






ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。它提供了一种增强稳定扩散的方法,在文本到图像生成过程中使用条件输入(如边缘映射、姿势识别等),可以让生成的图像将更接近输入图像,这比传统的图像到图像生成方法有了很大的改进。
在 Stable Diffusion 的基础上使用 ControlNet 就相当于给 Stable Diffusion 加了一个插件用于引导 AI 模型按照输入的条件来生成图,从而实现更精细的生成控制。
要在 Stable Diffusion WebUI 中使用 ControlNet,需要先安装这个扩展,安装步骤如下:
- 1)打开
Extensions栏。 - 2)打开
Extensions栏下的Install from URL栏。 - 3)在
URL for extension's git repository下的输入框中输入https://github.com/Mikubill/sd-webui-controlnet.git。 - 4)点击
Install按钮。 - 5)等待数秒,你应该会收到
Installed into stable-diffusion-webui/extensions/sd-webui-controlnet. Use Installed tab to restart的消息。 - 6)打开
Extensions栏下的Installed栏,点击Check for updates按钮,然后点击Apply and restart UI按钮。后面都可以用这种方式来更新 ControlNet 等扩展。 - 7)重启 Stable Diffusion WebUI。
- 8)从
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main下载后缀名为.pth的 ControlNet 的模型文件,并把它们放到stable-diffusion-webui/extensions/sd-webui-controlnet/models文件夹。 - 9)在
txt2img栏下的 ControlNet 面板中,点击Model下拉框右边的刷新按钮,然后你就能在下拉框中看到模型了。
ControlNet 的能力有很多中,我们下面以 ControlNet V1.1.233 版本为例来分类一一介绍。
1、简稿控图
1.1、Canny 模型:轮廓线稿控图
通过 Canny 模型可以对原始图片进行边缘检测,识别图像内对象的边缘轮廓,从而生成原始图片对应的线稿图。接着,再基于线稿图和提示词来生成具有同样线稿结构的新图,这样就实现了对新图的控制。
接下来,我们来介绍一下如何在 Stable Diffusion WebUI 中通过 ControlNet 扩展来使用这个模型:
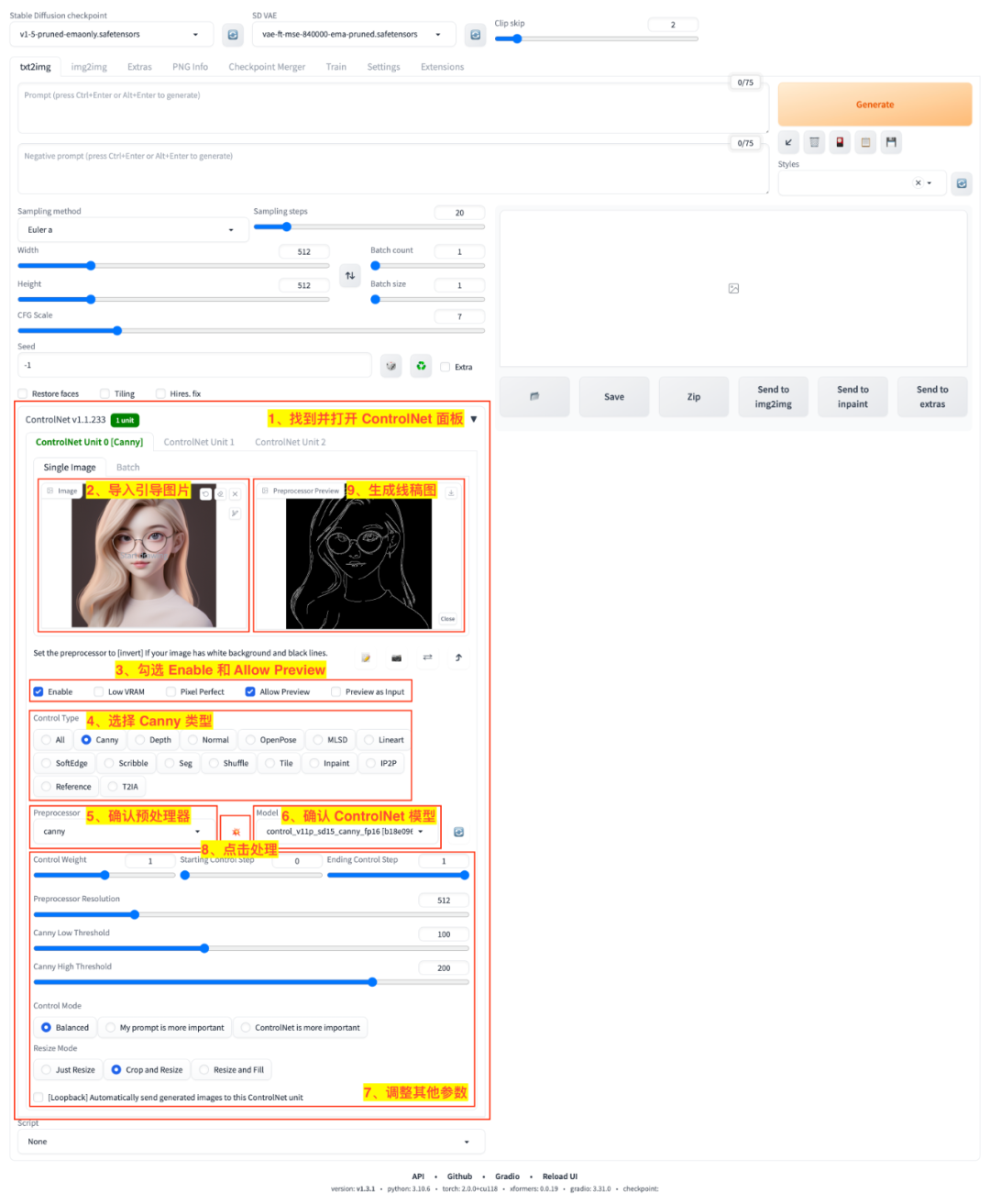
第一步:我们在 WebUI 页面中找到 ControlNet 面板,用引导图来生成轮廓线稿图
整个过程如图所示:
 Canny 模型生成线稿图
Canny 模型生成线稿图
- 1)在 WebUI 页面中找到 ControlNet 面板,点击右上角的三角按钮打开面板;
- 2)在 ControlNet 面板的
