








🎏:你只管努力,剩下的交给时间
🏠 :小破站
Gemini-2.5pro在OCR上表现超神,我的草书都能识别!
引言
Google最新推出的Gemini-2.5 Pro大型语言模型不仅在标准NLP任务上表现出色,更在光学字符识别(OCR)领域展现出惊人的能力。今天我将分享两个实际测试案例,证明这款模型的OCR识别能力已经达到了"超神"水平。
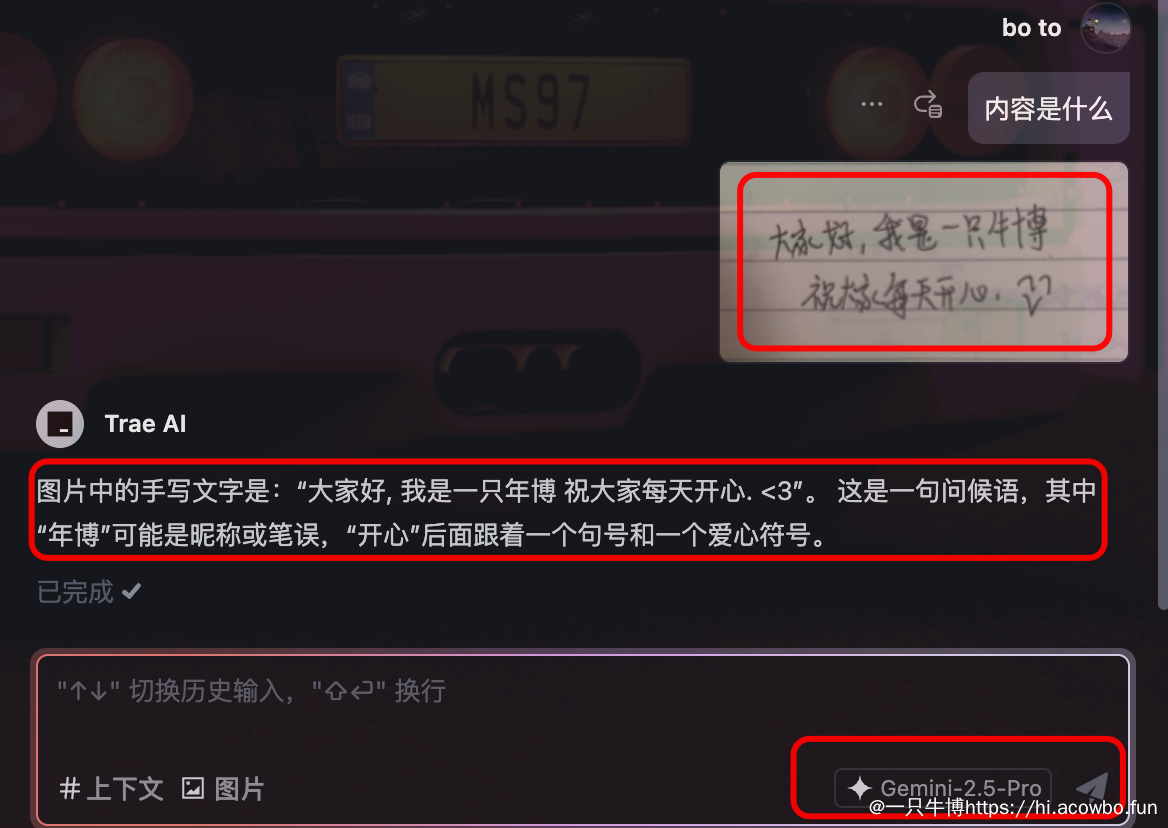
草书识别:连我自己都难辨认的字迹
作为一个字迹潦草的人,我的手写笔记常常连自己回头看都难以辨认。带着好奇心,我决定用我最潦草的笔记挑战Gemini-2.5 Pro。
将一句自我介绍+祝福语上传后,令人惊讶的是,Gemini几乎完美地识别出了所有内容,包括:
- 潦草的中文字符
- 不规则的标点符号
- 甚至是我自创的缩写和简写
- 表情符号
这远超出了我的预期,因为连我自己有时候都不认识自己的笔迹,而Gemini却能直接解读。

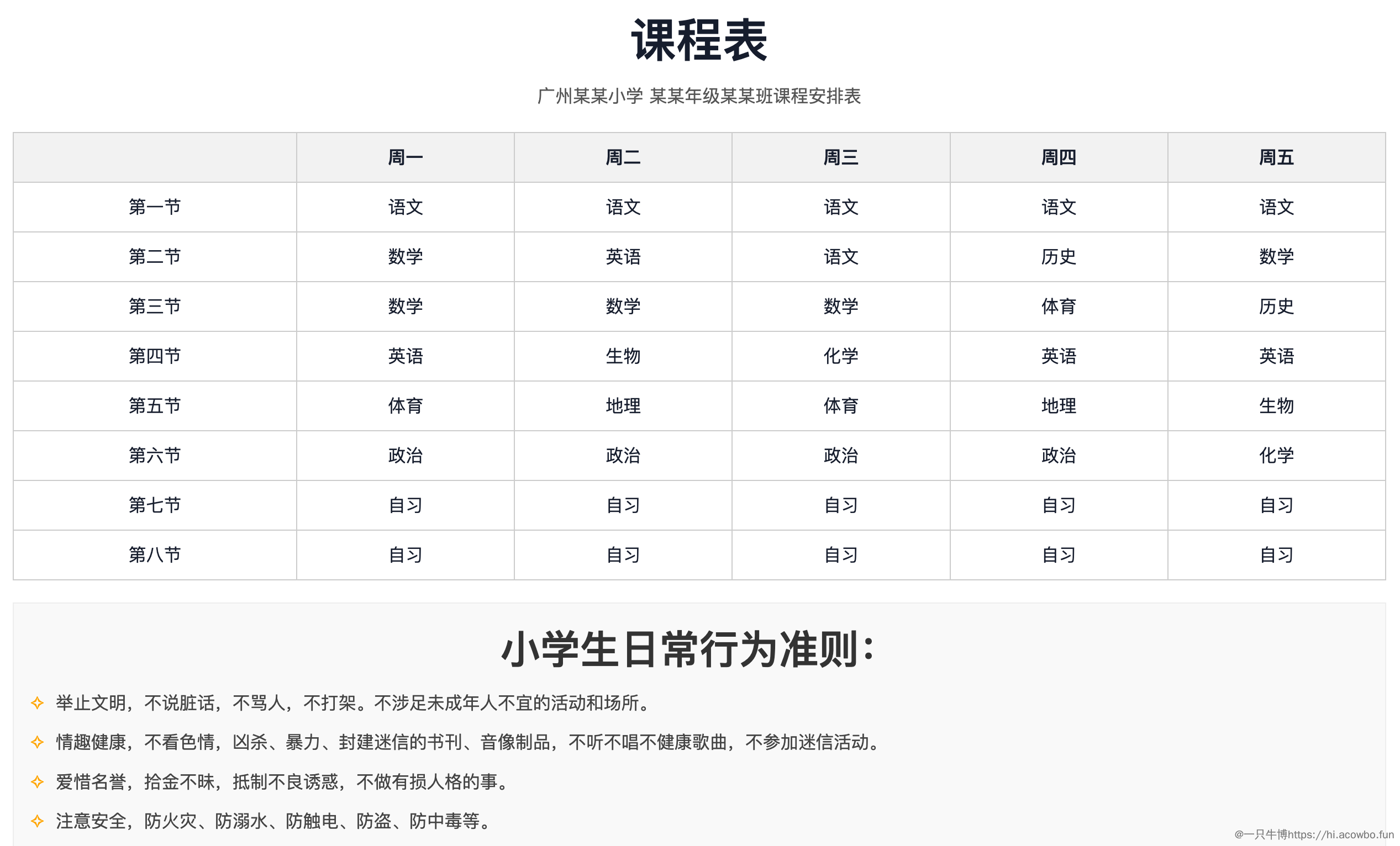
复杂课表转HTML:一键从图像到结构化数据
第二个测试更具挑战性:我从网上找了一张复杂的课程表,包含多个时间段、各种课程名称。这类表格通常需要手动重建或使用专业OCR软件处理。
将课表图片上传给Gemini-2.5 Pro后,我要求它识别内容并生成相应的HTML代码。结果令人震惊:
- 模型不仅准确识别了所有文字内容
- 还正确理解了表格的行列结构和单元格合并情况
- 生成的HTML代码格式规范,结构完整
- 直接复制代码到浏览器就能呈现出完整还原的课表
最令人印象深刻的是,Gemini不仅仅是识别了文字,而是真正"理解"了课表的含义和结构,这远超传统OCR工具的能力范围。
首先是我提问的内容以及课程表的内容:

生成的html如下图:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>课程表</title>
<style>
body {
font-family: sans-serif;
}
table {
width: 80%;
margin: 20px auto;
border-collapse: collapse;
border: 1px solid #ccc;
}
th, td {
border: 1px solid #ccc;
padding: 10px;
text-align: center;
}
th {
background-color: #f2f2f2;
}
.header {
text-align: center;
