主要包括如下三类功能:
- 使用命令行实现快速推理:PaddleHub基于“模型即软件”的设计理念,通过Python API或命令行实现快速预测,更方便地使用飞桨模型库。
- 使用预训练模型进行迁移学习:选择高质量预训练模型结合Fine-tune API,在短时间内完成模型训练。
- PaddleHub Serving一键服务化部署:使用简单命令行搭建属于自己的模型的API服务。
二、前置条件
在使用PaddleHub之前,用户需要完成如下任务:
- 安装Python:对于Linux或MAC操作系统请安装3.5或3.5以上版本;对于Windows系统,请安装3.6或3.6以上版本。
- 安装飞桨框架2.2版本,具体安装方法请参见快速安装。
- 安装PaddleHub 2.0或以上版本。
!pip install paddlenlp -U
!pip install paddlehub==2.1.0说明:
使用PaddleHub下载数据集、预训练模型等,要求机器可以访问外网。可以使用server_check()检查本地与远端PaddleHub-Server的连接状态,使用方法如下。 如果可以连接远端PaddleHub-Server,则显示“Request Hub-Server successfully”。否则显示“Request Hub-Server unsuccessfully”。
import paddlehub
paddlehub.server_check()三、预训练模型
PaddleHub支持的预训练模型涵盖了图像分类、关键点检测、目标检测、文字识别、图像生成、人脸检测、图像编辑、图像分割、视频分类、视频修复、词法分析、语义模型、情感分析、文本审核、文本生成、语音合成、工业质检等300多个主流模型。如果用户希望了解模型的具体信息则可以点击官网进行查看。
进入官网后,用户可以点击首页上“学习模型”部分的“所有模型 ”链接查看PaddleHub支持的所有预训练模型。如图2所示,页面的左侧导航栏中可以看到应用场景,网络结构,数据集和发布者等类别。在导航栏右侧,可以看到热门模型榜,最新上线和开发者贡献榜等标签页,帮助您快速锁定热门好用等预训练模型。如果用户希望查看某个预训练模型的具体信息,则可以点击对应页签进行查看。
四、使用命令行实现快速推理
为了能让用户快速体验飞桨的模型推理效果,PaddleHub支持了使用命令行实现快速推理的功能。例如用户可以执行如下命令使用词法分析模型LAC(Lexical Analysis of Chinese)实现分词功能。
说明: LAC是一个联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。
!hub run lac --input_text "现在,慕尼黑再保险公司不仅是此类行动的倡议者,更是将其大量气候数据整合进保险产品中,并与公众共享大量天气信息,参与到新能源领域的保障中。"实现快速推理的命令行的格式如下所示,其中参数解释如下:
- module-name:模型名称。
- input-parameter:输入参数,即上面例子中的“–input_text”
- input-value:推理的输入值,即上面例子中的“今天是个好日子”。
不同的模型,命令行格式和参数取值也不同,具体信息请在每个模型中查看“命令行预测示例”部分。
hub run ${module-name} ${input-parameter} ${input-value}当前PaddleHub中仅有部分预训练模型支持使用命令行实现快速推理功能,具体一个模型是否支持该功能,用户可以通过官网介绍中是否含有命令行预测及服务部署介绍获得。
五、使用预训练模型进行迁移学习
通过高质量预训练模型与PaddleHub Fine-tune API,使用户只需要少量代码即可实现自然语言处理和计算机视觉场景的深度学习模型。以文本分类为例,共分4个步骤:
1. 选择并加载预训练模型
本例使用ERNIE Tiny模型来演示如何利用PaddleHub实现finetune。ERNIE Tiny主要通过模型结构压缩和模型蒸馏的方法,将 ERNIE 2.0 Base 模型进行压缩。相较于 ERNIE 2.0,ERNIE Tiny模型能带来4.3倍的预测提速,具有更高的工业落地能力。
!hub install ernie_tiny==2.0.1import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.1', task='seq-cls', num_classes=2)其中,参数:
name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased,bert-base-chinese,roberta-wwm-ext,roberta-wwm-ext-large等。version:module版本号task:fine-tune任务。此处为seq-cls,表示文本分类任务。num_classes:表示当前文本分类任务的类别数,根据具体使用的数据集确定,默认为2。
