






文本匹配作为一项非常经典的任务,在学界和工业界都有大量的研究和引用,如在检索系统中的各个环节(召回、排序等)。
本文通过一些论文,回顾语言模型文本匹配的工作,介绍一下不同方向文本匹配的主流方法。
文章目录
- Matching Model
- Dual-Encoder
- Semantic Text Matching for Long-Form Documents
- RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
- PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
- RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
- Pre-trained Language Model for Web-scale Retrieval in Baidu Search
- 小小的总结
- Cross-Encoder
- 总结
Matching Model
A Deep Architecture for Matching Short Texts
- https://proceedings.neurips.cc/paper/2013/file/8a0e1141fd37fa5b98d5bb769ba1a7cc-Paper.pdf,2013 NIPS.
主要针对短文本匹配问题。对于两个待匹配的对象,常见的匹配方法是将两个对象分别映射为各自空间的向量,再进行相似性计算,如计算余弦相似性。论文提出了DeepMatch,通过深度网络建模文本间的交互。DeepMatch主要基于以下两个直觉:
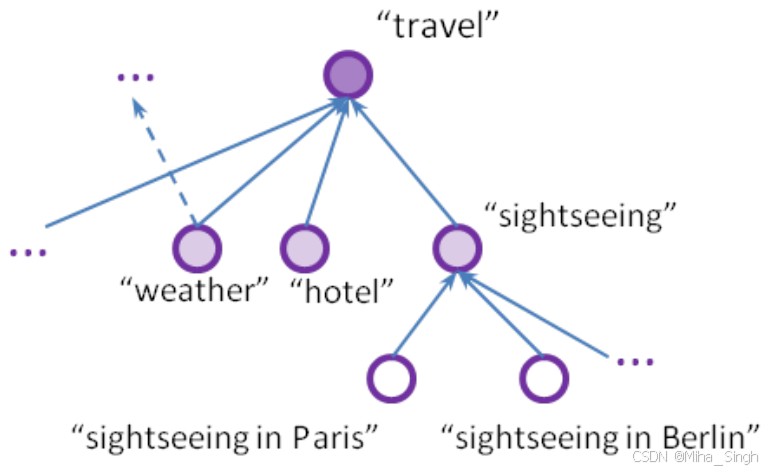
- Localness。即两个文本间存在的词级别的共现模式。在论文中,共现不一定是字面的精确匹配,也可以是话题级别的共现;
- Hierarchy,即共现模式可能在不同的词抽象层次中出现,组合出文本对间复杂的语义关系。如下图:
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
- https://www.iro.umontreal.ca/~lisa/pointeurs/ir0895-he-2.pdf,2014 CIKM.
一些方法以词袋处理query / doc,忽略了文本的上下文信息(文本中的token在不同的上下文中有不同含义)。论文提出了Convolutional Latent Semantic Model(CLSM,也即CDSSM),模型结构如下所示:
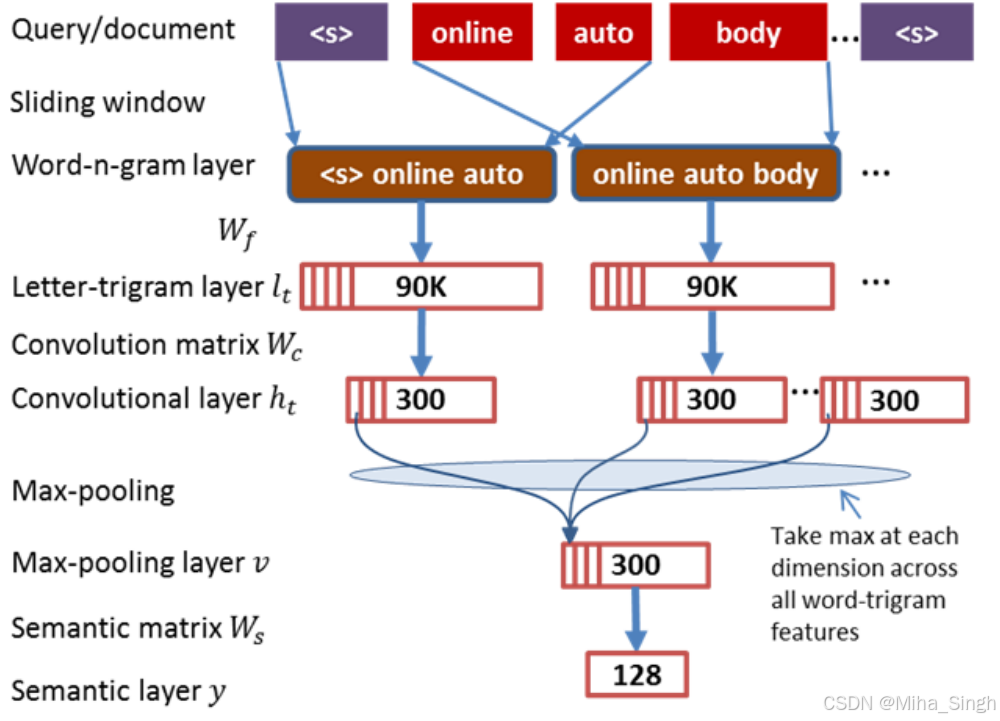
过程:
- word-n-gram layer。在输入的文本上做词粒度的n-gram,即用制定大小的滑动窗口在文本上滑动,每个窗口包含多个词。
- letter-trigram layer。每个词是通过字母的三元组表示的,如boy表示为三个字母三元组:#bo, boy, oy#。每个word则由多个字母三元组组成,用一个multi-hot向量表示,向量的长度是字母三元组的数量,也即词表的大小(假设是30k)。图中是word-3-gram,因此每个窗口里有3个词,每个词的向量拼起来就是长度为90k的向量。
- convolutional layer。即把每个word-n-gram转换成一个向量(图中的300维向量)。
- max-pooling。即把整个文本的多个word-n-gram的向量表示转化成一个向量(图中的300维的向量)。
- semantic layer。即对上一步得到的向量进行变化,压缩维度(图中的128维的向量)。
A Deep Relevance Matching Model for Ad-hoc Retrieval
- https://arxiv.org/pdf/1711.08611,2016 CIKM.