margin-bottom: 20px;
}
.header h1 {
margin-bottom: 5px;
}
.header p {
color: #555;
margin-top: 0;
}
.rules {
width: 80%;
margin: 20px auto;
padding: 15px;
border: 1px solid #eee;
background-color: #f9f9f9;
}
.rules h2 {
margin-top: 0;
text-align: center;
color: #333;
}
.rules ul {
list-style: none;
padding-left: 0;
}
.rules li {
margin-bottom: 10px;
line-height: 1.6;
color: #444;
}
.rules li::before {
content: "✧ "; /* Using a similar symbol */
color: #ffa500; /* Orange color */
margin-right: 5px;
}
</style>
</head>
<body>
<div class="header">
<h1>课程表</h1>
<p>广州某某小学 某某年级某某班课程安排表</p>
</div>
<table>
<thead>
<tr>
<th></th>
<th>周一</th>
<th>周二</th>
<th>周三</th>
<th>周四</th>
<th>周五</th>
</tr>
</thead>
<tbody>
<tr>
<td>第一节</td>
<td>语文</td>
<td>语文</td>
<td>语文</td>
<td>语文</td>
<td>语文</td>
</tr>
<tr>
<td>第二节</td>
<td>数学</td>
<td>英语</td>
<td>语文</td>
<td>历史</td>
<td>数学</td>
</tr>
<tr>
<td>第三节</td>
<td>数学</td>
<td>数学</td>
<td>数学</td>
<td>体育</td>
<td>历史</td>
</tr>
<tr>
<td>第四节</td>
<td>英语</td>
<td>生物</td>
<td>化学</td>
<td>英语</td>
<td>英语</td>
</tr>
<tr>
<td>第五节</td>
<td>体育</td>
<td>地理</td>
<td>体育</td>
<td>地理</td>
<td>生物</td>
