







 超级会员免费看
超级会员免费看
柱状图是在数据可视化过程中最为常见的图片形式之一,本文将借助R语言中的ggplot2这个包绘制常用的柱状图。在ggplot2包中主要是使用geom_bar()这个函数来绘制柱状图。该函数主要包括以下5个参数,我们可以通过输入?geom_bar命令来查看帮助文档。
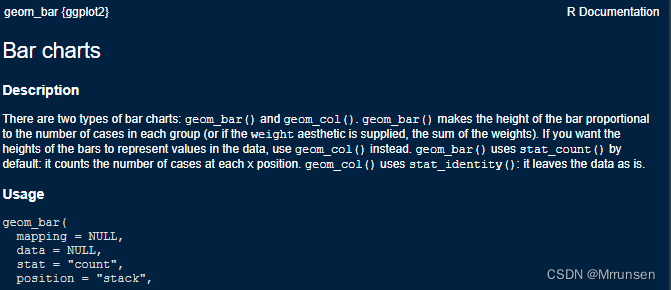
stat:有identity、count和bin这三个参数。其中identity比较常用,表示直接引用数据集中的变量的值(默认为count)。
position:我的理解为调整柱状图的形式,有identity、fill、dodge这三种形式,下面将通过案例1对此进行详细讲解。
width:调整柱子的宽度。
color:调整柱子边框的颜色。
fill:调整柱子的填充颜色。
案例一:在这里插入代码片
使用ggplot2包里的“diamonds”数据集。diamonds数据集包含大约 54 000 颗钻石的信息,每颗钻石具有 price、carat、color、clarity 和 cut 变量。案例一将使用cut(切割质量)和clarity (钻石的纯净度)这两个变量。
1、调整参数position=“identity”,color = “white”
library(tidyverse) # 载入数据集和绘图包
ggplot(data = diamonds) +
geom_bar(aes(x = cut, fill = clarity),
color = "white", position = "identity")
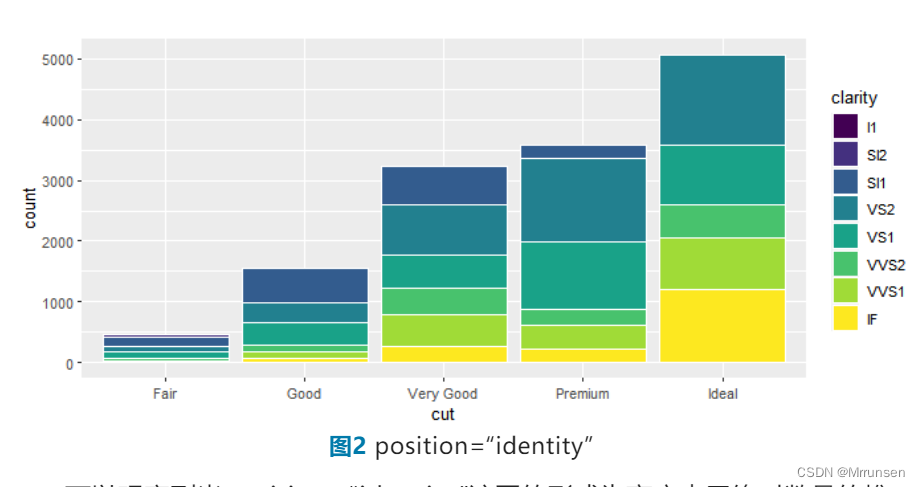
可以观察到当position=“identity”该图的形式为高度表示绝对数量的堆积柱状图,当color = “white”时边框变成了白色,当我们想改变柱子的填充颜色时,可以使用fill这个函数。
同时,我们也可以通过coord_flip()函数把柱子变成横向的。
coord_flip()