引导图输入区导入引导图,引导图对应着我们想要的轮廓; - 3)在多选框列表中勾选
Enable选择框以在后续绘图任务中启用 ControlNet;勾选Allow Preview选择框以开启预处理图的预览; - 4)在
Control Type单选区选择一种控制类型后,WebUI 将为我们匹配对应的预处理器(Preprocessor)和 ControlNet 模型(Model),我们这里选择Canny来确定使用 Canny 预处理器和模型进行后续的预处理和控制生成任务; - 5)
预处理器(Preprocessor)下拉框已经自动匹配了 canny 预处理器,但是这里可能会有其他适用的 canny 预处理器可供选择,可以点开下拉框选择即可; - 6)
ControlNet 模型(Model)下拉框已经自动匹配了 canny 模型,这里也可能会有其他类型的 canny 模型可供选择,可以点开下拉框选择即可; - 7)在下面的参数设置区设置其他参数,我们这里通常用默认值即可;
- 8)点击
💥按钮,启动预处理任务; - 9)在
预处理预览(Preprocessor Preview)区等待轮廓线稿图生成完成。
在上面第 7 步中可以设置的参数有这些:
Control Weight:使用 ControlNet 生成图片的权重占比影响(多个 ControlNet 组合使用时,需要调整权重占比)。Starting Control Step:在生成任务的第几步采样中开始使用 ControlNet。Ending Control Step:在生成任务的第几步采样中停止使用 ControlNet。Preprocessor Resolution:预处理器分辨率,默认 512,数值越高线条越精细,数值越低线条越粗糙。Canny Low Threshold:该数值越高,生成的线稿细节越少,线稿越简单。Canny High Threshold:该数值应该高于Canny Low Threshold。该数值越低,生成的线稿图细节越多,线稿越复杂。Control Mode:控制模式。Balanced表示平衡提示词和 ControlNet 对结果的影响;My prompt is more important表示设置提示词影响更大;ControlNet is more important表示 ControlNet 影响更大。Resize Mode:当预处理线稿图跟生成任务的目标分辨率不一样时采用的裁剪模式,默认使用Crop and Resize。
下面是我们使用的引导图和 ControlNet 生成的轮廓线稿图:
 引导图
引导图
 Canny 线稿图
Canny 线稿图
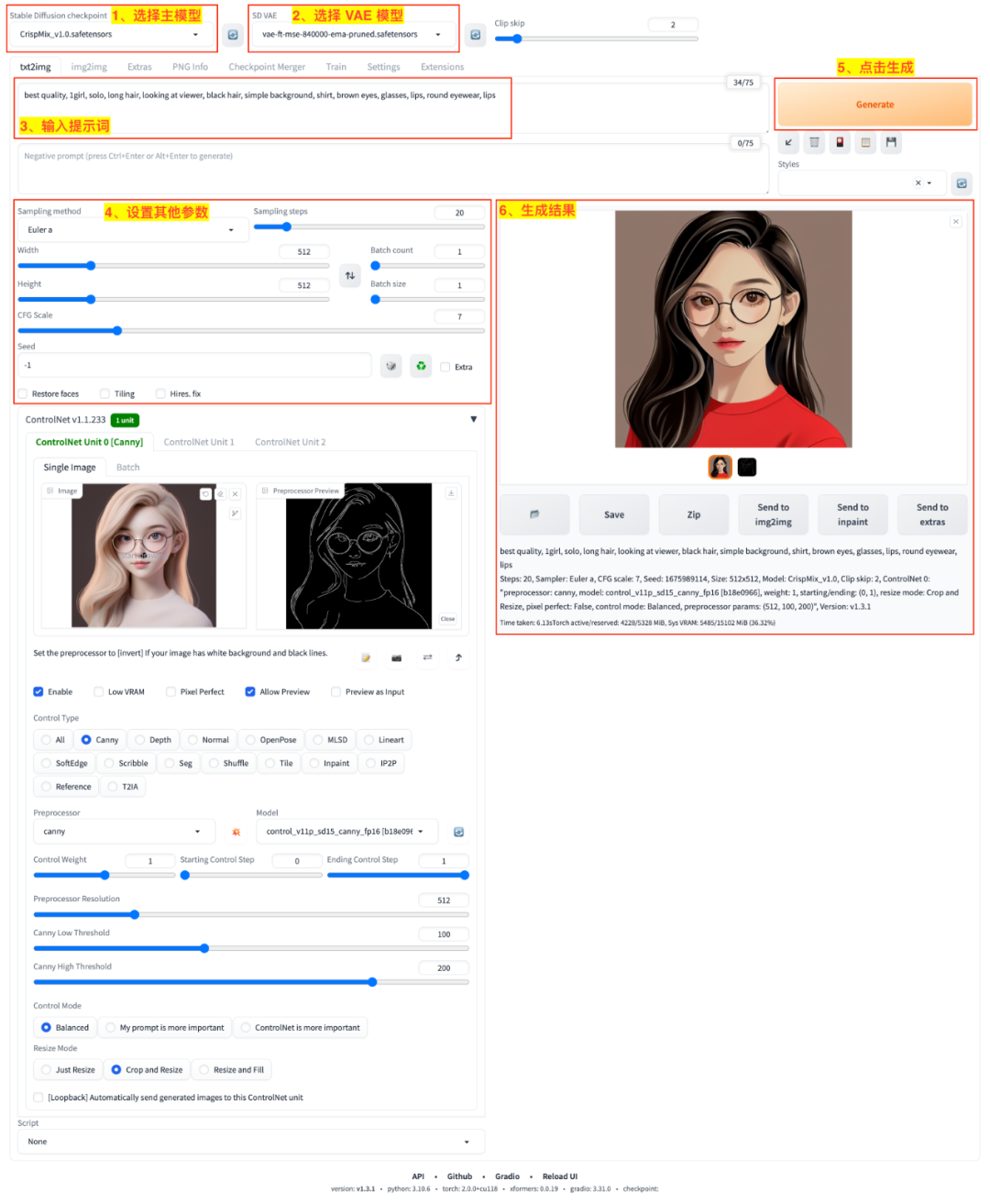
第二步:在轮廓线稿图的基础上,使用文生图生成同样姿势的新图
整个过程如图所示:
 文生图 + Canny 生成新图
文生图 + Canny 生成新图
- 1)选择主模型,这里我们选了
CripsMix_v1.0模型来生成与原图 3D 风格不同的清新插画风格图像; - 2)选择 VAE 模型,这里主要是
CripsMix_v1.0主模型需要配置 VAE 模型来提升图像颜色饱和度; - 3)输入提示词,这里我们指定了要生成
