







 本文介绍了Alexnet模型的背景及其在深度学习中的重要地位,特别是其卷积结构和局部响应归一化层。文章通过TensorFlow详细讲解了如何实现Alexnet,包括模型搭建、权重导入、卷积、池化和LRN操作,并提供了代码示例。重点讨论了tf.split和tf.concat在模型中的应用。
本文介绍了Alexnet模型的背景及其在深度学习中的重要地位,特别是其卷积结构和局部响应归一化层。文章通过TensorFlow详细讲解了如何实现Alexnet,包括模型搭建、权重导入、卷积、池化和LRN操作,并提供了代码示例。重点讨论了tf.split和tf.concat在模型中的应用。
一、Alexnet简介
2012年,Imagenet比赛冠军的model——Alexnet [2](以第一作者alex命名)。
说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大。
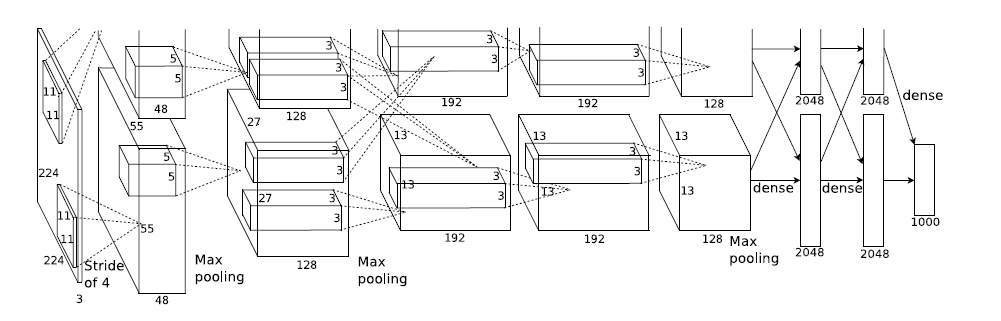
这个模型的特殊之处就在于卷几部分是画成上下两块的,即把输入数据的通道数平分成两份,将这层的feature map分开卷积,池化。如第一层上面的128个map是由上面的48map卷积得到的,到了第二层卷积-池化层的池化时,如图,虚线相互交叉,即每一个192map都是由前面的128+128=256map同时计算得到。
另外,Alexnet有一个特殊的计算层,LRN层
【LRN层】
全称为Local Response Normalization局部响应归一化层
local response normalization最早是由Krizhevsky和Hinton在关于ImageNet的论文里面使用的一种数据标准化方法,即使现在,也依然会有不少CNN网络会使用到这种正则手段。
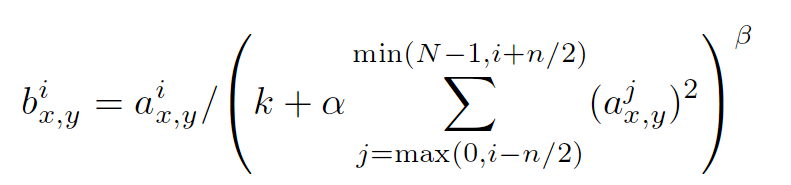
以上是这种归一手段的公式,其中a的上标指该层的第几个feature map,a的下标x,y表示feature map的像素位置,N指feature map的总数量,公式里的其它参数都是超参,需要自己指定的。
这种方法是受到神经科学的启发,激活的神经元会抑制其邻近神经元的活动(侧抑制现象),至于为什么使用这种正则手段,以及它为什么有效,查阅了很多文献似乎也没有详细的解释,可能是由于后来提出的batch normalization手段太过火热,渐渐的就把local response normalization掩盖了吧
tensorflow 中所用函数为:
tf.nn.lrn(input, depth_radius=None, bias=None, alpha=None, beta=None, name=None)
第一个参数input:这个输入就是feature map了,既然是feature map,那么它就具有[batch, height, width, channels]这样的shape
第二个参数depth_radius:这个值需要自己指定,就是上述公式中的n/2
第三个参数bias:上述公式中的k
第四个参数alpha:上述公式中的α
第五个参数beta:上述公式中的β
返回值是新的feature map,它应该具有和原feature map相同的shape
二、Alexnet具体实现
此处参考的是https://github.com/kratzert/finetune_alexnet_with_tensorflow
该例可以用任何自己的数据集从任意一层开始进行重新训练
1. 模型搭建
这里先考虑写一个Al
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4827
4827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