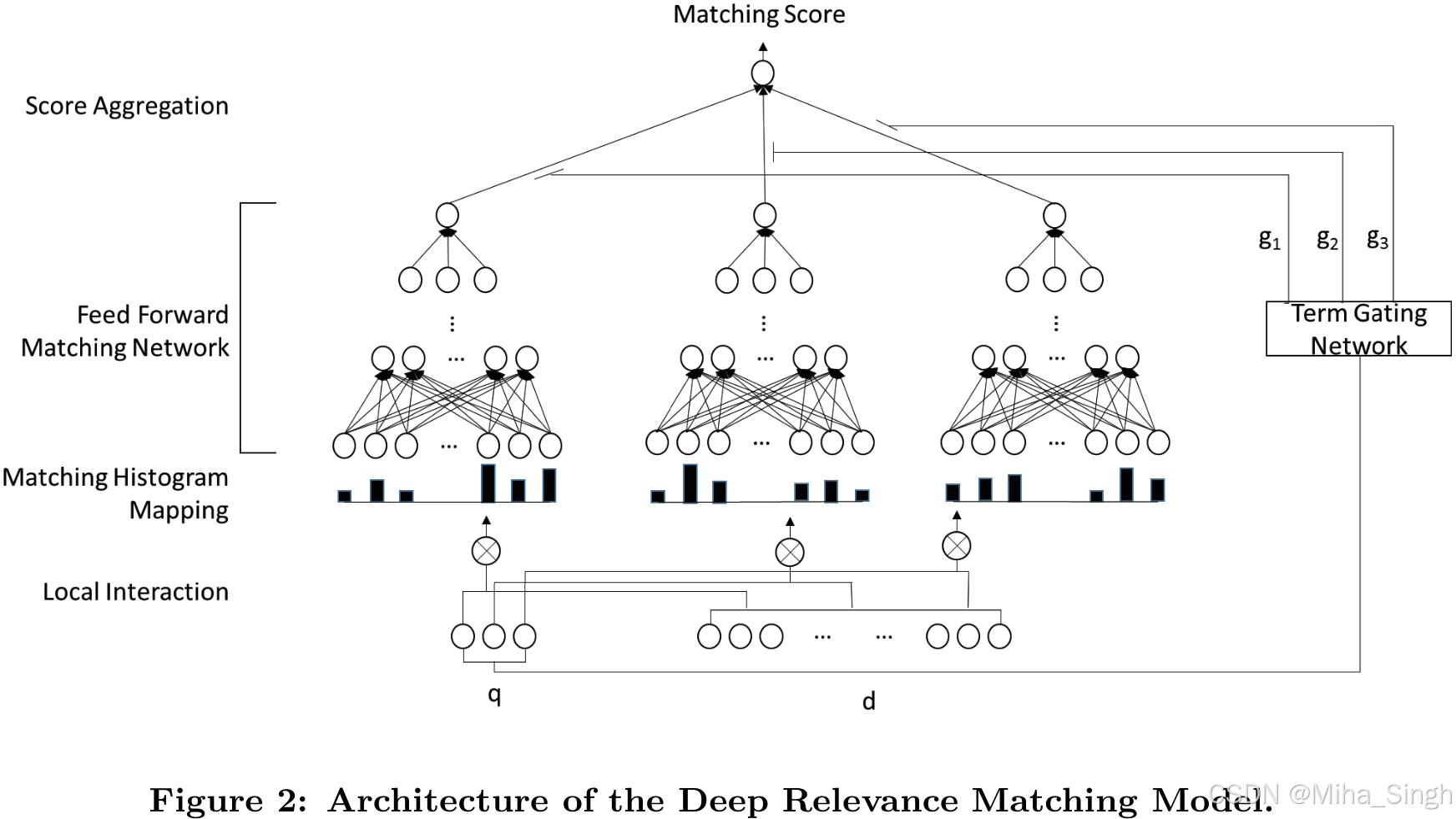
主要针对文本匹配中的相关性匹配(与语义匹配不同)。相关性匹配一般需要处理精确的匹配信号,如query中term的重要性、不同的匹配要求等。论文提出了DRMM(Deep Relevance Matching Model),在query的term级别进行相关性匹配。具体地:
- 基于嵌入,构建query中term和文档的局部交互。对于每个term,将交互映射为一个固定长度的匹配直方图。
- 对于每个匹配直方图,通过前馈网络将其映射为一个匹配分数。
- 最后,通过term门控网络聚合所有匹配直方图的匹配分数,作为最终的相关性分数。
文中对相关性匹配和语义匹配做了一个不错的对比。
- 语义匹配更看重:
- Similarity matching signals。与精确匹配不同,相似的文本间可能没有字面上的重叠,可能是二者之间有某种关联关系,比如问题和答案的关系。
- Compositional meanings。语义匹配中的文本通常具有一定的语法结构(没咋明白)。
- Global matching requirement。语义匹配中的文本相对较短,通常将两个文本看作一个整体来推断文本间的关系。
- 相关性匹配更看重:
- Exact matching signals。term之间精确的匹配信号。
- Query term importance。query中不同term的重要性是不一样的,命中更重要的term的文档更相关。
- Diverse matching requirement。相关性匹配通常是短文本和长文本的匹配。关于短query和长文档的匹配问题,有不同的假设(hypothesis),如verbosity hypothesis(假定长文档是围绕一个话题的,只是词比较多,更符合语义匹配的要求)和 scope hypothesis(假定长文本是由多个不同话题的短文本组成的)。相关性匹配并不要求长文本的所有内容都和query相关。
说了这么多,来看下模型结构:
用几个公式总结一下:
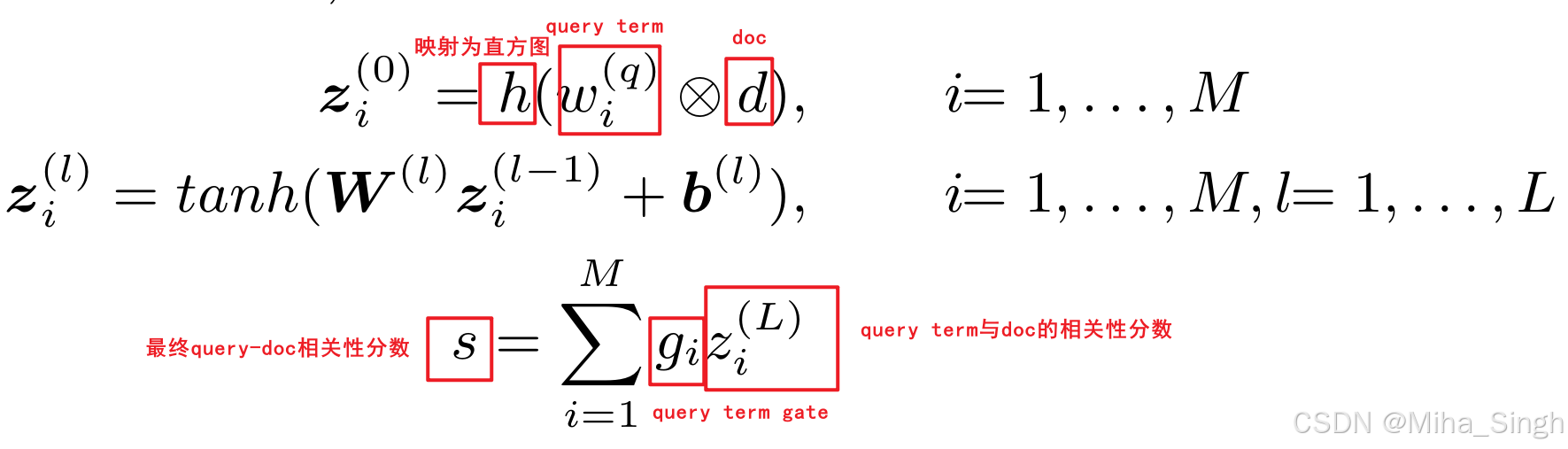
有几个细节:
- query、doc的term的表示是通过word2vec获取的,训练时并不需要学习词表;
- query term与doc的交互方式:query term与doc中每个term计算余弦相似性;
- 映射为直方图也比较直接,即根据query term与doc中term的相似性分数构建直方图。
几个问题:
- 首先,该方法是不考虑位置信息的;
- doc的长度对直方图的分布可能有较大的影响,对短doc效果如何?
DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval
- https://arxiv.org/pdf/1710.05649,2017 CIKM.
- https://github.com/pl8787/DeepRank_PyTorch.