black hair等特征; - 4)设置其他参数;
- 5)点击
Generate启动生成任务; - 6)等待生成结果。
最终的生成结果在结构上保持了和线稿图的一致性,同时又接受了提示词的引导。结果图如下:
 Canny 新图结果
Canny 新图结果
1.2、SoftEdge 模型:柔和线稿控图
通过 SoftEdge 模型也可以对原始图片进行边缘检测,从而基于原始图片生成对应的线稿图,但是边缘更柔和。
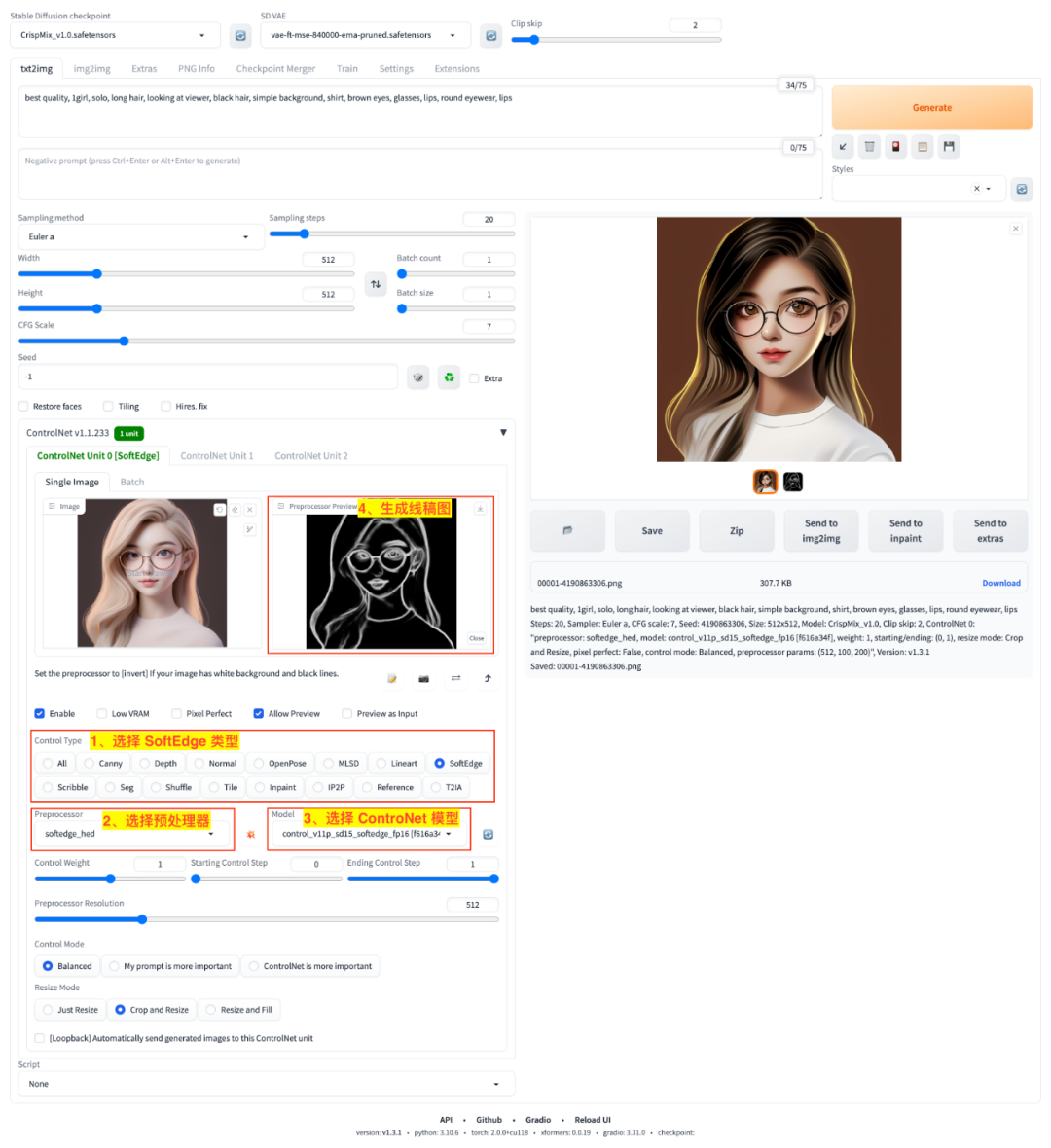
在 Stable Diffusion WebUI 中使用 SoftEdge 模型的过程和上面使用 Canny 模型基本上一致,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型,如图:
 SoftEdge 模型生成线稿图
SoftEdge 模型生成线稿图
- 1)在
Control Type面板中更改为SoftEdge类型; - 2)
预处理器(Preprocessor)下拉框会自动匹配SoftEdge相关的预处理器; - 3)
ControlNet 模型(Model)下拉框会自动匹配SoftEdge相关的模型; - 4)点击
💥按钮生成的线稿图变成了边缘更柔和的线稿图。
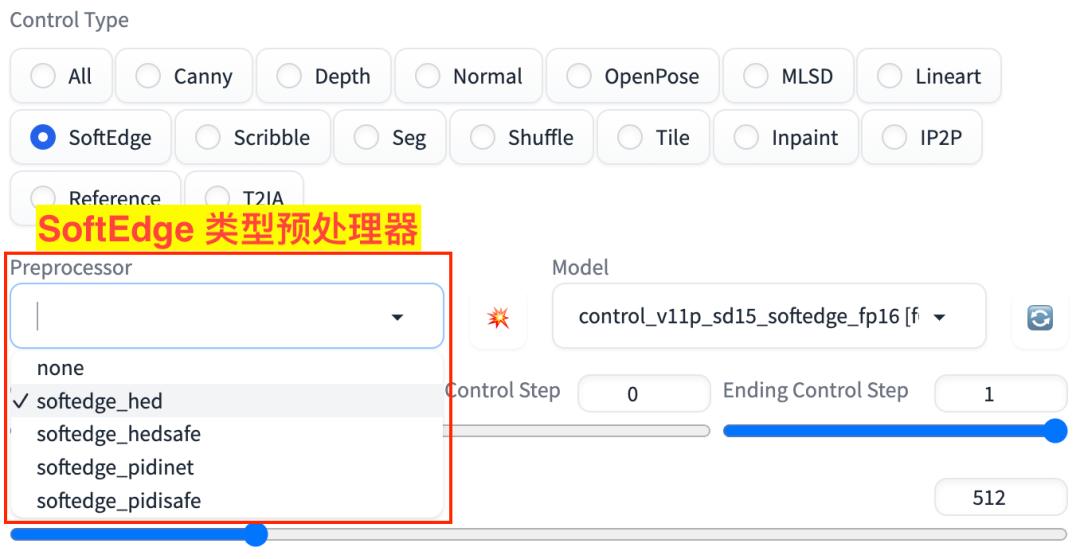
SoftEdge 对应的有 4 个预处理器,如图:
 SoftEdge 预处理器
SoftEdge 预处理器
softedge_hedsoftedge_hedsafesoftedge_pidinetsoftedge_pidisafe
对应的模型是:
control_v11p_sd15_softedge_fp16
按结果质量排序:softedge_hed > softedge_pidinet > softedge_hedsafe > softedge_pidisafe,其中名字结尾是 safe 的预处理器是为了防止生成的图像带有不良内容。SoftEdge 相比 Canny 生成的线稿边缘能够保留更多细节。下面是我们使用 softedge_hed 预处理器配合 control_v11p_sd15_softedge_fp16 模型生成的线稿图:
 SoftEdge 线稿图
SoftEdge 线稿图
剩下的基于 SoftEdge 模型生成新图的流程和使用 Canny 模型是一样的,我们这里就不再赘述了。结果图如下:
 SoftEdge 新图结果
SoftEdge 新图结果
1.3、Lineart 模型:精细线稿控图
Lineart 模型是 ControlNet V1.1 版本新增的模型,Lineart 预处理器也能够提取图像的线稿,并且相比 Canny 线稿要更加精细。
在 Stable Diffusion WebUI 中使用 Lineart 模型的过程和上面使用 Canny 模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Lineart 对应的有 6 个预处理器、2 个模型,如图:
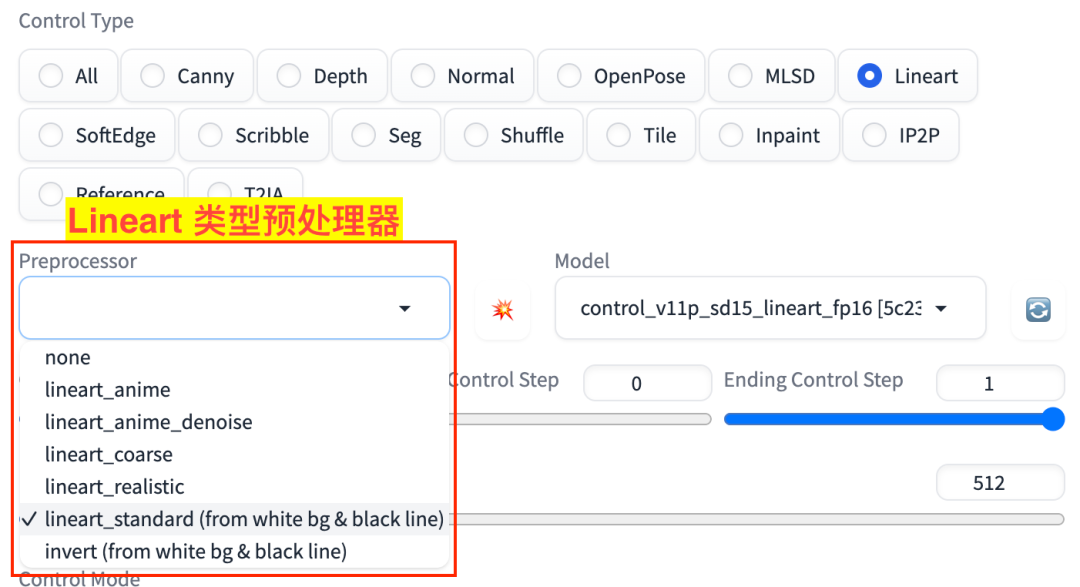 Lineart 预处理器
Lineart 预处理器
