







Gradient modulated contrastive distillation of low-rank multi-modal knowledge for disease diagnosis
Authors: Xiaohan Xing, Zhen Chen, Yuenan Hou, Yixuan Yuan
Source: Medical Image Analysis 88 (2023) 102874
Keywords: Multi-modal learning, Low-rank decomposition, Knowledge distillation, Glioma grading Skin lesion classification

关键术语:
- Gradient modulated - 梯度调制,是一种在训练神经网络时动态调整梯度的技术,以提高模型性能。
- Contrastive distillation - 对比蒸馏,是一种将知识从教师模型转移到学生模型的方法,通过最大化正样本对之间的相似性和最小化负样本对之间的相似性来实现。
- Low-rank - 低秩,指的是在矩阵或张量中,大部分信息都可以用少数几个基向量来表示,这样可以减少计算复杂度和内存消耗。
- Multi-modal - 多模态,是指融合来自不同来源或形式的数据,以获得更全面、准确的信息。
Abstract
多模态数据(例如医学图像和基因组图谱)的融合可以提供补充信息并进一步有益于疾病诊断。然而,多模态疾病诊断面临两个挑战:(1)如何通过利用互补信息来产生判别性的多模态表示,同时避免来自不同模态的嘈杂特征。(2)在实际临床场景中只有一种模式的情况下,如何获得准确的诊断。为了解决这两个问题,提出了一个两阶段的疾病诊断框架。在第一个多模态学习阶段,提出了一种新的动量丰富多模态低秩(M3LR)约束,以探索不同模态之间的高阶相关性和互补信息,从而产生更准确的多模态诊断。