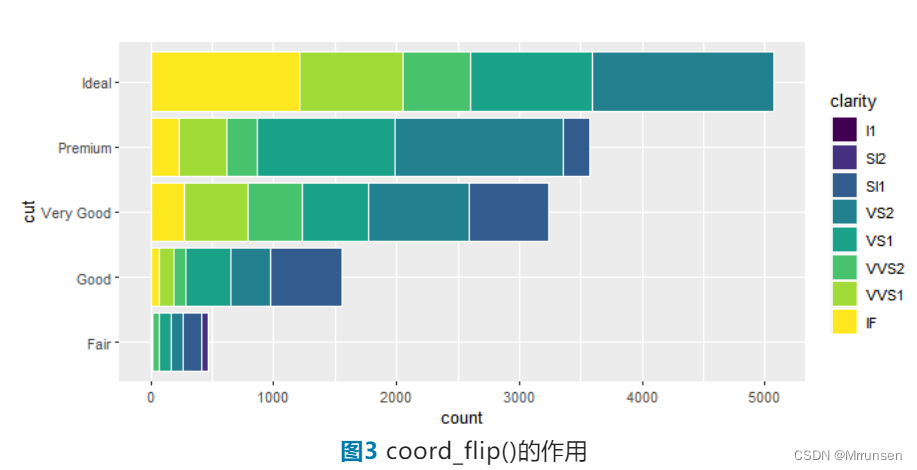
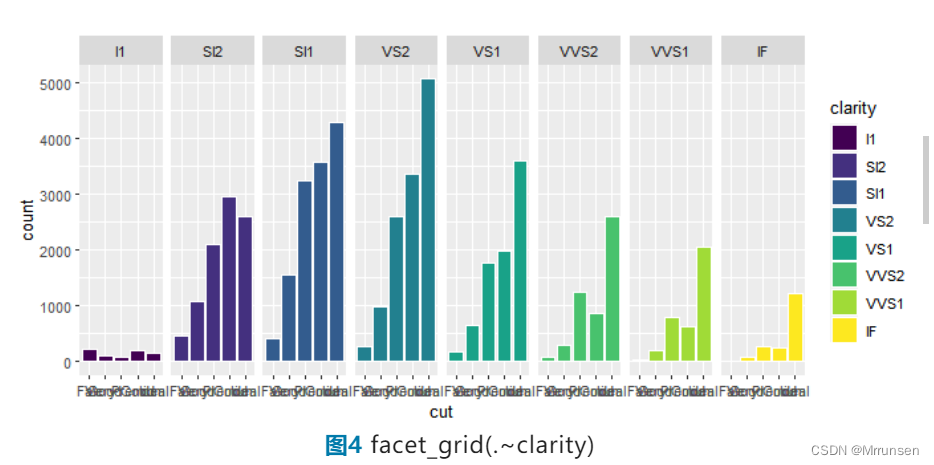
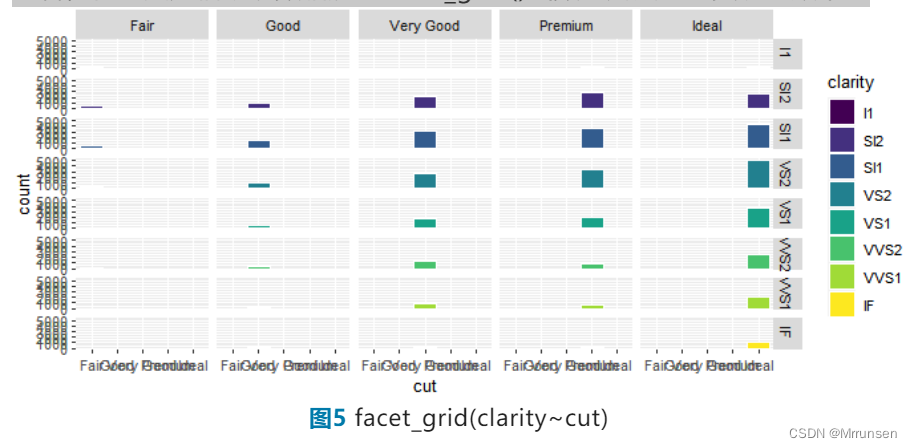
如果我们想通过clarify的不同把该图分为不同小块,可以通过facet_grid()函数来实现。
ggplot(data = diamonds) +
geom_bar(aes(x = cut, fill = clarity), color = "white", position = "identity")+
facet_grid(.~clarity)
ggplot(data = diamonds) +
geom_bar(aes(x = cut, fill = clarity), color = "white", position = "identity")+
facet_grid(clarity~cut)
从以上代码可以看出,facet_grid()2个变量间用“~”进行分隔,当只需要使用1个变量时,另一个变量使用“.”代替。当然,这个数据分块后的结果并不好看,在此只是借助该数据展示facet_grid()函数的用法与可实现的效果。
ggplot(data = diamonds) + geom_bar(aes(x = cut, fill = clarity), position = "fill")
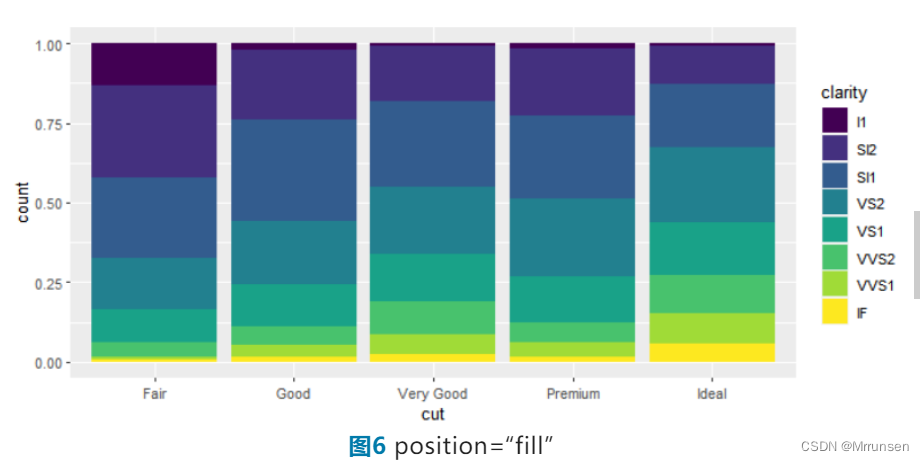
当position=“fill”时该图的形式为高度表示相对数量的百分比堆积柱状图,每个柱子的最大高度均为1。
ggplot(data = diamonds) +
geom_bar(aes(x = cut, fill = clarity), position = "dodge")
当position=“dodge”时该图的形式为柱子高度表示绝对数量的分组柱状图。
案例二:
下面将通过案例二来绘制分组堆叠柱状图.
library(ggplot2) # 用于绘图
library(ggalluvial) # 用于绘制柱状图背后的条带