lineart_standardlineart_realisticlineart_coarseinvertlineart_animelineart_anime_denoise
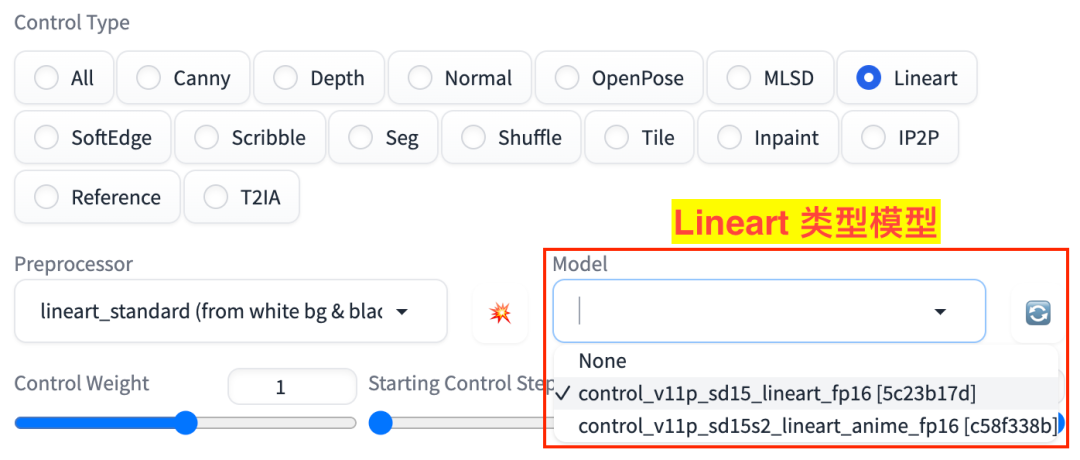 Lineart 模型
Lineart 模型
control_v11p_sd15s2_lineart_fp16control_v11p_sd15s2_lineart_anime_fp16
其中名字含 anime 的预处理器应该和 control_v11p_sd15s2_lineart_anime_fp16 模型搭配使用,其他预处理器则和 control_v11p_sd15s2_lineart_fp16 模型搭配使用。
下面是我们使用 invert 和 lineart_anime 预处理生成的线稿图:
 invert 线稿
invert 线稿
 lineart_anime 线稿
lineart_anime 线稿
下面是我们使用 invert 和 lineart_anime 线稿图控制生成的结果图:
 invert 结果图
invert 结果图
 lineart_anime 结果图
lineart_anime 结果图
其他 Lineart 预处理器大家可以自己试试效果。
1.4、Scribble 模型:涂鸦控图
Scribble 模型可以用来根据手绘涂鸦草图来生成图像,支持在空白画布上直接手绘涂鸦。
在 Stable Diffusion WebUI 中使用 Scribble 模型的过程和上面使用 Canny 模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Scribble 对应的有 4 个预处理器,如图:
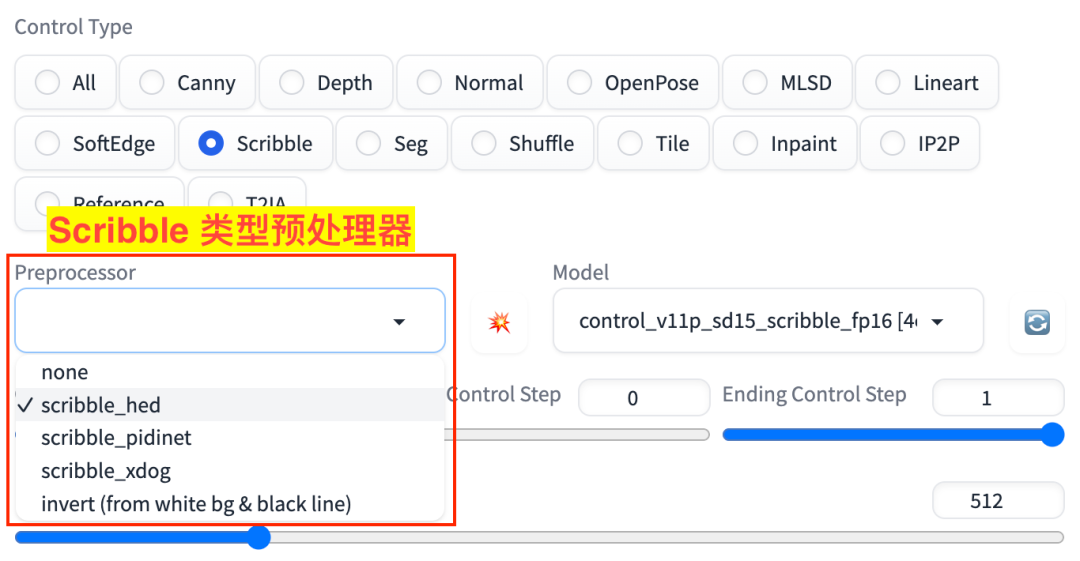 Scribble 预处理器
Scribble 预处理器
scribble_hedscribble_pidinetscribble_xdoginvert
对应的模型是:
control_v11p_sd15_scribble_fp16
下面是我们使用 scribble_hed 预处理生成的预处理图:
 Scribble 预处理图
Scribble 预处理图
下面是基于上面预处理涂鸦稿控制生成的结果图:
 Scribble 结果图
Scribble 结果图
1.5、Depth 模型:深度信息控图
Depth 模型可以提取原始图片中的深度信息,提取原始图片深度结构对应的深度图,这个深度图里,越亮的部分越靠前,越暗的部分越靠后。然后,基于深度图和提示词就可以生成具有同样深度结构的新图了。
在 Stable Diffusion WebUI 中使用 Depth 模型的过程和上面使用 Canny 模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Depth 对应的有 4 个预处理器,如图:
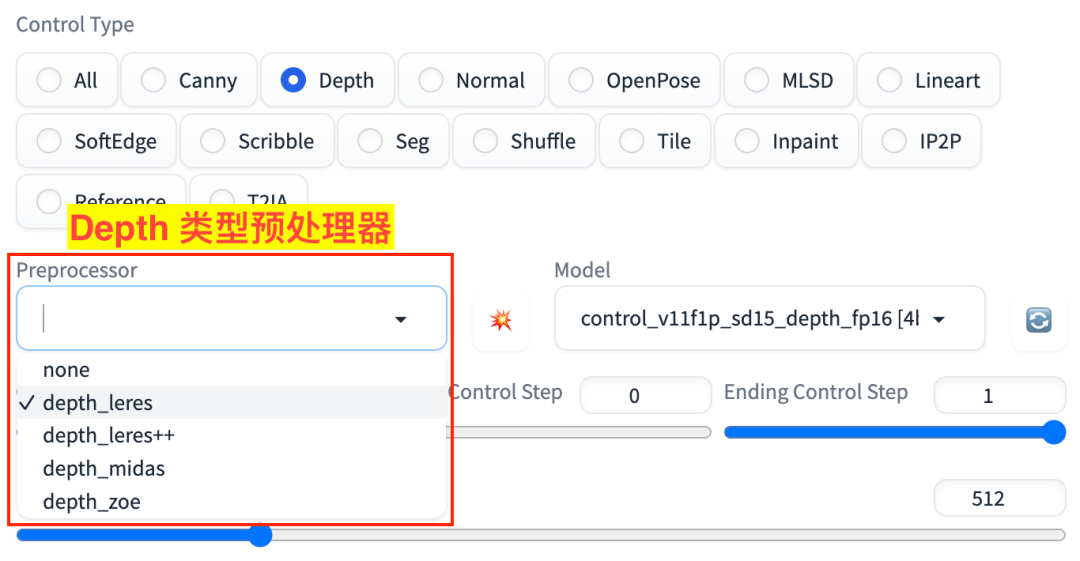 Depth 预处理器
Depth 预处理器
depth_leresdepth_leres++depth_midasdepth_zoe
对应的模型是:
control_v11f1p_sd15_depth_fp16
