







RNN网络架构解读
递归神经网络实际上就是普通的神经网络的部分进行修改更新:实际上常用于时间序列的更新。或者就是自然处理中
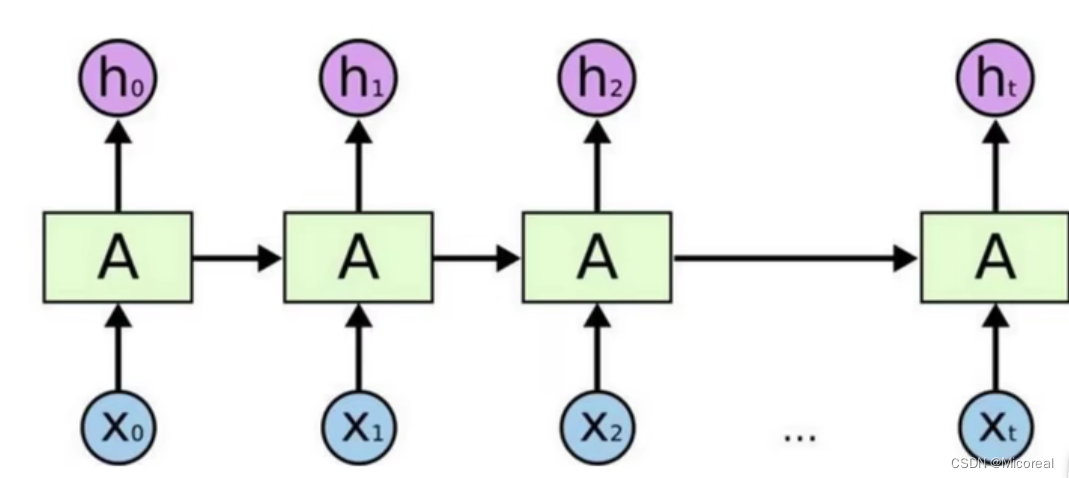
X序列代表着时间序列,x0是一个时间点,x1是下一个时间点。h就是中间输出的结果值,但是h又会输入到下一个时间点当中去运算。
-LSTM网络
是在Rnn网络的基础上进行改进的,加上一个C控制单元,用来控制当前模型的模型复杂度。
词向量模型
词向量模型实际上就是设置一个50维度-300维度的向量集,将相似的词安排到比较接近的向量分配当中,达到可以通过向量来反映出词,并且词义较为接近的词,所处在的向量空间,也较为接近。
举个构造的词向量模型:(50个特征)

模型整体框架
通常的情况下,向量的维度越高,能提供的信息也就越多,从而计算结果的可靠性也就越大。