PaddleHub还提供BERT等模型可供选择,具体可参见BERT。
2. 准备数据集并读取数据
用户可以选择使用自定义的数据集或PaddleHub提供的数据集进行迁移训练。
(1) PaddleHub提供的数据集ChnSentiCorp
# 自动从网络下载数据集并解压到用户目录下$HUB_HOME/.paddlehub/dataset目录
train_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')tokenizer:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。mode:选择数据模式,可选项有train,test,val, 默认为train。max_seq_len:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过model.get_tokenizer方法获取。
(2) 自定义数据集
如果用户希望使用自定义的数据集,则需要对自定义数据进行相应的预处理,将数据集文件处理成预训练模型可以读取的格式。例如用PaddleHub文本分类任务使用自定义数据时,需要切分数据集,将数据集切分为训练集、验证集和测试集。
a. 设置数据集目录。
用户需要将数据集目录设定为如下格式。
├──data: 数据目录
├── train.txt: 训练集数据
├── dev.txt: 验证集数据
└── test.txt: 测试集数据b. 设置文件格式和内容。
训练集、验证集和测试集文件的编码格式建议为utf8格式。内容的第一列是文本内容,第二列为文本类别标签。列与列之间以Tab键分隔。建议在数据集文件第一行填写列说明"label"和"text_a",中间以Tab键分隔,示例如下:
label text_a
房产 昌平京基鹭府10月29日推别墅1200万套起享97折
教育 贵州2011高考录取分数线发布理科一本448分
社会 众多白领因集体户口面临结婚难题
...c. 加载自定义数据集。
加载文本分类的自定义数据集,用户仅需要继承基类TextClassificationDataset,修改数据集存放地址以及类别即可,具体可以参考如下代码:
from paddlehub.datasets.base_nlp_dataset import TextClassificationDataset
class SeqClsDataset(TextClassificationDataset):
# 数据集存放目录
base_path = '/path/to/dataset'
# 数据集的标签列表
label_list=['体育', '科技', '社会', '娱乐', '股票', '房产', '教育', '时政', '财经', '星座', '游戏', '家居', '彩票', '时尚']
def __init__(self, tokenizer, max_seq_len: int = 128, mode: str = 'train'):
if mode == 'train':
data_file = 'train.txt'
elif mode == 'test':
data_file = 'test.txt'
else:
data_file = 'dev.txt'
super().__init__(
base_path=self.base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
label_list=self.label_list,
is_file_with_header=True)
# 选择所需要的模型,获取对应的tokenizer
import paddlehub as hub
model = model = hub.Module(name='ernie_tiny', task='seq-cls', num_classes=len(SeqClsDataset.label_list))
tokenizer = model.get_tokenizer()
# 实例化训练集
train_dataset = SeqClsDataset(tokenizer)至此用户可以通过SeqClsDataset实例化获取对应的数据集,可以通过hub.Trainer对预训练模型model完成文本分类任务,详情可参考PaddleHub文本分类demo 。
说明:
CV类预训练模型的自定义数据集的设置方法请参考PaddleHub适配自定义数据完成finetune。
3. 选择优化策略和运行配置
运行如下代码,即可实现对文本分类模型的finetune:
import paddle
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_ernie_text_cls', use_gpu=True)
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset, save_interval=1)优化策略