在第二阶段,通过提出的差异监督对比蒸馏 (DSCD) 和梯度引导知识调制 (GKM) 模块,将多模态教师的特权知识转移给单模态学生,这有利于基于单模态的诊断。在两项任务上验证了方法:(i) 基于病理切片和基因组数据的神经胶质瘤分级,以及 (ii) 基于皮肤镜检查和临床图像的皮肤病变分类。这两项任务的实验结果表明,提出的方法在多模态和单模态诊断方面都优于现有方法。
本文提出了一个两阶段疾病诊断框架,以促进多模式和单模式诊断。在第一阶段,提出了一种新的动量富集多模态低秩(M3LR)约束,以探索融合模态和动量编码器的高阶互补信息,从而实现更准确的多模态诊断。与现有的低秩约束不同,M3LR 利用融合模态作为中介来弥合模态差距,并利用动量编码器提供更丰富的互补信息。在第二阶段,提出了一个差异监督对比蒸馏(DSCD)模块和梯度引导知识调制(GKM)方案,以将多模态知识转移到更准确的单模态诊断中。具体来说,DSCD 模块通过从师生模型的差异中提取多个正对(来自同一类),同时将来自不同类是负对分开来提炼丰富的结构知识。与现有的对比KD相比,DSCD模块中的多个正对有助于通过正确的类语义传递更多的信息结构知识。GKM构建了一个综合知识库,其中包含来自多模态教师模型和单模态均值教师模型的多种知识,并根据它们在梯度空间中的一致性自适应地调节多种知识。这样,为单模态学生模型提供了更可靠、更全面的指导。
本文的贡献如下:
• 提出了一个两阶段疾病诊断框架,首先训练多模态网络,然后提炼多模态知识来训练单模态网络。
• 在多模态训练阶段,提出了一种新的M3LR约束,以捕获不同模态和动量编码器之间的共识和高阶互补信息。
• 在单模态训练阶段,提出了一个 DSCD 模块来提炼类和差异引导的对比知识,以及一个 GKM 方案来自适应地整合多种知识的优点。
• 对胶质瘤分级和皮肤病变分类任务的广泛实验表明,所提出的方法在多模式和单模式诊断方面都优于现有方法。
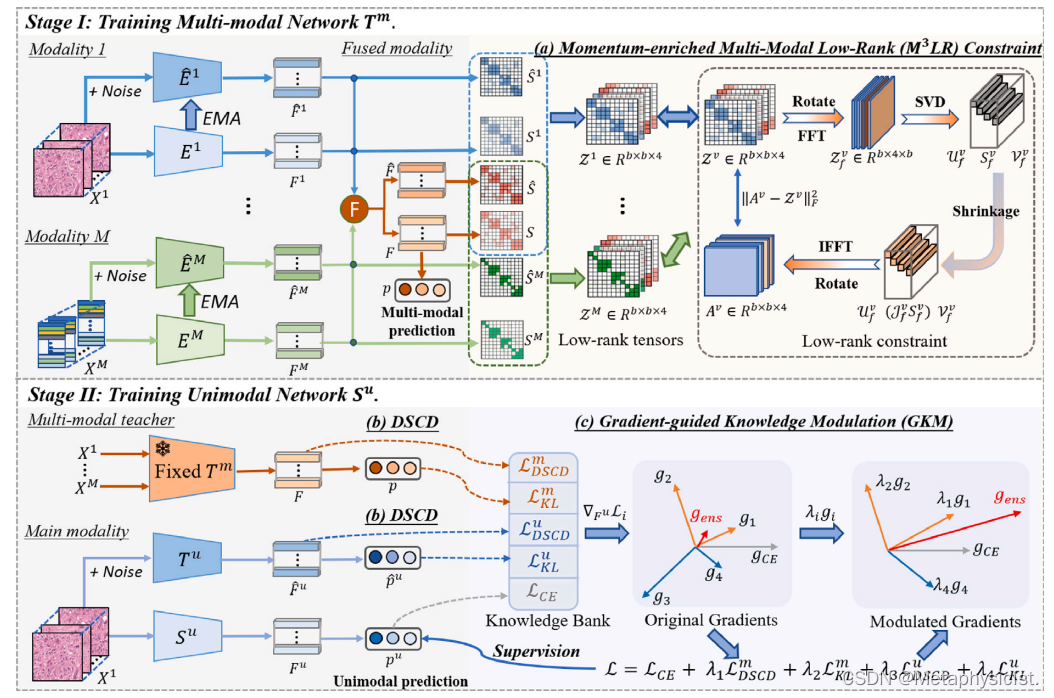