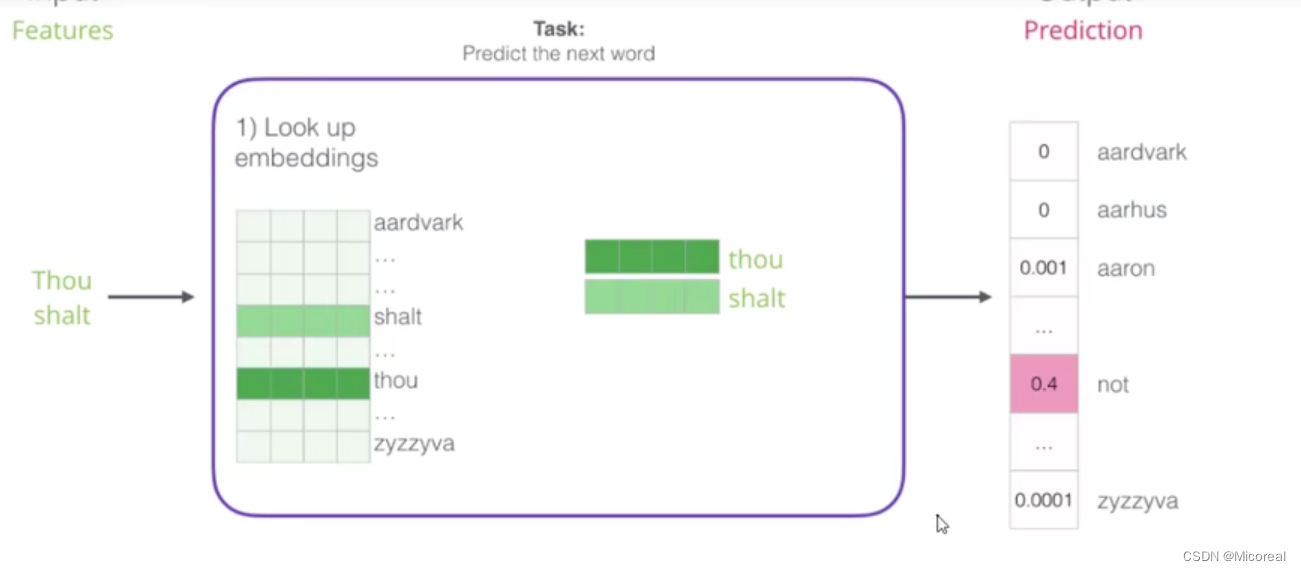
具体的框架见下,实际上就是我输入thou shalt之后对于我接下来准备输入的数据的预测。中间的黑盒子,使用的也就基本与神经网络方法是差不多的,先前向传播,得到loss之后再反向传播进行修改相对应的w。
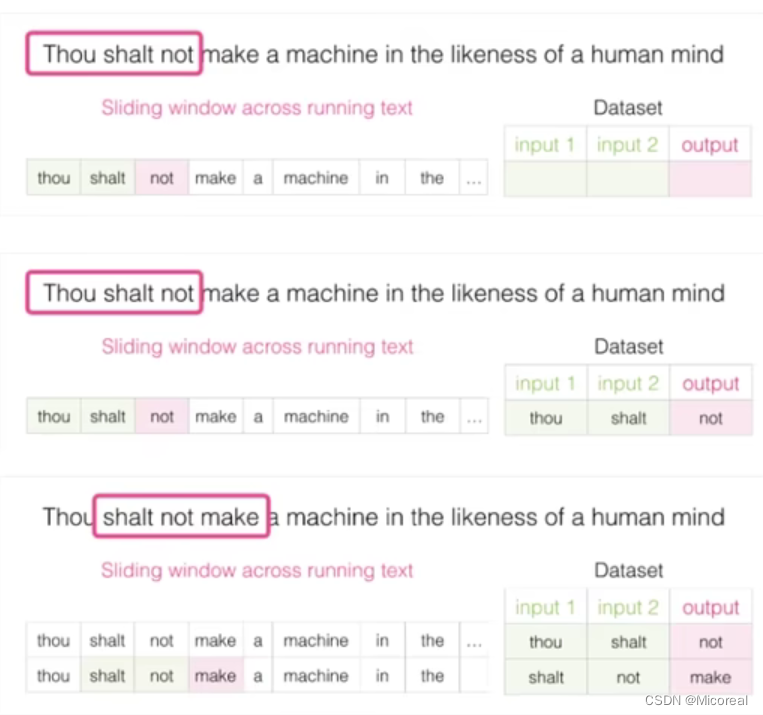
训练数据构建
构造训练数据的过程其实也非常简单,实际上也就是和之前的滑动窗口的方式差不多。
CBOW和Skip-gram模型
有了训练数据之后就可以开始挑训练模型了:
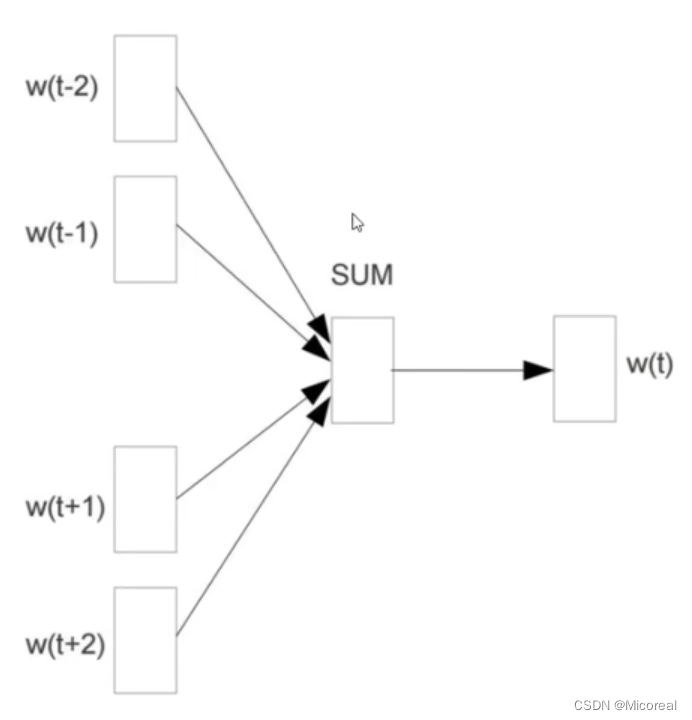
CBOW模型:

CBOW的训练是取要填入之地的前两个单词以及后两个单词作为输入,然后通过神经网络判断得出最有可能的输出值作为输出。
