







上几篇博文讲的都是关于抓取静态网页的相关内容,但是现在市面上绝大多数主流网站都在其重要功能中依赖JavaScript,使用JavaScript时,不再是加载后立即下载所有页面内容,这样就会造成许多网页在浏览器中展示的内容不会出现在html源码中。这时候再用前几篇博文中介绍的办法爬取来数据,得到的数据肯定为空。本篇博文将主要介绍对如动态网页应该如何进行爬取。
这里我们将介绍两种办法来抓取动态网页数据
① JavaScript逆向工程
② 渲染JavaScript
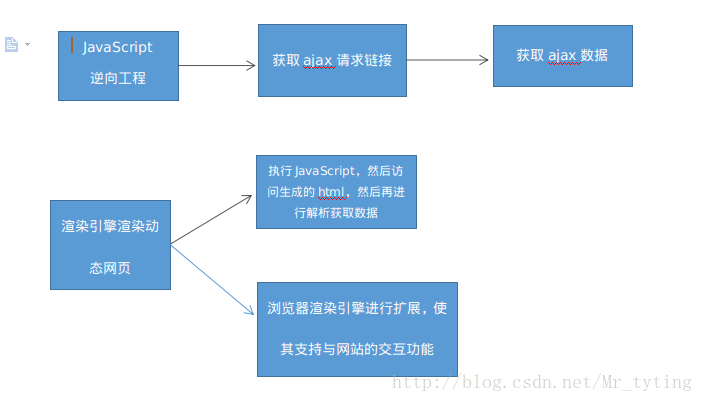
本篇博文主要思路如下图:
打开http://example.webscraping.com/places/default/search,我们在name框输入A。得到搜索结果页面如下:
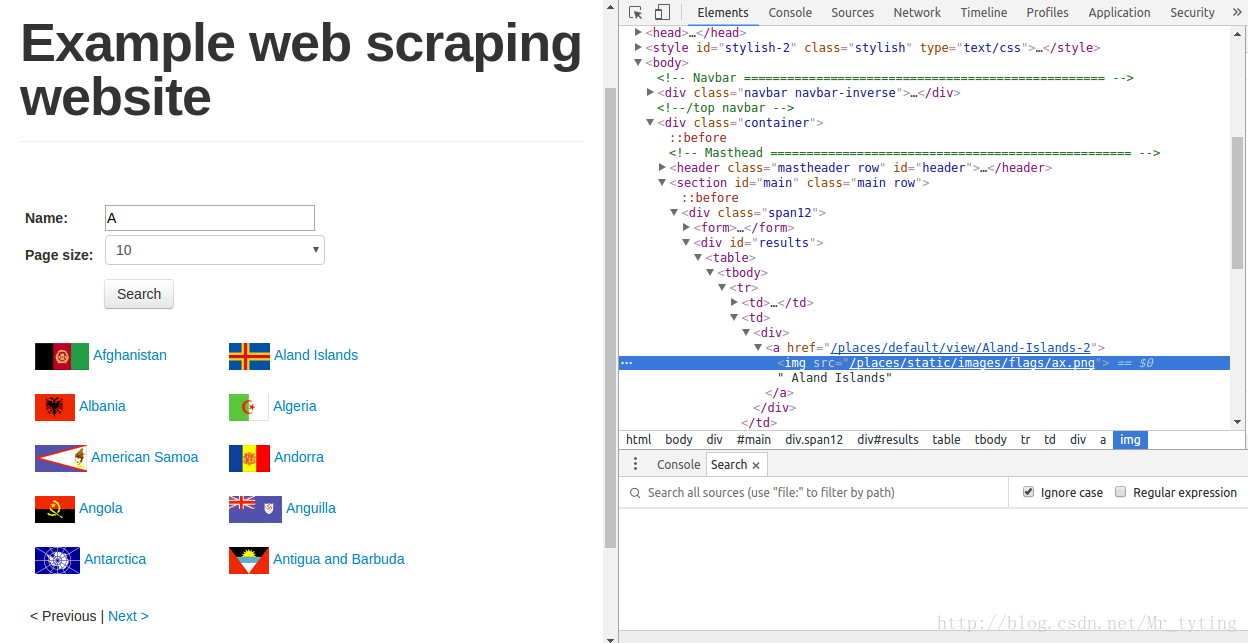
如右侧可以看出谷歌浏览器的控制生成了对应结果。那么我们用前几篇博文介绍的方法来对countries(国家名称)数据进行爬取试试。
import lxml.html
from new_chapter3.downloader import Downloader
D=Downloader()
html=D('http://example.webscraping.com/places/default/search')
tree=lxml.html.fromstring(html)
print tree.cssselect('div#result a')输出结果

