










24年5月来自Penn State和Ohio State两个大学更新的综述论文“Large Language Model Instruction Following: A Survey of Progresses and Challenges”。
任务语义可以通过一组输入-输出示例或一段文本指令来表达。传统的自然语言处理 (NLP) 机器学习方法主要依赖于大规模特定任务的示例集。出现了两个问题:首先,收集特定任务的标记示例不适用于任务可能过于复杂或注释成本过高,或者系统需要立即处理新任务的情况;其次,这并不方便用户使用,因为最终用户在使用系统之前可能更愿意提供任务描述而不是一组示例。因此,社区对 NLP 的监督-寻求范式越来越感兴趣:学习遵循任务指令,即指令跟随。尽管取得了令人瞩目的进展,但仍有一些未解的研究方程很麻烦。这篇综述论文试图总结并为当前关于指令跟随的研究提供见解,特别是通过回答以下问题:(i) 什么是任务指令,存在哪些指令类型?(ii) 如何建模指令? (iii) 流行的指令跟随数据集和评估指标有哪些? (iv) 哪些因素影响和解释指令的表现? (v) 指令跟随还面临哪些挑战?
如图所示有两种监督学习范式:(a)示例驱动学习使用大量标记示例来表示任务语义。最终系统只能推广到同一任务未见的实例;(b)指令驱动学习逼迫模型遵循各种任务指令。除了未见的实例外,最终系统还可以推广到未见的任务。
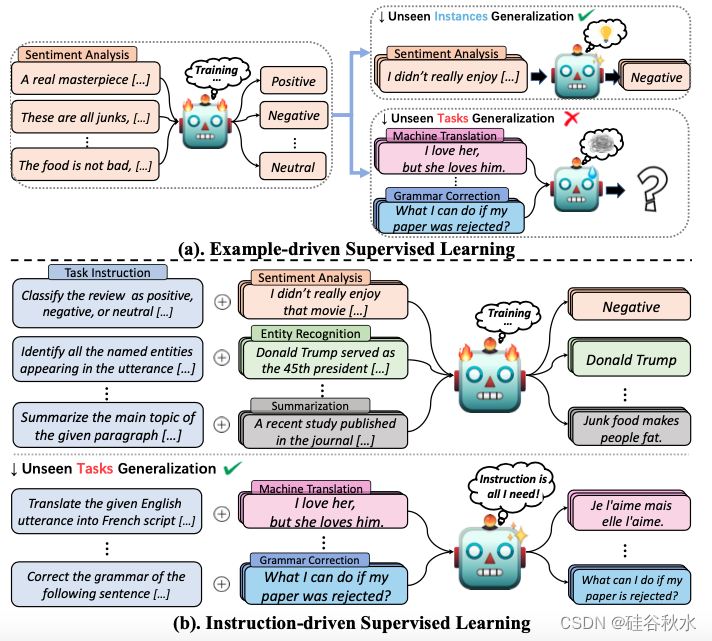
更重要的是,在学习新任务方面,指令遵循更接近人类智能——一个小孩子可以通过学习指令和一些例子很好地解决一项新的数学任务(Fennema,1996;Carpenter,1996)。因此,这种新学习范式最近引起了机器学习和 NLP 社区的主要关注(Wang,2022b;Longpre,2023)。提示仅仅是指令的一种特例。
如图所示,有三种文本指令模式,即T(模版),X(输入), Y(输出)的不同组合:(a)面向自然语言推理(NLI),(b)面向LLM和(c)面向人的指令
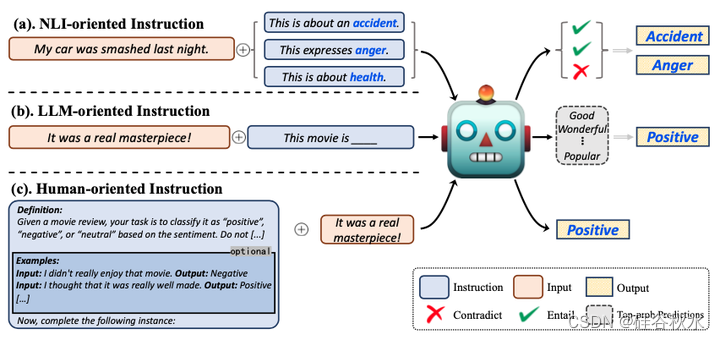
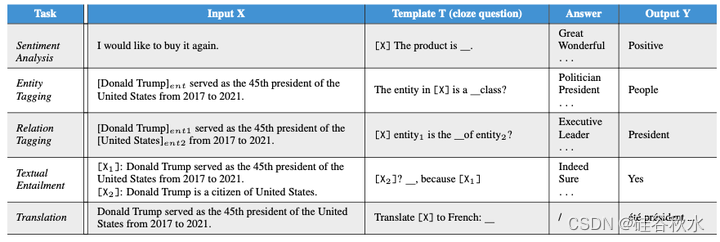
处理分类任务的传统方案是将目标标签转换为索引,并让模型决定输入属于哪些索引。这种范式只编码了输入语义,而丢失了标签语义。为了让系统不依赖大量标记示例来识别新标记,(Yin2019)提出为每个标签建立一个假设将目标分类任务转换为自然语言推理(NLI)——推导标签的真值然后转化为确定假设的真值。该方法将模板(T)与标签(Y)相结合来构建指令(I)解释任务语义。下表进一步提供了面向 NLI 指令更详细的示例。