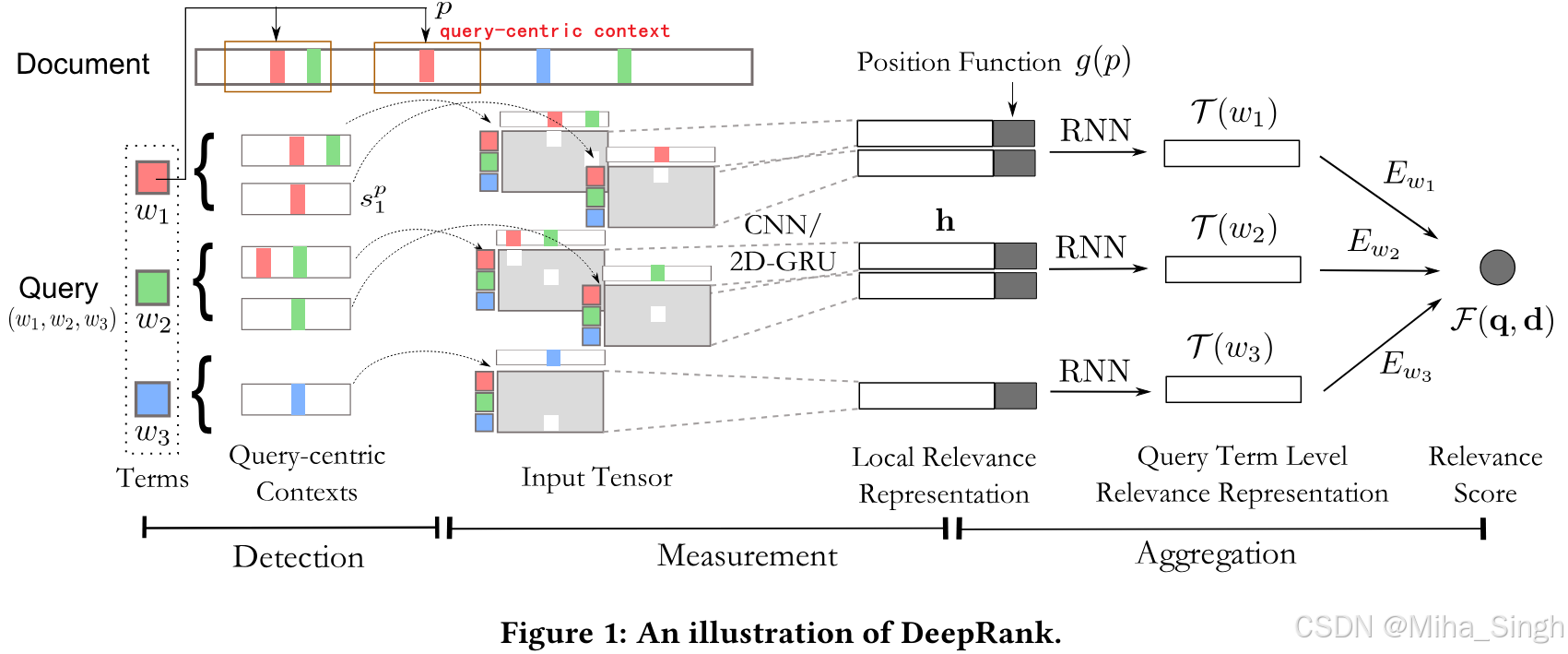
一些基于NN的相关性模型没有显式考虑相关性。人评价相关性的过程:1)检测相关性所在的位置;2)局部相关性分数;3)聚合局部相关性作为最终的相关性分数。论文提出了DeepRank,仿照人进行相关性判断,捕获精确的匹配信号和语义匹配。分三步走:
- 检测策略。抽取相关的内容——以query中某个term为中心的片段。
- 评估网络。评估局部相关性——query与每个检测到的片段的匹配矩阵,多个片段的匹配矩阵则可以看作一个三维的张量。每个匹配矩阵可以是精确的匹配或者是语义相似性(如向量的余弦相似度)。再通过CNN或者2D-GRU,把每个矩阵转化成一个相关性表示向量(即图中的Local Relevance Representation)。
- 聚合网络。聚合局部相关性,得到最终相关性分数——分两步:1)先把每个query term对应的多个片段的局部相关性表示聚合为单个向量,作为query term级别的相关性表示;2)聚合每个query term的相关性表示作为最终的分数。
Dual-Encoder
Semantic Text Matching for Long-Form Documents
- https://jyunyu.csie.org/docs/pubs/www2019paper.pdf,2019 WWW.
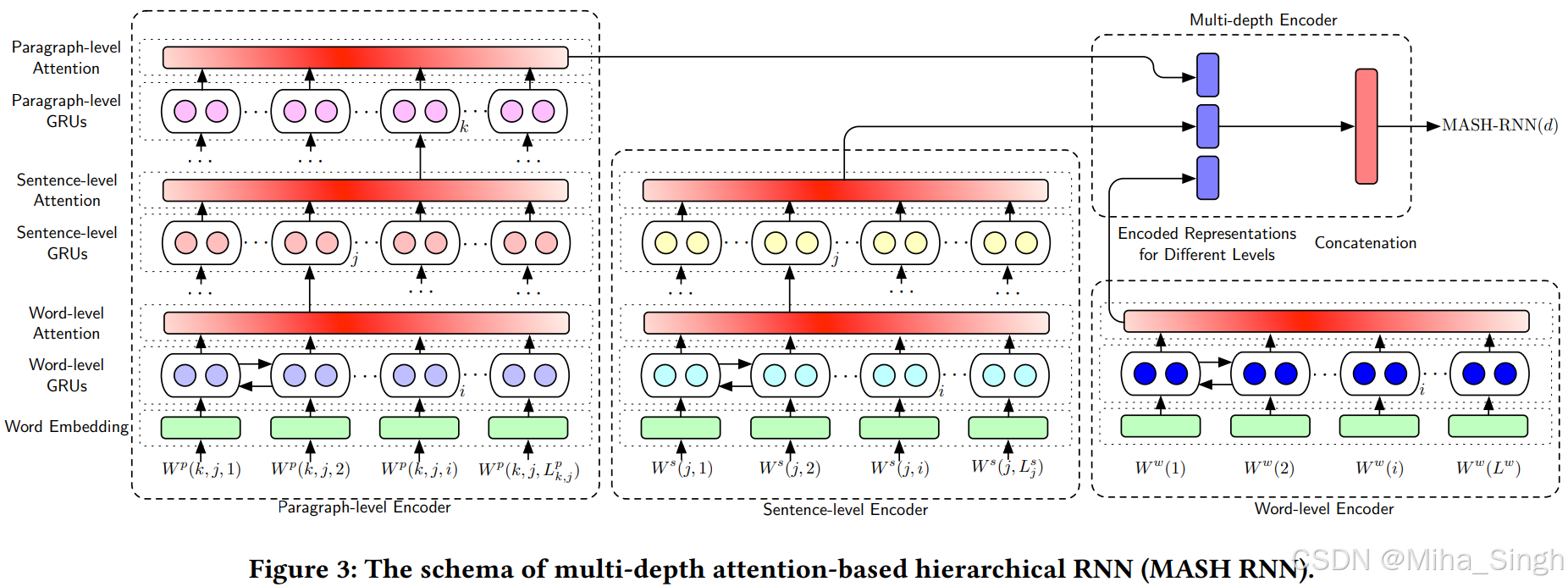
顾名思义,针对长文本间的文本匹配。论文提出了Siamese multi-depth attention based hierarchical recurrent neural network (SMASH RNN),学习doc的不同层次的表示作为doc表征,可以看作融合了多层次信息的表征。论文中一共考虑了三个层次:段落、句子、词。每个层次对应一个编码器,每个编码器输出对应层次的表征,最终将三个层次的表征融合作为文档最终的表征。进行文本匹配时,按照双塔的思路,分别计算两个doc的表征,再计算相似性。
模型结构如下:
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
- https://arxiv.org/pdf/2010.08191,2021 NAACL.