</tr>
<tr>
<td>第六节</td>
<td>政治</td>
<td>政治</td>
<td>政治</td>
<td>政治</td>
<td>化学</td>
</tr>
<tr>
<td>第七节</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
</tr>
<tr>
<td>第八节</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
<td>自习</td>
</tr>
</tbody>
</table>
<div class="rules">
<h2>小学生日常行为准则:</h2>
<ul>
<li>举止文明,不说脏话,不骂人,不打架。不涉足未成年人不宜的活动和场所。</li>
<li>情趣健康,不看色情,凶杀、暴力、封建迷信的书刊、音像制品,不听不唱不健康歌曲,不参加迷信活动。</li>
<li>爱惜名誉,拾金不昧,抵制不良诱惑,不做有损人格的事。</li>
<li>注意安全,防火灾、防溺水、防触电、防盗、防中毒等。</li>
</ul>
</div>
</body>
</html>
技术分析:为何Gemini-2.5 Pro的OCR如此强大?
Gemini-2.5 Pro的OCR能力优势主要体现在:
-
多模态理解:模型能同时处理视觉和语言信息,理解图像中的上下文。
-
丰富的训练数据:经过大量各类文字样本训练,包括不同字体、手写体和复杂布局。
-
上下文推理能力:当遇到模糊或不确定的字符时,能通过上下文推断最可能的内容。
-
结构化信息处理:不仅识别文字,还能理解表格、列表等结构化信息的逻辑关系。
实际应用场景
这种强大的OCR能力为许多应用场景带来可能:
- 学生可快速数字化手写笔记
- 研究人员能高效提取古籍或手稿中的信息
- 办公人员可一键将纸质表格转为电子文档
- 开发者能更容易实现文档自动化处理流程
结语
Gemini-2.5 Pro的OCR能力确实达到了"超神"水平,特别是在处理手写体和复杂结构化内容方面的表现令人印象深刻。这不仅是技术的进步,更代表了AI向真正理解和处理人类信息方式迈出的重要一步。
无论是草书识别还是复杂表格转换,Gemini-2.5 Pro都展示了超越传统OCR工具的卓越能力,为我们处理各类文本图像带来了全新的可能性。
另外,trae也是支持Gemini-2.5pro,下面是trae实现的



















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











