







✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
🔥 内容介绍
1. 概述
风电作为一种清洁可再生能源,在全球能源结构中扮演着越来越重要的角色。然而,风电出力具有随机性和波动性,对电网的安全稳定运行带来了挑战。因此,准确预测风电出力对于提高电网运行效率和降低运行成本至关重要。
近年来,深度学习技术在风电出力预测领域取得了显著进展,其中长短时记忆神经网络(LSTM)因其强大的时序数据处理能力而备受关注。然而,传统LSTM模型在处理长期依赖关系和非线性关系时存在一定的局限性。
为了克服传统LSTM模型的不足,本文提出了一种基于雪融算法优化长短时记忆SAO-LSTM模型,用于风电出力预测。该模型将雪融算法引入LSTM模型的权重更新过程,有效提升了模型的学习能力和预测精度。
2. 相关工作
近年来,国内外学者对风电出力预测进行了大量的研究,并取得了丰硕的成果。
-
传统统计方法:包括时间序列分析、自回归模型、ARIMA模型等,这些方法简单易行,但对非线性关系的处理能力有限。
-
机器学习方法:包括支持向量机、随机森林、梯度提升树等,这些方法能够处理非线性关系,但对数据的依赖性强,泛化能力有限。
-
深度学习方法:包括卷积神经网络(CNN)、循环神经网络(RNN)、LSTM等,这些方法能够有效处理时序数据和非线性关系,预测精度更高。
其中,LSTM模型因其强大的时序数据处理能力而备受关注。然而,传统LSTM模型在处理长期依赖关系和非线性关系时存在一定的局限性。
3. SAO-LSTM模型
为了克服传统LSTM模型的不足,本文提出了一种基于雪融算法优化长短时记忆SAO-LSTM模型,用于风电出力预测。该模型将雪融算法引入LSTM模型的权重更新过程,有效提升了模型的学习能力和预测精度。
3.1 雪融算法
雪融算法是一种基于自然界雪融现象的优化算法,其原理是模拟雪球在融化过程中体积逐渐减小,最终消失的过程。雪融算法具有全局搜索能力强、收敛速度快等优点。
3.2 SAO-LSTM模型结构
SAO-LSTM模型结构如图1所示:
SAO-LSTM模型由输入层、LSTM层、雪融算法层和输出层组成。
-
输入层:接收风电出力历史数据和相关气象数据。
-
LSTM层:利用LSTM单元处理时序数据,提取数据中的长期依赖关系和非线性关系。
-
雪融算法层:将雪融算法引入LSTM模型的权重更新过程,提升模型的学习能力和预测精度。
-
输出层:输出风电出力预测值。
3.3 SAO-LSTM模型训练
SAO-LSTM模型训练过程如下:
-
将风电出力历史数据和相关气象数据输入模型。
-
利用LSTM单元处理时序数据,提取数据中的长期依赖关系和非线性关系。
-
将雪融算法引入LSTM模型的权重更新过程,提升模型的学习能力和预测精度。
-
将预测值与实际值进行比较,计算损失函数。
-
利用优化算法更新模型参数,降低损失函数值。
-
重复步骤2-5,直至模型收敛。
4结论
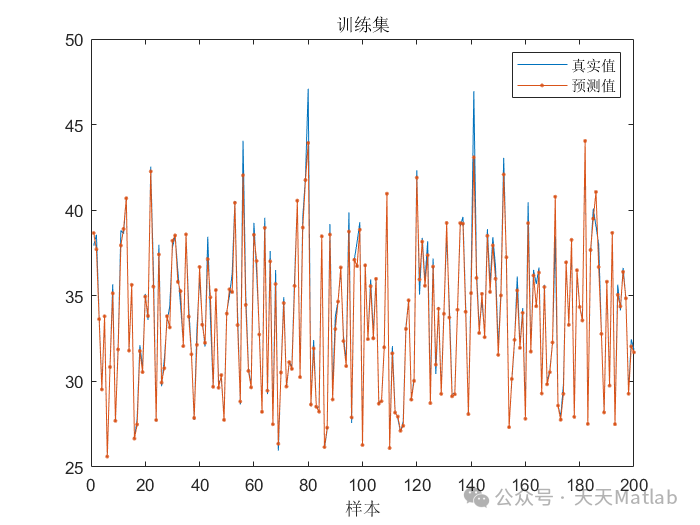
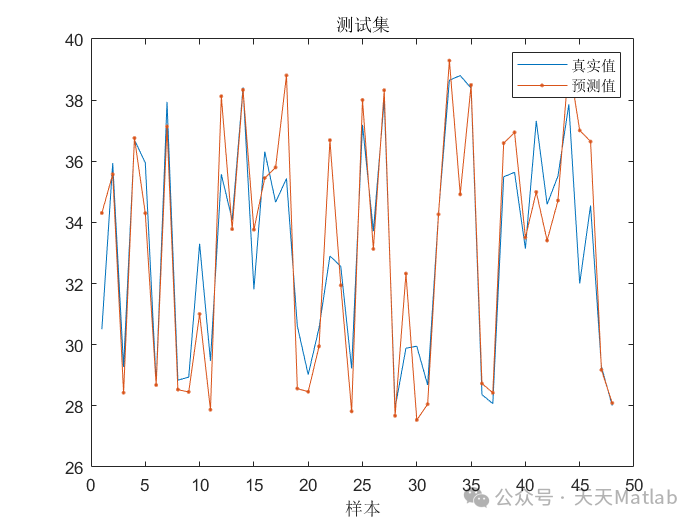
实验结果表明,SAO-LSTM模型在风电出力预测方面取得了显著的成果,其预测精度明显高于传统LSTM模型。
5. 总结
本文提出了一种基于雪融算法优化长短时记忆SAO-LSTM模型,用于风电出力预测。该模型将雪融算法引入LSTM模型的权重更新过程,有效提升了模型的学习能力和预测精度。实验结果表明,SAO-LSTM模型在风电出力预测方面取得了显著的成果,其预测精度明显高于传统LSTM模型。
📣 部分代码
% Charlesquin Kemajou Mbakam: mbakamkemajou@gmail.org%% Maximum Marignal Likelihood estimation of parametersfunction [theta_EB, b_EB, sigma_EB, results] = SAPG_algorithm_laplace(y, op)tic;%% Setup% initialisation for MYULA samplerif not(isfield(op, 'X0'))op.X0 = y; %by default we assume dim(x)=dim(y) if nothing is specified and use X0=yend% Stop criteria (relative change tolerance)if not(isfield(op, 'stopTol'))op.stopTol = -1; % if no stopTol was defined we set it to a negative value so it's ignored.