






相关申明 项目地址
@article{Ranftl2020, author = {Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun}, title = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2020}, }@article{Ranftl2021, author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun}, title = {Vision Transformers for Dense Prediction}, journal = {ArXiv preprint}, year = {2021}, }
Abstract
大量且多样化的训练集支撑了 monocular depth estimation 的研究。因为不同规模的环境中获得密集的地面真实深度具有挑战性,所以出现了许多具有不同特征和偏差的数据集。文章开发的工具可以在训练过程中混合多个数据集,即使它们的注释不兼容。特别地,文章提出了一个稳健的训练目标——深度范围和规模的变化不变,提倡使用原则的多目标学习结合来自不同来源的数据,并强调在辅助任务的预训练编码器的重要性。有了这些工具,研究实践了五个不同的训练数据集,包括一个新且庞大的数据源:3D电影。为了证明方法的泛化能力,使用了零镜头跨数据集传输,即对在训练期间没有看到的数据集进行了评估。实验证实,来自互补来源的混合数据大大提高了单眼深度估计。同时,文章的方法在不同数据集上明显优于竞争方法,为单眼深度估计奠定了新的新水平。
关键词:单眼深度估计,单图像深度预测,零镜头跨数据集传输,多数据集训练
Zero-shot Cross-dataset Transfer:在训练期间没有看到的数据集进行了评估。
Monocular depth estimation
Single-image depth prediction
Introduction
深度在物理环境中很有用,但单眼深度估计依旧存在很多挑战——多方面受限制。要解决这个问题,必须利用许多(有时微妙)的视觉线索,以及长期上下文和先验知识,因此需要基于学习的技术。
context
prior knowledge
为了学习在各种场景中有效的模型,需要训练具有相同变化的数据,并捕获视觉世界的多样性 。关键挑战点是获取足够规模的这些数据。在动态场景中提供(密集的)地面真实深度的传感器,如结构化的光或飞行时间,其射程和操作条件有限;激光扫描仪比较贵,只能在场景运动时提供稀疏的深度测量;立体声相机是的一个很有效的数据来源,但在不同规模的环境中收集合适的立体声图像仍然是一个挑战;SfM重建已被用于构建训练数据,跨各种场景进行单眼深度估计,但结果不包括独立移动的对象且因为多视图匹配的局限性,其结果不完整。(研究背景&痛点)总的来说,现有的数据集中没有一个足够丰富,以支持在不同场景的真实图像上工作有效的模型的训练。(研究出发点)目前,现有多个数据集,它们可以有效的相互补充,但拥有各自的偏差和不完整性。
在文章中,作者研究了训练robust单眼深度估计模型的方法,期望能在在不同的环境中执行。作者提出了新的损失函数,它基于数据集之间不兼容的主要来源不变,包括未知和不一致的规模和基线。损失函数允许对通过各种传感模式获得的数据进行训练,如立体相机(潜在未知校准)、激光扫描仪和结构化光传感器。同时还量化了各种现有数据集的单眼深度估计的值,探索了在训练过程中混合数据集的最佳策略。特别地,作者证明了一种基于多目标优化的原则方法,与一种朴素的混合策略相比,会得到改进的结果。且进一步通过经验强调了高容量编码器的重要性,并证明了在大规模辅助任务上对编码器进行预训练的不合理有效性。
unreasonable effectiveness:
大量实验包括大约6个月GPU的计算,表明一个模型通过适当的训练程序,对来自不同来源的丰富多样的图像进行训练,提供了在不同的环境中最先进的结果。为了证明这一点,作者使用了零镜头跨数据集传输的实验协议,即在某些数据集上训练一个模型,然后在其他数据集(训练过程未出现过的)上测试其性能。直觉上,零镜头跨数据集性能比训练和测试在单个数据集时更忠实的于真实世界在很大程度上表现出相同偏差。
在对六个不同数据集的评估中,作者的方案在定量和定性上都优于现有技术,并为单眼深度估计奠定了一个新的技术水平。案例结果如图1所示

