







一、实验要求
利用语料eng和chn,分别计算英语字母、英语单词、汉字、汉语词的熵,并和已公开结果比较(如英语字母熵4.03,汉字熵9.65),并思考汉语的熵对汉语编码/处理的影响。
二、计算英语字母、英语单词的熵
1.代码实现
def count_letters(file_path):
# 定义一个字典来存储每个字母的出现次数
letter_counts = {letter: 0 for letter in string.ascii_letters}
# 打开文件并逐行读取
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 对于每一行,逐个字符检查是否是字母,如果是,增加计数器
for char in line:
if char in letter_counts:
letter_counts[char] += 1
# 计算字母的总频数
total_letter_count = sum(letter_counts.values())
# 计算字母的信息熵
letter_entropy = 0
for count in letter_counts.values():
if count > 0:
frequency = count / total_letter_count
letter_entropy -= frequency * math.log2(frequency)
return total_letter_count, letter_entropy
# 使用空格分割单词,去重后统计单词数量
words = content.split()
word_count = len(set(words))
# 统计单词出现的频数
word_freq = collections.Counter(words)
# 计算总频数
total_freq = sum(word_freq.values())
# 计算单词熵
word_entropy = 0
for freq in word_freq.values():
probability = freq / total_freq
word_entropy -= probability * math.log2(probability)
2.代码运行结果
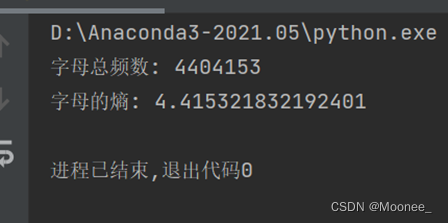
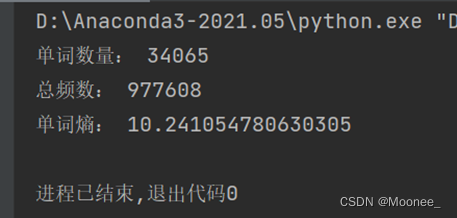
计算得出的英语字母熵为4.42,比4.03略大。可能是因为语料中包含了更多的不常见单词或者拼写错误的单词,这些单词的出现频率较低,但是对于计算熵值来说却具有较大的影响。
三、计算汉字、汉语词的熵
1.代码实现
# 计算信息熵的函数
def entropy(freq_dict, total_freq):
e = 0
for freq in freq_dict.values():
p = freq / total_freq
e -= p * math.log2(p)
return e
# 读取文本文件
filename = "chn" # 修改文件路径
with open(filename, "r", encoding="utf-8") as f:
text = f.read()
# 统计汉字数量和总频数
hanzi_dict = {}
total_hanzi_freq = 0
for char in text:
if '\u4e00' <= char <= '\u9fff': # 判断是否为汉字
hanzi_dict[char] = hanzi_dict.get(char, 0) + 1
total_hanzi_freq += 1
# 计算中文词语信息熵
word_entropy = entropy(word_dict, total_word_freq)
2.代码运行结果
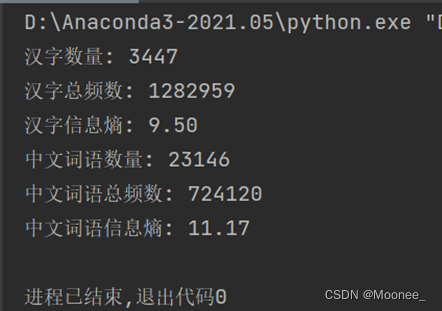
计算得出的汉字熵为9.50,比9.65略小,可能是因为语料库不够大或者不够多样化,导致计算出来的熵值偏低。
四、思考汉语的熵对汉语编码/处理的影响
熵是信息论中用来衡量信息量的一个指标,它表示信息的不确定性或随机性。汉语的熵比较高,因为汉语中有很多汉字,每个汉字都有很多不同的意思,而且汉字之间的组合方式也非常多样化。这就导致了在对汉语进行编码时,需要使用更多的编码位数来表示每个汉字,从而增加了编码的复杂度和长度。这也是为什么在计算机中,汉字通常需要使用Unicode编码来表示,而不是像英文字母那样只需要使用ASCII码。
汉语的熵对汉语编码的影响是促进了汉语信息的丰富性和多样性。由于汉语的熵比较高,汉语可以表达更多的信息和意义,这使得汉语成为了一种非常丰富和多样化的语言。在信息传递和交流方面,汉语的熵也使得汉语更加灵活和适应性强,可以更好地满足人们的需求。
但汉语的熵增加了编码的复杂度和长度,使得汉语在计算机和通信领域的应用受到了一定的限制,也增加了汉语信息处理的难度和成本。



















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