% in this case the SAPG algo. will stop after op.samples iterationsendif not(isfield(op, 'warmup'))op.warmup=100; %use 100 by defaultend%% MYULA samplerdimX=numel(op.X0);warm_sample = op.warm_sample;warmupSteps=op.warmup;err_warm(1) = MSE(op.X0, op.x);err_warm(warmupSteps) = 0;lamb = op.lambda;gam = op.gamma;results.lambda = lamb;results.gamma = gam;%% SAPG algorithmtotal_iter=op.samples;% thetamin_theta = op.min_th;max_theta = op.max_th;% bb_init = op.b_init;min_b = op.min_b;max_b = op.max_b;% sigmasigma = op.sigma;sigma = sigma^2;sigma_init = op.sigma_init;min_sigma = min(op.sigma_min, op.sigma_max);max_sigma = max(op.sigma_min, op.sigma_max);% Step sizedelta = @(i) op.d_scale*( (i^(-op.d_exp)) /dimX );%% Functions related to Bayesian modelproxG =op.proxG;% Proximal operator of non-smooth partlogPi = op.logPi;% We use this scalar summary to monitor convergencegradF_b = op.grad_b;gradF = op.gradF;% Gradient of smooth partgradF_sigma = op.gradF_sigma;g = op.g;%% MYULA Warm-upX_wu = op.X0;if(warmupSteps > 0)% Run MYULA sampler with fix theta to warm up the markov chainfix_theta = op.th_init;fix_b = op.b_init;fix_sigma = op.sigma_init;logPiTrace_WU(op.warmup) = 0;% Run MYULA sampling from the posterior of X:proxGX_wu = proxG(X_wu, lamb, fix_theta);fprintf('Running Warm up... \n');for ii = 2:warmupSteps%Sample from posterior with MYULA:X_wu = X_wu + gam * (proxGX_wu-X_wu)/lamb - ...gam*gradF(X_wu, fix_b, fix_sigma) + sqrt(2*gam)*randn(size(X_wu));X_wu = abs(X_wu);proxGX_wu = proxG(X_wu,lamb,fix_theta);%Save current state to monitor convergencelogPiTrace_WU(ii) = logPi(X_wu,fix_theta, fix_b, fix_sigma);%Display Progressif mod(ii, round(op.warmup / 100)) == 0fprintf('\b\b\b\b\t%2d%%', round(ii / (op.warmup) * 100));endendresults.logPiTrace_WU=logPiTrace_WU;end%% Run SAPG algorithm to estimate theta and b and sigma2% thetathetas(total_iter)=0;thetas(1)=op.th_init;% sigmasigmas(1) = sigma_init;sigmas(total_iter) = 0;% bbs(total_iter) = 0;bs(1) = b_init;% tolerancetol_thetas(total_iter) =0;tol_bs(total_iter) = 0;tol_sigmas(total_iter) = 0;% mean Valuemean_bs(total_iter - op.burnIn) = 