图 1.拟议的两阶段疾病诊断框架概述。在第一阶段,使用(a)动量富集多模态低秩(M3LR)约束对多模态网络T m进行训练,旨在改进多模态诊断。在第二阶段,通过提出的(b)差异监督对比蒸馏(DSCD)和(c)梯度引导知识调制(GKM)模块,将T m中的多模态知识转移到单峰网络S u,这有效地提高了基于单峰的诊断。
将训练数据表示为 {X1 , ..., XM , y},包括来自 M 模态的输入数据,并与诊断标签 y 配对。在第一阶段,从M个模态中提取的特征{F 1,...,F M}通过Kronecker积融合以产生多模态特征F。对于每种模态,动量编码器通过编码器的指数移动平均线 (EMA) 进行更新,产生 (M + 1) 动量丰富的特征 {F̂ 1 , ..., F̂M , F̂}。除了对地面实况标签y的监督外,每个单独的模态还受到所提出的Momentumenriched Multi-Modal Low-Rank(M3LR)约束的监督。M3LR 约束有助于利用跨模态互补信息,同时减轻模态特定的噪声,从而实现更准确的多模态诊断。在第二阶段,通过从训练有素的多模态网络 T m 中提炼特权知识来训练单模态网络 S u。通过提出的差异监督对比蒸馏(DSCD,图1(b))和梯度引导知识调制(GKM,图1(c))模块,可以从多模态教师T m和单模态平均教师T u中提炼出更可靠和全面的知识,从而在推理过程中仅有单一模态可用时改进诊断。
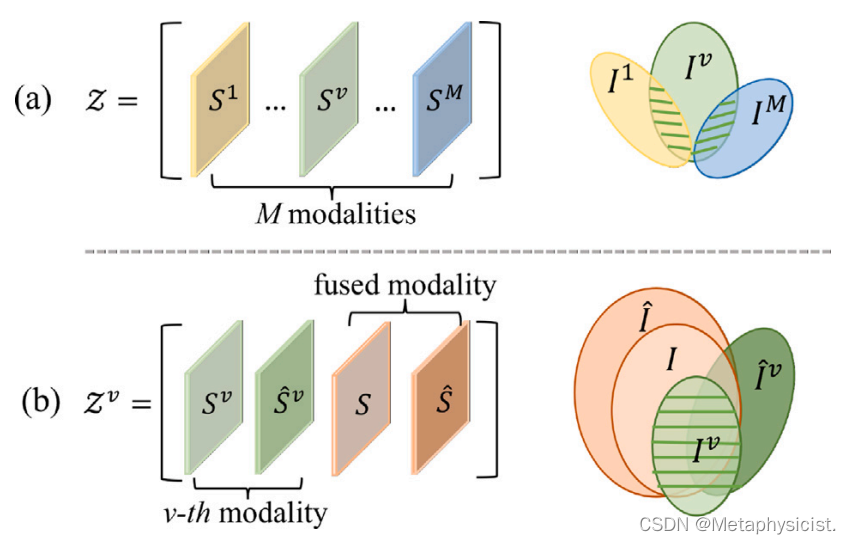
图 2.(a)现有方法(Xie et al., 2018)和(b)提出的M3LR约束的低秩张量(左)和信息图(右)。跨模态共识信息用条纹表示。
这一部分介绍了一种新的多模态低秩约束方法,称为动量丰富的多模态低秩(M3LR)约束。与现有方法直接在不同模态间施加低秩约束不同,M3LR约束为每个模态单独构建一个低秩张量。对于第v个模态,低秩张量由4个视图组成,即来自第v个模态编码器和动量编码器的相似度矩阵(𝑆𝑣和𝑆̂𝑣)以及融合模态的相似度矩阵(𝑆和𝑆̂)。与单个模态相比,融合模态与第v个模态共享更多的共识信息,并提供更丰富的互补信息。此外,第v个模态和融合模态的动量编码器中包含丰富的信息(𝐼̂𝑣和𝐼̂)。