面向 NLI 指令学习的优势有四个方面:(i)它保留标签语义并使编码输入输出关系成为可能;(ii)它将各种分类问题统一为一个 NLI 任务; (iii) 利用现有 NLI 数据集的间接监督,在 NLI 任务上训练的模型,有望以零样本方式处理其他任务;(iv) 它将原始的闭集索引分类问题扩展为开放域标签识别范式。因此,它已广泛应用于各种少样本/零样本分类任务 (Xu et al., 2023d),例如对题目 (Yin et al., 2019)、情绪 (Zhong et al., 2021)、立场 (Xu et al., 2022b)、实体类型 (Li et al., 2022a)、实体关系 (Murty et al., 2020; Xia et al., 2021; Sainz et al., 2021, 2022) 等进行分类。
如表所示,提示是面向 LLM 指令的代表,通常是以任务输入为前缀的简短话语(前缀提示)或完形填空(cloze)问题模板(完形填空提示)。它基本上是为从 LLM 查询中间响应(可以进一步转换为最终输出)而设计的。由于提示的输入符合 LLM 的预训练目标,例如,完形填空式输入满足掩码语言建模目标 (Devlin et al., 2019a),它有助于摆脱对传统监督微调的依赖,并大大减轻人工注释的成本。因此,提示学习在先前的大量少样本/零样本 NLP 任务中取得了令人印象深刻的成果,例如问答(Radford,2019;Lin,2022)、机器翻译(Li,2022c)、情绪分析(Wu & Shi,2022)、文本包涵(Schick & Schütze,2021a、b)、实体识别(Cui,2021;Wang,2022a)等。
尽管提示技术表现优异,但在实际应用中,面向 LLM 的指令仍然存在两个明显的缺点。(i)用户不友好。由于提示是为服务 LLM 而设计的,因此鼓励用“模型语言”设计提示(例如,模型倾向的不连贯词或内部嵌入)。然而,这种以 LLM 为导向的风格很难被用户理解,而且经常违背人类的直觉 (Gao et al., 2021; Li & Liang, 2021; Qin & Eisner, 2021; Khashabi et al., 2022)。同时,提示的性能高度依赖于费力的提示工程 (Bach et al., 2022),但大多数最终用户不是 LLM 专家,通常缺乏足够的知识来调整有效的提示。 (ii) 应用限制。提示通常简短而简单,而许多任务不能仅用简短的提示来有效地制定,这使得提示很难处理现实世界 NLP 任务的多种格式 (Chen et al., 2022b; Zhang et al., 2023a)。
面向人的指令本质上表示在人工注释平台(例如 Amazon MTurk)上用于众包的指令。与面向 LLM 的指令不同,面向人的指令通常是一些对人可读的、描述性段落样式的信息,由各种部分组成,例如“任务题目”、“类别”、“定义”和“要避免的事情”等(参见 Mishra,2022b)。因此,面向人的指令更加用户友好,可以理想地应用于几乎任何复杂的 NLP 任务。下表进一步显示了一些代表性任务示例。