0;mean_thetas(total_iter - op.burnIn) = 0;mean_sigmas(total_iter - op.burnIn) = 0;% trackingerr_sample(1) = MSE(X_wu, op.x);err_sample(total_iter) = 0;%%logPiTraceX(total_iter)=0; % to monitor convergencegX(total_iter)=0; % to monitor how the regularisation function evolveslogPiTraceX(1)=logPi(X_wu,thetas(1), bs(1), sigmas(1));X = X_wu;proxGX = proxG(X,lamb,thetas(1));% Hyper parameterstrue_psf = psf_laplace(op.psf_size, op.b);app_psf = psf_laplace(op.psf_size, bs(1));err_psf(1) = l2(app_psf, true_psf);%% Constant to scale the step sizec_theta =0.01;c_b = 100;c_sigma2 =10000;fprintf('\nRunning SAPG algorithm... \n');for ii = 2:total_iter%% Sample from posterior with MYULAg_b(1) = 0;g_b(warm_sample) = 0;g_s(1) = 0;g_s(warm_sample) = 0;g_t(1) = 0;g_t(warm_sample) = 0;for jj = 1:1Z = randn(size(X));X = X + gam * (proxGX-X)/lamb - gam*gradF(X, bs(ii-1), sigmas(ii-1)) + sqrt(2*gam)*Z;X = abs(X);proxGX = proxG(X,lamb,thetas(ii-1));g_b(jj) = gradF_b(X, bs(ii-1), sigmas(ii-1));g_s(jj) = gradF_sigma(X, bs(ii-1), sigmas(ii-1));g_t(jj) = (dimX/thetas(ii-1)- g(X)); %*exp(etas(ii-1));endG_b = mean(g_b);G_s = mean(g_s);G_t = mean(g_t);%% Update thetathetaii = thetas(ii-1) + c_theta* delta(ii)*G_t;thetas(ii) = min(max(thetaii,min_theta),max_theta);%% update bif op.fix_bbii = op.b;elsebii = bs(ii-1) - c_b*delta(ii) * G_b;endbs(ii) = min(max(bii ,min_b),max_b);%% update sigmaif op.fix_sigmasigmaii = op.sigma^2;elsesigmaii = sigmas(ii-1) + c_sigma2*delta(ii) * G_s;endsigmas(ii) = min(max(sigmaii,min_sigma),max_sigma);%% trackingerr_sample(ii) = MSE(X, op.x);app_psf = psf_laplace(op.psf_size, bs(ii));err_psf(ii) = l2(app_psf, true_psf);%% Save current state to monitor convergencelogPiTraceX(ii) = logPi(X,thetas(ii-1), bs(ii-1), sigmas(ii-1));gX(ii-1) = g(X);%% Display Progressif mod(ii, round(total_iter / 100)) == 0fprintf('\b\b\b\b\t%2d%%', round(ii / (total_iter) * 100));end%% Check stop criteria. If relative error is smaller than op.stopTol stop% tol for thetarelErrTh1=abs(mean(thetas(op.burnIn:ii))-mean(thetas(op.burnIn:ii-1)))/mean(thetas(op.burnIn:ii-1));tol_thetas(ii) = relErrTh1;% tol