关键词:question answering、dense passage retrieval、dual-encoder。
看摘要,本质是要解决训练数据的问题?论文提出了RocketQA,一个优化的训练方法,主要贡献有三:
- cross-batch negatives。
- denoised hard negatives。
- 数据增强。
对比一下dual-encoder(双塔模型)和cross-encoder(交互模型):
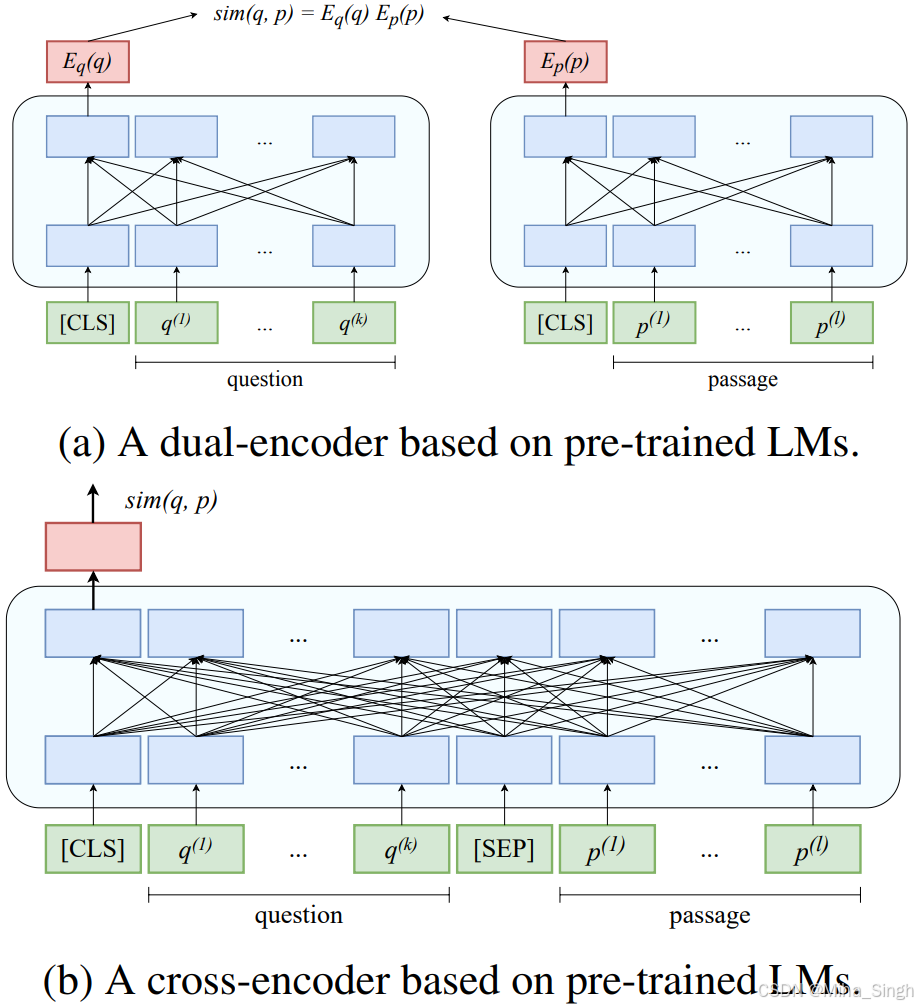
看看各个优化点是怎么做的。
Cross-Batch Negatives
先看看In-batch negatives是啥:在一个batch中,对每个query来说只有一个正样本,以其他query的正样本作为该query的负样本。为了使模型见到更多的负样本,提出了Cross-batch。In-Batch和Cross-Batch的对比如下(在A个GPU上数据并行训练,每个Batch的大小为B):
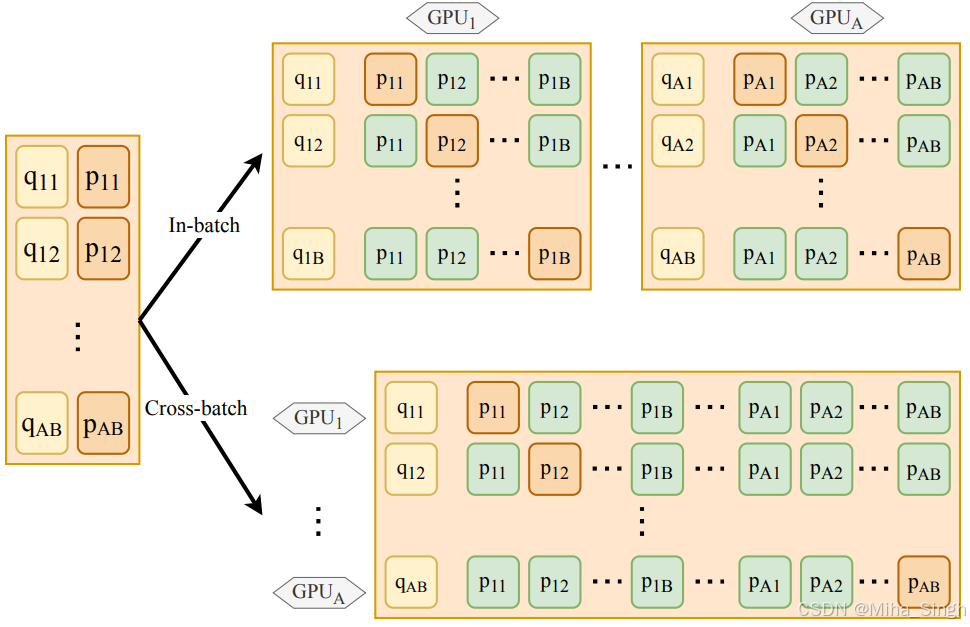
从图上可以看出,原来In-Batch中每个q的负样本只是同batch内其他q的正样本。Cross-Batch中,每个q的负样本包含了其他batch中的样本。在数据并行训练的实践中的做法:计算每个p的嵌入,然后在多个GPU间共享——这通信量这么大,训练起来不会很慢吗?
本质还是再扩充负样本,现在看来已经是常规手段了。除了实践时的效率问题(个人猜测),也不适用于交互形的模型,只能在输入模型前就构造好。
Denoised Hard Negatives
一般而言,训练的时候为每个q配一个正样本(标注时一般就标一两个正样本),其他的都作为负样本(一般通过检索top的结果得到)。这种情况假阴样本的问题可能会比较突出——负样本中有一些实际是正样本,这类数据会给训练引入噪音。这个问题确实还是蛮常见的,数据去噪,提升样本质量一直都很重要。
论文中的做法比较直接:训练一个更复杂的交互式模型,用于筛选真正的负样本。
Data Augmentation
这个就更直接了,直接用交互式模型进行打标,生成更多的数据。
PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
- https://aclanthology.org/2021.findings-acl.191.pdf,2021 ACL.
