







一、好的数据集什么样?
提供数据的人往往不是专业人士,他们给的数据集很自由。交给数据分析师的时候,分析师就很头疼了。这数据的结构一点也不放面研究。所以为了更好地分析数据,数据清理的一个主要任务就是提供标准化结构的数据集。
那问题来了,好的数据集应该是什么样的呢?
大原则有3条:
每一个变量是一列;
每个观测值是一行;
每一种类型观测值单元组成一个表。
我们举个例子:
| treatmenta | treatmentb | |
|---|---|---|
| John | - | 2 |
| Jane | 16 | 11 |
| Mary | 3 | 1 |
上面这个数据集就不是很nice,treatmenta和treatmentb本身就是一个变量的两个值。
这里会出现问题,比如,John在treatmenta这里有空缺值,为了不影响计算,我们要把这一行去掉。也无形当中把John在treatmentb这一个值也给删除了。
所以,这个数据集,可以这样子来整理:
| person | treatment | result |
|---|---|---|
| John | a | - |
| Jane | a | 16 |
| Mary | a | 3 |
| John | b | 2 |
| Jane | b | 11 |
| Mary | b | 1 |
除了以上的三个大原则之外,还有一些推荐的小原则:
- 分类变量在前,测量中产生的变量放后。
- 相关变量放在一起。
- 第一个变量最好能用于排序。
二、数据清理实战·数据的分散和聚合
当我们拿到数据集之后,第一步就是找出观测值是什么,变量是什么。
第二步是解决两个常见的问题:
- 有些变量会扩散到多列。
- 有些观测值会分散在多行。
解决这两个问题,可以用tidyr库中的gather和spread函数。
数据聚合gathering
什么是聚合,我们看下面这个数据集的结构:
| name | 1990 | 1991 |
|---|---|---|
| 小明 | 98 | 32 |
| 小红 | 98 | 22 |
你瞅瞅,第二列和第三列其实是一个变量的两个值。所以每一行就代表了两个观察值了。简而言之,这个数据集不干净的地方在于把值当成列名了,我们需要的是把变量做为列。
这个时候,我们要用到gather函数,把数据集整理成以下的样子:
| name | year | num |
|---|---|---|
| 小明 | 1990 | 98 |
| 小明 | 1991 | 32 |
| 小红 | 1990 | 98 |
| 小红 | 1991 | 22 |
数据分散spreading
spreading就是gathering的反向操作。
比如,我们看下面的数据集:
| name | year | type | num |
|---|---|---|---|
| 小明 | 1990 | 车 | 2 |
| 小明 | 1990 | 房 | 1 |
| 小红 | 1991 | 车 | 3 |
| 小红 | 1991 | 房 | 10 |
看看这个数据集,描述小明时,其实就是四个信息:
姓名(name)
年份(year)
车2个
房子1个
但是这个数据,却分散成两行了。
我们希望的数据集是这样的:
| name | year | 车 | 房 |
|---|---|---|---|
| 小明 | 1990 | 2 | 1 |
| 小红 | 1991 | 3 | 10 |
这个时候我们用spread函数。
清理实战-实践
我们先来创建一个tibble,所谓的tibble就是类似于data.frame的东西,但是更轻便。
stock <- tibble(year=c(2015,2015,2016,2016),half=c(1,2,1,2),return=c(1.88,0.59,0.92,0.17))
以上代码生成下面的数据集:

我们可以这样理解,
第一行代表2015年上半年回报率是1.88。
第二行代表2015年下半年回报率是0.59。
假设我们把2015年当成一个观测值,我们可以看到这一个观测值分到了两行里。这个时候我们用spread函数试一下。
(spread(stock,key=half,value=return))
结果如下:

其实你可以猜到spread的两个参数,第一个key就是类别,它会变成列。对应的就是这个类别下的数据。
但是如果我们把每个半年当成一个观测值,那现在就出现问题了,上面的数据集中列1和列2就属于一个变量的两个值。
这个时候我们用gather。
(spread(stock,key=half,value=return) %>% gather("1","2",key="half",value="return"))