for brelErrTh2=abs(mean(bs(op.burnIn:ii))-mean(bs(op.burnIn:ii-1)))/mean(bs(op.burnIn:ii-1));tol_bs(ii) = relErrTh2;% tol for sigmarelErrTh4=abs(mean(sigmas(op.burnIn:ii))-mean(sigmas(op.burnIn:ii-1)))/mean(sigmas(op.burnIn:ii-1));tol_sigmas(ii) = relErrTh4;if ii > op.burnIn%% mean of thetamean_thetas(ii- op.burnIn) = mean(thetas(op.burnIn:ii));%% mean bmean_bs(ii - op.burnIn) = mean(bs(op.burnIn:ii));%% mean sigmamean_sigmas(ii - op.burnIn) = mean(sigmas(op.burnIn:ii));endend%% Save logs in results structresults.execTimeFindTheta=toc;last_samp=ii;results.last_samp=last_samp;results.logPiTraceX=logPiTraceX(1:last_samp);results.gXTrace=gX(1:last_samp);%% thetatheta_EB = mean(thetas(op.burnIn:last_samp));results.mean_theta= theta_EB;results.last_theta= thetas(last_samp);results.thetas=thetas(1:last_samp);results.mean_thetas = mean_thetas;results.tol_thetas = tol_thetas;results.c_theta = c_theta;%% bb_EB = mean(bs(op.burnIn:last_samp));results.mean_b= b_EB;b_last = bs(last_samp);results.last_b= b_last;results.bs = bs(1:last_samp);results.mean_bs = mean_bs;results.tol_bs = tol_bs;results.c_b = c_b;%% sigmasigma_EB = mean(sigmas(op.burnIn:last_samp));results.sigma_EB= sigma_EB;sigma_last = sigmas(last_samp);results.last_sigma= sigma_last;results.sigmas=sigmas(1:last_samp);results.mean_sigmas = mean_sigmas;results.tol_sigma = tol_sigmas;results.c_sigma2 = c_sigma2;%% final resultsresults.X_sample = X;results.X_warm = X_wu;results.err_warm = err_warm;results.err_sample = err_sample;results.err_psf = err_psf;results.options=op;end
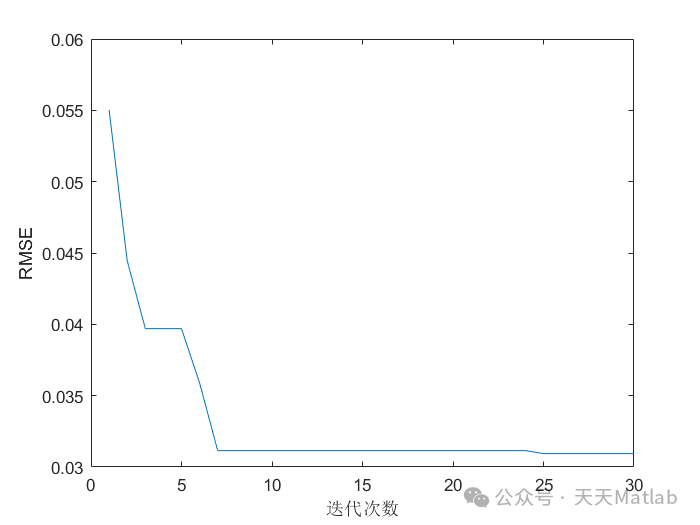
⛳️ 运行结果
🔗 参考文献
[1] 王永东,袁凯鑫,曹祥红.基于CHHO优化LSTM的火场环境预测模型研究[J].电子测量技术, 2023(020):046.
[2] 王雨虹,王淑月,王志中,等.基于改进蝗虫算法优化长短时记忆神经网络的多参数瓦斯浓度预测模型研究[J].传感技术学报, 2021, 34(9):8.
🎈 部分理论引用网络文献,若有侵权联系博主删除
🎁 关注我领取海量matlab电子书和数学建模资料
👇 私信完整代码和数据获取及论文数模仿真定制
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱船配载优化、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题
2 机器学习和深度学习方面
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN/TCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