关键词:dual-encoder、query-passage similarity。
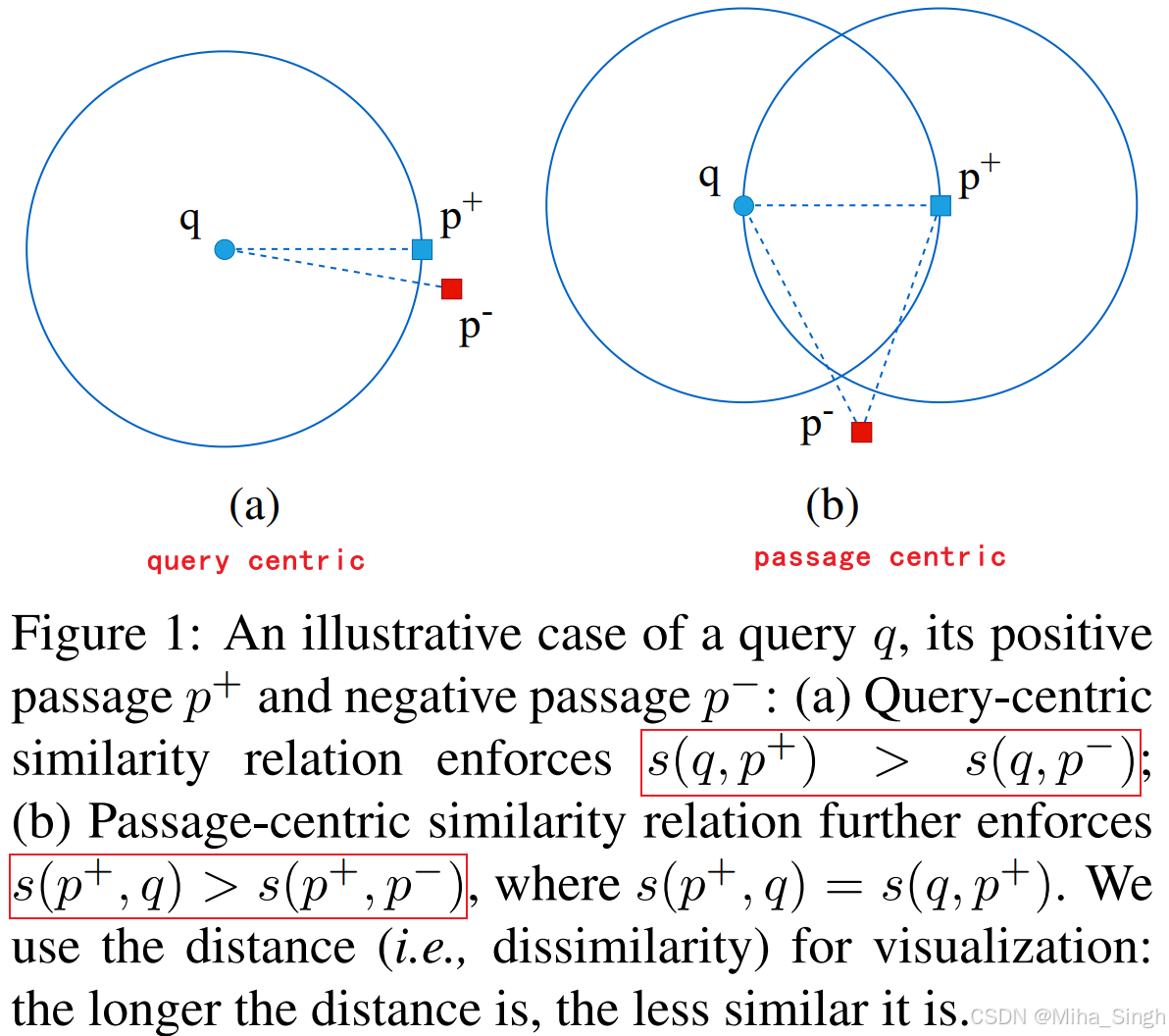
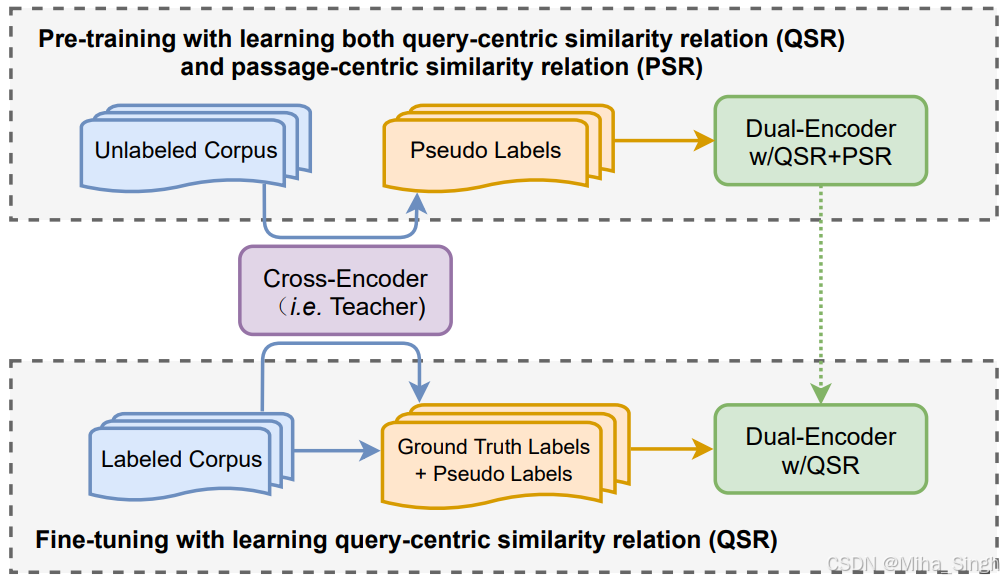
看标题可知一二——以passage为中心的相似性。一图胜千言,如下图,将 s ( p + , q ) > s ( p + , p − ) s(p^+, q) > s(p^+, p^-) s(p+,q)>s(p+,p−) 引入训练中。虽然看似简单,但在实现时却有一些问题:1)如何形式化定义query-centric和passage-centric这两种相似关系;2)需要大量高质量的数据学习passage-centric相似性;3)同时学习query-centric和passage-centric,可能会与主任务(query-centric)冲突。论文提出了PAssage-centric sImilarity Relations(PAIR)来解决以上问题:1)损失函数;2)生成伪标签数据;3)两阶段的训练流程。
Defining the Loss Functions
简言之,就是通过两个损失函数来结合query-centric和passage-centric,如下:
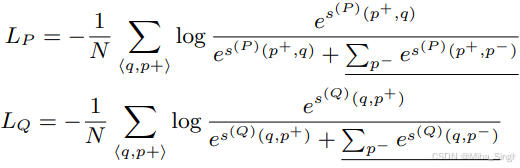
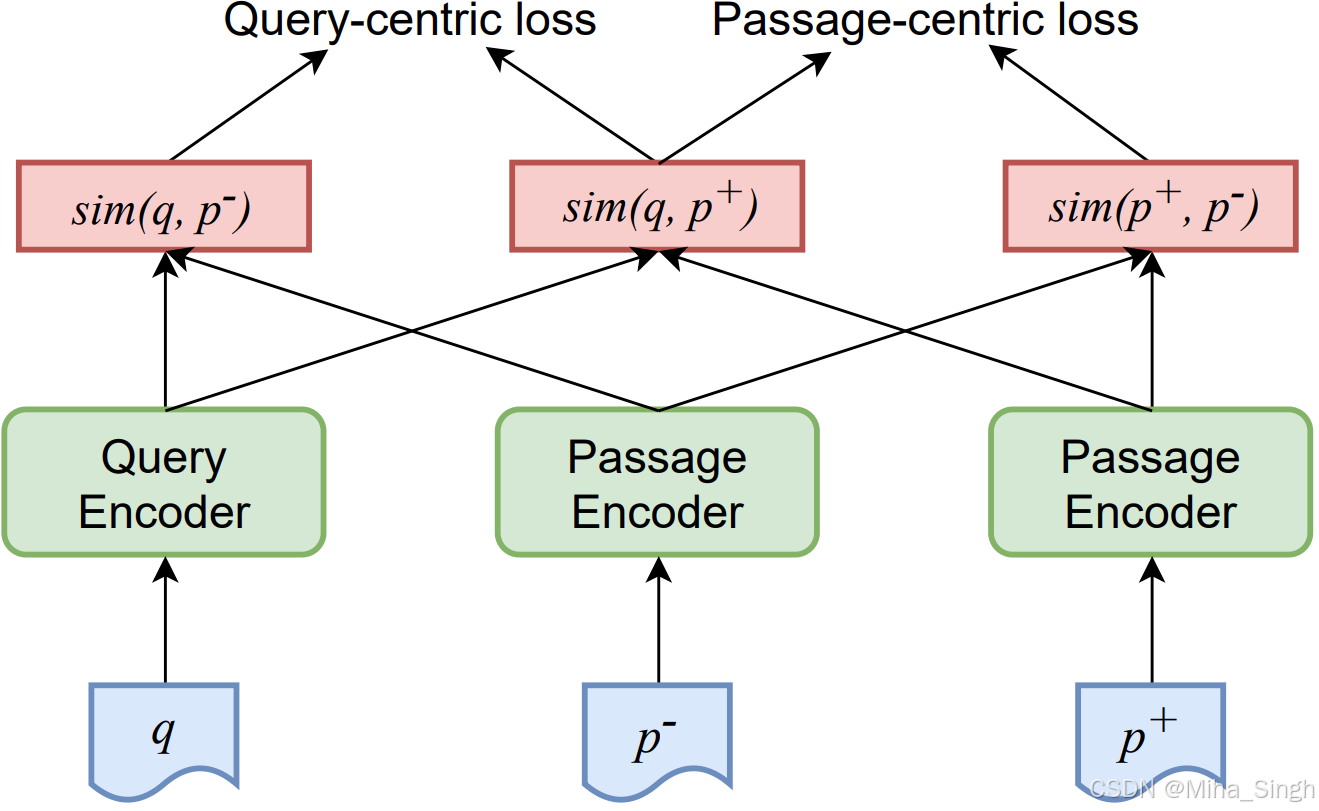
通过损失可以看到,需要假设query、passage在同一映射空间中,因此论文的双塔之间的参数是共享的。
Generating the Pseudo-labeled Training Data via Knowledge Distillatio
用一个更复杂的交互式模型去打标,以获取更多数据。
Two-stage Training Procedure
由于dual-encoder的实际目标还是计算query-passage间的相似性,因此将训练分为两个阶段:
- 预训练阶段:在伪标签数据上,训练query-centric和passage-centric两个任务;
- 微调阶段:在标注数据和伪标签数据上,仅训练query-centric任务。
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
- https://aclanthology.org/2021.emnlp-main.224.pdf,2021 EMNLP.