看一看,这是不是就回去了。
三、数据清理实战·对付缺失值
数据缺失有两种形式:
- 被标记为缺失NA
- 隐性缺失
方法一:通过gather和spread变换数据集
比如我们来看一组数据集:
stock <- tibble(year=c(2015,2015,2015,2015,2016,2016,2016),qrt=c(1,2,3,4,2,3,4),return=c(1.88,0.59,0.35,NA,0.92,0.17,2.66))
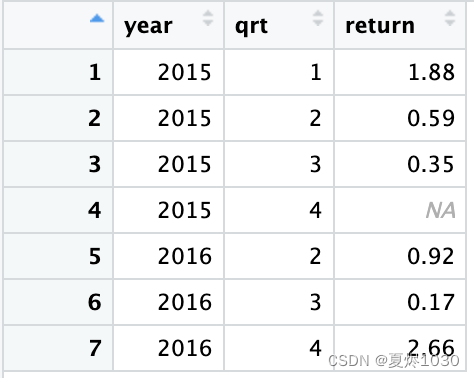
很明显,2015第四季度的值缺失了,但与此同时,我们也能看出来2016年第一季度的值是没出现的,这也属于缺失值。
我们转换一下数据集就能方便看出来了:
(stock %>% spread(year,return))

在这种形式下,就出现了两个NA。
如果我们再聚合一下:
(stock %>% spread(year,return) %>% gather(year,return,`2015`:`2016`))

如果这些缺失值不重要,那可以加上na.rm=TRUE这个参数。
(stock %>% spread(year,return) %>% gather(year,return,`2015`:`2016`,na.rm=TRUE))

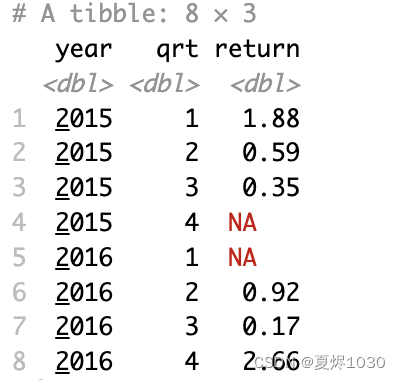
方法二:通过complete
complete取几个列,把所有唯一组合取出来。
比如:
complete(year,qrt)
就是把每一年每一个季度的组合都取出来。
stock %>% complete(year,qrt)
方法3:补充空值。
可以用fill的方式把空值直接补充。
我们再建立一个简单的数据集。
treat <- tribble(~person,~treatment,~response,"Derrick",1,7,NA,2,10,NA,3,9,"Kate",1,4)

treat %>% fill(person)

你应该猜出来了,补充的值就是前一个有值的内容。
四、综合案例研究
我们这次案例使用的数据集是tidyr包中的who数据集。
这个数据集里面包含了对于肺结核病人的调研。
?who
head(who)
我们通过这两条命令了解一下这个数据集的构成。

这里我们看到这个数据集有60列。
第一列: country
国家名
第2\3列: iso2,iso3
这里指的是国家代号
也就是说数据前三列都是代表国家
第四列: year
年份
从第五列开始,分别是new_sp_m014一直到new_rel_f65
这里面是用了三个编码来描述这个群体的。
前三个字母(如new__)代表是新病例还是老病例。
接下来几个字母代表肺结核类型:
比如:ne_ep_*:代表肺外结核(这个比较专业术语了,我也不知道准不准确,反正就是肺结核的不同类型)
第二个下划线后面的m代表男性,f代表女性
最后一串数字代表年龄段
014=0-14岁
25-34=25-34岁
我们能看到这个数据集的列更像是“值”,而不是变量。所以我们按照我们之前讲的,需要对这个数据集进行gather。
who1 <- who %>% gather(new_sp_m014:newrel_f65,key="key",value="cases",na.rm=TRUE)
(who1)
之所以把新产生的列称为key,因为暂时还不知道这个新产生变量的含义。
此外,这个数据集里面有很多缺失值,所以我们加上na.rm=TRUE这个参数。
结果如下图:

那既然key的值是由4个变量组成的,那我们肯定希望把这四个变量分开。这时候我们可以用separate函数。
separate函数什么作用呢?
举个例子,如果key的值是new_sp_m014这样的形式,那经过separate之后,key这一列就会分成三列,分别包含new对应的值,sp对应的值,m014对应的值。这就符合每一列都是一个变量这个原则了。
于是我们用count这个函数检查一下,key的值是不是都是都由三部分组成的。
结果真是恶心:
who1 %>% count(key) %>% print(n=56)
结果中有一部分不堪入目:

也就是说newrel这个变量并没有遵从new_rel这种写法。
所以为了解决这个问题,我们用字符串替换函数,把newrel变成new_rel
who2 <- who1 %>% mutate(key=stringr::str_replace(key,"newrel","new_rel"))
用print函数打印一下看看有没有修改完成。

好,这样没有其他情况了,我们可以进行separate了。
who3 <- who2 %>% separate(key,c("new","type","sexage"))
结果如下:
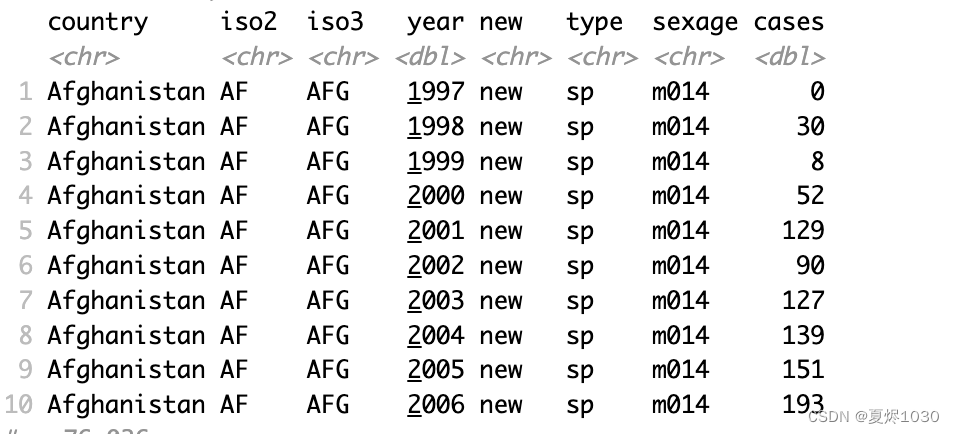
目前有的问题是sexage是sex和age两个变量的组合,那我们再separate一次。
who4 <- who3 %>% separate(sexage,c("sex","age"),sep=1)
结果如下:
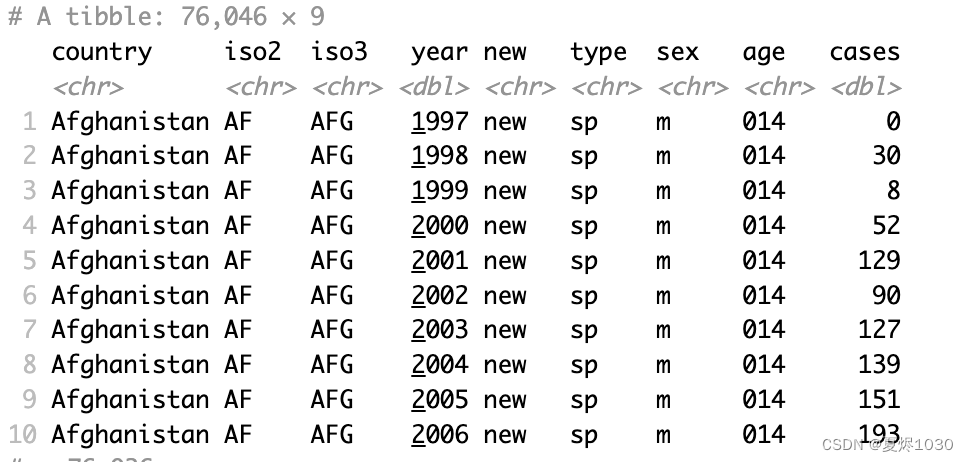
那我们再检查一下,每一行都是一个观测值,每一列都是一个变量,这个整体组成了一个表。
所以,经过一番操作之后,这个表终于算是干净了。















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