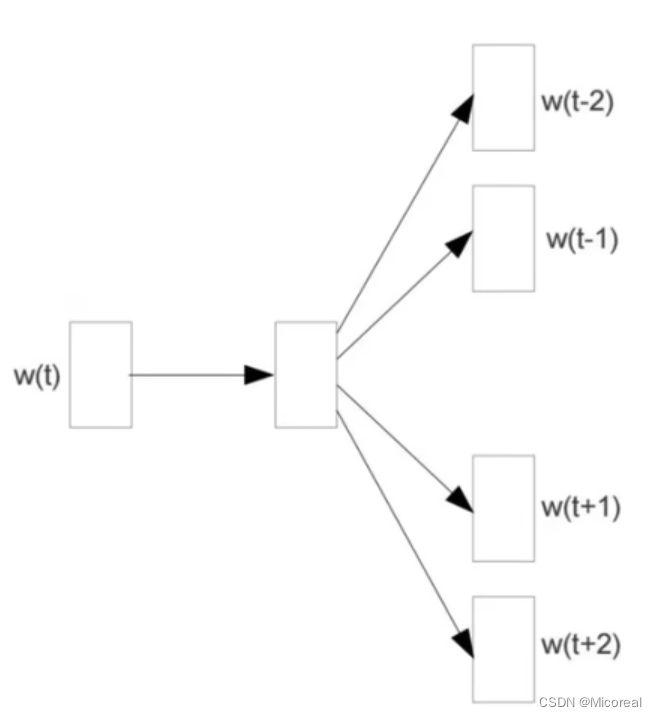
Skip-gram模型:
与CBOW模型相反
负采样方案
解决由于语言库太大,最后一层softmax计算起来就会十分耗时。
方式解决就是:变成同时输入not thou 进行判断thou是not后面的概率为多少。
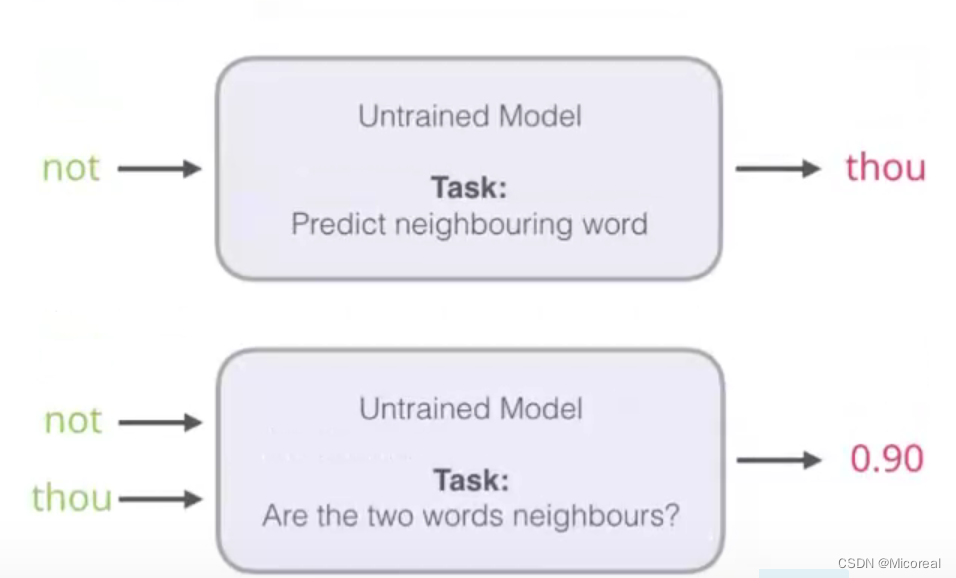
但是在这种过程中,你训练的文本得出的训练量其实都是1,比如我们一句话放进去训练,它总是拿这句话进去判断是否是导致训练量全是1,所以我们就需要人为的提供一些文本当中没有出现的训练量,并使其为0.这也就是负采样模型。
通常情况下,负采样模型的个数应当是5个。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