联合优化召回和重排,论文的内容主要分成两部分:1)dynamic listwise distillation;2)hybrid data augmentation。
Dynamic Listwise Distillation
召回和排序模型一般是分开训练的,虽然也会把排序模型蒸馏到召回模型,但二者不是联合训练、同时学习的。论文通过两个损失联合训练召回和排序模型,并在训练过程中将排序模型蒸馏到召回模型,如下图所示:
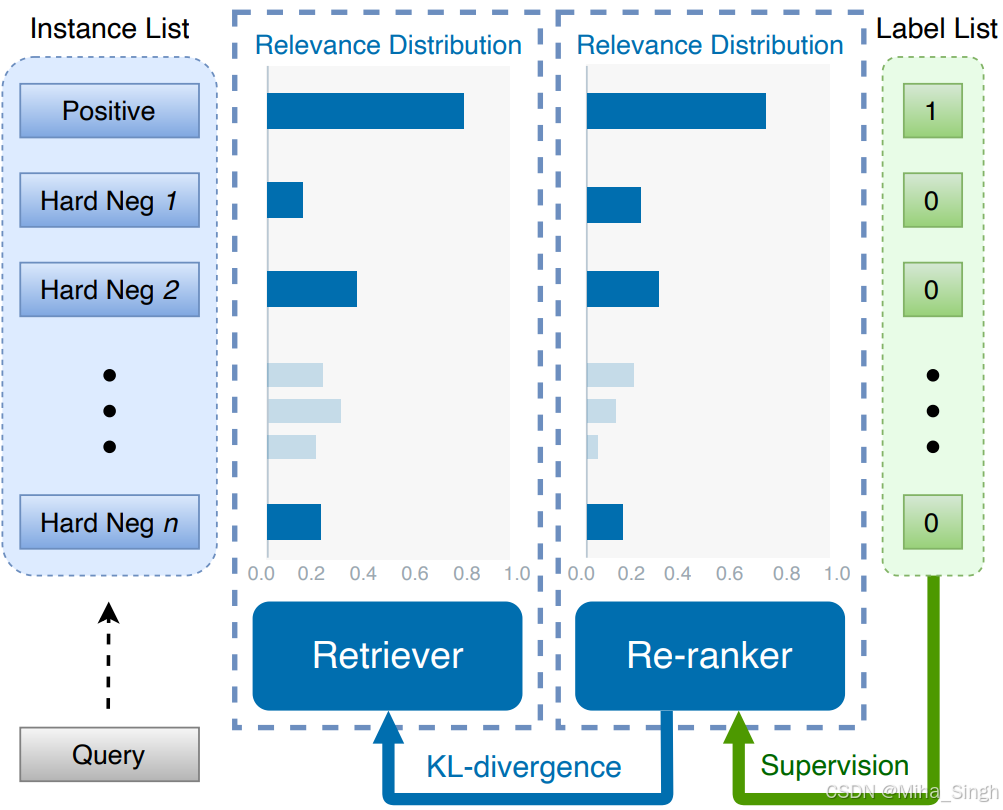
训练时输入为listwise的样本,一个正样本多个负样本。通过两个损失将召回和排序串联起来:
- 真实标签与排序模型输出计算listwise的监督损失;
- 排序模型输出的分数分布与召回模型输出的分数分布计算KL损失,及将排序模型蒸馏到召回模型。
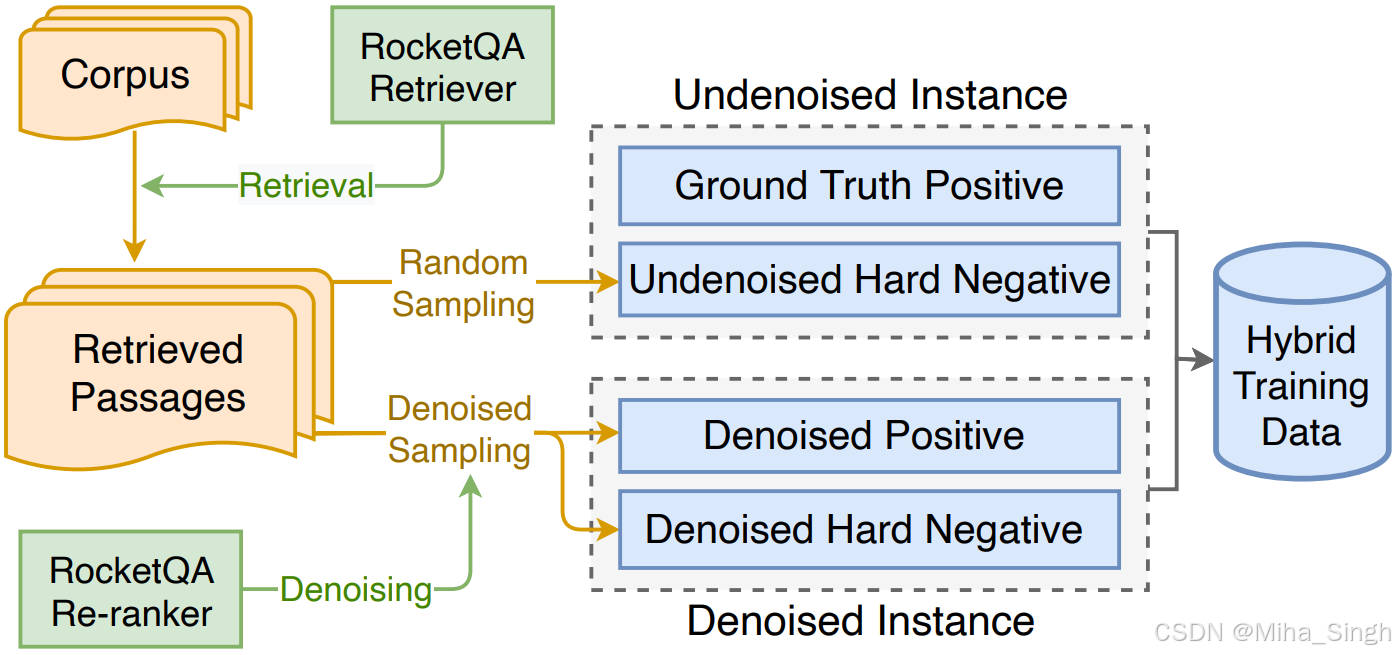
Hybrid Data Augmentation
由于训练时输入为listwise形式的样本,希望输入列表中包含多样化和高质量的passages,以更好地表示真实的样本分布(召回和排序的样本分布能一样吗?)。如下图,在构造数据时基于RocketQA Retriever和Reranker进行筛选,过程见下图即可。
Pre-trained Language Model for Web-scale Retrieval in Baidu Search
- https://arxiv.org/pdf/2106.03373#page=9&zoom=100,76,330,2021 KDD.
这篇论文针对检索系统的以下三个挑战提出了解决方案:
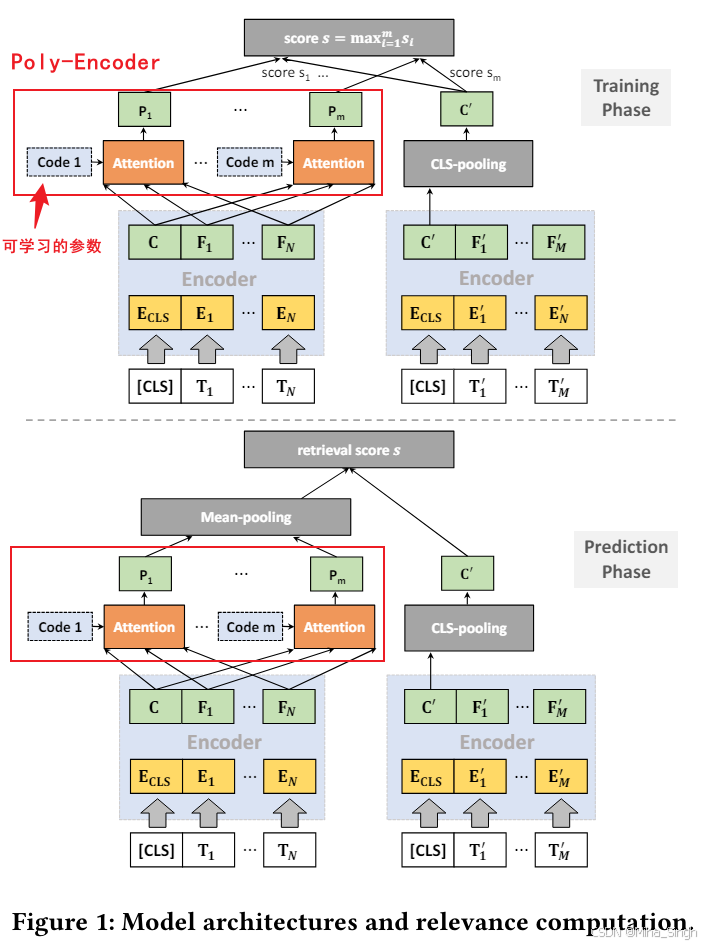
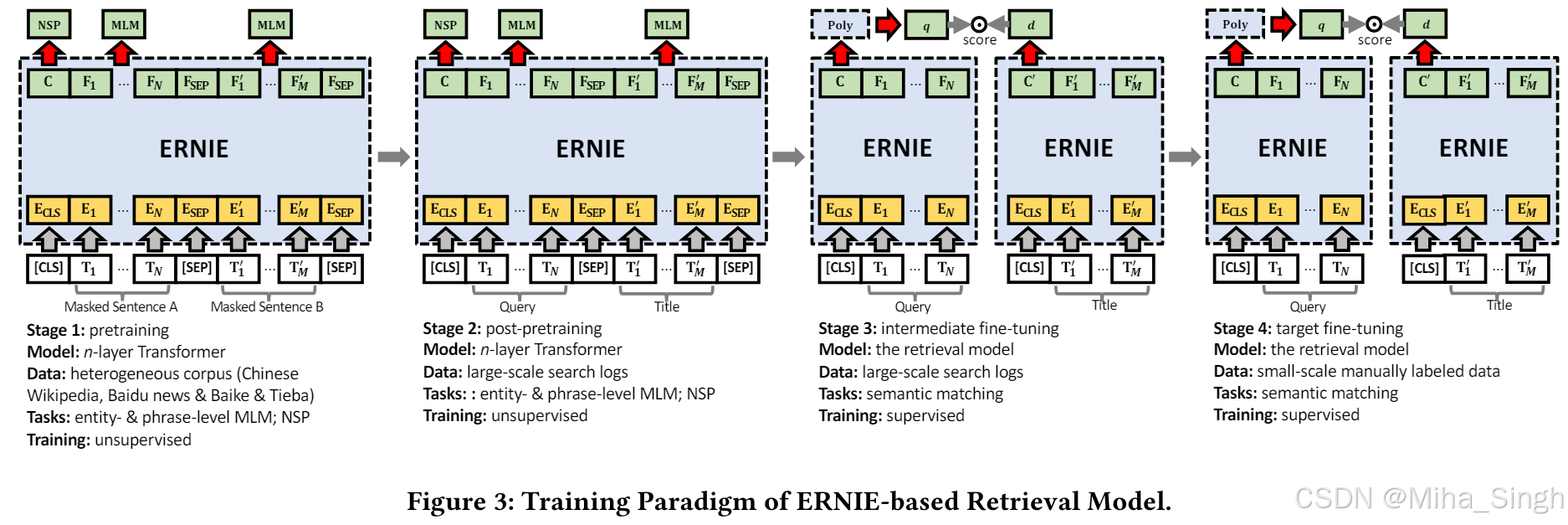
- 语义匹配的一个难点——不同分布间的匹配,query更偏向自然语言,文档更规范。方案:用ERNIE(双塔结构)进行文本匹配,两个塔的交互采用Poly-Encoder,模型结构如Figure 1所示。