那么为什么抓取失败了呢?打开网页源码可以帮助我们了解失败的原因。

可以清楚的看出,我们要抓取的内容在源码中实际为空!!!可以看出谷歌浏览器控制台显示的是网页当前的状态,也就是使用JavaScript动态加载完搜索结果之后的网页。而这个网页不会出现在html源码中。
这里需要介绍下ajax:
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。
AJAX = 异步 JavaScript和XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必须重载整个网页页面。
对动态网页的逆向工程
某些网页数据是通过JavaScript动态加载的,要想抓取该数据,我们需要了解网页是如何加载该数据的,该过程称为逆向工程。这里我们使用谷歌浏览器,再次打开http://example.webscraping.com/places/default/search,按F12进入开发者模式,在name框输入字母A,点击搜索。然后在点击右边控制台Network,观察其XHR下的数据
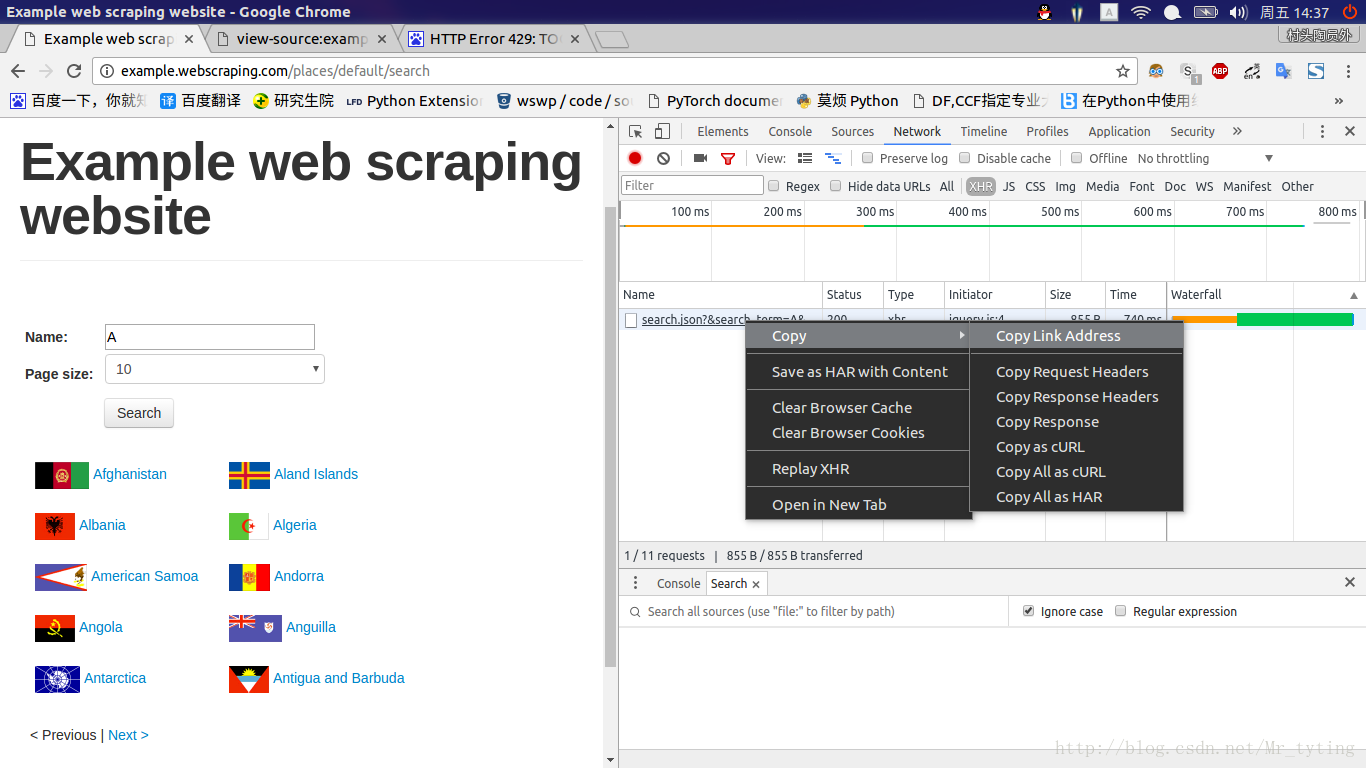
可以看到当执行一次搜索以后,将会产生一个ajax请求,该ajax数据可以直接下载。通过复制链接我们可以得到http://example.webscraping.com/places/ajax/search.json?&search_term=A&page_size=10&page=0
我们直接下载该链接对应的网页看看:
from new_chapter3.downloader import Downloader
import json
D=Downloader()
## 这里每搜索后的结果中,每个页面5个国家信息,显示的是第一个页面,也就是首先的5个国家。
html=D('http://example.webscraping.com/places/ajax/search.json?&search_term=a&page_size=5&page=0')
print json.loads(html)打印结果:

结果中的records中有page_size个国家信息。
通过搜索字母表中的每个字母,可以抓取下所有的国家信息。然后将其结果存储到表格中。
#coding:utf-8
import json
import string
import new_chapter3.downloader as Downloader
import new_chapter3.mongo_cache as MongoCache
def main():
template_url = 'http://example.webscraping.com/places/ajax/search.json?&search_term={}&page_size=10&page={}'
countries = set()
cache=MongoCache.MongoCache()
cache.clear()
download = Downloader.Downloader(cache=cache)
for letter in string.lowercase:
page = 0
while True:
html = download(template_url.format(letter,page))
try:
ajax = json.loads(html)
except ValueError as e:
print e
ajax = None
else:
for record in ajax['records']:
countries.add(record['country'])
page += 1
if ajax is None or page >= ajax['num_pages']:
break
open('countries.txt', 'w').write('\n'.join(sorted(countries)))
if __name__ == '__main__':
main()
这里面需要注意的是,下载这么多网页要注意延迟一会,否则会报too many requests。不过这个download函数里面已经有同一域名内下载不同网页延迟的功能。
这里我们依次遍历了26个字母,这个办法抓取所有数据显得比较笨,我们可以用.来代替所有字母,这样就可以一次性获取到所有数据。
import json
import csv
import new_chapter3.downloader as downloader
def main():
writer = csv.writer(open('countries2.csv', 'w'))
D = downloader.Downloader()
html = D('http://example.webscraping.com/places/ajax/search.json?&search_term=.&page_size=1000&page=0')
ajax = json.loads(html)
for record in ajax['records']:
writer.writerow([record['country']])
if __name__ == '__main__':
main()
比起上面26个字母慢慢抓取的办法,这种办法不仅代码量少,而且很快。
渲染动态网页
有些网站很复杂,不太容易对其进行逆向工程进行解析来获取数据。我们可以利用浏览器渲染引擎来对网页进行渲染。这种渲染引擎是在浏览器在显示网页时解析html,应用css样式并执行JavaScript语句的部分。这里使用Webkit渲染引擎,通过QT框架可以获取该引擎的python接口。
为了确认Webkit能执行JavaScript语句,打开http://example.webscraping.com/places/default/dynamic这个简单示例,其网页源码为:

我们先尝试用传统方法下载原始html来获取数据:
import lxml.html
from new_chapter3.downloader import Downloader
import json
D=Downloader()
html=D('http://example.webscraping.com/places/default/dynamic')
tree=lxml.html.fromstring(html)
print "结果为: ",tree.cssselect('#result')[0].text_content()打印结果为:

结果为空,解析其html获取不了JavaScript内的数据。我们再尝试使用webkit来获取数据:
#coding:utf-8
try:
from PySide.QtGui import *
from PySide.QtCore import *
from PySide.QtWebKit import *
except ImportError:
from PyQt4.QtGui import *
from PyQt4.QtCore import *
from PyQt4.QtWebKit import *
import lxml.html
import new_chapter3.downloader as downloader
def direct_download(url):
download = downloader.Downloader()
return download(url)
def webkit_download(url):
##初始化QApplication对象,在其他QT对象完成初始化之前。QT框架需要先创建该对象
app = QApplication([])
##创建QWebView对象,该对象是Web文档的容器
webview = QWebView()
webview.loadFinished.connect(app.quit)
webview.load(url)
app.exec_() # delay here until download finished
return webview.page().mainFrame().toHtml()
def parse(html):
tree = lxml.html.fromstring(html)
print tree.cssselect('#result')[0].text_content()
def main():
url = 'http://example.webscraping.com/places/default/dynamic'
#parse(direct_download(url))
parse(webkit_download(url))
return
print len(r.html)
if __name__ == '__main__':
main()打印结果:

成功获取到JavaScript内数据,这种方式就是利用webKit执行JavaScript,然后访问生成的html,然后再进行解析获取数据。
上面介绍的浏览器引擎还不能抓取搜索页面,为此我们还需要对浏览器渲染引擎进行扩展,使其支持与网站的交互功能。
对与上面的ajax搜索示例,下面给出另外一个版本,支持交互功能。
#coding:utf-8
try:
from PySide.QtGui import QApplication
from PySide.QtCore import QUrl, QEventLoop, QTimer
from PySide.QtWebKit import QWebView
except ImportError:
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl, QEventLoop, QTimer
from PyQt4.QtWebKit import QWebView
import lxml.html as lm
def main():
'''
首先设置搜索参数和模拟动作事件,获取在此参数和动作下搜索后得到的网页
然后在这网页下,获取数据
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(QUrl('http://example.webscraping.com/places/default/search'))
loop.exec_()
webview.show()## 显示渲染窗口,,可以直接在这个窗口里面输入参数,执行动作,方便调试
frame = webview.page().mainFrame()
## 设置搜索参数
# frame.findAllElements('#search_term') ##寻找所有的search_term框,返回的是列表
# frame.findAllElements('#page_size option:checked')
# ## 表单使用evaluateJavaScript()方法进行提交,模拟点击事件
# frame.findAllElements('#search')
frame.findFirstElement('#search_term').setAttribute('value', '.') ##第一个search_term框
frame.findFirstElement('#page_size option:checked').setPlainText('1000') ##第一个page_size框
## 表单使用evaluateJavaScript()方法进行提交,模拟点击事件
frame.findFirstElement('#search').evaluateJavaScript('this.click()') ##第一个点击框
## 轮询网页,等待特定内容出现
## 下面不断循环,直到国家链接出现在results这个div元素中,每次循环都会调用app.processEvents()
##用于给QT事件执行任务的时间,比如响应事件和更新GUI
elements = None
while not elements:
app.processEvents()
elements = frame.findAllElements('#results a') ##查找下载网页内的所有a标签
countries = [e.toPlainText().strip() for e in elements] ##取出所有a标签内的文本内容
print countries
if __name__ == '__main__':
main()为了提高代码的易用性,我们把使用到的方法封装到一个类中:
#coding:utf-8
import re
import csv
import time
try:
from PySide.QtGui import QApplication
from PySide.QtCore import QUrl, QEventLoop, QTimer
from PySide.QtWebKit import QWebView
except ImportError:
from PyQt4.QtGui import QApplication
from PyQt4.QtCore import QUrl, QEventLoop, QTimer
from PyQt4.QtWebKit import QWebView
import lxml.html
class BrowserRender(QWebView):
def __init__(self, display=True):
self.app = QApplication([])
QWebView.__init__(self)
if display:
## 显示渲染窗口,,可以直接在这个窗口里面输入参数,执行动作,方便调试
self.show() # show the browser
def open(self, url, timeout=60):
"""Wait for download to complete and return result"""
loop = QEventLoop()
timer = QTimer() ## 设置定时器
timer.setSingleShot(True)
timer.timeout.connect(loop.quit)
self.loadFinished.connect(loop.quit)
self.load(QUrl(url))
timer.start(timeout * 1000)
loop.exec_() # delay here until download finished
if timer.isActive(): ##如果定时器还是活跃,那么说明下载没有超时
# downloaded successfully
timer.stop()
return self.html() ##网页下载完成后,将其转成html,方便在html上进行数据抽取
else:
# timed out
print 'Request timed out:', url
def html(self):
"""Shortcut to return the current HTML"""
return self.page().mainFrame().toHtml()
def find(self, pattern):
"""Find all elements that match the pattern"""
"""因为这个网页中每个框的名字都不一样,故findFirstElement和findAllElements没有什么区别"""
##只不过findFirstElement返回是一个一个元素
## findFirstElement返回是一个列表,用这个列表时需要遍历
return self.page().mainFrame().findFirstElement(pattern)
#return self.page().mainFrame().findFirstElement(pattern)
def attr(self, pattern, name, value):
"""Set attribute for matching elements"""
self.find(pattern).setAttribute(name, value)
# for e in self.find(pattern):
# e.setAttribute(name, value)
def text(self, pattern, value):
"""Set attribute for matching elements"""
self.find(pattern).setPlainText(value)
# for e in self.find(pattern):
# e.setPlainText(value)
def click(self, pattern):
"""Click matching elements"""
self.find(pattern).evaluateJavaScript("this.click()")
# for e in self.find(pattern):
# e.evaluateJavaScript("this.click()")
def wait_load(self, pattern, timeout=60):
"""Wait for this pattern to be found in webpage and return matches"""
## 设置定时器,跟踪等待时间,并在截止事件前取消循环,否则当网络出现问题时,事件会无休止的运行下去
deadline = time.time() + timeout
while time.time() < deadline:
self.app.processEvents()
matches = self.page().mainFrame().findAllElements(pattern)
if matches:
return matches
print 'Wait load timed out'
def main():
'''
首先设置搜索参数和模拟动作事件,获取在此参数和动作下搜索后得到的网页
然后在这网页下,查找相关内容
'''
br = BrowserRender()
br.open('http://example.webscraping.com/places/default/search')
br.attr('#search_term', 'value', '.')
br.text('#page_size option:checked', '1000')
br.click('#search')
##设置定时器,跟踪等待时间,并在截止事件前取消循环,否则当网络出现问题时,事件会无休止的运行下去
elements = br.wait_load('#results a')
writer = csv.writer(open('countries1.csv', 'w'))
#for country in [e.toPlainText().strip() for e in elements]:
for country in [e.toPlainText().strip() for e in elements]:
print country,
writer.writerow([country])
if __name__ == '__main__':
main()














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