对于第v个模态的小批量特征𝐹𝑣∈𝑅𝑏×𝑑,相似度矩阵𝑆𝑣计算如下:
其中⋅表示内积,𝑓𝑣𝑖和𝑓𝑣𝑗分别是第i个和第j个样本的特征。第v个模态的动量丰富多模张量构造为:
其中b表示每个小批量中的样本数。通过约束𝒵𝑣为低秩张量,可以增强这4个视图(即𝑆𝑣,𝑆̂𝑣,𝑆,𝑆̂)之间的共识信息,同时抑制模态特定的噪声。
在傅里叶域中对张量𝒵𝑣施加低秩约束。首先将张量𝒵𝑣旋转得到𝒵𝑅𝑜𝑡𝑣∈𝑅𝑏×4×𝑏,然后沿𝒵𝑅𝑜𝑡𝑣的第三维进行快速傅里叶变换(FFT)得到𝒵𝑓𝑣∈𝑅𝑏×4×𝑏。由于旋转操作,𝒵𝑅𝑜𝑡𝑣或𝒵𝑓𝑣的每个前切片都包含来自动量编码器和不同模态的信息,因此在每个前切片上施加低秩约束,以促进不同模态之间动量丰富的互补信息的探索和传播。
张量的秩可以表示为张量核范数(TNN),定义为所有前切片𝒵𝑓𝑣,𝑘的奇异值之和:
因此,通过降低‖𝒵𝑣‖𝑇𝑁𝑁可以实现对𝒵𝑣的低秩约束。具体地,引入一个辅助变量𝒴𝑣来替换𝒵𝑣,并定义M3LR损失为:
其中第一项对每个模态的张量𝒴𝑣施加低秩约束,第二项调节编码器(𝑝𝑣)和动量编码器(𝑝̂𝑣)预测之间的KL散度。通过SVD收缩操作更新𝒴𝑓𝑣的每个前切片𝒴𝑓𝑣,𝑘:
其中奇异值收缩算子𝒴̄𝑓𝑣,𝑘是一个对角矩阵。
通过这种方式,可以保证𝒵𝑣的低秩性质。因此,由于充分利用了来自融合模态和动量编码器的共识和互补信息,同时抑制了模态特定的噪声,因此可以获得更准确的多模态诊断。

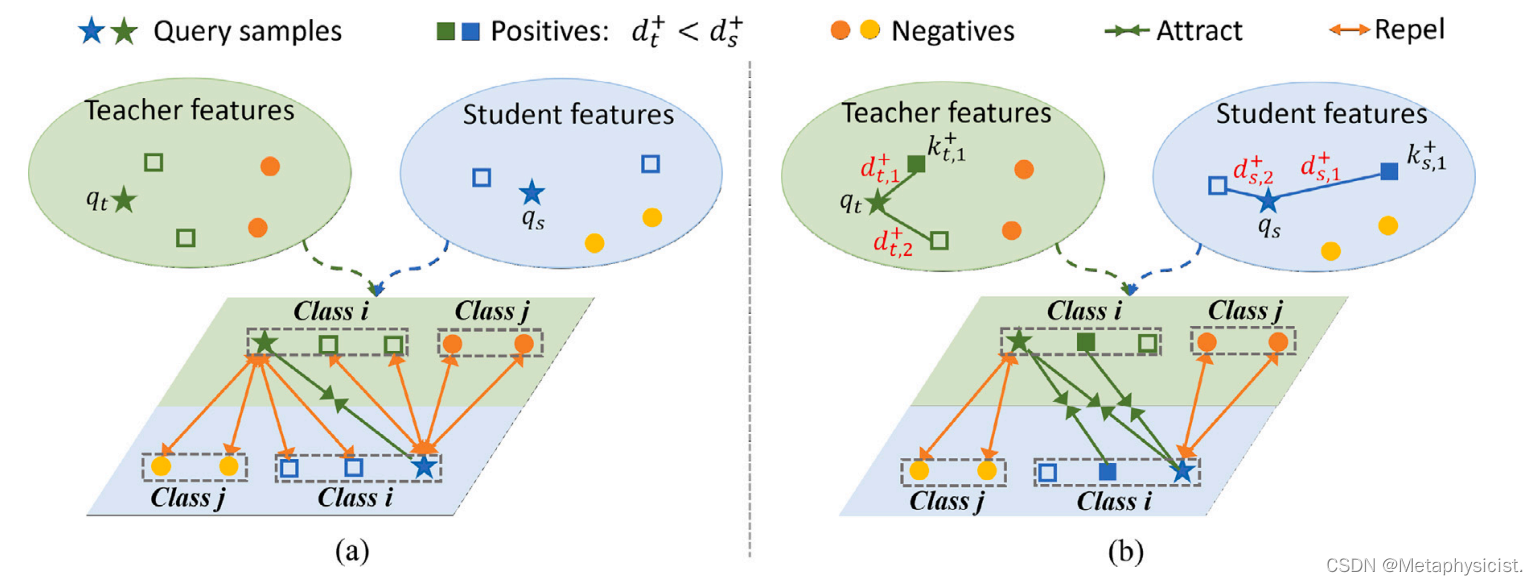
图 3.(a)现有的对比KD的说明,它将每个查询样本的单个正数与由所有其他样本组成的一组负数进行对比;(b)提出的差异监督对比蒸馏(DSCD)模块,该模块将从同一类别中选择的kP信息正数与来自不同类别的kN负数对进行对比。