图1.展示了如何利用来自多个互补源的训练数据来进行单视图深度估计,尽管存在不同的和未知的深度范围和规模。作者的方法能够跨数据集进行很强的泛化。顶部:输入图像。中间:用该方法预测的逆深度图。底部:从一个新的视点呈现的相应的点云。通过Open3D渲染的点云。输入来自微软COCO数据集的图像,这在训练期间没有使用。
strong generalization
Related Work
早期的单眼深度估计工作使用了基于MRF的公式,简单的几何假设,或非参数方法。最近,通过利用卷积网络的表达能力,直接从输入图像回归场景深度,取得了重大进展。各种架构创新已经被提出来提高预测精度,通常使用RGB-D相机或激光雷达传感器获得地面真实深度(必需)进行训练。其他人利用现有的立体匹配方法来获得监督的真实地面。(研究痛点)这些方法往往在用于训练它们的特定类型的场景中效果很好,但由于训练数据的规模和多样性有限,因此不能很好地推广到不受约束的场景。
Garg等人建议使用校准的立体声摄像机进行自我监督,这虽然大大简化了训练数据的获取,但它仍然没有解除对一个非常特定的数据制度的限制。从那时起,各种方法都利用了自我监督,但它们要么需要立体图像,要么利用表观运动,因此很难应用于动态场景。
作者认为,(研究想法)单眼深度估计的高容量深度模型原则上可以操作于相当宽和无约束的场景范围。限制它们性能的原因是缺乏跨越如此广泛条件的大规模、密集的真实地面。常用的数据集具有均匀的场景布局,如特定地理区域的街道场景或室内环境。特别注意到,这些数据集只显示了少量的动态对象。在具有如此强烈偏差的数据上训练的模型在约束较少的环境中容易失败。
high-capacity deep models
研究者们一直在努力创建更多样化的数据集。如......
据作者所知,(研究需求)在此背景下之前还没有探索过多个数据源的受控混合。 Ummenhofer等人提出了一种用于双视图结构和运动估计的模型,并在(静态)场景数据集上对其进行训练,该数据集是多个较小数据集的联合,但是,他们没有考虑最佳混合的策略,也没有研究组合多个数据集的影响。 同样,Facil 等人使用具有简单混合策略的多个数据集来学习具有已知相机内在特性的单眼深度, 他们的测试数据与他们训练集的一半非常相似,即室内场景的 RGB-D 记录。
Existing Datasets
已经提出了的各种适合于单眼深度估计的数据集,它们由RGB图像组成。数据集在捕获的环境和对象(室内/室外场景、动态对象)、深度注释类型(稀疏/密集、绝对/相对深度)、精度(激光、飞行时间、SfM、立体声、人工注释、合成数据)、图像质量和相机设置以及数据集大小等方面都有所不同。
每个数据集都有自己的特性,并有自己的偏差和问题。对于动态对象,高精度数据很难大规模获取,而且存在问题,而来自互联网来源的大数据收集的图像质量和深度精度有限,以及未知的相机参数。在单个数据集上进行训练可以在同一数据集(相同摄像机参数、深度注释、环境)的相应测试分割上获得良好的性能,但可能对具有不同特征的看不见数据具有有限的泛化能力。因此,作者在一组数据集上进行训练,并通过在不同数据集上(训练未使用)进行测试证明这种方法导致强烈增强的泛化。在表1中列出了我们的训练和测试数据集,以及它们的个体特征。
表1在我们的工作中使用的数据集。顶部:作者的训练集。底部:作者的测试集。没有一个真实世界的数据集(大量不同的具有密集和准确的真实地面的场景)。