- 长尾问题。对于长尾query,语义计算可能不准确。方案:将ERNIE的训练分成四个阶段:1)pretraining;2)post-pretraining;3)intermediate fine-tuning;4)target fine-tuning,如Figure 3所示。
- 线上部署时的性能。方案:对输出的向量维度进行压缩以及量化。
这篇论文比较有意思的是给出了生产环境下,离线和线上系统的使用方法:
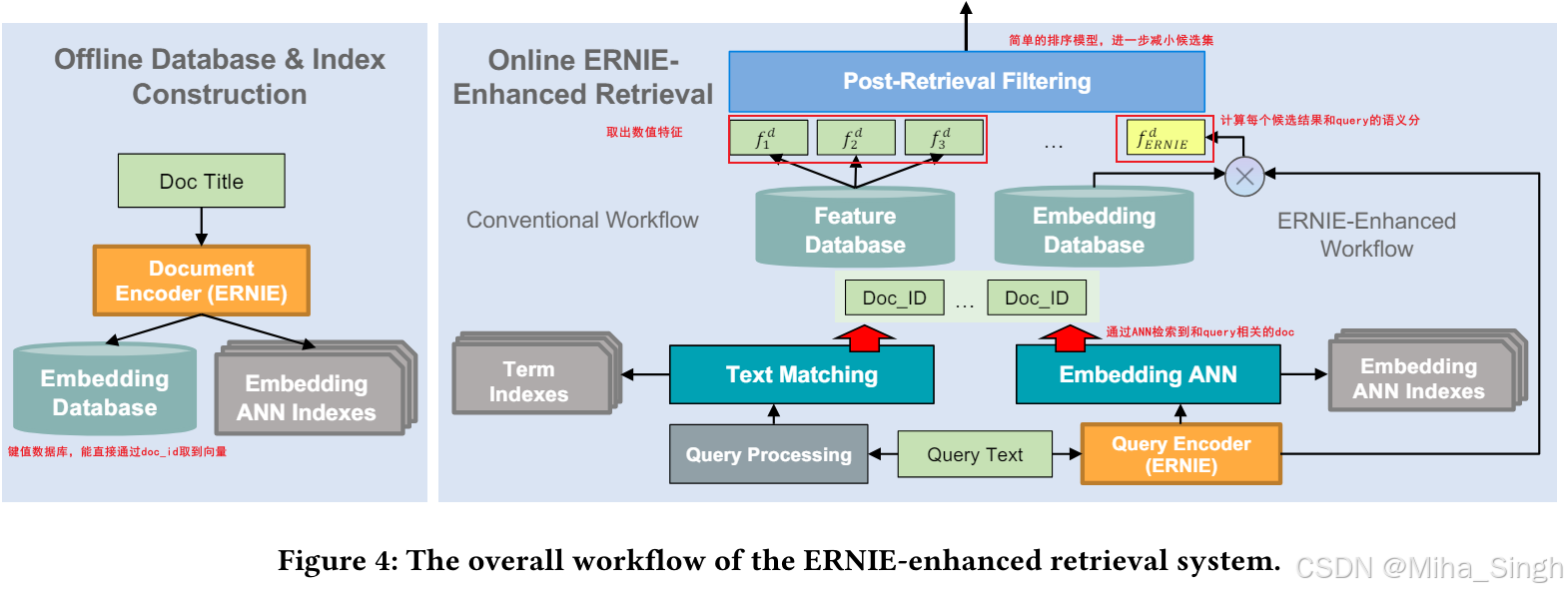
论文虽然没有突出的创新点,比较偏向工程实践,不仅涉及到模型、训练,还涉及到线上部署的流程,其中的方法对业界来说也有很大的参考价值。
小小的总结
总的来看,这些论文主要是围绕训练策略和数据上做的一些优化,不涉及对模型的变动,虽然看起来没有那么高大上,不过感觉还是很贴近业界的实践的。的确,实践中往往训练策略和数据的影响是比较大的,记一些比较重要的点:
- 数据去噪,这里的“噪”一般是指假阴样本。实践中,正样本一般时人工标注的,负样本也会有一部分是标注的,但是往往我们还需要挖掘大量的负样本,挖掘过程中就难免会引入一些假阴样本,即把一些正样本当作负样本。
- 难负样本。难负样本已经是一种常规优化手段了,但是有时候或许需要反其道行之。当前阶段是否需要添加难负样本,需要多少难负样本。这就涉及到更大的范畴了——样本配比,模型训练中的重中之重。
Cross-Encoder
随着对文本匹配效果的进一步追求,交互式的编码器开始登场。模型结构上来看,交互式和双塔式没有本质的区别,大多用的也是Bert极其衍生的模型,区别在于交互式通常会在比较前的阶段就让两个输入进行交互,比如输入时直接把两个文本拼接。这类模型就太多了,BERT系列的模型大多都是这种,这里就先不展开了。
相比双塔式方法还存在模型结构上的一些差距,交互式的方法主要体现在训练方式上,当然模型结构上也存在一定差别,比如迟交互式,接下来就看看ColBERT三连招。
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- https://arxiv.org/pdf/2004.12832,2020 SIGIR.