ra <- as.matrix(read.table("abundance.txt", row.names =1,
header = F, sep = "\t")) # 读入相对丰度数据并转换为矩阵方便后续数据整理
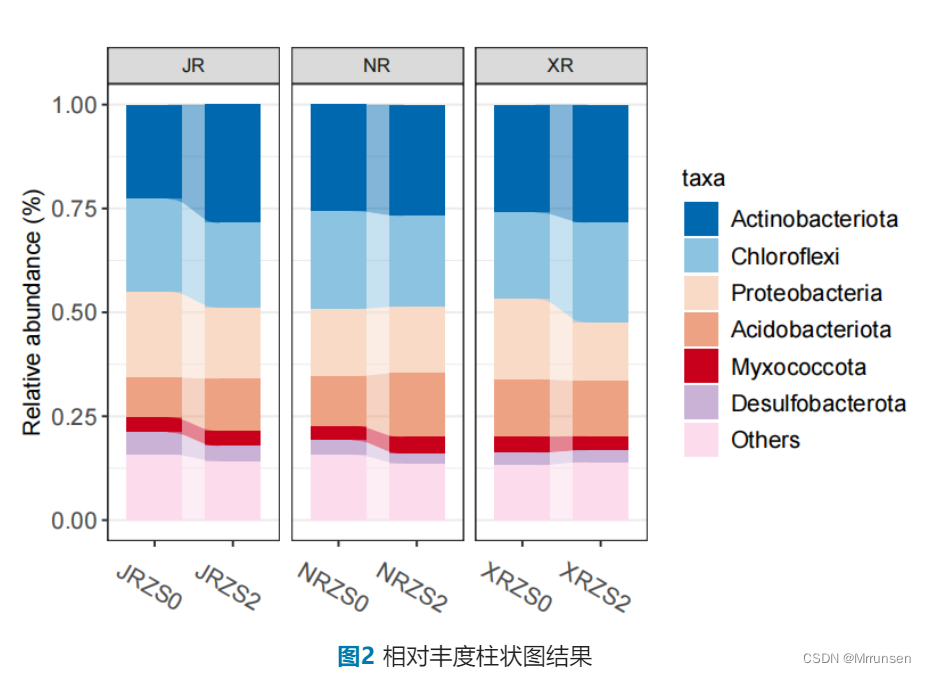
Note: 从左至右分组分别为JRZS0,JRZS2,NRZS0,NRZS2,XRZS0,XRZS2共6个分组。其中JR、NR、XR分别为3种不同品种的水稻:粳稻、糯稻、籼稻;ZS0和ZS2分别代表不施用基肥和施用2kg/亩的锌肥。
group <- c("JR", "NR","XR") # 水稻品种变量
code <- c("JRZS0","JRZS2","NRZS0","NRZS2","XRZS0","XRZS2") # 6组处理变量
dat <- data.frame(code = rep(code,each = 7),
taxa = rep(rownames(ra), 6),
cultivar = rep(group, each = 14),
abundance = as.vector(ra)) # 按照ggplot绘图所需格式进行数据整理
dat$taxa <- factor(dat$taxa, levels = c("Actinobacteriota","Chloroflexi","Proteobacteria",
"Acidobacteriota","Myxococcota","Desulfobacterota","Others"))
#这个用于对各菌门数据进行排序
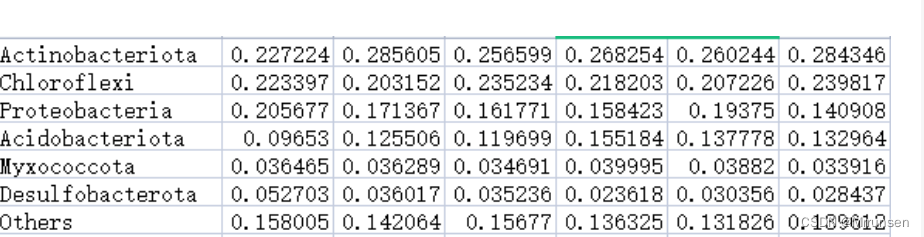
head(dat) # 查看整理好的数据前6行
code taxa cultivar abundance
1 JRZS0 Actinobacteriota JR 0.22722374
2 JRZS0 Chloroflexi JR 0.22339743
3 JRZS0 Proteobacteria JR 0.20567651