Training datasets
作者用5个现有的互补数据集进行了训练实验。ReDWeb(RW)是一个小的、精心策划的数据集,具有多样的动态场景,是通过相对较大的立体基线获得的。MegaDepth(MD)要大得多,但主要是静态场景。由于使用宽基线多视图立体重建进行采集,因此在背景区域的地面真相通常更准确。WSVD(WS)由从网络上获得的立体声视频组成,具有多样化的动态场景,此数据集只能作为立体声视频链接的一个集合提供,没有提供任何事实真相,因此,作者根据原始作者概述的程序重现了地面真相。室内场景(DIMLIuvoon,DL)是一个主要是静态室内场景的RGB-D数据集,使用Kinectv2捕获。
complementary datasets
ReDWeb(RW) MegaDepth(MD)WSVD(WS) DIML luvoon(DL)
Test datasets
为了对单眼深度估计模型的泛化性能进行基准测试,根据地面真实数据集的多样性和准确性选择了6个数据集。DIW高度多样化,但仅以稀疏有序关系的形式提供地面真理。ETH3D具有高精度的激光扫描地面真相在静态场景。Sintel 具有完美的地面真相的合成场景。KITTI和NYU是具有特征偏差的常用数据集。对于TUM数据集,使用了在室内环境中以人类为特征的动态子集。请注意,作者从未对任何这些数据集上进行微调模型,将这个实验过程称为零镜头交叉数据集传输。
generalization performance
benchmark
DIW ETH3D Sintel KITTI NYU TUM
zero-shot cross-dataset transfer
3D Movies
为了补充现有的数据集,作者提出了一个新的数据源:3D电影(MV)。3D电影以高质量的视频帧为特色,包含以人类为重心、故事和对话发展的好莱坞电影到自然场景、风景和动物的纪录片等各种动态场景。虽然数据不提供度量深度,但可以使用立体匹配来获得相对深度(类似于RW和WS)。(研究动机)作者的驱动动机是数据的规模和多样性。在精心控制的条件下,捕获3D电影提供了已知的最大的立体声对,这加大了从不断增长的内容库中获取数百万张高质量图像的可能性。作者注意到,3D电影已经被单独地在相关任务中使用。作者将通过将它们与其他互补的数据源相结合,来揭示它们的全部潜力。与自然环境中的类似数据收集相比,该数据源不需要手动对有问题的内容进行过滤。因此,数据集可以很容易地扩展或适应特定的需求(专注于人类舞蹈或自然纪录片)。
Challenges
电影数据自身充满挑战并不断完善。制作立体电影时的主要目标是提供视觉上愉快的观看体验,同时避免观众的不适。这意味着任何给定场景的视差范围(也称为深度预算)是有限的,并且取决于艺术和心理物理方面的考虑。 例如,通常在电影的开头和结尾增加视差范围,以在短时间内引起非常明显的立体效果。 中间的深度预算可能会更低,以便更舒适地观看。 因此,立体摄影师会根据场景的内容、过渡甚至节奏来调整他们的深度预算。
因此,立体声设备摄像机之间的焦距、基线和收敛角是未知的,即使在单个电影中,场景之间也有所不同。此外,与直接从标准立体声相机获得的图像对相比,电影中的立体声对通常包含正的和负的差异,以允许物体在屏幕前面或后面被感知。此外,与屏幕对应的深度是依赖于场景的,通常在后期制作中通过移动图像对进行修改。作者描述了解决这些挑战的数据提取和训练过程。
focal lengths
baseline
convergence angle
Movie selection and preprocessing
作者选择了23部不同电影。这个选择是基于以下考虑因素:
- 只选择了使用物理立体声摄像机拍摄的电影。(一些3D电影是用单眼相机拍摄的,艺术家在后期制作中添加了立体效果
- 试图平衡现实主义和多样性
- 只选择了蓝光格式的电影,因此允许提取高分辨率的图像
作者以1920x1080分辨率和24帧每秒(fps)提取立体图像对。电影有不同的长宽比,导致在帧的顶部和底部有黑条,而一些电影由于后期制作而沿着帧边界有薄薄的黑条。因此,作者将所有帧的中央裁剪到1880x800像素。作者使用阶段信息(蓝光元数据)将每部电影分割成单独的阶段。此外,删除了第一章和最后一章,因为它们通常包括介绍和字幕。
使用场景检测工具FFmpeg设置阈值为0.1提取单个片段。丢弃小于1秒的剪辑,以过滤掉混乱的动作场景和在对话中快速切换的高度相关的剪辑。为了平衡场景的多样性,对每个片段的前24帧进行采样,另外每4秒采样24帧,以进行更长的剪辑。由于多个帧是同一个剪辑的一部分,因此完整的数据集高度相关。因此,作者进一步对4fps的训练集和1fps的测试和验证集进行子采样。
scene detection tool of FFmpeg:参考文献53
Disparity extraction
提取的图像对可以用于估计立体匹配的视差图。不幸的是,最先进的立体声匹配器在应用于电影数据时表现不佳,因为匹配器的设计和训练只能在正视差范围内进行匹配。这一假设适用于标准立体声相机的校正输出,但不适用于从立体胶片中提取的图像对。此外,由于深度预算有限,3D 电影中遇到的视差范围通常小于标准立体设置中常见的范围。
为了缓解这些问题,作者将现代光流算法应用于立体声对,保留了流的水平分量作为差异的代理。光流算法可以自然地处理正差异和负差异,通常对中等大小的位移表现良好。对于每对立体声图像,作者使用左的相机作为参考,并从左到右的图像提取光流,反之亦然。作者执行左右一致性检查,并将视差差超过2像素的像素标记为无效。作者按照Wang等人的指导方针,自动过滤出质量差的帧:如果超过10%的像素有垂直视差>2像素,水平视差范围为<10像素,或通过左右一致性检查的像素百分比为<70%,则拒绝帧。在最后一步中,使用预先训练的语义分割模型检测属于天空区域的像素,并将它们的视差设置为图像中的最小视差。
选定电影的完整列表以及使用自动清洗管道过滤后保留的帧数如表2所示。请注意,由于不同的运行时间和不同的差异质量,每部电影提取的帧数量会出现差异。作者使用来自19部电影的帧进行训练,并分别留出两部电影进行验证和两部电影进行测试。来自结果数据集的示例帧如图2所示。
表2自动处理后三维电影数据集中的电影列表和提取帧数