本文还提出了一种新的知识蒸馏方法,称为差异监督对比蒸馏(Discrepancy Supervised Contrastive Distillation, DSCD)。为了解决单模态诊断的问题,作者提出在第二阶段通过从训练好的多模态教师模型中蒸馏特权知识来训练单模态网络。与现有的对比蒸馏方法不同,DSCD模块基于类别标签和教师-学生差异来选择对比样本。具体而言,它从同一类中选择个信息量大的样本作为正样本对,拉近它们的表示,同时从不同类中选择
个样本作为负样本对,推开它们的表示。正样本对的信息量
定义为:
其中表示余弦距离:
DSCD损失函数定义为:
其中是控制集中度的温度参数。与现有的对比蒸馏方法相比,DSCD引入了类别指导,并根据教师-学生差异探索了信息量大的正样本,使多模态教师能够为单模态学生传递更多具有正确类别语义的信息知识。
这段内容介绍了一种梯度引导的知识调制(Gradient-guided Knowledge Modulation, GKM)方案,用于为学生模型提供更可靠和全面的指导。作者构建了一个知识库 ,包括由真实标签监督的知识($\mathcal{L}_{CE}$)、来自多模态教师的特权知识(
)和来自单模态平均教师的回顾知识(
)。
作者假设可靠的知识更可能在梯度空间中与其他知识具有相似的梯度,而不可靠知识的梯度通常是矛盾的。因此,他们根据每个知识与其他知识在梯度空间中的一致性来衡量其可靠性。具体地,他们计算每个知识的梯度,得到梯度空间,其中
表示单模态学生模型提取的特征向量。
对于第个训练步骤,第
个知识的权重
由前一步的聚合权重和当前步的可靠性决定:
其中系数控制聚合损失权重
和当前步骤的梯度关系
的影响,后者计算如下:
如果两个知识在梯度空间中的余弦相似度 大于阈值
则它们之间的关系
设置为1,否则设置为0。通过这种方式,与其他知识一致性更高的知识会被分配更大的
。相反,由于与其他知识矛盾,不可靠的知识会被分配更小的
。单模态学生的总训练损失为:
通过调制多个知识的权重,它们对学生训练的贡献根据其可靠性进行重新校准。在调制后,来自可靠知识的梯度被增强,而不可靠知识的梯度