飞桨提供了多种优化器选择,如SGD, Adam, Adamax等, 其中Adam:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
运行配置
Trainer 主要控制Fine-tune的训练,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_gpu: 是否使用gpu;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
trainer.train 主要控制具体的训练过程,包含以下可控制的参数:
train_dataset: 训练时所用的数据集;epochs: 训练轮数;batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;num_workers: works的数量,默认为0;eval_dataset: 验证集;log_interval: 打印日志的间隔, 单位为执行批训练的次数。save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
4. 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在${CHECKPOINT_DIR}/best_model目录下,其中${CHECKPOINT_DIR}目录为Fine-tune时所选择的保存checkpoint的目录。
我们以以下数据为待预测数据,使用该模型来进行预测:
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。import paddlehub as hub
data = [
['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'],
['怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'],
['作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'],
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='seq-cls',
load_checkpoint='./test_ernie_text_cls/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))PaddleHub中不同模型的迁移训练方法请参考:
此外PaddleHub在AI Studio上针对常用的热门模型提供了在线体验环境,欢迎用户使用:
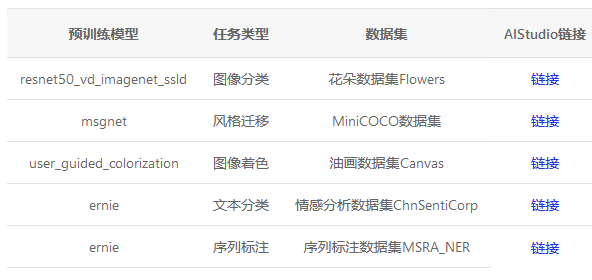
六、PaddleHub Serving一键服务化部署
使用PaddleHub能够快速进行模型预测,但开发者常面临本地预测过程迁移线上的需求。无论是对外开放服务端口,还是在局域网中搭建预测服务,都需要PaddleHub具有快速部署模型预测服务的能力。在这个背景下,模型一键服务部署工具——PaddleHub Serving应运而生。开发者通过一行命令即可快速启动一个模型预测在线服务,而无需关注网络框架选择和实现。
PaddleHub Serving是基于PaddleHub的一键模型服务部署工具,能够通过简单的Hub命令行工具轻松启动一个模型预测在线服务,前端通过Flask和Gunicorn完成网络请求的处理,后端直接调用PaddleHub预测接口,同时支持使用多进程方式利用多核提高并发能力,保证预测服务的性能。
1. 部署方法
使用PaddleHub Serving部署预训练模型的方法如下:
(1) 启动服务端部署
PaddleHub Serving有两种启动方式,分别是使用命令行启动,以及使用配置文件启动。
a. 命令行命令启动
启动命令:
hub serving start --modules Module1==Version1 Module2==Version2 ... \
--port XXXX \
--use_gpu \
--use_multiprocess \
--workers \
--gpu \参数:
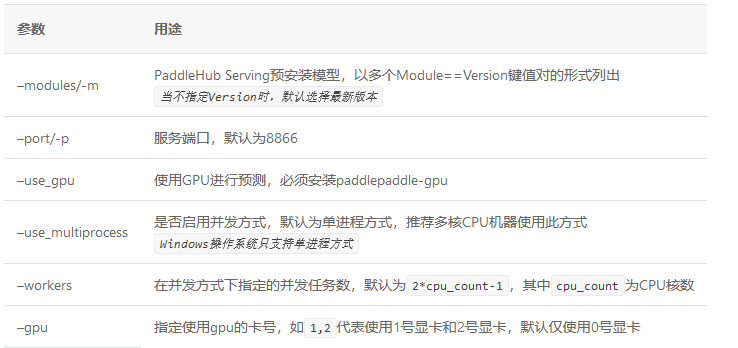
NOTE: --use_gpu不可与–use_multiprocess共用。
b. 配置文件启动
启动命令:
hub serving start --config config.json
其中config.json格式如下:
{
"modules_info": {
"yolov3_darknet53_coco2017": {
"init_args": {
"version": "1.0.0"
},
"predict_args": {
"batch_size": 1,
"use_gpu": false
}
},
"lac": {