图2.来自三维电影数据集的示例图像。展示了训练集中一些电影的图像以及它们的逆深度图。天空区域和无效的像素被掩蔽。每张图像都是从不同的胶片中拍摄的。3D电影提供了大量的不同的数据来源。

a proxy for disparity
a left-right consistency check
Training on Diverse Data
在不同的数据集上进行单眼深度估计的训练模型是一种挑战,因为真实地面有不同的形式(见表1)。它可以是绝对深度(来自基于激光的测量或具有已知校准的立体摄像机)、深度到未知尺度(来自SfM),或视差图(来自具有未知校准的立体摄像机)。一个合理的训练方案的主要要求是在一个适当的输出空间中进行计算,该空间与所有的真实地面表示兼容,并在数值上表现良好。作者还设计了一个足够灵活的损失函数,以处理各种数据源,同时最佳地利用所有可用的信息。
(研究难点)作者确定了三个主要的挑战。
- 深度的本质不同表示:直接深度表示和逆深度表示。
- 尺度模糊性:对于某些数据源,深度只被给予到一个未知的尺度。
- 位移的模糊性:一些数据集只提供未知的尺度和全局视差移动,这是未知基线的函数和由于后处理引起的主点的水平位移的功能。
Scale- and shift-invariant losses
作者提出在视差空间(逆深度到尺度和位移)中进行预测,以及一系列尺度和位移不变的密集损失,以处理上述歧义。999
inverse depth up to scale and shift:逆深度到比例和移动


Related losses functions
主要对比表明作者提出的损失的优势
- 损失被定义在视差空间中,它在数值上是稳定的,并与相对深度的共同表示相兼容。
- 作者提出的损失都考虑到了所有可用的数据。
- 作者的尺度和移位不变损失变量导致持续更好的性能。
Final loss
为了定义完全损失,作者将多尺度、尺度不变的梯度匹配项适应于视差空间。这个术语适用于具有尖锐的不连续性,并与地面真实值的不连续相一致。