因此,面向人的指令近年来引起了更多关注(Hu,2022b;Gupta,2022;Yin,2022)。然而,由于其复杂性,面向人的指令更难通过 原始 LLM 进行编码。例如,现成的 GPT-2 在遵循 MTurk 指令方面表现不佳(Wolf,2019;Efrat & Levy,2020)。为了让 LLM 更好地理解以人为本的指令,后续工作开始收集大规模指令数据集(Mishra,2022b;Wang,2022b)。所有先前的结果都表明,在使用各种任务指令进行微调后,文本到文本的 LLM,如 T5(Raffel,2020)、OPT(Zhang,2022a)和 Llama(Touvron,2023),通过遵循这些复杂的指令实现显着的少样本/零样本泛化(Wang,2023c;Ivison,2023b)。
虽然这三类指令彼此之间有很大差异,但本质上都在寻求同一件事——间接监督——以应对注释有限的目标任务。
具体而言,面向NLI的指令将目标NLP问题转换为源任务——NLI——以便来自现有NLI数据集的监督可以作为这些目标问题的间接监督。面向LLM的指令将目标问题重新格式化为源任务——语言建模,以便可以直接利用这些LLM中丰富的通用知识来获得输出。无论是面向NLI的指令还是面向LLM的指令,都试图用可泛化的系统解决未见的任务。然而,它们都具有有限的应用范围,例如,它们不能有效地处理一些结构化的预测任务(Chen,2022b;Zhang,2023a)。以人为本的指令不是从单一来源任务(NLI 或语言建模)寻求监督,而是从大量训练任务中学习间接监督,因此,理想情况下,生成的系统可以推广到任何未见的文本任务。下表从不同维度进一步比较了它们。
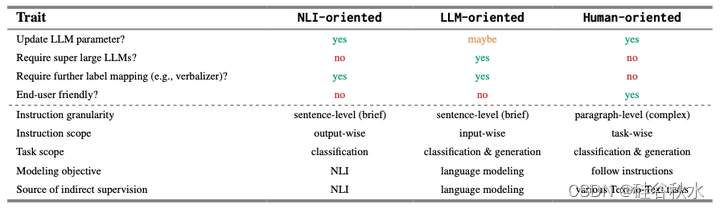
由于面向 NLI 的指令和面向 LLM 的指令都与输入 X 或输出 Y 相关联,因此这些类型的指令不需要特定的系统设计来对其进行编码。面向 NLI 的指令可以由用于 NLI 任务的常规系统处理,而面向 LLM 的指令大多被馈送到自回归 LLM。相比之下,面向人类的指令是最具挑战性的类型,因为它独立于任何标记实例。
面向人类的指令有几种主流建模策略,如图所示:(a)基于语义解析器,(b)基于扁平-拼接,(c)基于超网络,和(d)带人类反馈的强化学习(RLHF)。
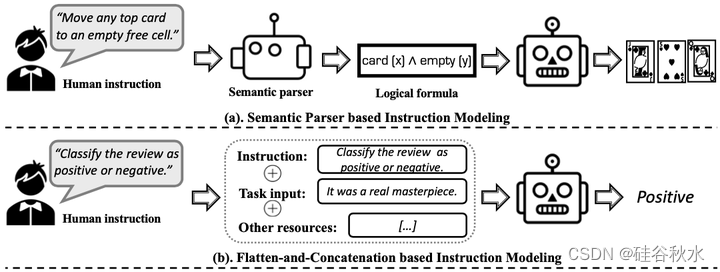
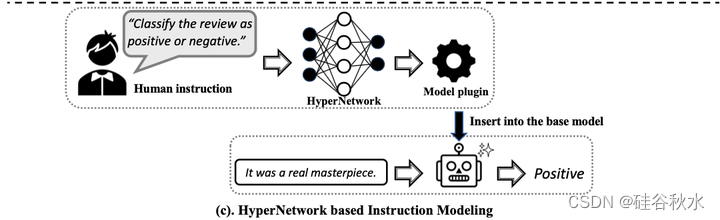
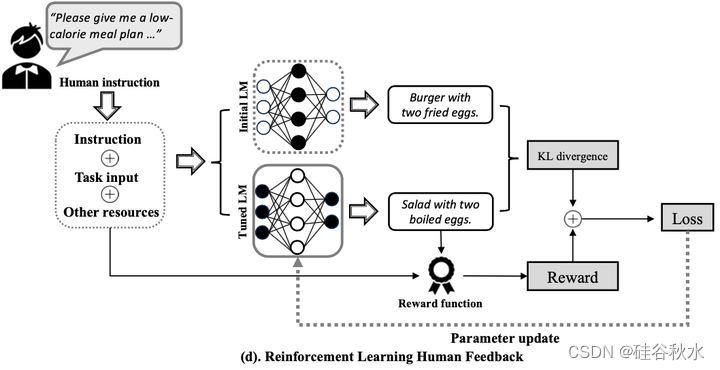
指令跟随的本质,是遵循各种任务指令并用相应的期望输出做出响应来强迫模型。因此,指令调优数据集(高质量的指令-输出对)是关键部分(Wang,2023c;Zhou,2023a)。当前的指令调优数据集可以根据不同的注释类分为两类:1)人工注释数据集;2)LLM 合成数据集。
如何评估指令调优模型也是一个关键话题。大多数传统的 NLP 任务通常对任务目标有具体的标准,而对于指令跟随,关键目标是强迫模型遵循指令——模型遵循指令的程度非常主观,取决于各种偏好。因此,不同的工作倾向于使用不同的评估策略。
基本上评估分成两种:任务为中心和人为中心。
指令跟随在很多少样本/零样本 NLP 任务中被证明是有效的,但如何解释指令的出色表现?哪些方面构成了成功的指令跟随程序?影响指令跟随表现的因素分为五个维度:模型、指令、演示、模型-指令对齐和数据。下表显示路线图和要点:

规模化可以说是导致指令跟随成功的核心因素。在基于 LLM 的指令跟随之前,扩展主要针对深度学习模型:从单层神经网络到多层感知器,从卷积/循环神经网络到深层 Transformer(Hochreiter & Schmidhuber,1997;LeCun,1998;Vaswani,2017;Devlin,2019b)。
随着大量原始文本数据的预训练,不断增加的模型预计会编码大量通用知识(Zhou,2023a)。在指令跟随时代,社区对跨任务泛化更感兴趣,仅仅规模化 LLM 似乎还不够。因此,研究人员采取了并行方式:收集越来越多的训练任务和每个任务的标记示例。将其解释为双轨规模化。总体而言,这种双轨规模化共同寻求监督来解决新任务——监督要么来自 LLM 的预训练,要么来自大量的训练任务。

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