下面是我们使用 depth_leres 预处理生成的预处理图:
 Depth 预处理图
Depth 预处理图
下面是基于上面预处理深度信息图控制生成的结果图:
 Depth 结果图
Depth 结果图
1.6、Normal 模型:法线信息控图
Normal 模型可以提取原始图片的凹凸信息,生成一张原图的法线贴图,这样便于 AI 给图片内容进行更好的光影处理,它比深度模型对于细节的保留更加的精确。法线贴图在游戏制作领域用的较多,常用于贴在低模上模拟高模的复杂光影效果。
在 Stable Diffusion WebUI 中使用 Normal 模型的过程和上面使用 Canny 模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Normal 对应的有 4 个预处理器,如图:
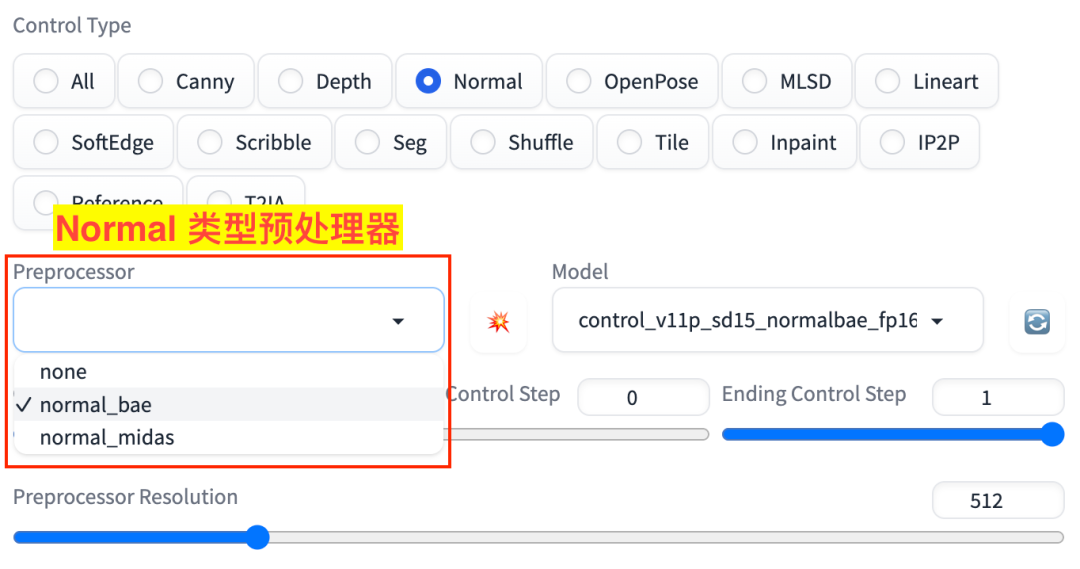 Normal 预处理器
Normal 预处理器
normal_baenormal_midas
对应的模型是:
control_v11p_sd15_normalbae_fp16
下面是我们使用 normal_bae 预处理生成的预处理图:
 Normal 预处理图
Normal 预处理图
下面是基于上面预处理深度信息图控制生成的结果图:
 Normal 结果图
Normal 结果图
1.7、MLSD 模型:建筑线条控图
MLSD 模型通常用来检测建筑物的线条结构和几何形状,生成建筑物线框,再配合提示词、建筑及室内设计风格模型来生成图像。
下面我们将以下面这张毛胚房间图片为引导图来用 MLSD 预处理器对其进行预处理生成建筑房间线框图,然后在其基础上生成房间设计图。
 原图
原图
在 Stable Diffusion WebUI 中使用 MLSD 模型的过程如图:
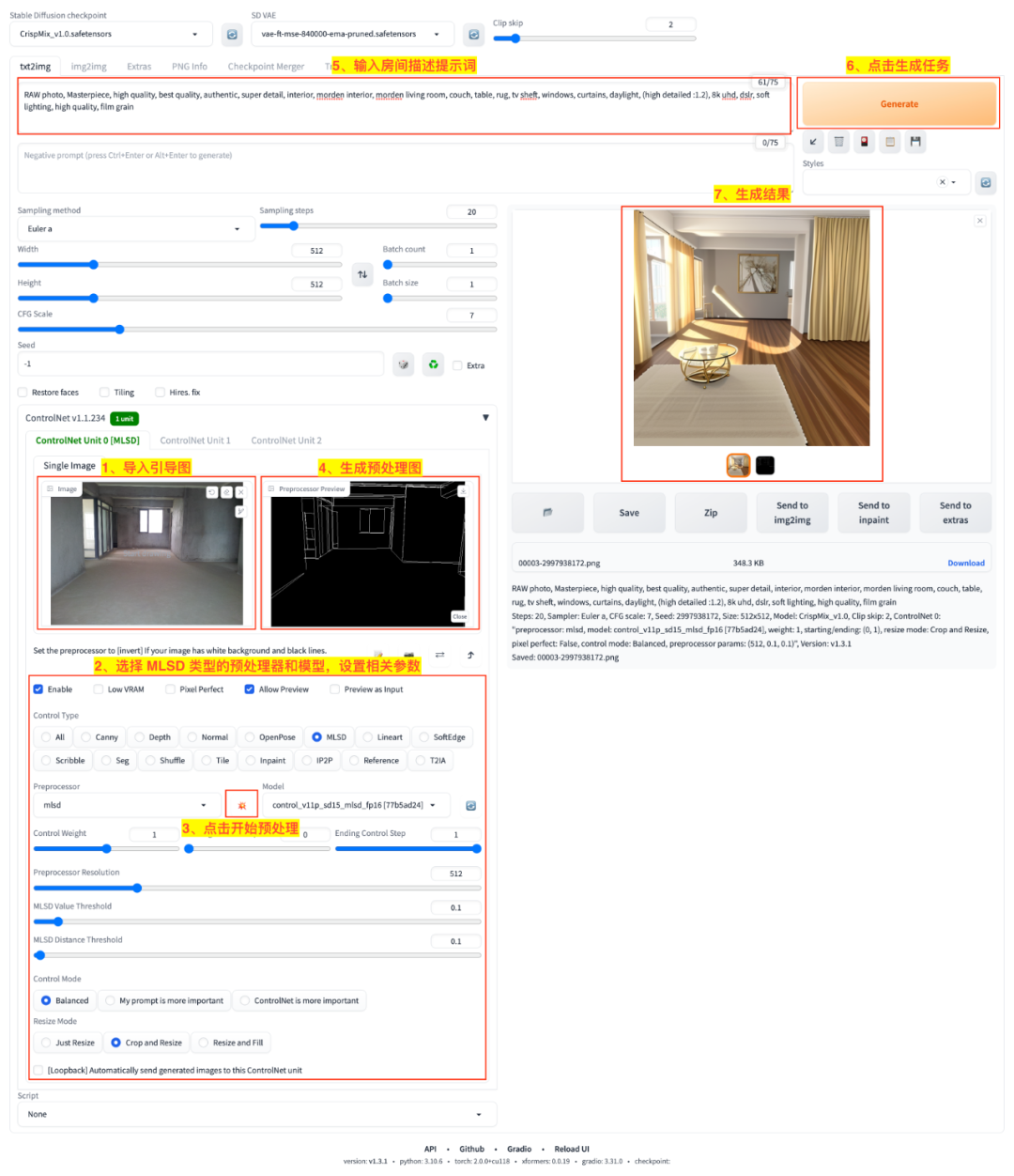 文生图 + MLSD 生成新图
文生图 + MLSD 生成新图
- 1)在 ControlNet 面板的
引导图输入区导入引导图,这里我们用的是一张毛胚房间图片; - 2)在 ControlNet 面板的
参数设置区选择MLSD控制类型、选择对应的预处理器(Preprocessor)和ControlNet 模型(Model)、设置好其他参数,这里预处理器是用的mlsd,模型用的是control_v11p_sd15_mlsd_fp16; - 3)点击
💥按钮启动 ControlNet 预处理; - 4)在
预处理预览(Preprocessor Preview)区等待预处理的建筑线条图生成完成; - 5)在
提示词输入区输入房间描述的提示词; - 6)点击
Generate启动生成任务; - 7)等待生成结果。
可以看到整个流程和上面使用 Canny 及其他模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型,另外提示词则是改成了房间描述。
下面是上面过程中预处理生成的建筑线条图和最终生成任务生成的结果图:
 MLSD 预处理图
MLSD 预处理图
 MLSD 结果图
MLSD 结果图
我们把毛胚房变成了精装房,这个在室内设计领域还是很有用的。