Mixing strategies
虽然作者的预测空间的丢失和选择使混合数据集成为可能,但目前尚不清楚在使用随机优化算法进行训练时应该集成不同数据集的比例。在实验中探索了两种不同的策略。
第一种策略,简单的策略是在每个minibatch中相等地混合数据集。对于大小为B的minibatch,从每个数据集采样B/L训练样本,其中L表示不同数据集的数量。这种策略确保了所有的数据集在有效的训练集中被平均表示,而不管它们的个体大小如何。
第二个策略探索了一种更有原则的方法,其中采用了最近的Pareto-optima多任务学习程序来适应相关的设置。作者将在每个数据集上的学习定义为一个单独的任务,并在数据集上寻找一个近似的Pareto-optima值(如:一种解决方案,在任何训练集上都不能减少损失的解决方案)。在形式上,作者使用中[12]提出的算法来最小化多目标优化准则:
![]()
其中,模型参数θ跨数据集共享。
Pareto-optimal multi-task learning
Experiments
作者从 Xian 等人的实验设置开始[32] 并使用他们基于 ResNet 的多尺度架构进行单幅图像深度预测。作者使用预训练的 ImageNet权重初始化编码器并随机初始化其他层。作者使用 Adam,随机初始化层的学习率为 ,预训练层的学习率为
,并将指数衰减率设置为 β1 = 0.9 和 β2 = 0.999。 图像以 50% 的概率水平翻转,并随机裁剪并调整为 384 × 384 以增加数据并保持不同输入图像的纵横比, 没有使用其他增强。
随后,作者对损失函数进行了消融研究,由于作者推测ImageNet数据的预训练对性能和编码器架构也有显著影响。作者使用性能最好的预训练模型作为数据集混合实验的起点。使用一个8L的批次大小,即当混合三个数据集时,批处理大小为24。当比较不同大小的数据集时,术语epoch没有明确定义;因此,作者定义一个周期为处理72000张图像,大约是MD和MV的大小,并训练60个周期。作者将所有数据集的地面-真实视差平移和缩放到范围[0,1]。
Test datasets and metrics
对于损耗和编码器的消融研究,作者使用了作者保留的RW(360张图像)、MD(2963张图像-官方验证集)和MV(3058张图像-见表2)。对于所有的训练数据集混合实验和与最新技术的比较,作者在训练期间从未见过的数据集上进行了测试:DIW、ETH3D、Sintel、KITTI、NYU和TUM。
- 对于DIW,作者从DIW训练集中创建了10,000张图像的验证集,并与现有技术相比,使用了74,441张图像的官方测试集。
- 对于NYU,使用了官方的测试分割(654张图像)。
- 对于KITTI,使用官方验证集的交叉点进行深度估计(具有改进的地面真实深度[59])和特征测试分割[60](161张图像)。
- 对于ETH3D和Sintel,使用了具有地面真实度的整个数据集(分别为454张和1064张图像)。
- 对于TUM数据集,使用了以室内环境中的人类为特征的动态子集(1815张图像)。
对于每个数据集,作者使用一个单个metric来符合该数据集的基本度量。
- 对于DIW,使用加权人类分歧率(WHDR)[34]。
- 对于基于相对深度的数据集,测量了视差空间(MV、RW、MD)中的均方根误差。
- 对于提供精确绝对深度的数据集(ETH3D,Sintel),测量了深度空间(AbsRel)中相对误差
的平均值绝对值。
最后,使用的像素百分比来评估KITTI、NYU和TUM上的模型。遵循 [10],作者将在深度空间中评估的数据集的预测上限设置为适当的最大值。 对于 ETH3D、KITTI、NYU 和 TUM,深度上限设置为最大地面实况深度值(分别为 72、80、10 和 10 米)。 对于 Sintel,作者对真实深度低于 72 米的区域进行评估,因此使用 72 米的深度上限。 对于作者所有的模型和基线,在测量误差之前,将每个图像的预测和基本事实按比例和偏移对齐。 作者基于最小二乘准则在逆深度空间中执行对齐。 由于在对多个数据集进行评估时,绝对数字很快变得难以解释,因此与适当的基线方法相比,作者还展示了性能的相对变化。
Input resolution for evaluation
作者调整测试图像的大小,使较大的轴等于384像素,而较小的轴被调整为32像素的倍数(由编码器施加的约束),同时保持高宽比尽可能接近原始长宽比。由于KITTI的宽,这种策略将导致非常小的输入图像。因此,作者将该数据集上较小轴的大小调整为等于384像素,并采用相同的策略来保持长宽比。
作者比较的大多数最先进的方法都是专门针对特定的数据集(具有固定的图像维度),因此没有指定在推理过程中如何处理不同的图像大小和长宽比。作者试图找到所有方法的最佳性能设置,遵循它们的评估脚本和训练维度。对于在正方形斑块上训练的方法,作者遵循作者的设置,将较大的轴设置为训练图像轴的长度,并调整较小的轴,保持长宽比尽可能接近原始值。对于具有非正方形斑块的方法,将较小的轴固定在较小的训练图像轴维数上。对于DORN,遵循他们的tiling协议,分别将图像的大小调整为其NYU和KITTI评估所指定的尺寸。对于单深度2和结构2深度,都在KITTI训练,因此期望一个非常宽的高宽比,作者使用反射填充填充输入图像,以获得相同的宽比,调整到它们的特定输入尺寸,并将得到的预测裁剪到原始目标尺寸。对于模型权重可用于不同训练分辨率的方法,评估了所有这些方法,并报告了性能最佳的变体的编号。
所有的预测都被重新调整到地面真实值的解决方案中,以进行评估。
Comparison of loss functions
在图 3 中展示了不同损失函数对验证性能的影响。使用 RW 来训练具有不同损失的网络。 对于序数损失(参见等式 (9)),随机抽取 5,000 个点对。 在适当的情况下,将损失与梯度正则化项(11)结合起来。 还通过在(1)中固定 t=0 来测试视差空间 Lsimse 中的尺度不变但不是平移不变的 MSE。 使用 Lord 训练的模型对应于 Xian 等人的重新实现。图 3 显示作者提出的修剪后的 MAE 损失在所有数据集上产生最低的验证错误。 因此,作者使用 Lssitrim + Lreg 进行接下来的所有实验。
图3.不同的损失函数的相对性能(较高的性能更好),以性能最佳的损失Lssitrim+Lreg作为参考。我们提出的四项损失(白色区域)都优于目前最先进的损失(灰色区域)。