被减弱,从而得到更可靠的梯度
,有利于学生学习和收敛。
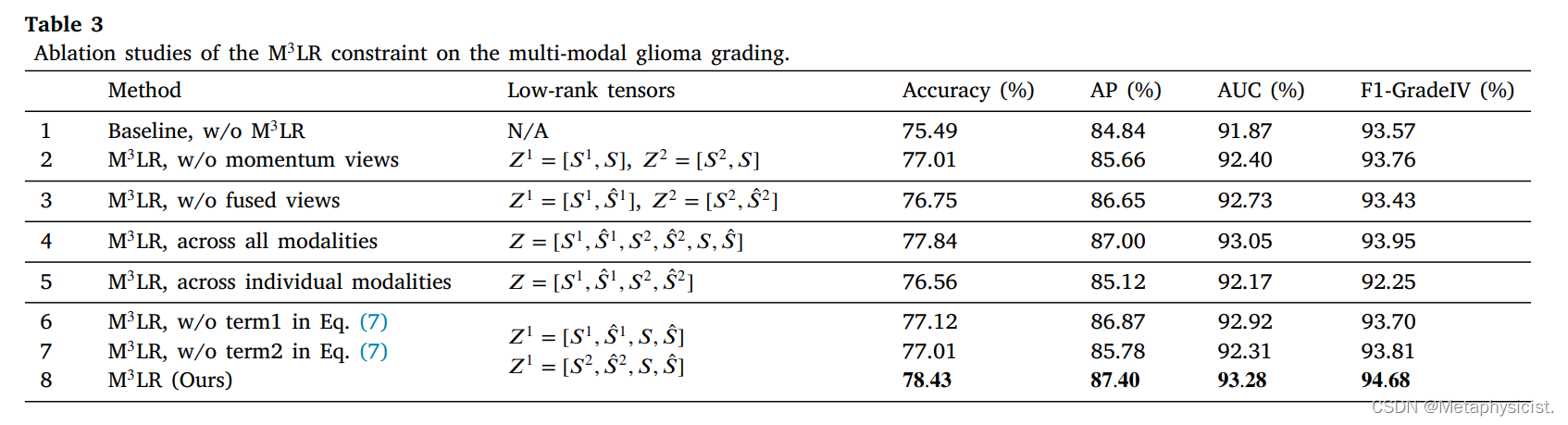
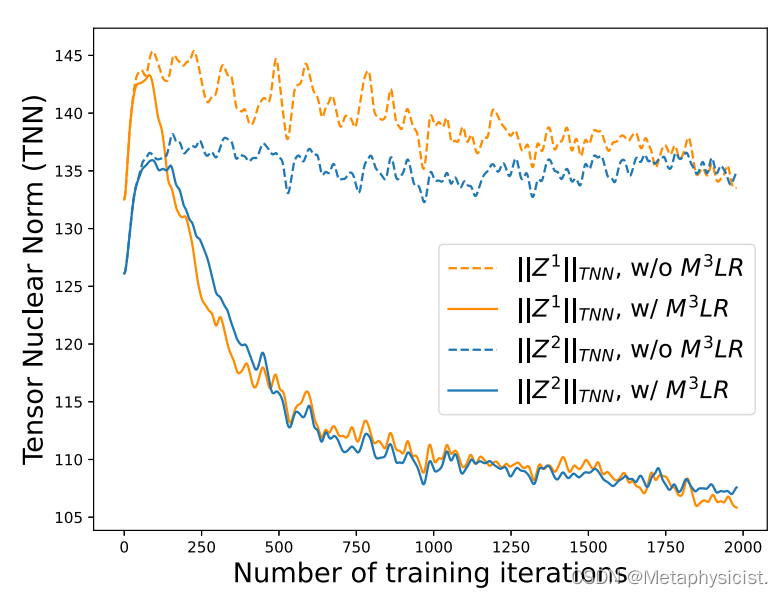
图 4.对于多模态胶质瘤分级任务,Z1 的张量核范数 (TNN) 用于病理学模式,Z2 用于基因组模式。TNN 越小,表示张量秩越低。
图 5.不同低秩约束对融合模式和个体模式(病理学和基因组学)的神经胶质瘤分级准确性的影响。
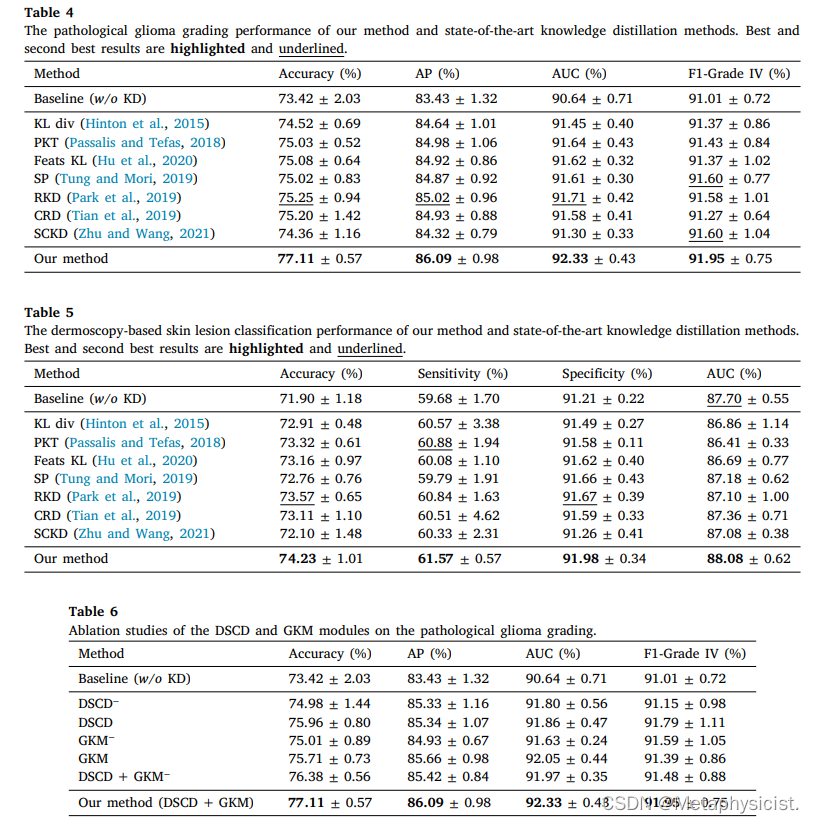

图 6.(a) 基线 (w/o KD)、(b) KL div (Hinton 等人,2015 年)、(c) RKD (Park 等人,2019 年)、(d) CRD (Tian 等人,2019 年)、(e) 方法和 (f) 基本事实的小批量样本(批次大小 = 256)之间的关系矩阵。输入样本沿每个轴按真值类别分组。沿对角线的块状图案表明来自同一类的样本是相似的。本方法生成的关系矩阵与基本事实更加一致,表明不同类别之间的区分更好。
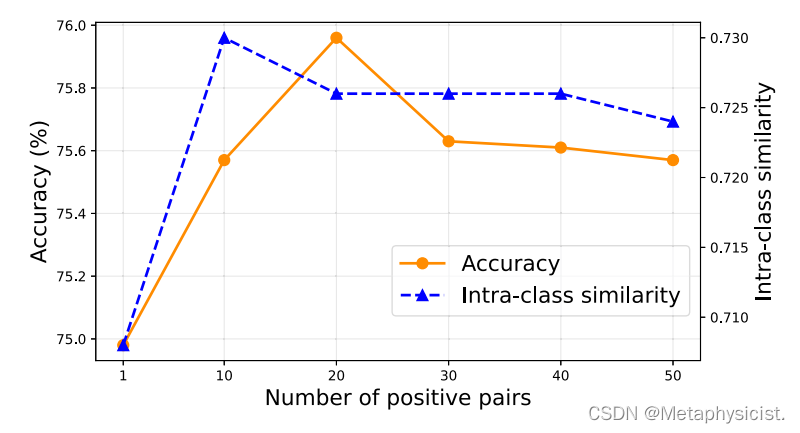
图 7.神经胶质瘤分级精度和类内相似性与DSCD模块中选择的不同正对数(kP)。
多模态诊断的实验结果:
-
在GBMLGG数据集上,作者提出的方法在准确率、AP、AUC和F1-Grade IV等评价指标上都取得了最佳表现,分别达到了78.43%、87.40%、93.28%和94.68%。与其他多模态融合方法相比,作者的方法优势明显,证明了M3LR约束在探索跨模态高阶互补信息和减轻模态特定噪声方面的贡献。
-
在皮肤病变数据集上,与其他最新的多模态融合方法相比,作者的方法同样取得了最佳性能,准确率为76.56%,敏感性为59.54%,特异性为92.05%,AUC为90.31%。这进一步验证了作者提出方法的优势,尤其是在模态间互补信息有限的情况下。
-