4 JRZS0 Acidobacteriota JR 0.09652968
5 JRZS0 Myxococcota JR 0.03646502
6 JRZS0 Desulfobacterota JR 0.05270264
ggplot(dat, aes(x = code, y = abundance, fill = taxa))+
geom_bar(stat = "identity", width = 0.7)+ # 柱状图绘制
geom_flow(aes(alluvium = taxa), alpha = 0.5) + # 添加柱状图后的条带
scale_fill_manual(values = c("#0068ad", "#8ac2df","#f8d9c5",
"#eca282","#c80321","#c9b1d5","#fcdaeb"))+
theme_bw()+ # 将主题调整为白色背景和浅灰色网格线
facet_grid(.~cultivar, scales = "free_x", space = "free_x")+ # 按照cultivar这个变量进行分块
xlab("")+ # 去掉x轴的标题
ylab("Relative abundance (%)")+ # 设置y轴的标签
theme(panel.grid.major.x = element_blank(),
axis.text.x = element_text(size = rel(1.2), angle = (-30)),
axis.text.y = element_text(size=rel(1.2)),
legend.text = element_text(size = rel(1))) # 更改x轴、y轴的字体大小、刻度线等
ggsave("Abundance.pdf", width = 6, height = 4) # 图片导出,导出为pdf文件,设置图片长和宽















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