Comparison of encoders
在图4中评估了编码器架构的影响。作者使用Xian等人最初使用的ResNet-50编码器来定义该模型作为的基线,并显示在不同编码器交换时性能相对改善(越高越高更好)。作者测试了ResNet-101、ResNeXt-101和DenseNet-161。所有的编码器都在ImageNet上进行了预训练。对于ResNeXt-101,作者还使用了一个variant,该variant在ImageNet训练之前使用大量弱监督数据语料库(WSL)进行了预训练。所有的模型都在RW上进行了微调。
variant
图4.不同编码器的相对性能(较高越好)。一个编码器的图像网的性能可以预测其在单眼深度估计中的性能。
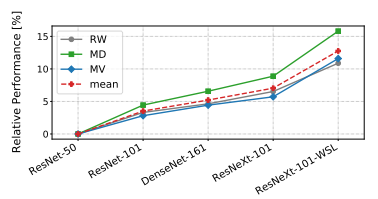
实验观察到,通过使用更好的编码器,可以实现显著的性能提高。更高容量的编码器的性能优于基线。在弱监督数据上预训练的ResNeXt-101编码器比仅在ImageNet上训练的编码器性能要好得多。实验发现预训练至关重要。具有随机初始化的ResNet-50编码器的网络的性能平均比预先训练的对应网络差35%。一般来说,编码器的ImageNet性能是其单眼深度估计性能的强预测器。这是令人鼓舞的,因为在图像分类方面的进步可以直接产生稳健的单眼深度估计的收益。超过基线的性能提高是显著的:高达15%的相对改善,没有任何特定于任务的适应。作者在所有后续实验中都使用ResNeXt-101-WSL。
Training on diverse datasets.
在表3和表4中评估了不同训练数据集对泛化的有效性。虽然更专门的数据集在类似的测试集(室内场景DL或ETH3DMD)上达到更好的性能,但其余数据集的性能下降。有趣的是,单独使用的每一个数据集平均都比使用小但经过策划的RW数据集导致更差的泛化性能。在兼容数据集上的增益平均被在其他数据集上的减少所抵消。
表3在不同的单个训练集上进行微调(较高更好)时,基线的相对性能为百分比。绿色比优于基线,红色比性能差。最佳表现是大胆的,第二好是下划线。RW基线的绝对误差显示在上一行。虽然一些数据集在单个、相似的数据集上提供了更好的性能,但零镜头跨数据集传输的平均性能会下降。
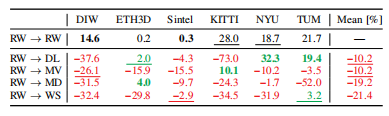
表4当在不同的单个训练集上进行微调时,绝对性能更好。此表对应于表3。
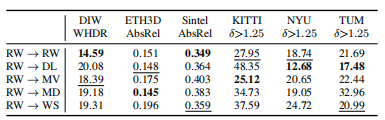
RW、MV和WS的性能差异特别有趣,因为它们具有相似的特性。虽然明显大于RW,但MV和WS都表现出较差的个体表现。这可以部分用冗余的数据来解释,因为这些数据集的视频性质,以及RW中可能更严格的过滤(专家人为的去除了有明显缺陷的样本)。通过比较WS和MV,发现MV导致了更一般的模型,可能是因为由于图像更可控,导致了更高质量的立体声对。
在随后的混合实验中,作者使用表3作为参考,即从性能最好的单个训练数据集开始,并连续添加到混合中。在表5中显示了哪些数据集包含在单个训练集中。为了更好地理解电影数据集的影响,还显示了在除电影(Moves,MIX4)外的所有数据集上训练的结果。作者总是从预先训练过的RW开始训练基线。
表5用于训练的数据集的组合
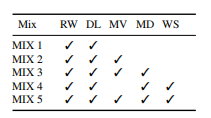
表6和表7显示,与使用单个数据集相比,混合多个训练集始终相对于基线提高性能。然而,实验也看到,当使用朴素混合时,添加数据集并不能无条件地提高性能(see MIX 1 vs. MIX 2)。表8和表9报告了一个使用Pareto-optimal最优数据集混合的类似实验的结果。可以观察到,这种方法优于朴素的混合策略。它还能够更一致地利用其他数据集。将所有五个数据集与Pareto-optimal最优混合相结合,可以得到性能最好的模型。在图5中显示了对结果模型的定性比较。
表6朴素数据集混合相对于RW基线(上行)的相对性能-较高更好。虽然我们在添加数据集时通常会看到一个改进,但添加数据集可能会损害朴素混合的泛化性能。
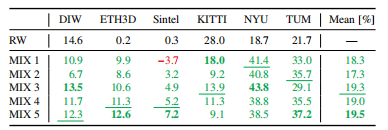
表7朴素数据集混合的绝对性能更好。此表对应于表6。
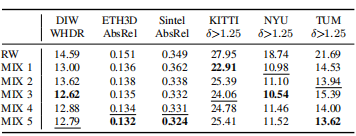
表8混合了多目标优化的数据集相对于RW基线(上行)的相对性能-较高越好。原则混合主导了通过朴素混合发现的解决方案。
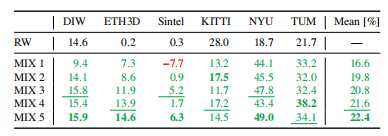
表9多目标优化数据集混合的绝对性能更好。此表对应于表8。
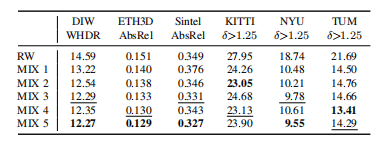
图5.比较使用Pareto-optimal mixing在不同数据集组合上训练的模型,图片来自微软COCO。