1.8、Seg 模型:分割区块控图
Seg 模型通过语义分割将画面标注为不同的区块颜色和结构,从而控制画面的构图和内容,其中不同颜色代表不同类型的对象。
在 Stable Diffusion WebUI 中使用 Seg 模型的过程和上面使用其他模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Seg 对应的有 3 个预处理器,如图:
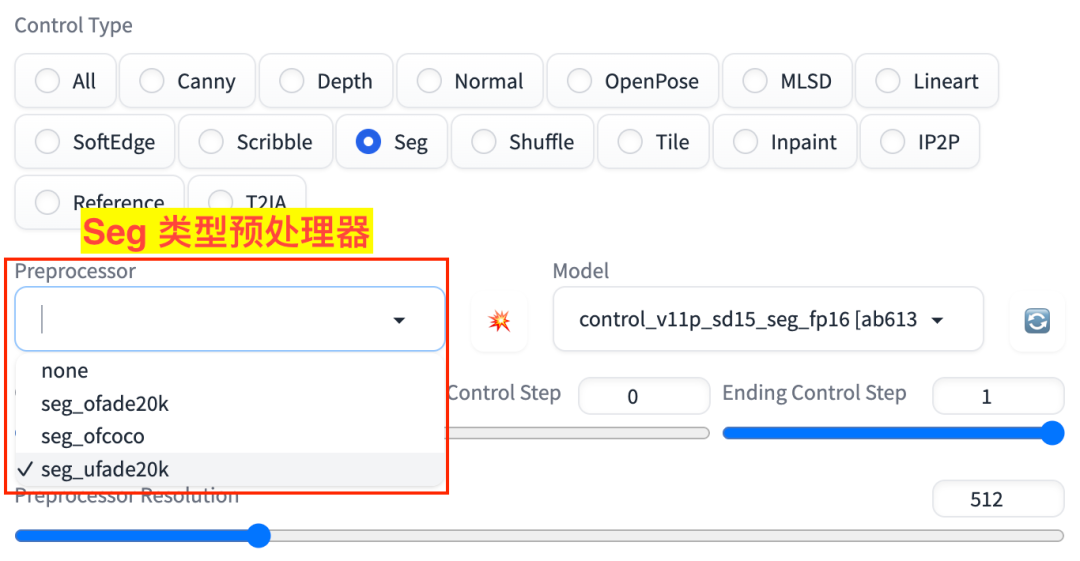 Seg 预处理器
Seg 预处理器
seg_ofade20kseg_ofcocoseg_ufade20k
对应的模型是:
control_v11p_sd15_seg_fp16
下面是原图,以及我们使用 seg_ufade20k 预处理生成的预处理图:
 原图
原图
 Seg 预处理图
Seg 预处理图
下面是基于上面预处理深度信息图控制生成的结果图:
 Seg 结果图
Seg 结果图
2、姿势绑定
2.1、OpenPose 模型:骨骼绑定
OpenPose 模型可以检测原始图片的骨骼形态信息,从而生成一张原图的骨骼姿势图。接着,再基于骨骼姿势图和提示词来生成具有同样骨骼姿势的新图,这样就实现了姿势控制。
在 Stable Diffusion WebUI 中使用 OpenPose 模型的过程和上面使用其他模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
OpenPose 对应的有 5 个预处理器,支持整体身体形态、面部、手指等信息的提取,如图:
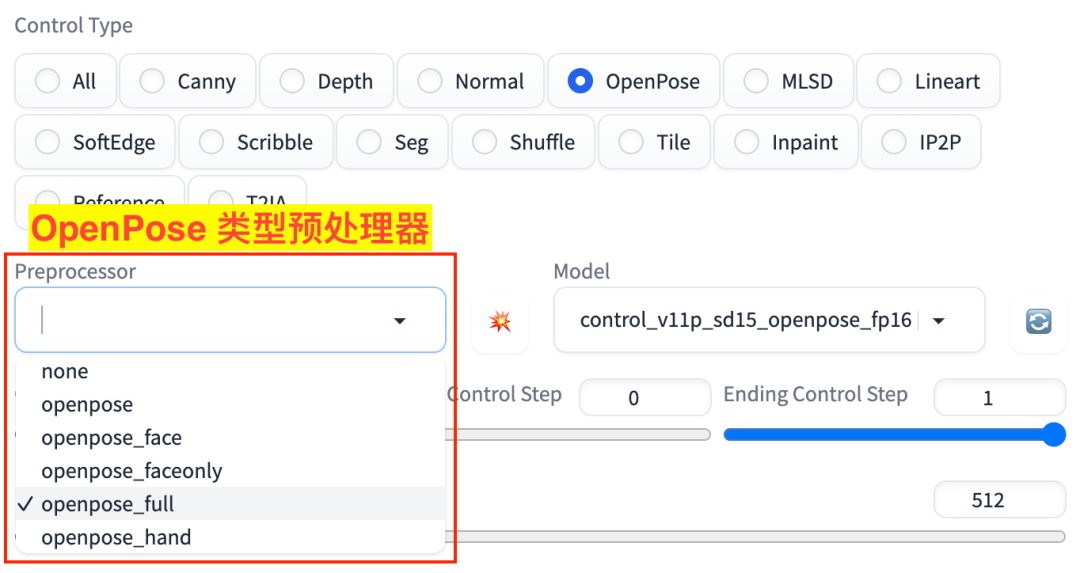 OpenPose 预处理器
OpenPose 预处理器
openposeopenpose_faceopenpose_faceonlyopenpose_fullopenpose_hand
对应的模型是:
control_v11p_sd15_openpose_fp16
下面是原图,以及我们使用 openpose_full 预处理生成的预处理图:
 原图
原图
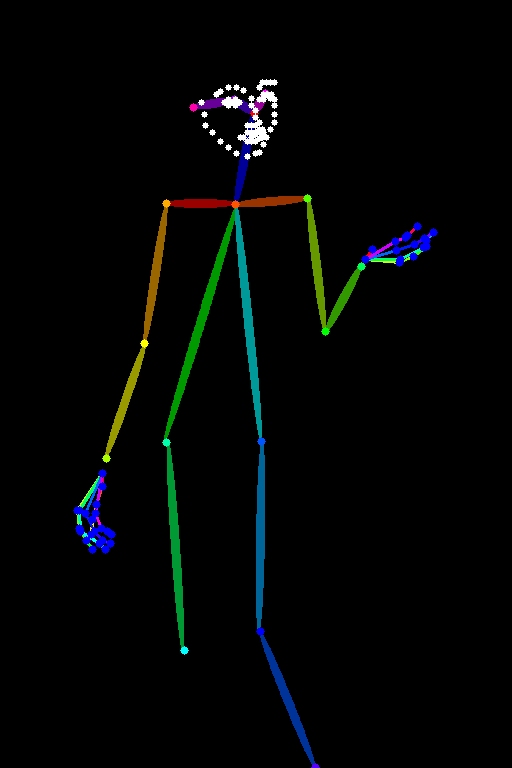 OpenPose 预处理图
OpenPose 预处理图
下面是基于上面预处理骨骼姿势图控制生成的结果图:
 OpenPose 结果图
OpenPose 结果图
3、特征控图
3.1、Shuffle 模型:风格迁移
Shuffle 模型可以提取出引导图的风格,再基于提示词将风格迁移到生成的新图上。
在 Stable Diffusion WebUI 中使用 Shuffle 模型的过程和上面使用其他模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Shuffle 对应的预处理器,如图:
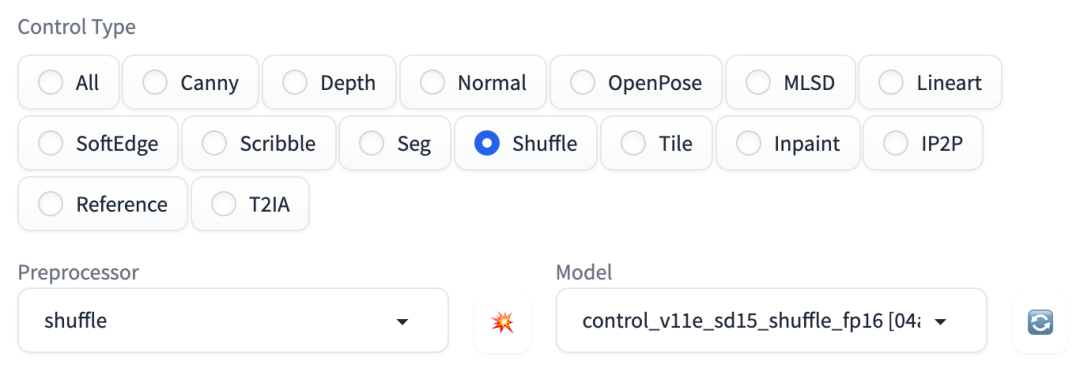 Shuffle 预处理器
Shuffle 预处理器
shuffle
对应的模型是:
control_v11e_sd15_shuffle_fp16
下面是原图,以及我们使用 shuffle 预处理生成的预处理图:
 原图
原图
 Shuffle 预处理图
Shuffle 预处理图