"init_args": {
"version": "1.1.0"
},
"predict_args": {
"batch_size": 1,
"use_gpu": false
}
}
},
"port": 8866,
"use_multiprocess": false,
"workers": 2,
"gpu": "0,1,2"
}参数:
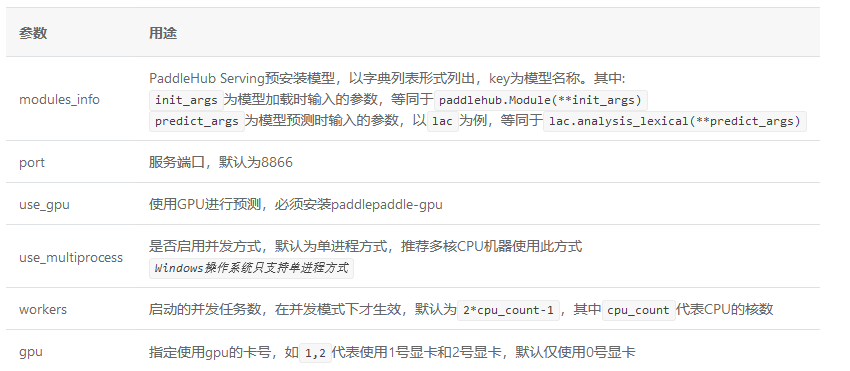
NOTE: --use_gpu不可与–use_multiprocess共用。
(2) 访问服务端
在使用PaddleHub Serving部署服务端的模型预测服务后,就可以在客户端访问预测接口以获取结果了,接口url格式为:
http://127.0.0.1:8866/predict/<MODULE>其中,<MODULE>为模型名。
通过发送一个POST请求,即可获取预测结果,下面我们将展示一个具体的demo,以说明使用PaddleHub Serving部署和使用流程。
(3) 关闭serving
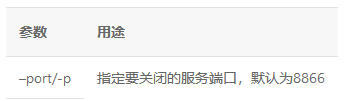
使用关闭命令即可关闭启动的serving,
$ hub serving stop --port XXXX参数:
2. Serving部署在线服务展示
我们将以lac分词服务为例,展示如何利用PaddleHub Serving部署在线服务。
主要分为3个步骤:
(1) 部署lac在线服务
现在,我们要部署一个lac在线服务,以通过接口获取文本的分词结果。
首先,任意选择一种启动方式,两种方式分别为:
$ hub serving start -m lac或
$ hub serving start -c serving_config.json其中serving_config.json的内容如下:
{
"modules_info": {
"lac": {
"init_args": {
"version": "1.1.0"
},
"predict_args": {
"batch_size": 1,
"use_gpu": false
}
}
},
"port": 8866,
"use_multiprocess": false,
"workers": 2
}启动成功界面如图:
这样我们就在8866端口成功部署了lac的在线分词服务。 此处warning为Flask提示,不影响使用
(2) 访问lac预测接口
在服务部署好之后,我们可以进行测试,用来测试的文本为今天是个好日子和天气预报说今天要下雨。
客户端代码如下:
# coding: utf8
import requests
import json
if __name__ == "__main__":
# 指定用于预测的文本并生成字典{"text": [text_1, text_2, ... ]}
text = ["今天是个好日子", "天气预报说今天要下雨"]
# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
# 对应本地部署,则为lac.analysis_lexical(data=text, batch_size=1)
data = {"texts": text, "batch_size": 1}
# 指定预测方法为lac并发送post请求,content-type类型应指定json方式
url = "http://127.0.0.1:8866/predict/lac"
# 指定post请求的headers为application/json方式
headers = {"Content-Type": "application/json"}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(json.dumps(r.json(), indent=4, ensure_ascii=False))运行后得到结果:
{
"msg": "",
"results": [
{
"tag": [
"TIME", "v", "q", "n"
],
"word": [
"今天", "是", "个", "好日子"
]
},
{
"tag": [
"n", "v", "TIME", "v", "v"
],
"word": [
"天气预报", "说", "今天", "要", "下雨"
]
}
],
"status": "0"
}
(3) 停止serving服务
由于启动时我们使用了默认的服务端口8866,则对应的关闭命令为:
$ hub serving stop --port 8866或不指定关闭端口,则默认为8866。
$ hub serving stop等待serving清理服务后,提示:
$ PaddleHub Serving will stop.则serving服务已经停止。

















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