Comparison to the state of the art.
作者将自己表现最好的模型与表10和表11中各种最先进的方法进行了比较。每个表的顶部部分与没有在任何一个评估的数据集中进行微调的基线进行比较(i.e.零镜头转移,类似于本文的模型)。底部显示了在数据集子集上微调的基线以供参考。在训练集栏中,MC指的人体模型挑战和CS到城市景观。A→B表示对A的预训练和对B的微调。
表10最先进的方法相对于本文的最佳模型(上排)的相对性能-更高更好。顶部:没有在任何数据集上进行微调的模型。底部:在被测试数据集的一个子集上进行了微调的模型。
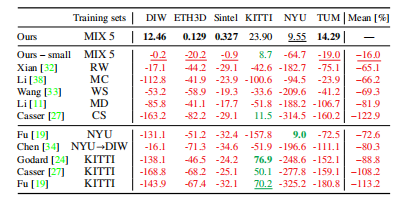
表11现有方法的绝对性能,按平均排名排序。此表对应于表10。

本文的模型在zero-shot性能方面明显优于基线。请注意,本文的模型优于Li等人的the Mannequin Challenge model。Li等人专门策划的TUM数据集的[38],来展示他们的模型的优势。作者在自身的模型的一个变体上显示了额外的结果,它有一个基于ResNet-50的较小的编码器(Ours – small)。该体系结构相当于Xian等人提出的网络。较小的模型也远远优于现有技术。这表明,作者的模型的强性能不仅是由于网络容量的增加,而且从根本上是由于所提出的训练方案。
the Mannequin Challenge model:
一些为一个特定数据集训练的模型t(e.g.KITTI或NYU在表格的下方)。在这些单个数据集上表现非常好,但在所有其他测试集上表现明显更差。对单个数据集的微调会导致对特定环境的强先验。这在某些应用程序中可能是可取的,但如果模型需要泛化,则不适合。本文的模型与四个表现最好的竞争对手的定性比较如图6所示。
图6.本文的方法与来自微软COCO数据集的图像上的四个最佳竞争对手的定性比较