下面是新生成的结果图:
 Shuffle 结果图
Shuffle 结果图
3.2、T2IA Color 模型:颜色继承
T2IA Color 模型可以用网格的方式提取引导图的颜色分布图,然后在颜色分布的基础上结合提示词去将生成新图,从而控制新图保持对应的颜色分布。
在 Stable Diffusion WebUI 中使用 T2IA Color 模型的过程和上面使用其他模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
T2IA Color 对应的预处理器是 t2ia_color_grid、模型是 t2iadapter_color_sd14v1,如图:
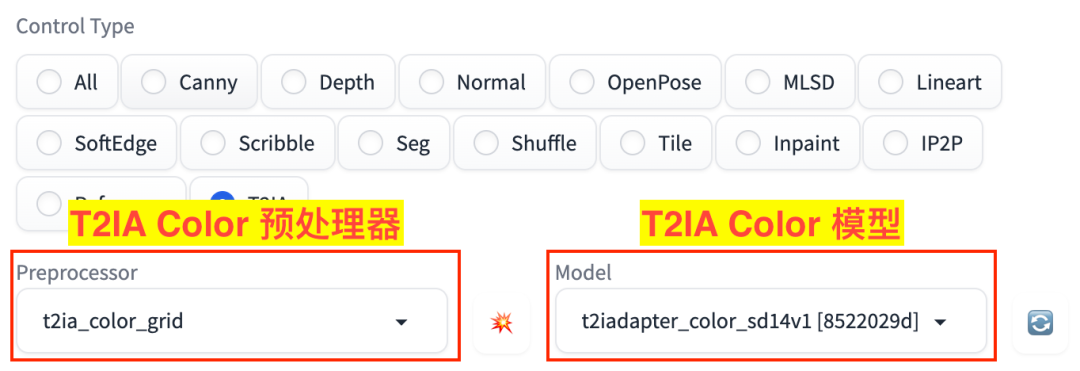 T2IA Color 预处理器和模型
T2IA Color 预处理器和模型
下面是原图,以及我们使用 t2ia_color_grid 预处理生成的预处理图:
 原图
原图
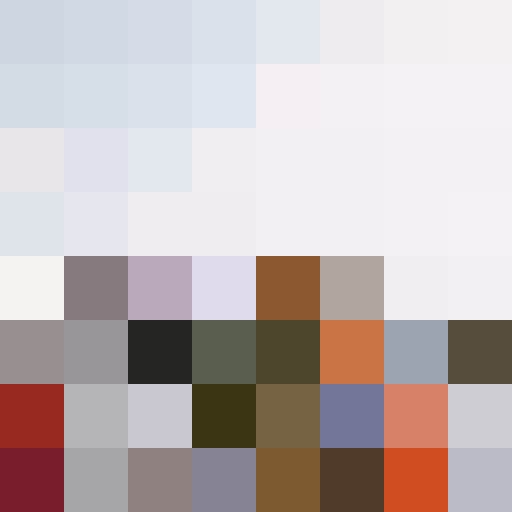 T2IA Color 预处理图
T2IA Color 预处理图
下面是基于上面预处理的颜色分布图控制生成的结果图:
 T2IA Color 结果图
T2IA Color 结果图
3.3、Reference:相似重现
Reference 预处理器不使用模型,它可以在新图中尽量还原原图中的角色,作用和 Seed 有点像。
在 Stable Diffusion WebUI 中使用 Reference 预处理器时不需要选择模型,如图:
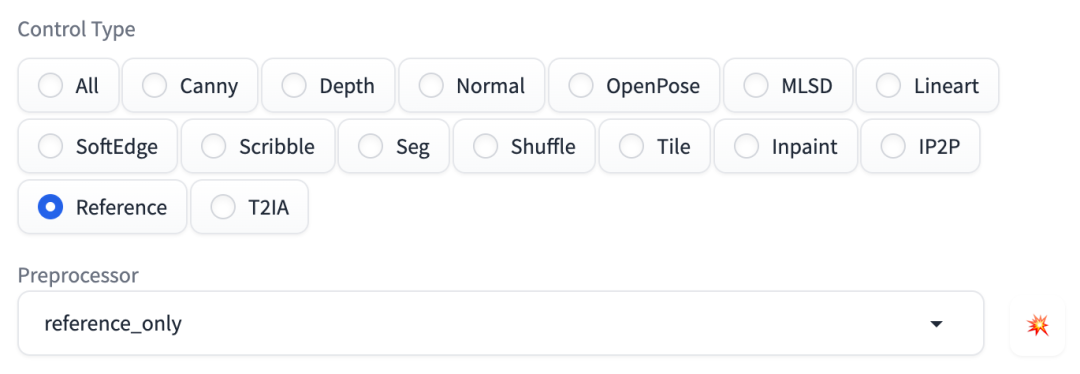 Reference 预处理器
Reference 预处理器
下面是原图,以及我们使用 reference_only 预处理器结合提示词生成的新图:
原图
 Reference 结果图
Reference 结果图
原图和新图在人脸上会有一些相似。
4、细节增强
4.1、Tile 模型:细节增强
Tile 模型可以在原图的结构基础上对图像的细节进行增强。
在 Stable Diffusion WebUI 中使用 Tile 模型的过程和上面大部分模型也是基本一致的,主要的区别就是更换了 Control Type 以及对应的预处理算法和模型。
Tile 对应的有 3 个预处理器,如图:
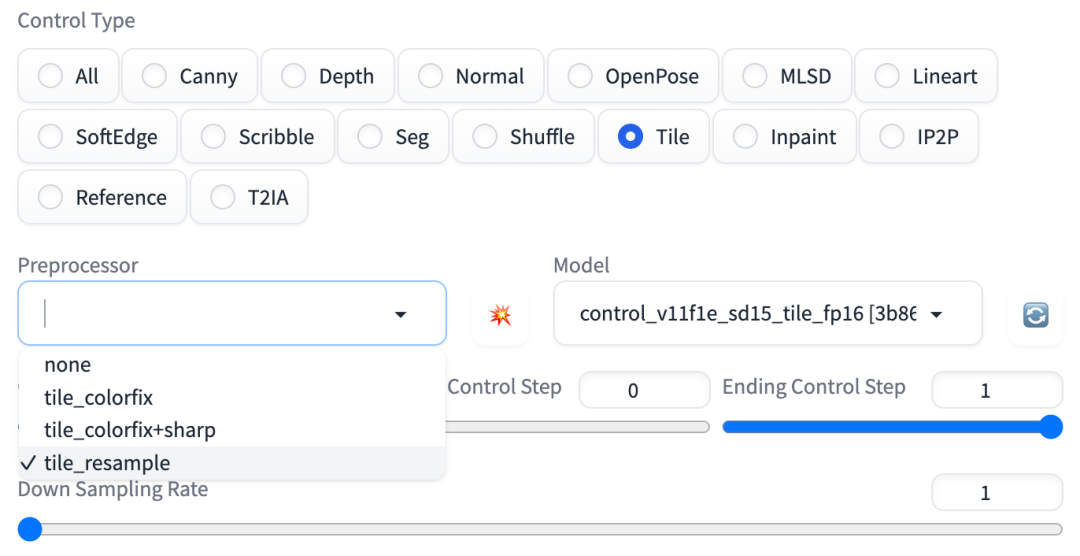 Tile 预处理器
Tile 预处理器
tile_resampletile_colorfixtile_colorfix+sharp
对应的模型是:
control_v11f1e_sd15_tile_fp16
下面是原图:
 原图
原图
Tile 的是在原图的基础上增加更多细节,下面是生成的结果图:
 Tile 结果图
Tile 结果图
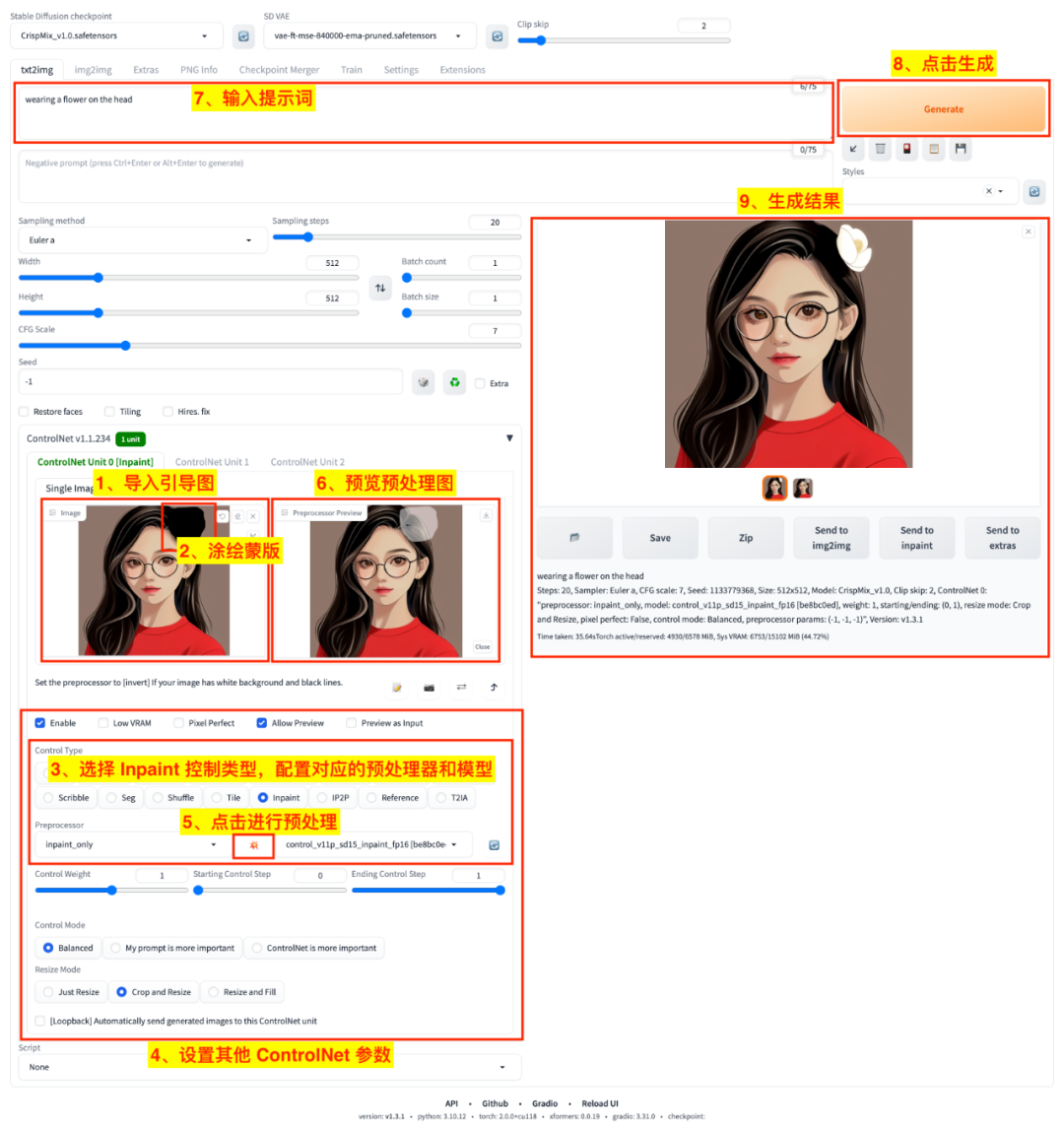
4.2、Inpaint 模型:图像重绘
Inpaint 模型可以在原图的基础上添加蒙版,并对蒙版部分进行重绘。与我们在前面《图像局部重绘》一节介绍的功能类似。
在 Stable Diffusion WebUI 中使用 Inpaint 模型的过程如图:
 文生图 + Inpaint 生成新图
文生图 + Inpaint 生成新图
- 1)在 ControlNet 面板的
引导图输入区导入引导图; - 2)在引导图上涂绘出蒙版区域,我们将对蒙版区域进行重绘;
- 3)在
Control Type单选区选择Inpaint类型,并配置对应的预处理器(Preprocessor)和 ControlNet 模型(Model); - 4)在 ControlNet 面板中设置其他相关参数;
- 5)点击
💥按钮,启动预处理任务; - 6)在
预处理预览(Preprocessor Preview)区等待生成预处理图; - 7)在
提示词输入区输入提示词,我们这里输入wearing a flower on the head预期在女孩头上戴上一朵花; - 8)点击
Generate按钮启动生成任务; - 9)等待生成结果。
这里的 Inpaint 类型的预处理器有 3 种,如图:
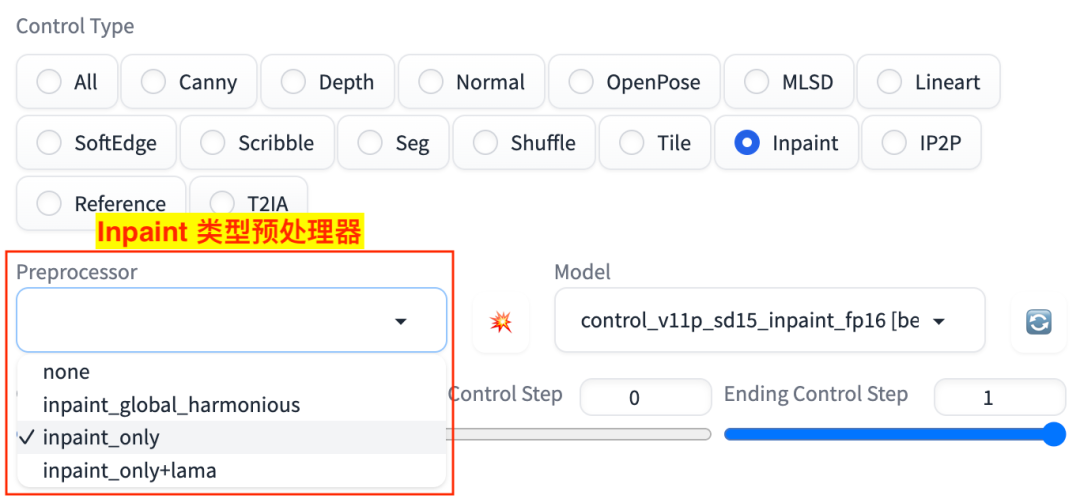 Inpaint 预处理器
Inpaint 预处理器
inpaint_onlyinpaint_only+lamainpaint_global_harmonious
对应的模型是:
control_v11p_sd15_inpaint_fp16
下面分别是上述过程中用到的原图、生成的预处理图和最终生成的结果图:
原图
 Inpaint 预处理图
Inpaint 预处理图
 Inpaint 结果图
Inpaint 结果图
4.3、IP2P 模型:图片指令
IP2P 模型可以在原图的基础上通过提示词指令对其增加更多细节元素。
在 Stable Diffusion WebUI 中使用 IP2P 模型的过程和上面使用其他模型有一些不同:
- IP2P 模型不需要预处理器;
- 在
图生图(img2img)中使用 IP2P 模型效果更好; - 使用 IP2P 模型时,需要使用格式如
make it ...的指令式提示词来对图片增加细节元素。
下图是在图生图(img2img)中使用 IP2P 模型的流程:
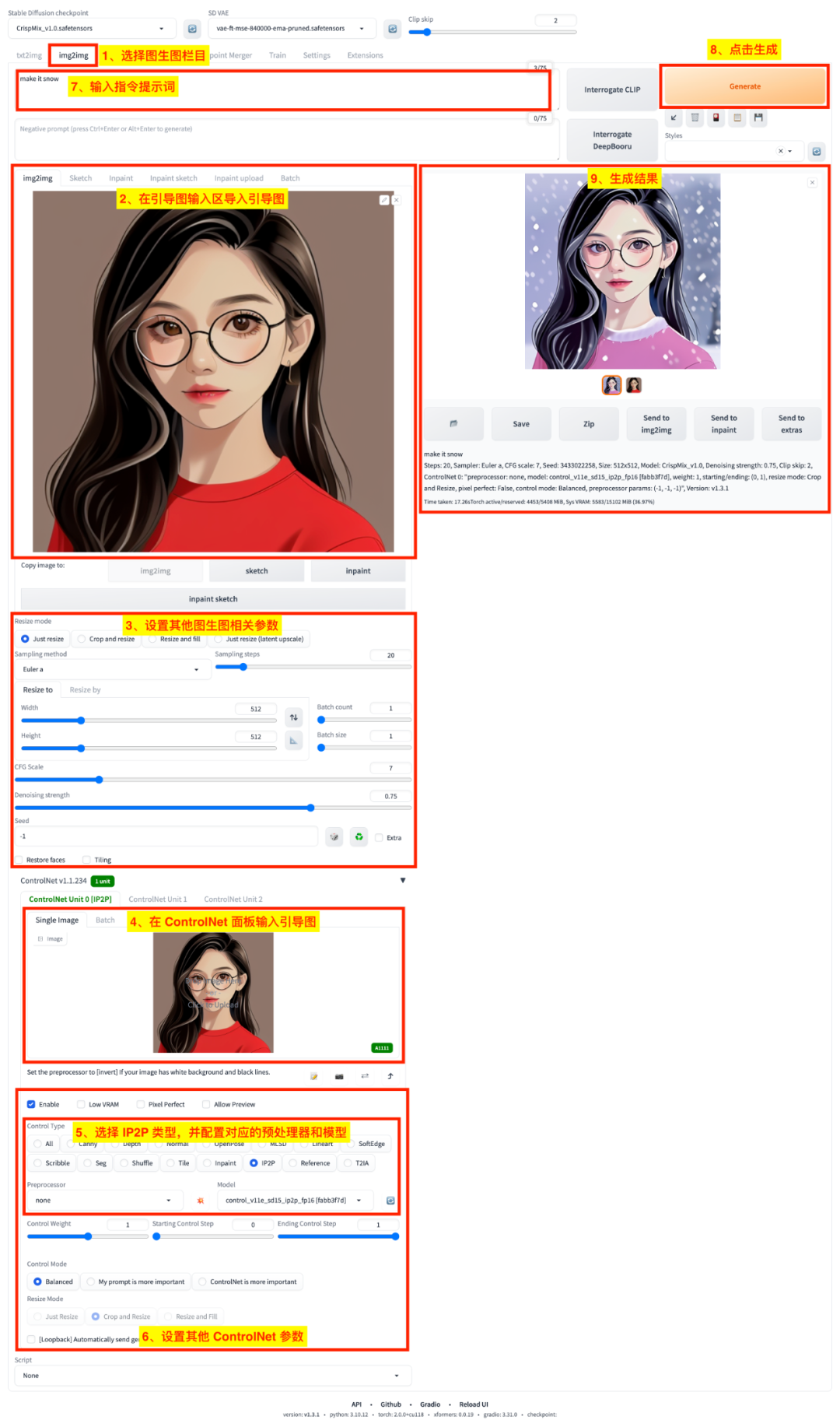 图生图 + IP2P 生成新图
图生图 + IP2P 生成新图
- 1)选择
图生图(img2img)栏目; - 2)在
img2img子栏目输入引导图; - 3)设置其他图生图相关参数;
- 4)在 ControlNet 面板的
引导图输入区导入引导图,这里用的引导图与第 2 步一样; - 5)在
Control Type单选区选择IP2P类型,这里不需要配置的预处理器(Preprocessor),只用配置 ControlNet 模型(Model)即可; - 6)在 ControlNet 面板中设置其他相关参数;
- 7)在
提示词输入区输入提示词,我们这里输入make it snow指令提示词预期在原图中加入下雪效果; - 8)点击
Generate按钮启动生成任务; - 9)等待生成结果。
下面分别是上述过程中用到的原图和最终生成的结果图:
原图
 IP2P 结果图
IP2P 结果图
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