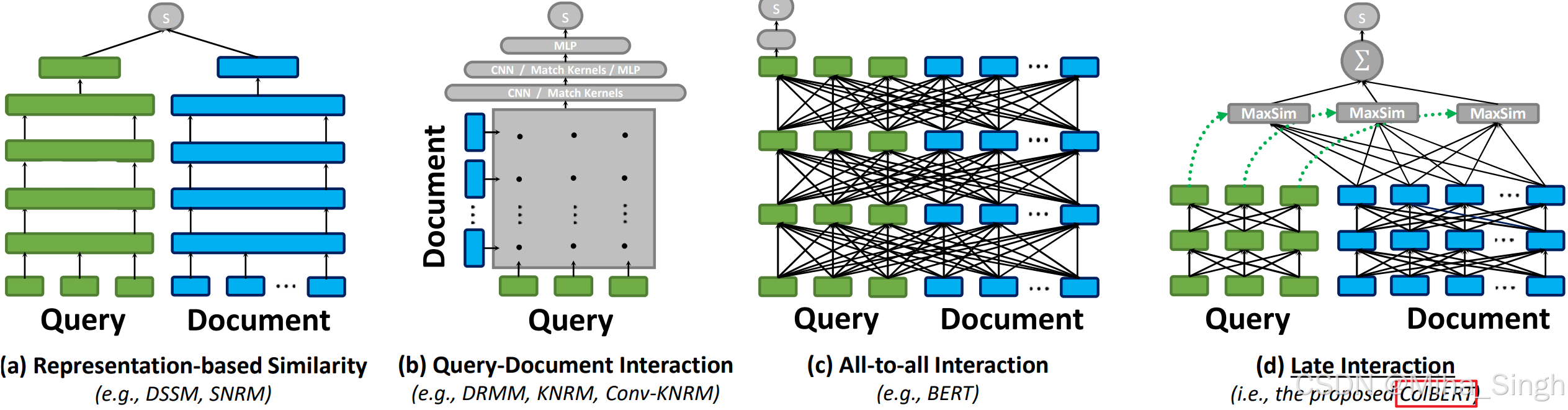
提出了一种基于双塔的迟交互模型,结合双塔模型的效率和交互模型的性能。通过一张图直观对比一下不同文本匹配架构,右一为文中提出的ColBert(contextualized late interaction over BERT):
详细看看ColBert的模型结构:
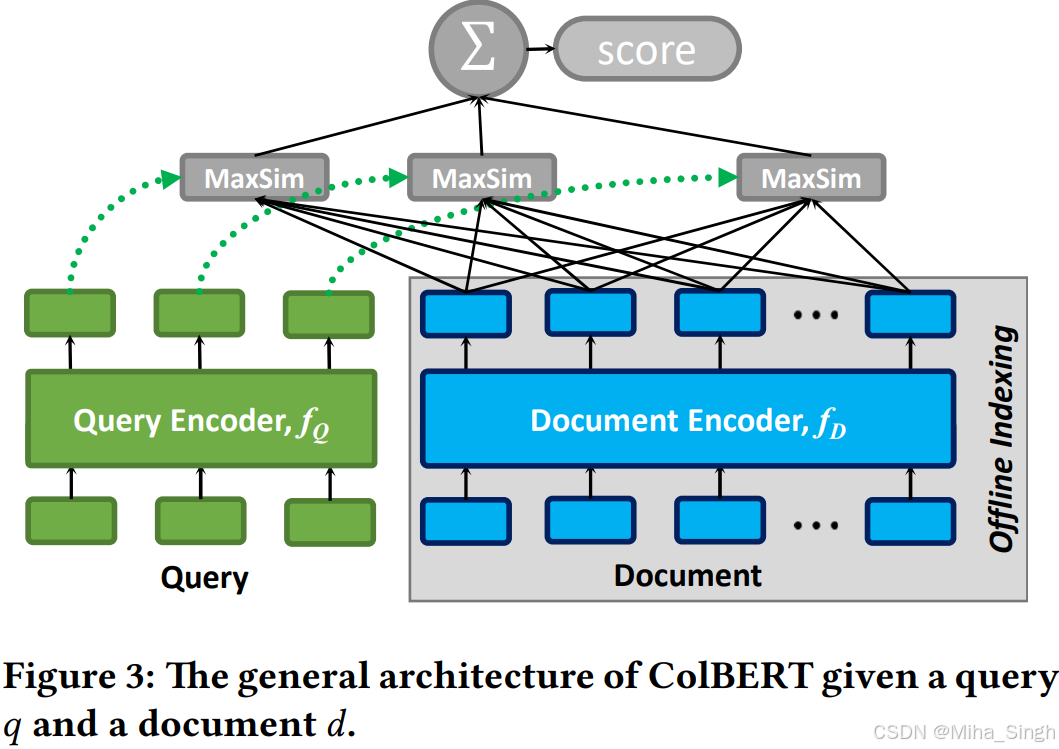
简述一下其核心思想:用query中的每个词 t q t_q tq去文档中软匹配,找到文档中与之最匹配的词 t d t_d td,作为 t q t_q tq与文档的匹配分数,再把所有 t q t_q tq的匹配分数相加作为query和文档的匹配分数。在计算 t q t_q tq与 t d t_d td的匹配时,由于 t d t_d td的嵌入是融合了其上下文信息的,因此二者并不单单只是词之间的匹配,而是融合了上下文信息。
再来看看具体怎么做的。
-
先通过编码器(Bert)对query和文档分别进行编码,获得每个token的嵌入。query和文档可以共享编码器,为了区分输入,编码前在query或文档的开始处分别添加特殊的token,[Q]或[D]。此外还有一些细节上的处理(如嵌入的归一化、过滤掉停用词token、过线性层压缩维度等)。用公式表述一下:
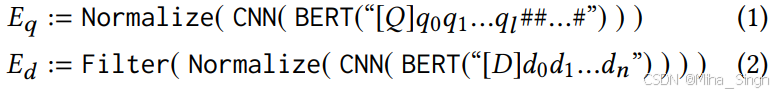
-
迟交互。
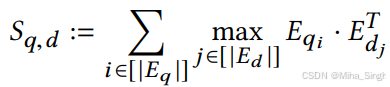
总的来说,ColBert性能接近Bert(论文实验说明),但性能大大提高。有一个问题,如果真的离线计算每个文档中的所有token的嵌入并建索引,这存储成本可行吗,或者直接在线计算?
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
- https://arxiv.org/pdf/2112.01488,2022 NAACL.
ColBERT可能确实存在存储上的问题,这不ColBERTv2就来了。
论文提出了ColBERTv2,对迟交互进行轻量化,实现高效且节省空间的检索。具体的流程或者包括的模块是:
- 模型压缩:ColBERTv2通过残差压缩机制,将每个向量表示为最接近的聚类中心的索引和量化的残差向量。
- 去噪监督:结合了交叉编码器的蒸馏和硬负样本挖掘,以提升检索质量。
- 索引构建:通过k-means聚类选择聚类中心,段落中的每个token的嵌入表示为聚类中心的索引加上一个量化后的残差向量。
- 检索过程:在查询时,通过候选生成、近似“MaxSim”操作和候选段落的排名来完成检索。
ColBERTv2在存储空间上比原始的ColBERT减少了6-10倍。
PLAID: An Efficient Engine for Late Interaction Retrieval
- https://arxiv.org/pdf/2205.09707,2022 CIKM.
论文提出了PLAID(Performance-optimized Late Interaction Driver),可以看作是ColBERTv2的升级版,进一步降低检索的延时。PLAID的核心方法在于利用中心点(centroid)交互机制,将每个段落视为中心点集合,通过中心点剪枝(centroid pruning)和优化的引擎实现延迟的大幅降低。具体流程或包括的模块是:
- 中心点交互(Centroid Interaction):通过将每个token的嵌入向量替换为其最近的中心点,以近似每篇文档的相关性,从而在不加载更大残差的情况下快速筛选出高相关性的段落。
- 中心点剪枝(Centroid Pruning):基于查询向量与所有中心点的距离,提前剪枝掉与查询向量距离较远的中心点ID,从而在检索的早期阶段就减少需要考虑的中心点数量。
- 优化的内核(Fast Kernels):为了加速MaxSim操作和残差解压缩,PLAID实现了定制的C++代码和CUDA内核,以提高数据移动、解压缩和评分组件的效率。
在多个信息检索基准测试中,PLAID在保持检索质量的同时,相较于原始ColBERTv2模型,在GPU上实现了高达7倍的加速,在CPU上实现了高达45倍的加速。
总结
本文对文本匹配任务的几种主流方法进行了梳理,介绍了一些相关的论文工作。经历字面匹配、模糊匹配,目前的主要基于语言模型学习文本表征进行语义匹配,目前很多的工作也已经逐步收敛到训练流程和训练数据的优化。


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