Additional qualitative results.
图7显示了DIW测试集上的其他定性结果。作者展示了一组不同的输入图像的结果,包括人类、哺乳动物、鸟类、汽车和其他人造和自然物体。图像的特点是室内,街道和自然场景,不同的照明条件,和不同的相机角度。此外,主题区域从特写镜头到远程镜头不等。
图7.在DIW测试集上的定性结果。

在补充视频https://youtu.be/D46FzVyL9I8.中显示了DAVIS视频数据集[64]的定性结果请注意,每一帧都是单独处理的,即没有以任何方式使用任何时间信息。对于每个剪辑,逆深度地图被联合缩放和移动以进行可视化。该数据集由一组不同的视频组成,包括人类、动物和汽车。该数据集是用单眼摄像机拍摄的,因此没有地面真实的深度信息。
Hertzmann最近观察到,作者的公开供应即使是在抽象的线条图上,模型也提供了合理的结果。类似地,在图8中显示了具有不同抽象层次的绘画和绘画的结果。由此可以定性地证实[65]中的发现:该模型显示了即使在相对抽象的输入上的惊人能力来估计合理的相对深度。这似乎是真实的,只要一些(粗糙的)深度线索,如阴影或消失的点出现在艺术作品中。
图8.对绘画和绘画的结果。最上面排:A Friend in Need, Cassius Marcellus Coolidge, and Bathers at Asni´eres, Georges Pierre Seurat. 最底层:Mittagsrast, Vincent van Gogh, and Vector drawing of central street of old european town, Vilnius

Failure cases
作者确定了本文的模型的常见故障案例和偏差。图像有一个自然的偏差,即图像的较低的部分比较高的图像区域更接近相机。当随机抽取两点,并将较低的点分类为更接近摄像机时,与human annotators的一致率为85.8%。这种偏差也被本文的网络学习到,在图9第一行所示的一些极端情况下可以观察到。在左边的例子中,模型无法恢复地平面,这可能是因为输入的图像旋转了90度。在右边的图像中,与相机大约相同距离的球被重建更接近图像的下部。这种情况可以通过增加具有旋转图像的训练数据来预防。然而,目前尚不清楚图像旋转的不变性是否是该任务的期望属性。
图9.故障情况。相对深度排列中的细微故障或缺失的细节以绿色突出显示。

human annotators
图9的第二行显示了另一个有趣的故障案例。绘画、照片和镜子往往不能被识别出来。该网络根据反射器上描述的内容来估计深度,而不是预测反射器本身的深度。
其他的故障案例显示在其余的行中。强烈的边缘会导致幻觉的深度不连续。在某些情况下,可能会遗漏薄结构,断开连接的对象之间的相对深度排列可能会失败。结果在背景区域的情况往往会模糊,这可能是由于输入图像的分辨率有限和远距离的地面真实值不完善。
Conclusion
深度网络的成功是由大量的数据集驱动的。对于单眼深度估计,作者认为现有的数据集仍然不够,很可能构成限制因素。
- 由于大规模捕获不同深度数据集较为困难,作者引入了结合互补数据源的工具。
- 提出了一种灵活的损失函数和一种原则性的数据集混合策略。
- 进一步引入了一个基于3D电影的数据集,它为不同的动态场景提供了密集的地面真实值。
通过零镜头跨数据集传输,评估了模型的鲁棒性和通用性。作者发现,系统测试模型在(训练未使用的)数据集上进行测试时在“自然环境下”的表现甚至比在目前可用的最多样化的数据集的进行部分测试的测试拥有更好的性能。
作者的工作奠定了通用单眼深度估计的最先进水平,并表明所提出的想法大大提高了在不同环境中的性能。同时希望这项工作将有助于部署满足实际应用要求的单眼深度模型。















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