消融实验验证了M3LR约束的有效性。在GBMLGG数据集上,与基线相比,使用M3LR约束后,准确率提高了2.94%,AP提高了2.56%,AUC提高了1.41%,F1-GradeIV提高了1.11%。进一步的分析表明,M3LR约束不仅提高了融合模态的性能,也提高了单个模态(病理和基因组)的性能。
单模态诊断的实验结果:
-
在GBMLGG数据集上,仅使用病理切片作为输入,使用不同知识蒸馏方法训练的单模态网络都优于基线模型,表明多模态的特权知识有助于单模态诊断。作者提出的方法取得了最佳性能,准确率为77.11%,AUC为92.33%。作者方法的优势归因于DSCD模块蒸馏的丰富结构知识以及GKM方案调制的综合知识。
-
在皮肤病变数据集上,使用皮肤镜模态进行诊断,与基线模型相比,现有的知识蒸馏方法带来的性能提升有限。而作者的方法通过充分利用多模态教师和单模态平均教师的可靠结构知识,取得了最佳性能,准确率为74.23%,AUC为88.08%。
-
消融实验评估了DSCD和GKM模块的贡献。结果表明,单独使用DSCD模块将分级准确率提高到75.96%,显著优于基线模型。进一步分析发现,与单一正样本对相比,DSCD模块中的多个正样本对不仅提高了准确率,还提高了类内相似性。GKM模块也将分级准确率提高到75.71%。消融实验证明,GKM模块中的权重调制对学生从多个教师吸收有益知识并屏蔽误导信息至关重要。
Reference
[1] Xing, X., Chen, Z., Hou, Y., & Yuan, Y. (2023). Gradient modulated contrastive distillation of low-rank multi-modal knowledge for disease diagnosis. Medical Image Analysis, 88, 102874.















 1334
1334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











